
作者介绍
欧阳辰,超过15年的软件开发和设计经验,目前就职于小米公司,负责小米广告平台的架构研发。曾为微软公司工作10年,担任高级软件开发主管。热爱架构设计和高可用性系统,特别对于大规模互联网软件的开发,具有丰富的理论知识和实践经验。个人公众号:互联居。
数据分析(Data Analytics)从来都不是一个寂寞的领域,每一个时代都赋予其新的内容。在大数据盛行之时,各种大数据分析软件如雨后春笋一般涌现出来,整个市场一片繁花似锦、欣欣向荣。本篇文章主要介绍一些常用的大数据分析软件,帮助大家望尽天涯路,如对某软件有兴趣的话,可另找资料。
数据分析既是一门艺术,所谓艺术就是结合技术、想象、经验和意愿等综合因素的平衡和融合。数据分析的目的就是帮助我们把数据(Data)变成信息(Information),再从信息变成知识(Knowledge),最后从知识变成智慧(Wisdom)。
在数据分析的领域,商务智能(BI:Business Intelligence)、数据挖掘(DM:Data Mining)、联机分析处理(OLAP:On-Line Analytical Processing)等概念在名称上和数据分析字面非常接近,容易混淆,如下做个简单介绍。
商务智能(BI):商务智能是在商业数据上进行价值挖掘的过程,BI的历史很长,很多时候会特别指通过数据仓库的技术进行业务报表制作和分析的过程,分析方法上通常使用聚合(Aggregation)、分片(Slice)等方式进行数据处理。技术上,BI包括ETL(数据的抽取、转换、加载),数据仓库(Data Warehouse),OLAP(联机分析处理),数据挖掘(Data Mining)等技术。
数据挖掘:数据挖掘是指在大量数据中自动搜索隐藏于其中的有着特殊关系性(属于Association rule learning)的信息的过程。相比商务智能,数据挖掘是一种更加学术的说法,范围也广,深浅皆宜,强调技术和方法。
联机分析处理:联机分析处理(OLAP)是一个建立数据系统的方法,其核心思想即建立多维度的数据立方体,以维度(Dimension)和度量(Measure)为基本概念,辅以元数据实现可以钻取(Drill-down/up)、切片(Slice)、切块(Dice)等灵活、系统和直观的数据展现。
数据分析就是以业务为导向,从数据中发掘提升业务能力的洞察。
数据分析软件市场从来都是活跃的市场,从两个视角来看,一个是商业软件市场,充满了大鱼吃小鱼的故事;另一个是开源数据存储处理软件,在互联网精神和开源情怀的引导下,各种专业领域的开源软件日益壮大,通用数据存储系统也不断升级。
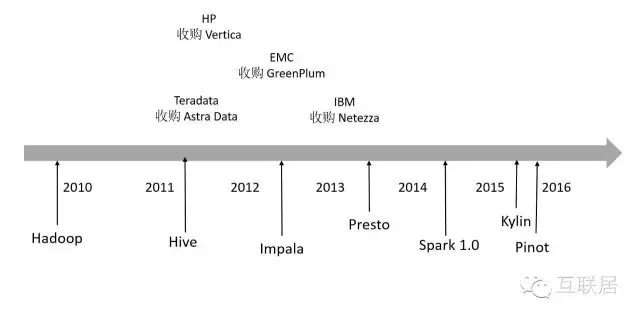
举例来说,2011年,Teradata收购了Aster Data 公司, 同年惠普收购实时分析平台Vertica等;2012年,EMC收购数据仓库软件厂商Greenplum;2013年,IBM宣布以17亿美元收购数据分析公司Netezza;这些收购事件指向的是同一个目标市场———大数据分析。传统的数据库软件,处理TB级数据非常费劲,而这些新兴的数据库正式瞄准TB级别,乃至PB级别的数据分析。
在开源世界,Hadoop将人们引入了大数据时代,处理TB级别大数据成为一种可能,但实时性能一直是Hadoop的一个伤痛。2014年,Spark横空出世,通过最大利用内存处理数据的方式,大大改进了数据处理的响应时间,快速发展出一个较为完备的生态系统。另外,大量日志数据都存放在HDFS中,如何提高数据处理性能,支持实时查询功能则成为了不少开源数据软件的核心目标。例如Hive利用MapReduce作为计算引擎,Presto自己开发计算引擎,Druid使用自己开发索引和计算引擎等,都是为了一个目标:处理更多数据,获取更高性能。
