

(点击“这里”获取单超演讲完整PPT)
讲师介绍
单超,现任唯品会大数据平台高级架构师,曾带领团队完成了唯品会的Hadoop平台上线,Greenplum数据仓库迁移,基于大数据的ETL系统开发,storm/spark实时平台管理等工作。目前致力于完善大数据离线和实时全链路监控系统,自动化大数据平台问题管理和资源管理,构建实时多维分析平台等技术方向的工作。
大家好,很高兴有机会分享一些大数据方面的思考。当集群到达一定的规模以后,不可避免会碰到一些管理上的痛点,今天我就唯品会在面对这些痛点的一些解决方法和思路,与大家交流讨论。
本次演讲主要分为四个部分:
1、唯品会大数据平台规划和现状
2、大数据中的资源管理
3、存储资源管理和计算资源管理
4、案例分享
一、唯品会大数据平台规划和现状

这是唯品会大数据平台一个中长期的规划。目标很明确,我们希望从技术上能把整个大数据做成一个包含离线计算平台、流式计算平台、模型训练平台、VRE、 DMP和多种应用的完整生态链,并且希望通过这个平台,让我们公司的分析师、开发人员可以很简易地运用起来。
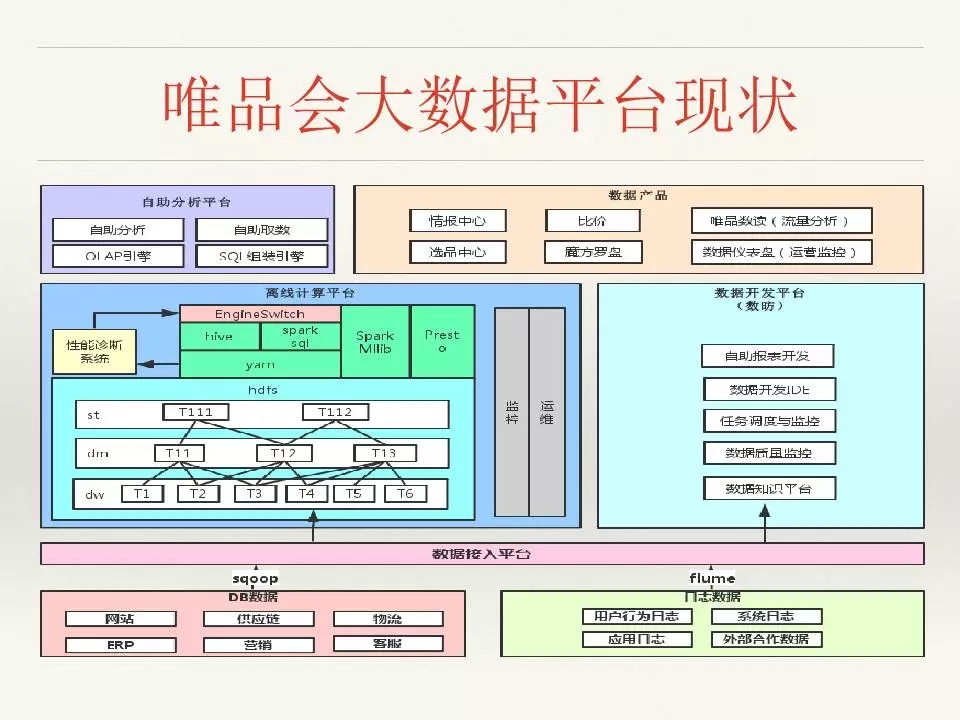
这是唯品会大数据平台的现状,总体和上面的规划图类似,重点在于离线平台的搭建,目前离线计算平台也已经做得差不多了。我们现在有一套很完整的数据开发平台,可以让公司的分析人员在不需要任何培训的情况下,方便地利用这个系统去挖掘大数据中的各种知识,为业务服务。除此之外,我们也有很多产品,看到图中数据产品一块,有情报中心、比价、选品、数读、魔方罗盘、仪表盘等。
二、大数据中的资源管理

大数据管理本身是一个很广的概念,涵盖了很多知识面。但资源管理是今年让唯品会特别难受的一个点,很多工作人员经过长时间的不眠不休,才最终把它解决掉。所以今天我会把资源管理作为重点,单独拿出来分享。

