





今天处理了一起紧急问题,回过头来看还是有不少需要注意的地方。
首先是收到了报警,有一台DB服务器的负载有一些高,但是会快就恢复了。所以自己也没有在意,但是过了大概40多分钟,又接到一封报警邮件,而且随着报警频繁,感觉真是出了问题,在中控机器上使用ssh连接竟然都抛出了异常。
# ssh 10.127.xxxx
Connection timed out during banner exchange
对于这类问题,是因为超出了默认的超时参数,不过我没有纠结在超时的时长,因为这个本身已经不重要,既然中控超时连接,那么服务器端看来是出了点状况。
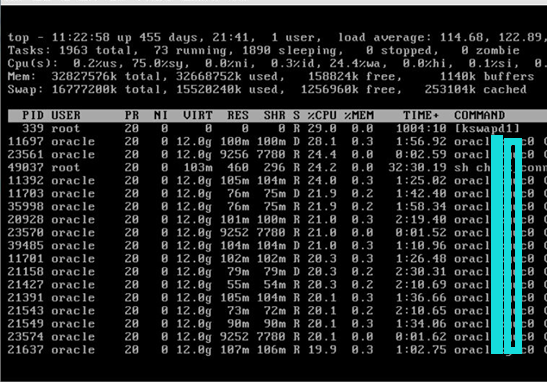
可以看到SWAP很严重,已经到了岌岌可危的地步,远远超出了默认的阈值范围60%,而内存空间也是所剩无几,导致SWAP被过度使用。
到底有多慢呢,在iLO端切换用户差不多得等30秒,结果使用sqlplus / as sysdba登录竟然几分钟没有响应,取消又是几十秒,在这种龟速的情况下,服务端的响应情况可想而知。
好不容易运行了一个top命令,一看CPU使用率极高。
下面的图形来自于Zabbix监控,可以看到问题发生的时间段里,CPU使用率极高,而且红色的部分是系统级使用率,占用极高,iowait也很高。
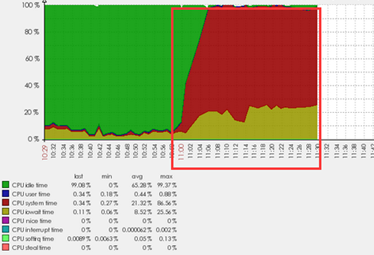
当然情况紧急,在紧急情况下,是考验基本功的时刻。尽管我可以看到有一些进程占用CPU严重,但是我连接到数据库出了点问题,我也知道需要绑定v$process和v$session就可以得到对应的SQL语句,但是思路是通的,实现起来就是个问题。这种情况该怎么办。
有的同学说切换备库,或者停止数据库我们来说一说。
首先是切换备库,这无疑是一个不错的方案,但是也有局限性,切换本身需要简单评估一番,如果前期准备充分,这个地方就不用花太多的时间,而关注的点就是是否需要替换IP,而问题就来了,原来的服务器还没有宕机,IP资源还在,switchover是不可行了,还需要把这台服务器直接关掉,腾出网络资源再替换IP。这个过程还是存在一些隐患,备库是否一定好用,现在面临的问题在备库是否会迎刃而解,如果是简单的问题复制,那么这个主备库都被搞挂了,而且已经完全不一致了。这可就麻烦了。
而停止数据库我们就需要考虑集中方式,首先是使用shutdown immediate,这种方式不太可行,在目前的情况下,我想这个操作得持续至少10分钟,连接数有1000多个。这个资源的释放本身还是需要不少的时间。如果使用shutdown abort肯定是命令方式最快的了,但是问题是我现在还没有连接到数据库端,这个操作还是会让我很纠结。所以经过评估我们一方面准备备库环境,一方面准备重启主库,因为考虑到SWAP极高,而我们早已经配置了大页,所以只需要重启数据库实例即可生效。怎么停呢,一种方式就是杀掉进程,我们知道数据库的5大必备进程,SMON,PMON,CKPT,DBWR,LGWR这个5个任何一个出现问题,实例都会宕掉,所以我们就杀掉一个进程,让系统资源极快释放,而这个过程本身还是存在一些风险,我们准备了备库,有备无患,所以在这种情况我开始了操作。
杀掉SMON进程发现部分的进程信息还在,我又杀掉PMON,进程资源马上得到了释放。这也就充分证明了PMON才是真正的进程管理进程,系统资源释放后,中控也能连接了,负载一下子降了下来,我们需要简单验证,重启数据库实例至nomount状态,查看大页开启了无误,启动实例,因为应用是自动连接,所以这个时候看问题就会简单需要,因为我们没有切换服务器,不需要修改IP,不需要考虑其他的权限影响。这种代价最低,而且恢复业务最快。看着数据库日志都在期望之中,所以这个问题后续关注,系统资源都趋于稳定。
当然问题的原因都需要经得起推敲,为什么在指定的时间会突然多出几百个进程(数据库会话),为什么SWAP的争用问题会在哪个时候放大,变得严重,而从系统和数据库层面而看待这个问题就是一个整体的眼光了,系统调优和问题分析都离不开这些必要条件,我们后续来揭晓。
而这个问题一下子让我想起了当年客户那边碰到的一个重大问题,是由于大页设置不当导致没有生效在OLTP业务中直接卡住,看到这个问题一下子让我想起了当年,所以尽快恢复业务是王道。