为了全面了解分类数据分析软件,我们按照以下几个分类来介绍。
商业数据库
开源时序数据库
开源计算框架
开源数据分析软件
开源SQL on Hadoop
云端数据分析SaaS
商用数据库软件种类繁多,但是真正能够支持TB级别以上的数据存储和分析并不太多,这里介绍几个有特点的支持大数据的商用数据库软件。
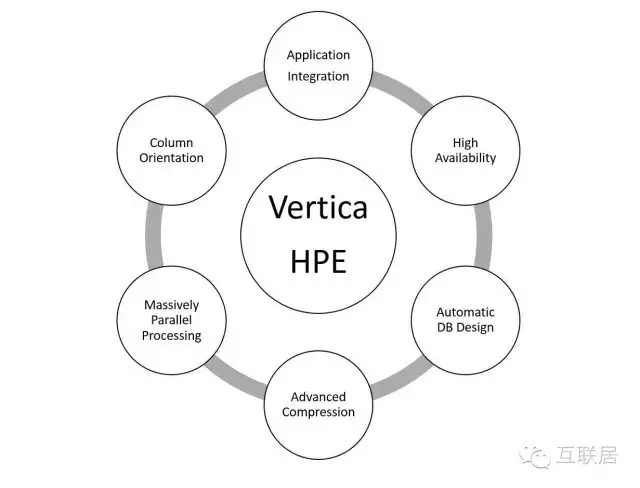
Vertica公司成立于2005年,创立者为数据库巨擘Michael Stonebraker(2014年图灵奖获得者,INGRES,PostgreSQL,VoltDB等数据库发明人)。2011年Vertica被惠普收购。Vertica软件是能提供高效数据存储和快速查询的列存储数据库实时分析平台,还支持大规模并行处理(MPP)。产品广泛应用于高端数字营销、互联网客户(比如Facebook、AOL、Twitter、 Groupon)分析处理,数据达到PB级。Facebook利用Vertica进行快速的用户数据分析,据称Facebook超过300节点(Node)和处理超过6PB数据。
Vertica有以下几个特点:
面向列的存储
灵活的压缩算法,根据数据的排序性和基数决定压缩算法
高可用数据库和查询
MPP架构,分布式存储和任务负载,Share Nothing架构
支持标准的SQL查询,ODBC/JDBC等
支持Projection(数据投射)功能
Vertica的Projection技术,原理是将数据的某些列提取出来进行专门的存储,以加快后期的访问数据,同一个列可以在不同的Projection中。

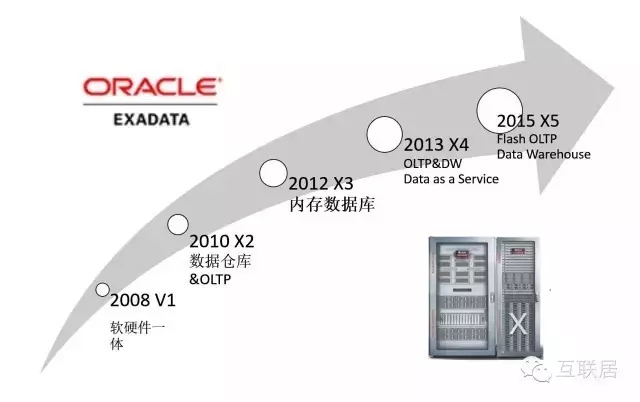
Oracle Exadata是数据库发展史上一个传奇,它是数据库软件和最新硬件的完美结合。其提供最快最可靠的数据库平台,不仅支持常规的数据库应用,也支持联机分析处理(OLAP)和数据仓库(DW)的场景。
Exadata采用了多种最新的硬件技术,例如40Gb/秒的InfiniBand网络( InfiniBand 是超高速的专用数据网络协议,主要专用硬件支持),3.2TB PCI闪存卡(每个闪存卡都配有Exadata智能缓存,X6型号)。Oracle Exadata 数据库云服务器允许将新一代服务器和存储无缝部署到现有Oracle Exadata 数据库云服务器中。它包含两套子系统,一套处理计算密集型的查询,一套处理存储密集型的查询,Exadata能够做到智能查询分配。
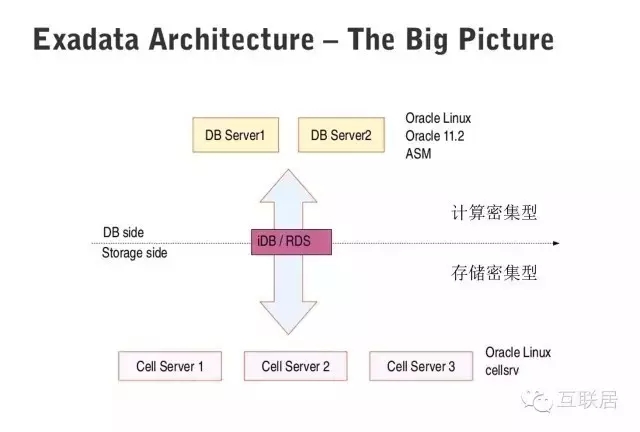
Oracle Exadata有如下几个技术特点:
采用InfiniBand高速网络 采用极速闪存方案。
全面的Oracle数据库兼容性。
针对所有数据库负载进行了优化,包括智能扫描。
Oracle Exadata支持混合列压缩。
Oracle Exadata2008年推出,软硬件一体,不断发展壮大,渐渐形成高性能数据库的代名词。
Oracle Exadata混合列存储是介于行存储和列存储之间的一个方案,主要思想是对列进行分段处理,每一段都使用列式存储放在Block中,而后按照不同的压缩策略处理。
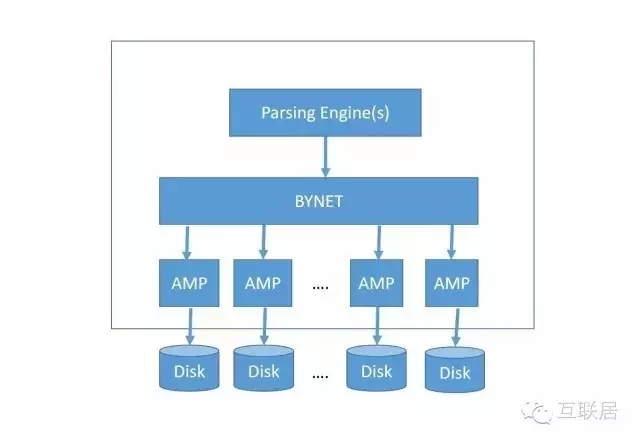
Teradata(天睿)公司专注于大数据分析、数据仓库和整合营销管理解决方案的供应商。Teredata采用纯粹的Share Nothing架构,支持MPP。对于多维度的查询更加灵活,专注与数据仓库的应用领域。下面是TereData的架构,其中PE用于查询的分析引擎,分析SQL查询,制定查询计划,聚合查询结果等;BYNET是一个高速的互联层,是一个软件和硬件结合的解决方案。
