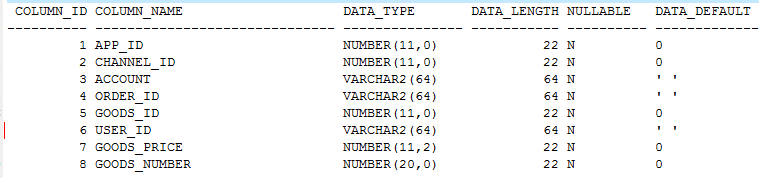
最近有个同事碰到一个问题,想让我给点思路。我大体了解了一下,是一个系统目前在做压力测试,但是经业务反馈发现某个环节的处理时间有些长,排查了一圈,最后这件事情就落在了DB这边,希望DB能够给点意见,是否存在一些性能瓶颈。 我们从开发同学那里得到的一个基本的SQL语句,根据关键字从v$sql中做了提取,发现对应的SQL语句的执行时间还是OK的。 得到的SQL语句如下: SQL_ID SQL_FULLTEXT ------------- ---------------------------------------------------------------------------------------------------- 6h4w0u8stp3z0 select APP_ID,GOODS_ID,ORDER_ID,ORDER_STATUS,GOODS_REGISTER_ID,GOODS_NUMBER,GROUP_ID,GOODS_PRICE,US ER_ID,ROLE_ID,ROLE_NAME,CHANNEL_ID,PUSH_NUM,PUSH_INFO from TB_ORDE R WHERE ORDER_ID=:1 AND USER_ID=:2 AND SUBSTR(CHANNEL_ID,0,4)=:3 这样一个语句,如此来看性能上应该是没有多少改进的空间了。我查看了数据库层面的相关统计信息,发现DB time极低,比如Elapsed time为60分钟,DB time就不到1分钟, 类似下面这样的输出。 Snap Id Snap Time Sessions Curs/Sess --------- ------------------- -------- --------- Begin Snap: 3295 24-Aug-16 13:00:17 38 .9 End Snap: 3296 24-Aug-16 14:00:20 44 .9 Elapsed: 60.05 (mins) DB Time: 0.03 (mins) 如此之低的情况下,很难和性能问题联系起来。通过得到的数据情况分析,细化到ASH报告也没有发现任何异常,所以我们可以说DB层面没有性能瓶颈,这个问题还需要进一步的确认。 当然交代完这件事情,主要任务就完成了。就简单再看了看这个问题。 执行计划的情况如下,看到这样的执行计划似乎也没有任何可挑剔的。 谓词信息如下: 看到这里我开始有一些疑惑,作为一个订单表,订单号应该是作为主键的,看到索引的情况,发现确实是。 表结构如下所示,在分析之前还是需要说明这些基本情况的。 那么问题就来了,按道理是需要走唯一性索引代价最低,为什么执行计划缺走了另外一个索引,由期望中的唯一性索引扫描变为了范围索引扫描,这是疑点1. 解答这个问题的过程中发现,其实会引出更多的问题,原本的问题只是开始,因为后面要走的路还有很多。 对于这个问题,我们得求助于10053事件,这个诊断事件能够从根本上解释清楚这个原因来。 当然开启10053,我开启了1级,日志量相对要更多一些。 开启10053事件 ALTER SESSION SET EVENTS='10053 trace name context forever, level 1'; 运行SQL语句 结束10053事件 ALTER SESSION SET EVENTS '10053 trace name context off'; 其中需要说明一点的是,如果采用如下的这种方式开启诊断事件,是不行的。 alter session set current_schema=ordermob; select 。。。。 from OP_ORDER WHERE ORDER_ID='160824165342672424' AND USER_ID='15000501196112' AND SUBSTR(CHANNEL_ID,0,4)=5046 ; 可以使用如下的方式来代替。 select 。。。 from ordermob.OP_ORDER WHERE ORDER_ID='160824165342672424' AND USER_ID='15000501196112' AND SUBSTR(CHANNEL_ID,0,4)=5046 ; 10053事件中查询转换结果如下: Final query after transformations:******* UNPARSED QUERY IS ******* SELECT "OP_ORDER"."APP_ID" "APP_ID",。。。。 FROM "ORDERMOB"."TB_ORDER" "OP_ORDER" WHERE "OP_ORDER"."ORDER_ID"='160824165342672424' AND "OP_ORDER"."USER_ID"='15000501196112' ANDTO_NUMBER(SUBSTR(TO_CHAR("OP_ORDER"."CHANNEL_ID"),0,4))=5046 kkoqbc: optimizing query block SEL$1 (#0)