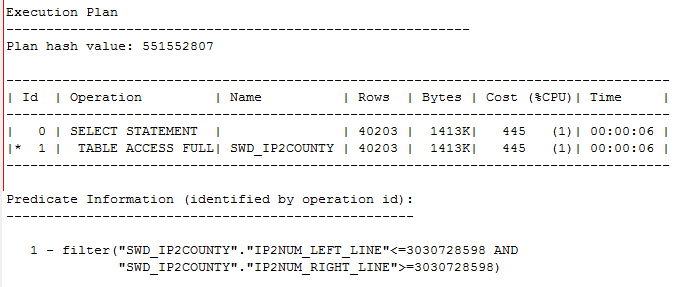
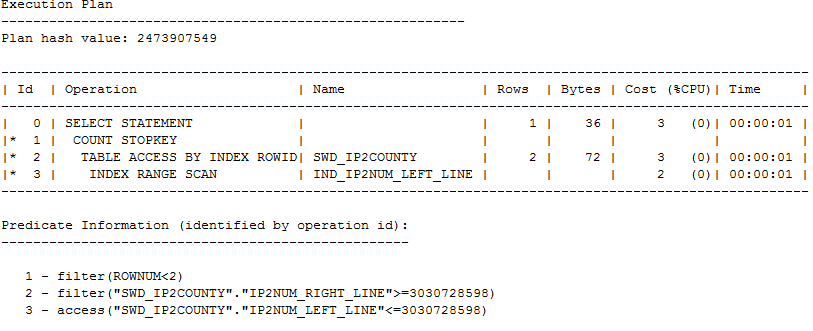
昨天中午吃饭的时候,突然手机收到一条报警信息,提示数据库的负载突然提高了。对于一个高配,稳定,核心的系统来说,出现这么一个报警会立刻引起关注。 连接到环境之后,发现在问题发生时间段快照中资源消耗较大的SQL情况如下: SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL ---------- ------------- ---------------- ---------- ---------- 2396 63f970ck8r3kc 26284 7316s 49% 2396 0k8yyk60k4y7x 63356 7342s 49% 2396 63f970ck8r3kc 0 7316s 49% 2396 174qq0v73j2at 37952 2s 0% 2396 87katd5jmmthy 1761 0s 0% 可以看到有两个语句的执行频率还是比较高,整体占用了绝大多数的CPU资源。 对应的前两个SQL语句如下: SQL_FULLTEXT ---------------------------------------------------------------------------------------------------- SELECT IP_ID,COUNTRY,PROVINCE,CAPITAL FROM SWD_IP2COUNTY WHERE STRIPTOINT(:B1 ) BETWEEN IP2NUM_LEFT_LINE AND IP2NUM_RIGHT_LINE 看起来语句很简单,第一感觉是不是全表扫描导致的,也就潜意识中感觉是不是没有相关的索引。 但是查看表结构信息,发现在IP2NUM_LEFT_LINE和IP2NUM_RIGHT_LINE有两个索引,索引最初的猜想不成立。 然后开始看这个语句的细节,发现这个语句还真是有点意思,之前还没见过这种写法。 首先是里面看起来是是存在一个函数STRIPTOINT处理绑定变量,然后有一个过滤条件between xxx and xxx,两端的可是字段,不是具体的数值。 如果函数STRIPTOINT处理某个字段的数值,那么就是一种使用不规范的情况,肯定会走索引,但是这里的情况又有些特殊。 看到这个逻辑,我是有些懵了,咱也不能随便猜。看看表结构。 COLUMN_ID COLUMN_NAME DATA_TYPE DATA_LENGTH NULLABLE ---------- ------------------------------ --------------- ----------- ---------- 1 IP_ID NUMBER(10,0) 22 N 2 IP_LEFT_LINE VARCHAR2(15) 15 N 3 IP_RIGHT_LINE VARCHAR2(15) 15 N 4 IP2NUM_LEFT_LINE NUMBER(10,0) 22 N 5 IP2NUM_RIGHT_LINE NUMBER(10,0) 22 N 6 COUNTRY VARCHAR2(20) 20 Y 7 PROVINCE VARCHAR2(20) 20 Y 8 CAPITAL VARCHAR2(20) 20 Y 可以看出是和IP相关的,而且里面存在一些地理区域的信息。 函数STRIPTOINT是对传入的IP做过滤,比如传入一个IP 10.1.3.5 ,函数会把这个IP按照".”进行分隔,从第一部分开始到第四部分,会逐步拉开数据的梯度。 比如传入一个IP,就会转换为一个较大的数值,尽可能保证不会重复。 SQL> select STRIPTOINT('124.115.229.74') from dual; STRIPTOINT('124.115.229.74') ---------------------------- 208797012 所以这个SQL语句就类似下面的形式。 SELECT IP_ID,COUNTRY,PROVINCE,CAPITAL FROM tlbb.SWD_IP2COUNTY WHERE 208797012 BETWEEN IP2NUM_LEFT_LINE AND IP2NUM_RIGHT_LINE 这样理解起来还真是有点费劲,我们继续介绍一些相关的业务情况,这些也是我根据数据猜出来的,后面和开发的同学聊,和我想的是一样的。 比如数据是这样的形式: IP_LEFT_LINE IP_RIGHT_LINE IP2NUM_LEFT_LINE IP2NUM_RIGHT_LINE COUNTRY PROVINCE CAPITAL ----- --------------- --------------- ---------------- ----------------- ---------- ---------- ------- 5.34.184.0 5.34.191.255 86161408 86163455 中国 北京 北京 5.34.192.0 5.34.223.255 86163456 86171647 中国 河北 石家庄 比如IP 5.34.184.0~5.34.191.255 这个区间代表的是北京地区,5.34.192.0 ~ 5.34.223.255 这个区间代表的是河北石家庄。