AMP(Access Module Processor)是存储和查询数据的节点,支持排序和聚合等操作。
另外Teredata还提出了一个统一的数据数据分析框架,其中包括两个核心产品,一个是Teredata数据仓库,另外是一个Teredata Aster数据分析产品。这两个产品分别走不同的路线:Teredata是传统数据仓库,满足通用的数据需求,Aster实际上是一种基于MapReduce的数据分析解决方案,可以支持更加灵活的数据结构的处理,例如非结构化数据的处理。
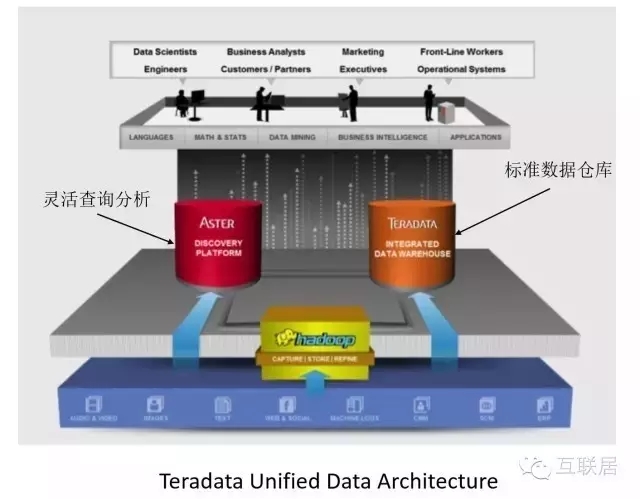
Teredata提供了一个完整的数据解决方案,包括数据仓库和MapReduce。
时序数据库用于记录在过去时间的各个数据点的信息,典型的应用是服务器的各种性能指标,例如CPU,内存使用情况等等。目前也广泛应用于各种传感器的数据收集分析工作,这些数据的收集都有一个特点,对时间的依赖非常大,每天产生的数据量都非常大,因此写入的量非常大,一般的关系数据库无法满足这些场景。因此时序数据库,在设计上需要支持高吞吐,高效数据压缩,支持历史查询,分布式部署等特点。
OpenTSDB是一个开源的时序数据库,支持存储数千亿的数据点,并提供精确查询功能。它采用Java语言编写,通过基于HBase的存储实现横向扩展。它广泛用于服务器性能的监控和度量,包括网络和服务器,传感器,IoT,金融数据的实时监控领域。OpenTSDB应用于很多互联网公司的运维系统,例如Pinterest公司有超过100个节点的部署,Yahoo!公司也有超过50节点的部署。它的设计思路是利用HBase的Key存储一些tag信息,将同一个小时数据放在一行存储,方便查询的速度。
InfluxDB是最近非常流行的一个时序数据库,由GoLang语言开发,目前社区非常活跃,它也是GoLang的一个非常成功的开源应用。其技术特点包括:支持任意数量的列、支持方便强大的查询语言、集成了数据采集、存储和可视化功能。它支持高效存储,使用高压缩比的算法等。早期设计中,存储部分使用LevelDB为存储,后来改成Time Series Merge Tree作为内部存储,支持SQL类似的查询语言。
Hadoop 是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。除了文件存储,Hadoop还有最完整的大数据生态,包括机器管理、NoSQL KeyValue存储(如HBase)、协调服务(Zookeeper等)、SQL on Hadoop(Hive)等。
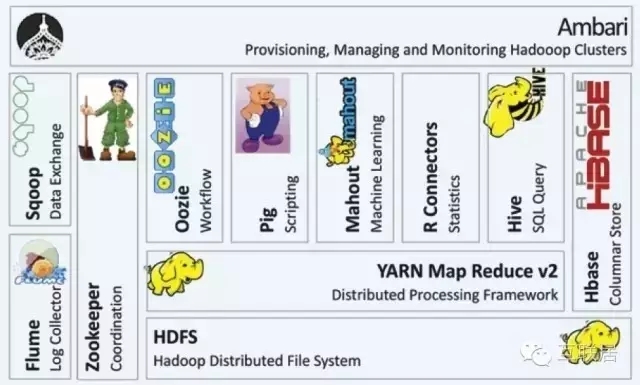
Hadoop基于可靠的分布式存储,通过MapReduce进行迭代计算,查询批量的数据。Hadoop是高吞吐的批处理系统,适合大型任务的运行,但对任务响应时间和实时性上有严格要求的需求方面Hadoop并不擅长。
Spark是UC Berkeley AMP lab开源的类Hadoop MapReduce的通用的并行计算框架,Spark同样也是基于分布式计算,拥有Hadoop MapReduce的所有优点;不同的是Spark任务的中间计算结果可以缓存在内存中,这样迭代计算时可从内存直接获取中间结果而不需要频繁读写HDFS,因此Spark运行速度更快,适用于对性能有要求的数据挖掘与数据分析的场景。
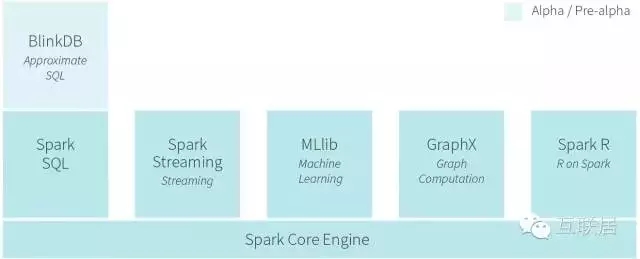