这里的“数据平台使用申请”打了引号,我想说的是这个“平台使用申请”在初创公司或者建设数据平台的初期,一般是很难做到这么完善的。因为我们需要用户提交很多要求,而且这些要求是明确的,包含了比如我需要什么样的资源,HDFS的存储、数据库、计算都需要多少,资源的数目是多少,要通过什么方式去访问。拿到这个申请以后,管理员会负责去分配同样的资源,比如HDFS中分配多少资源给你使用,Hive也是,如果我想要这样一个资源分配队列,需要明确分配给你的最大/最小资源是多少。

当然,这是一个理想的情况,现实却很骨感。因为这个行业的发展非常快,相信很多做大数据的同学,很多时候你是被业务和领导推着向上的,所以这时你的思考可能不是很完善,你会发现,你的理想状态是系统很强大、数据规范、流程规范、技术成熟、业务成熟,但现实呢?唯品会在半年前也是这种现状:模型的变更非常迅速,线上的那些代码实际上是我们的人员按小时为单位去做变更的。用户的能力参差不齐。有很多的历史包袱,唯品会的数据平台其实四年前就开始搭建了,其中有三年的历史包袱。同时,有大量的技术包袱,而且平台非常不稳定,掌控力差,有各种各样的瓶颈。整个大数据平台的分层也不是很明确。这是我们面临的现实。
那么,这种情况下,维护人员或者像我们这样的技术架构人员就会经常接到用户各种各样的投诉和问题。这里我列了一些用户经常会抱怨的问题:
这个任务昨天还好好的,为什么今天跑不出来了?
2-10倍的数据量,能撑得住吗?
怎么几千个任务都慢了?
最近磁盘使用率急剧增加,谁在用?
这个表好像不用了,我能删除掉吗?
集群要扩容吗?扩多少?
当你在没有足够能力应付的情况下,面对这些问题,你是一筹莫展的。而由此也引申出今天的核心议题——资源管控。
三、资源管控中的存储资源和计算资源
做运维、DBA,或者大数据管理人员,都需要了解一个核心,那就是资源管控。做资源管控,其实和分田到户是同样的道理。当把一块田交给你,那你就在这块田里自己玩,不要到别人的田里去掺和。通过资源管控,可以实现很多目的:
从乱序到有序。
申请和分配有据可查。
规则公开透明。
数据公开透明。
有多少资源,干多少事。
有合理的KPI和惩罚机制。
ROI,资源倾斜给回报率高的项目。

以Hadoop为例。Hadoop平台是大家都在用的一个技术框架,它有哪些资源呢?总的来说,有四个模块:计算资源、存储资源、权限资源、业务资源。今天我会重点讲右侧的计算资源和存储资源。
首先是NameNode。NameNode在Hadoop中相当于一个技术的管理节点,我们平台目前已经存储2亿的文件超过2亿的blocks,现在NameNode的内存使用在100G左右。在这么大的一个集群规模情况下,会遇到很多问题。
standby namenode updateCountForQuota缓慢影响主从一致性,进而影响切换(HDFS-6763)
standby checkpoint缓慢导致增量blockreport汇报被skip, 影响主从一致性,进而影响切换(HDFS-7097)
standby checkpoint GC导致transfer Fsimage超时失败
这里列了几个问题点,都在社区被不少人提出来,我们也确实受到了影响。
其中,最重要的是集群启动时,规模越大,你的启动时间可能越慢,除非你把这部分的代码全部进行重构。举个例子,可能我们的集群重启需要30分钟,因为需要每个block去上报。
另外,第二个瓶颈就是资源管理,叫做ResourceManager,这也是Hadoop中的一个技术组件。唯品会现在的规模并行度是高峰期可以有一千个任务在跑,每天有将近40万的任务提交到Hadoop集群里,基本24小时内时时刻刻都有人在运行。因为现在的电商,包括现在的大数据已经不是以前那种玩法,不是你晚上跑个批处理,事情就做完了。现在大家的要求是,你能不能5分钟内跑出来,所以我的批处理在上面可能是5分钟一个力度去提交的,所以这个集群对我们来说已经不是夜间作业的集群,而是24小时专机,永远不能宕机的一个服务。
https://issues.apache.org/jira/browse/YARN-3547部分解决问题
https://issues.apache.org/jira/browse/YARN-518 our patch for fairscheduler
这里也列了两个问题,就不展开讲了,关键是第二个,我们提交给社区的补丁。这些问题社区还没有解决,我们这个补丁也还没有打到任何社区的版本里去,但是如果当你的集群规模非常大,运行HDFS时肯定会遇到和我们同样的问题——分配能力有瓶颈。目前我们通过这个补丁,分配能力提升到了近10-15倍。这其实很夸张,我们一直考虑的是,现在已经有几百台节点了,那能不能变到几千台?如果分配这个问题不解决,你的瓶颈永远卡在那,即使再加机器,管理也会因为瓶颈上不去,无法提升到几千台这样的规模。