那么传入一个IP就开始映射得到一个数值,通过这个范围区间来找到对应的地区。 这样一个语句,明白了需求,好像还是有点道理。 来看看awr的SQL报告怎么说吧。 Snap Id Snap Time Sessions Curs/Sess --------- ------------------- -------- --------- Begin Snap: 2397 01-Sep-16 13:00:52 567 1.9 End Snap: 2398 01-Sep-16 13:30:54 566 1.9 Elapsed: 30.03 (mins) DB Time: 138.02 (mins) 可以看到在短期内,数据库的负载还是比较高。 而SQL的执行统计信息如下: Stat Name Statement Per Execution % Snap ---------------------------------------- ---------- -------------- ------- Elapsed Time (ms) 8,067,698 276.4 97.4 CPU Time (ms) 8,059,783 276.1 97.8 Executions 29,191 N/A N/A Buffer Gets 3.3692E+07 1,154.2 74.8 Disk Reads 0 0.0 0.0 Parse Calls 73 0.0 0.0 Rows 28,516 1.0 N/A User I/O Wait Time (ms) 0 N/A N/A Cluster Wait Time (ms) 0 N/A N/A Application Wait Time (ms) 0 N/A N/A Concurrency Wait Time (ms) 0 N/A N/A Invalidations 0 N/A N/A Version Count 4 N/A N/A Sharable Mem(KB) 46 N/A N/A
如果想得到更多的详细的信息,使用诊断事件也是不错的选择,这也是11g的一个功能。 比如对某一条SQL开启sql_trace,可以使用如下的方式。 开启: alter system set events 'sql_trace [sql: 63f970ck8r3kc] level 12'; 关闭: alter system set events 'sql_trace [sql: 63f970ck8r3kc] off'; 而如果有大量的会话频繁调用,那还是不建议使用的,会生成大量的trace文件,目前的情况就是如此,需要谨慎使用。 而我们怎么去分析这个SQL呢,来做一个10053事件吧。 ALTER SESSION SET EVENTS='10053 trace name context forever, level 1'; SELECT IP_ID,COUNTRY,PROVINCE,CAPITAL FROM test.SWD_IP2COUNTY WHERE 208797012 BETWEEN IP2NUM_LEFT_LINE AND IP2NUM_RIGHT_LINE; ALTER SESSION SET EVENTS '10053 trace name context off';
这个时候trace的信息可以看到,内部做了查询转换,会把原有的语句转换为下面的形式: Final query after transformations:******* UNPARSED QUERY IS ******* SELECT "SWD_IP2COUNTY"."IP_ID" "IP_ID","SWD_IP2COUNTY"."COUNTRY" "COUNTRY","SWD_IP2COUNTY"."PROVINCE" "PROVINCE","SWD_IP2C OUNTY"."CAPITAL" "CAPITAL" FROM "TEST"."SWD_IP2COUNTY" "SWD_IP2COUNTY" WHERE "SWD_IP2COUNTY"."IP2NUM_LEFT_LINE"<=208797012 AND "SWD_IP2COUNTY"."IP2NUM_RIGHT_LINE">=208797012
对于执行路径和表信息的统计信息如下: Access path analysis for SWD_IP2COUNTY *************************************** SINGLE TABLE ACCESS PATH Single Table Cardinality Estimation for SWD_IP2COUNTY[SWD_IP2COUNTY]