Spark是实现弹性的分布式数据集概念的计算集群系统,可以看做商业分析平台。 RDDs能复用持久化到内存中的数据,从而为迭代算法提供更快的计算速度。这对一些工作流例如机器学习格外有用,比如有些操作需要重复执行很多次才能达到结果的最终收敛。同时,Spark也提供了大量的算法用来查询和分析大量数据,其开发语言采用scala,因此直接在上面做数据处理和分析,开发成本会比较高,适合非结构化的数据查询处理。
Druid是我非常喜欢的一个开源分析数据库:简单,高效,稳定,支持大型数据集上进行实时查询的开源数据分析和存储系统。它提供了低成本,高性能,高可靠性的解决方案,整个系统支持水平扩展,管理方便。实际上,Druid的很多设计思想来源于Google的秘密分析武器PowerDrill,从功能上,和Apache开源的Dremel也有几分相似。
Druid被设计成支持PB级别数据量,现实中有数百TB级别的数据应用实例,每天处理数十亿流式事件。Druid广泛应用在互联网公司中,例如阿里,百度,腾讯,小米,爱奇艺,优酷等,特别是用户行为分析,个性化推荐的数据分析,物联网的实时数据分析,互联网广告交易分析等领域。
从架构上解释,Druid是一个典型的Lambda架构,分为实时数据流和批处理数据流。全部节点使用MySQL管理MetaData,并且使用Zookeeper管理状态等。
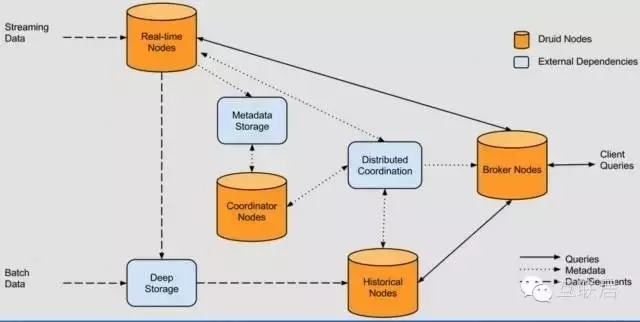
Druid的架构图显示Druid自身包含以下四类节点:
实时节点(Realtime Node):及时摄入实时数据,以及生成Segment数据文件。
历史节点(Historical Node):加载已生成好的数据文件以供数据查询。
查询节点(Broker Node):对外提供数据查询服务,并同时从实时节点与历史节点查询数据、合并后返回给调用方。
协调节点(Coordinator Node):负责历史节点的数据负载均衡,以及通过Rules管理数据的生命周期。
同时,集群还包含以下三类外部依赖:
元数据库(Metastore):存储Druid集群的原数据信息,比如segment的相关信息,一般用MySQL或PostgreSQL。
分布式协调服务(Coordination):为Druid集群提供一致性协调服务的组件,通常为Zookeeper。
数据文件存储库(DeepStorage):存放生成的Segment数据文件,并供历史节点下载。
对于单节点集群来说可以是本地磁盘,而对于分布式集群一般来说是HDFS或NFS。
从数据流转的角度来看,数据从架构图的左侧进入系统,分为实时流数据与批量数据。实时流数据会被实时节点消费,然后实时节点将生成的Segment数据文件上传到数据文件存储库;而批量数据经过Druid集群消费后(具体方法后面的章节会做介绍)会被直接上传到数据文件存储库。同时,查询节点会响应外部的查询请求,并将分别从实时节点与历史节点查询到的结果合并后返回。
如果要找一个与Druid最接近的系统,那么非LinkedIn Pinot莫属。Pinot是Linkedin公司于2015年底开源的一个分布式列式数据存储系统。Linkedin在开源界颇有盛名,大名鼎鼎的Kafka就是来源于LinkedIn,因此Pinot在推出后就备受关注和追捧。
Pinot的技术特点如下:
一个面向列式存储的数据库,支持多种压缩技术
可插入的索引技术 – SortedIndex、Bitmap Index、Inverted Index
可以根据Query和Segment元数据进行查询和执行计划的优化
从kafka的准实时数据灌入和从hadoop的批量数据灌入