前面讲到了很多问题,怎么解决呢?开源节流。分两块,一块要提升各方面主机的性能,图中列出来的,包括了NameNode RPC性能、yarn的container assign性能,以及加机器。另外一块,就是要做各种优化管理。大家想,原先你就有几百个用户在用,当开放出去后,随着大数据应用的发展,不断有人去用,久而久之就会变成上万个用户在用。这时,你的存储是否被有效地利用呢?是否都是有价值的数据放在上面呢?你的计算是否都是有效的计算呢?还有人在用这样的一个任务吗?

给大家看一下我们在这一块的成果。理念很简单,就是做一个闭环。把整个数据仓库和Hadoop做成一个闭环,大家可以看到内圈,其实就是正常开发的一个数据仓库,你会建立任务、执行、下线,这是一个循环。而外循环是从整个任务建立时就开始对它进行管理,当你任务申请好之后,你会分配到一个队列,查看你的每一个日志。存储和计算会告诉你用了多少,同时还可以做一些智能的分析。在你的任务执行完之后,可以在系统里面看到任务的整个生命周期运行情况。

基本上我们就是把整个大数据分到项目,分到人,分到数据库,分到几个任务,所有的指标都可以可视化地让你看到,也就是说,即使你只是简单地在系统里提交了一个SQL,可实际上你得到的是一个可视化、数据化的成果。你可以知道,今天我提交了多少个SQL,占用了多少资源,剩下多少文件,所有这些东西在系统里都可以看到。
这样数据分析师也能主动跟你讲,今天慢了可能是因为提交的任务太多,今天提交的任务比上周多了一倍。你也能主动地在系统里找,为什么多了一倍?什么样的任务最占用资源?整个架构闭环大大降低基本架构技术人员的工作量。而当我们所有的数据都开放给数据分析师时,他们又能通过这些数据去做一些自己的分析,这也是一个闭环的形成。对很多公司来说,通过构建闭环,这一块的工作效率将会得到很大的提升。
接下来重点讲两块资源的管理。一块是存储的资源,一块是计算的资源。

一般情况下,大家在Hadoop中都是用Hive这个数据库,它对应的是后端的一些一二三级目录等数据库和表的目录。我们要怎样获取这些数据呢?从我们的角度来说,我们也是数据分析人员,我们要做的东西和其他的分析师其实是一样的,只不过我们分析的对象是系统的性能数据。我们会想要获取各种各样的性能数据,同时,我们需要去计算这些性能数据,做多维度的各种计算,然后把它推出去给用户看。

存储资源基本上就是通过这几大块来收集,左边是获取到的各种存储的信息,文件、表、数据仓库、ETL、Hadoop的日志……第二步是把它转化为Hive里计算的文件元数据信息、表元数据信息、调度任务元数据信息、路径访问信息,最后得到的产出通过各种维度的计算,可以得到:
维度:包括分区、表、数据库、任务、业务、人、目录层级、时间等所有维度;
指标:全量、增量、趋势、平均文件大小、最大文件大小、最小文件大小、文件数目、占比等;
热度:哪些表被频繁访问?哪些表3个月没人访问,是否可以下线了?
安全:有没有敏感信息被非法访问。
通过这一系列的存储资源管理,可以把所有的关键信息收集起来。下面,讲一下这些数据的使用,这也是我们公司目前正在践行的:
容量计费
通过计费来控制资源,使存储数据完整透明。消费预警,会提前知会用户。
空间管理
自动配置生命周期管理规则;存储格式,压缩格式选择(orc+gzip);
文件管理
自动配置生命周期管理规则;小文件har归档。
控制存储的价值:一方面可以解决NN“单点”瓶颈,控制服务器的数量,降低成本。如果没有加以控制,很快你的规模就会变成几百、几千,逐渐失控。另一方面,规范数据生命周期管理,统计冷热数据的使用,区别哪些数据是能删的、哪些是能归档的、哪些是被频繁使用的,都可以通过这个手段反馈给ETL生命周期管理。

这是yarn的一个架构图。大家都知道yarn是Hadoop的一个统一的调度管理。但yarn好像把所有资源管理的事情都搞定了,我们还需要管理什么呢?实际上,还有很多没有解决的问题。

问题比较多,这里挑两个出来详细说说。
先讲一个维护人员比较关心的问题。当维护大量的机器时,判断这些机器本身是不是在正常运行其实很难。因为一个机器是不是fail其实很难去权衡,可能是硬盘有问题,或者网络、CPU有问题,但最终表现出来的都是对Hadoop集群有影响。Hadoop对机器硬件的要求其实并不高,那我们可以通过什么数据来告诉你Hadoop集群是有问题呢?很简单,所有上面跑过的任务都统计过了,我们就可以知道,跑了100个任务,失败了多少个。如果你定下指标,跑了100个,结果失败的超过了20个,这明显是不合理的,肯定需要去管理,所以这是从数据角度去反馈给运维人员,就是我告诉你这个系统是有问题的,你反回去查。
再讲一下数据倾斜。怎么知道一个任务是不是数据倾斜?一种是靠数据分析师人为的经验,另一种从技术角度,当你跑MapReduce的时候,你的MapReduce可能是100个,前面99个在一分钟内跑完,有1个跑了一个小时,这时肯定是出现倾斜了。解决这个问题也很简单,就是把数据开放给用户,通过智能的分析告诉用户任务倾斜了,至于为什么会倾斜,让用户自己通过数据去反查。
现在我们的大数据平台上每天有几十万的任务在跑,数据量也不小,每个任务都分到MapReduce里,加起来有千万级别的数据。所以为了拿到刚才讲的各种数据,就需要考虑数据的收集问题。目前我们有很多不同时间力度的收集方案,会每分钟去拿,实时去拿,也会在每个任务提交后自己主动去上报,每个ETL任务完成后也会上报。
这一部分资源怎么用呢?跟存储资源类似:
容量计费
1)通过计费来控制资源
2)存储数据完整透明
3)消费预警,提前知会用户
实时告警和自动处理
1)根据队列设置不同的规则,如运行时长、使用资源、自动发现和触发停止动作
2)通过业务注码,自动展示运行中的业务细节
数据倾斜自动识别
队列数据化运营
关于公平调度,我们有自己的一套管理原则:
尽量细化,单个业务分配单独队列。
细化和大锅饭的区别就是两个人吃一碗饭和每人分一小碗的区别。这样就可以很清楚地知道你吃了多少,你是不是还饿着,另一个人可能是浪费的。我们的管理理念基本上就是尽可能去细化,来一个新的项目我给你分一个新的独立资源。
队列分配的min/max/weight由实际业务来评估,上线初期会不断调整、观察。
min是保证的最小资源,确保优先获得。
max是业务的最大资源限制,确保不会超过。
每个队列由多个不同级别的子队列组成,子队列业务可灵活调整。
子队列大小可以基于时间动态调整:
1)白天,天任务队列缩小,小时任务队列放大;
2)夜晚,天任务队列放大,小时任务队列缩小;
3)关键任务确保队列内的最小队列保证。
四、案例分享
接下来讲一些实操的例子。