类似于SQL的查询语言和各种常用聚合
支持多值字段
水平扩展和容错
在架构上,Pinot也采用了Lambda的架构,将实时数据流和批处理数据分开处理。其中Realtime Node 处理实时数据查询,Historical Nodes处理历史数据。

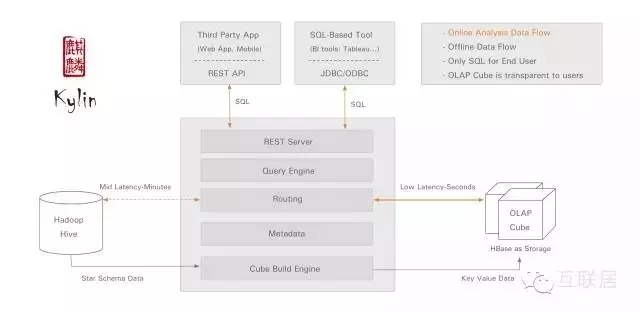
Kylin是一个Apache开源的分布式分析引擎,提供了Hadoop之上的SQL查询接口及多维分析(OLAP)能力,可以支持超大规模数据。最初由eBay公司开发并于2015年贡献至开源社区。它能在亚秒内查询巨大的Hive表。
Kylin的优势很明显,它支持标准的ANSI SQL接口,可以复用很多传统的数据集成系统,支持标准的OLAP Cube,数据查询更加方便,与大量BI工具无缝整合。另外它提供很多管理功能,例如Web管理,访问控制,支持LDAP,支持HyperLoglog的近似算法。
从技术上理解,Kylin在Hadoop Hive表上做了一层缓存,通过预计算和定期任务,把很多数据事先存储在HBase为基础的OLAP Cube中,大部分查询可以直接访问HBase拿到结果,而不需访问Hive原始数据。虽然数据缓存、预计算可以提高查询效率,另外一个方面,这种方式的缺点也很明显,查询缺乏灵活性,需要预先定义好查询的一些模式,一些表结构。目前,Kylin缺少实时数据注入的能力。Druid使用Bitmap Index作为统一的内部数据结构;Kylin使用Bitmap Index作为实时处理部分的数据结构,而使用MOLAP Cube为历史数据的数据结构。
另外,Kylin开发成员中很多开发人员来自中国,因此PMC成员中,中国人占了大部分,所以使用Kylin很容易得到很好的中文支持。Kylin的愿景就是创建一个分布式的高可扩展的OLAP引擎。
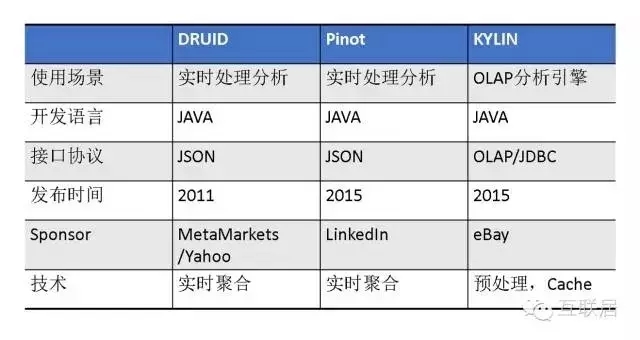
Druid,Pinot和Kylin是数据分析软件选型经常碰到的问题。Druid和Pinot解决的业务问题非常类似。Pinot架构设计比较规范,系统也比较复杂一些,由于开源时间短,社区的支持力度弱于Druid。Druid的设计轻巧,代码库也比较容易懂,支持比较灵活的功能增强。Kylin的最大优势是支持SQL访问,可以兼容传统的BI工具和报表系统,性能上没有太大优势。
下面是这几个软件的简单比较:
Dremel 是Google 的“交互式”数据分析系统。可以组建成规模上千的集群,处理PB级别的数据。由于Map Reduce的实时性缺陷,Google开发了Dremel将处理时间缩短到秒级,作为Map Reduce的有力补充。Dremel作为Google BigQuery的Report引擎,获得了很大的成功。
Dremel 支持上千台机器的集群部署,处理PB级别的数据,可以对于网状数据的只读数据,进行随机查询访问,帮助数据分析师提供Ad Hoc查询功能,进行深度的数据探索(Exploration)。Google开发了Dremel将处理时间缩短到秒级,它也成为Map Reduce的一个有利补充。Dremel也应用在Google Big Query的Report引擎,也非常成功。Dremel的应用如下。
抓取的网页文档的分析,主要是一些元数据
追踪Android市场的所有安装数据
谷歌产品的Crash报告
作弊(Spam)分析
谷歌分布式构建(Build)系统中的测试结果
上千万的磁盘 I/O 分析
谷歌数据中心中任务的资源分析
谷歌代码库中的Symbols和依赖分析
其他
Google公开的论文《Dremel: Interactive Analysis of WebScaleDatasets》,总体介绍了一下Dremel的设计原理。论文写于2006年,公开于2010年,Dremel为了支持Nested Data,做了很多设计的优化和权衡。
Dremel系统有以下几个主要技术特点:
Dremel是一个大规模高并发系统。举例来说,磁盘的顺序读速度在100MB/s上下,那么在1s内处理1TB数据,意味着至少需要有1万个磁盘的并发读,在如此大量的读写,需要复杂的容错设计,少量节点的读失败(或慢操作)不能影响整体操作。
Dremel支持嵌套的数据结构。互联网数据常常是非关系型的。Dremel还支持灵活的数据模型,一种嵌套(Nested)的数据模型,类似于Protocol Buffer定义的数据结构。Dremel采用列式方法存储这些数据,由于嵌套数据结构,Dremel引入了一种树状的列式存储结构,方便嵌套数据的查询。论文详细解释了嵌套数据类型的列存储,这个特性是Druid缺少的,实现也是非常复杂的。
Dremel采用层级的执行引擎。Dremel在执行过程中,SQL查询输入会转化成执行计划,并发处理数据。和MapReduce一样,Dremel也需要和数据运行在一起,将计算移动到数据上面。所以它需要GFS这样的文件系统作为存储层。在设计之初,Dremel并非是MapReduce的替代品,它只是可以执行非常快的分析,在使用的时候,常常用它来处理MapReduce的结果集或者用来建立分析原型。
在使用Dremel时,工程师需要通过Map Reduce将数据导入到Dremel,可以通过定期的MapReduce的定时任务完成导入。在数据的实时性方面,论文并没有讨论太多。
Apache Drill 通过开源方式实现了 Google's Dremel。Apache Drill的架构,整个思想还是通过优化查询引擎,进行快速全表扫描,以快速返回结果。

Apache Drill 在基于 SQL 的数据分析和商业智能(BI)上引入了 JSON 文件模型,这使得用户能查询固定架构,支持各种格式和数据存储中的模式无关(schema-free)数据。该体系架构中关系查询引擎和数据库的构建是有先决条件的,即假设所有数据都有一个简单的静态架构。
Apache Drill 的架构是独一无二的。它是唯一一个支持复杂和无模式数据的柱状执行引擎(columnar execution engine),也是唯一一个能在查询执行期间进行数据驱动查询(和重新编译,也称之为 schema discovery)的执行引擎(execution engine)。这些独一无二的性能使得 Apache Drill 在 JSON 文件模式下能实现记录断点性能(record-breaking performance)。该项目将会创建出开源版本的谷歌Dremel Hadoop工具(谷歌使用该工具来为Hadoop数据分析工具的互联网应用提速)。而“Drill”将有助于Hadoop用户实现更快查询海量数据集的目的。
目前,Drill已经完成的需求和架构设计。总共分为以下四个组件:
Query language:类似Google BigQuery的查询语言,支持嵌套模型,名为DrQL。
Low-lantency distribute execution engine:执行引擎,可以支持大规模扩展和容错,并运行在上万台机器上计算数以PB的数据。
Nested data format:嵌套数据模型,和Dremel类似。也支持CSV,JSON,YAML之类的模型。这样执行引擎就可以支持更多的数据类型。
Scalable data source: 支持多种数据源,现阶段以Hadoop为数据源。