这张图,用过Hadoop的同学会比较熟悉,这是Hadoop官方提供的关于yarn实时运行监控情况。从图中可以看到你的集群到底跑了多久,和你的集群使用率。这个数据是完全实时的,也就是过时不候,没有历史时序数据,展现不够直观。那我们要如何去获取这样的表格数据呢?
一个方法就是通过Hadoop的jobhistory,获取每个application的明细执行结果。缺点是只有在任务完成后才能获取到完整信息。另一个方法是job api。通过api实时获取到所有job的基础信息,比默认rm的api提供更多字段信息,如SQL信息,但也有缺点,它获取的不是100%完整的数据,定期获取必然会丢失数据。
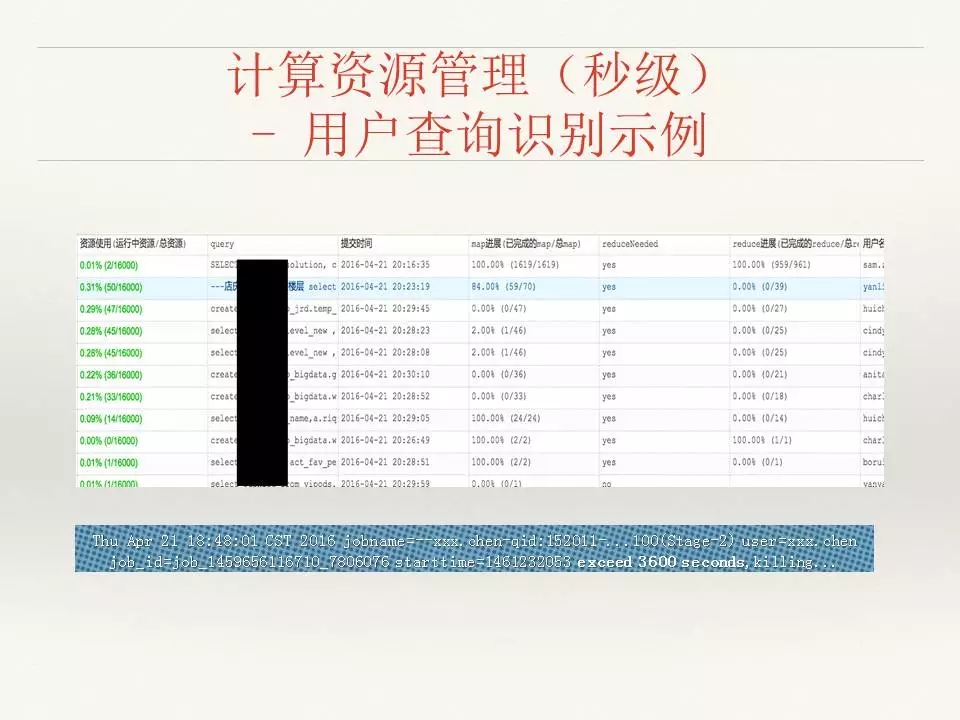
刚才提到的秒级计算资源管理, 就是通过把实时数据计算的过程监控移植到产品中,那么在这个产品中我们就可以看到一共有多少资源、你用了多少、什么样的查询、什么时候提交、进展怎样、是否需要reduce,这些都可以在界面看到。同时,我们还可以根据实时拿到的数据,检查有些任务是否跑了过长时间,有些资源使用是否超过预值了,可以把它kill掉。

分钟级的话,我们可以每分钟获取Hadoop内部jmx的信息。这里列了一些信息:

这些信息拿出来之后会做成下面这种实时监控的图,交给运维人员去使用。
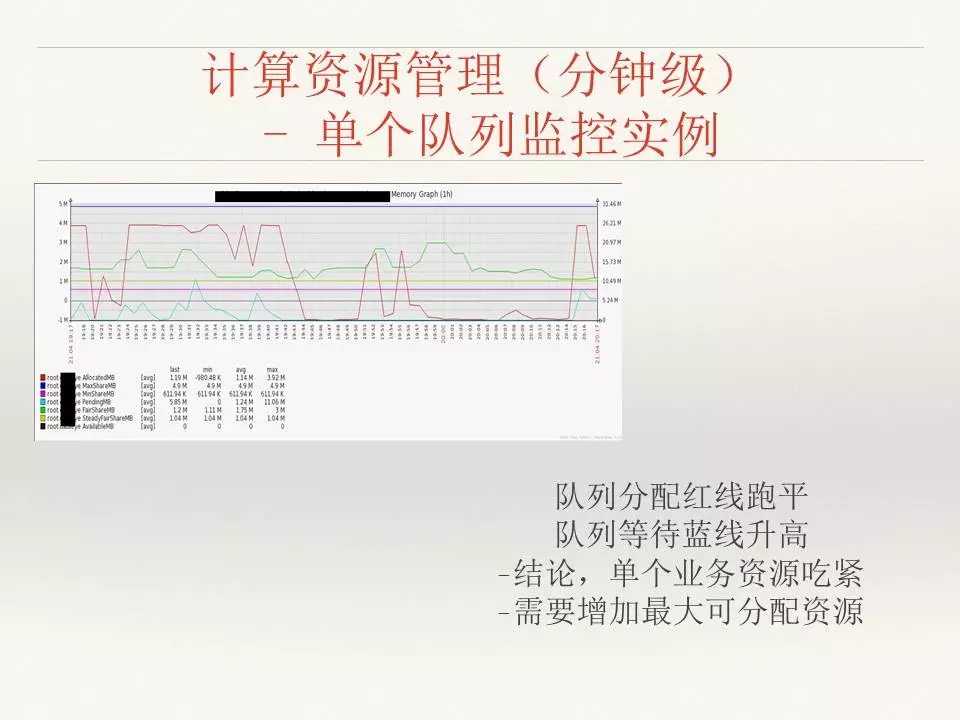
如果队列分配红线跑平,而队列等待蓝线升高,就可以得出单个业务资源吃紧,需要增加最大可分配资源。

这是另一个Bug,也是刚才我们提到的yarn分配能力出问题了。蓝色是等待的线,当等待的数据在急剧增加时,绿色的线反而在下降,这是因为出现资源分配不均,资源使用率越来越低。我们看到,整个集群在高峰期等待非常多,但集群使用率低于50%,这是很不正常的现象,说明你的集群根本没有得到合理的释放。
再简单讲一下前面这些资源管控的优化展现。一方面是队列的展现,目前我们可以看到任意时刻任何队列的使用情况,看到集群总体资源分布的情况,同时也可以查看最消耗资源的是什么任务,以及实时/历史的数据查看。


离线资源天级的场景,我们也会做一些汇总。比如:
查询集群的资源使用场景
时间/应用/队列维度的资源使用情况
核心ETL任务近期map/reduce使用情况
单个attempt的metrics指标查看,如读取超过1kw行数据的map任务
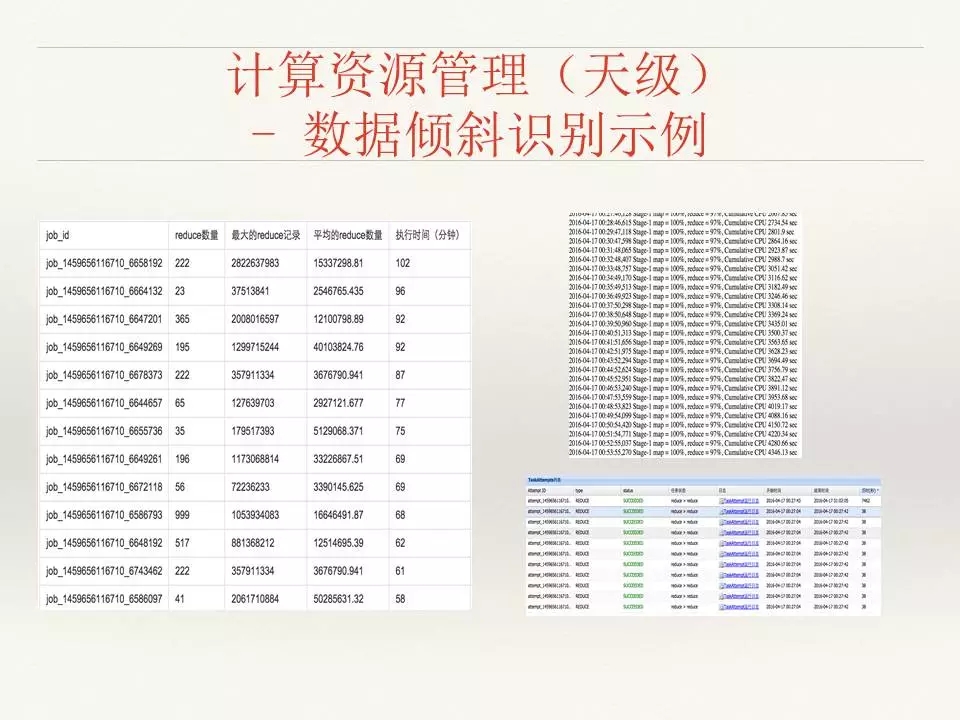
对于数据倾斜的识别,就是通过数据来分析,看所有的计算中数据量是不是一致的,会不会有1到2个计算的数据量是异常的,可以通过这种方法分析出来。这里列了一个从数据到日志、到系统的数据表。
下面是一些优化的例子。
用更少的资源计算
1)orcfile,压缩率更高,列式存储降低资源消耗
2)权衡资源和性能,基于record而不是size调整reduce数量
3)基于hll的uv估算函数,提供可增量的uv计算
用更多的资源计算,更快的释放
1)sparksql,内存需求高,复杂计算快
2)presto/impala,利用mpp框架提高计算性能
不同队列的资源使用上限限制
1)基于项目粒度的队列资源把控,个性化控制最大可提交资源
2)项目队列的最大值限制,避免单个项目失控
Reduce Slow Start
1)基于实际m/r的比值设置该参数
2)资源更快的获得和释放,整体集群受益

最后,制作资源使用报告时,我们可以把它转化、精简,保证所有集群使用的信息都可以在里面看到,并每周定时给业务发一份详细的报表和邮件就可以了。
◆ 近期热文 ◆
◆ 专家专栏 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com










230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