Elasticsearch是Elastic公司推出的一个基于Lucene的分布式搜索服务系统,它是一个高可靠、可扩展、分布式的全文搜索引擎,下面简称ES,提供了方便的RESTful web接口。ES采用Java语言开发,并作为Apache许可条款下的开放源码发布,它是流行的企业搜索引擎。与之类似的软件还有Solr,两个软件有一定的相似性。
ES在前几年的定位一直是文本的倒排索引引擎,用于文本搜索的场景。最近几年,Elastic公司将ES用于日志分析和数据的可视化,慢慢转成一个数据分析平台。它能够提供类似于OLAP的一些简单的Count ,Group by 功能。另外,套件中内置的Kibana可视化工具提供了出色的交互界面,可以对接常用的仪表盘(Dashboard)功能。因此,在一些数据量不大,需要文本搜索的场景下,直接使用Elaticsearch作为简单的数据分析平台也是快速的解决方案。
Elastic主推ELK产品,它是一个提供数据分析功能的套装,包括LogStash:数据收集、ES:数据索引和 Kibana:可视化表现。
ES内部使用了Lucence的倒排索引,每个Term后面都关联了相关的文档ID列表,这种结构比较适合基数较大的列,比如人名,单词等。Elasticsearch支持灵活的数据输入,支持无固定格式(Schema Free)的数据输入,随时增加索引。
相比Druid,Elaticsearch对于基数大的列能够提供完美的索引方案,例如文本。Elasticsearch也提供了实时的数据注入功能,但是性能比Druid要慢很多,应为它的索引过程更加复杂。另外一个显著不同,ES是Schema Free的,也就是说无需定义Schema,就可以直接插入Json数据,进行索引,而且数据结构也支持数组等灵活的数据类型。Druid需要定义清楚维度和指标列。另外一个很大区别,ES会保持元素的文档数据,而Druid在按照时间粒度数据聚合后,原始数据将会丢弃,因此无法找回具体的某一数据行。
最近几年,ES一直在增加数据分析的能力,包括各种聚合查询等,性能提升也很快。如果数据规模不大的情况下,ES也是非常不错的选择。Druid更善于处理更大规模,实时性更强的数据。
Hadoop生态发展了多年,越来越多的公司将重要的日志数据存入Hadoop的HDFS系统中,数据的持久化和可靠性得到了保证,但是如何快速挖掘出其中的价值确实很多公司的痛点。常用的分析过程有以下几种:
数据从HDFS导入到RDBMS/NoSQL
基于HDFS,写代码通过Map Reduce进行数据分析
基于HDFS,编写SQL直接访问
SQL访问内部转为Map Reduce任务
访问引擎直接访问HDFS文件系统
接下来,我们来看看简单的SQL查询是如何访问HDFS的。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将sql语句转换为Map Reduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的Map Reduce统计,不必开发专门的Map Reduce应用,十分适合数据仓库的统计分析。 Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop Map Reduce 的作业执行模型,整个查询过程也比较慢,不适合实时的数据分析。
几乎所有的Hadoop环境都会配置Hive的应用,虽然Hive易用,但内部的Map Reduce操作还是带来非常慢的查询体验。所有尝试Hive的公司,机会都会转型到Impala的应用。
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,使用C++编写,通过使用与商用MPP类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。 Impala使用的列存储格式是Parquet。Parquet实现了Dremel中的列存储,未来还将支持 Hive并添加字典编码、游程编码等功能。 在Cloudera的测试中,Impala的查询效率比Hive有数量级的提升,因为Impala省去了Map Reduce的过程,减少了终结结果落盘的问题。

Presto出生名门,来自于Facebook,从出生起就收到关注。它是用于大数据的一个分布式SQL查询引擎,系统主要是Java编写。Presto是一个分布式SQL查询引擎,它被设计用于专门进行高速、实时的数据分析。它支持标准的ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。下图展现了简化的Presto系统架构。
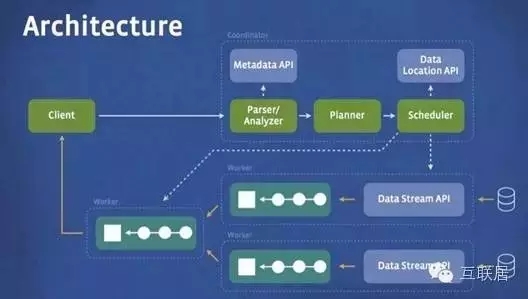
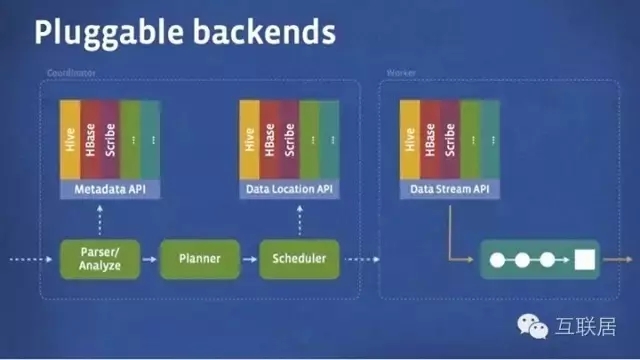
Presto的运行模型和Hive或MapReduce有着本质的区别。Hive将查询翻译成多阶段的MapReduce任务, 一个接着一个地运行。每一个任务从磁盘上读取输入数据并且将中间结果输出到磁盘上。然而Presto引擎没有使用Map Reduce。它使用了一个定制的查询和执行引擎和响应的操作符来支持SQL的语法。除了改进的调度算法之外,所有的数据处理都是在内存中进行的。通过软件的优化,形成处理的流水线,以避免不必要的磁盘读写和额外的延迟。这种流水线式的执行模型会在同一时间运行多个数据处理段,一旦数据可用的时候就会将数据从一个处理段传入到下一个处理段。这样的方式会大大的减少各种查询的端到端响应时间。
Amazon Redshift 是一种快速、完全托管的 PB 级数据仓库,可方便你使用现有的商业智能工具以一种经济的方式轻松分析所有数据。 Amazon Redshift 使用列存储技术改善 I/O 效率并跨过多个节点平行放置查询,从而提供快速的查询性能。Amazon Redshift 提供了定制的 JDBC 和 ODBC 驱动程序,你可以从我们的控制台的“连接客户端”选项卡中进行下载,以使用各种各种大量熟悉的 SQL 客户端。你也可以使用标准的 PostgreSQL JDBC 和 ODBC 驱动程序。数据加载速度与集群大小、与 Amazon S3、Amazon DynamoDB、Amazon Elastic MapReduce、Amazon Kinesis 或任何启用 SSH 的主机的集成呈线性扩展关系。
分析型数据库(Analytic DB),是阿里巴巴自主研发的海量数据实时高并发在线分析(Realtime OLAP)云计算服务,使得您可以在毫秒级针对千亿级数据进行即时的多维分析透视和业务探索。分析型数据库对海量数据的自由计算和极速响应能力,能让用户在瞬息之间进行灵活的数据探索,快速发现数据价值,并可直接嵌入业务系统为终端客户提供分析服务。
数据分析的世界繁花似锦,虽然我们可以通过开源/商业,SaaS/私有部署等方式来分类,但是每种数据分析软件都有自己独特的定位。大部分组织,在不同的阶段会使用不同的软件解决业务的问题,但是业务对于数据分析的根本需求没有变化:更多的数据,更快的数据,更多样的数据源,更有价值的分析结果,这也是大数据的4V本质。









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