
一、大数据处理的常用方法
大数据处理目前比较流行的是两种方法,一种是离线处理,一种是在线处理,基本处理架构如下:
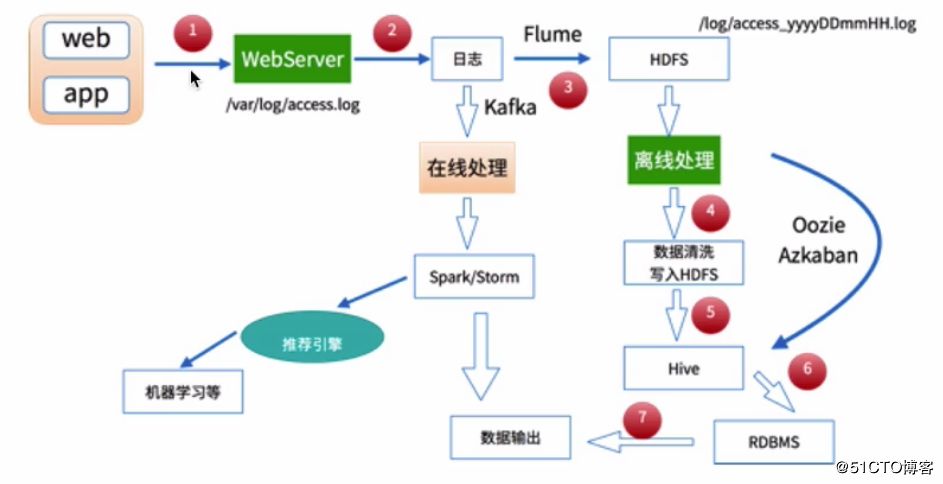
在互联网应用中,不管是哪一种处理方式,其基本的数据来源都是日志数据,例如对于Web应用来说,则可能是用户的访问日志、用户的点击日志等。
如果对于数据的分析结果在时间上有比较严格的要求,则可以采用在线处理的方式来对数据进行分析,如使用Spark、Storm等进行处理。比较贴切的一个例子是天猫双十一的成交额,在其展板上,我们看到交易额是实时动态进行更新的,对于这种情况,则需要采用在线处理。
当然,如果只是希望得到数据的分析结果,对处理的时间要求不严格,就可以采用离线处理的方式,比如我们可以先将日志数据采集到HDFS中,之后再进一步使用MapReduce、Hive等来对数据进行分析,这也是可行的。
本文主要分享对某个电商网站产生的用户访问日志(access.log)进行离线处理与分析的过程,基于MapReduce的处理方式,最后会统计出某一天不同省份访问该网站的UV与PV。
二、生产场景与需求
在我们的场景中,Web应用的部署是如下的架构:
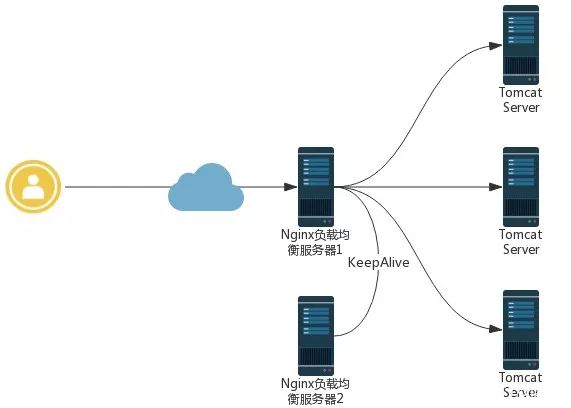
即比较典型的Nginx负载均衡+KeepAlive高可用集群架构,在每台Web服务器上,都会产生用户的访问日志,业务需求方给出的日志格式如下:

其每个字段的说明如下:
appid ip mid userid login_type request status http_referer user_agent time
其中:
appid包括:web:1000,android:1001,ios:1002,ipad:1003
mid:唯一的id此id第一次会种在浏览器的cookie里。如果存在则不再种。作为浏览器唯一标示。移动端或者pad直接取机器码。
login_type:登录状态,0未登录、1:登录用户
request:类似于此种 "GET /userList HTTP/1.1"
status:请求的状态主要有:200 ok、404 not found、408 Request Timeout、500 Internal Server Error、504 Gateway Timeout等
http_referer:请求该url的上一个url地址。
user_agent:浏览器的信息,例如:"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36"
time:时间的long格式:1451451433818。
根据给定的时间范围内的日志数据,现在业务方有统计出每个省每日访问的PV、UV的需求。
三、数据采集:获取原生数据
数据采集工作由运维人员来完成,对于用户访问日志的采集,使用的是Flume,并且会将采集的数据保存到HDFS中,其架构如下:
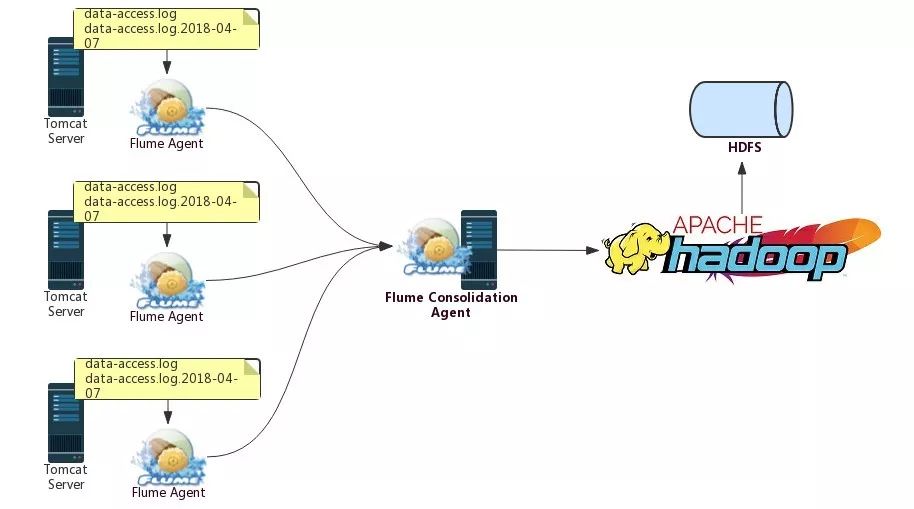
可以看到,不同的Web Server上都会部署一个Agent用于该Server上日志数据的采集,之后,不同Web Server的Flume Agent采集的日志数据会下沉到另外一个被称为Flume Consolidation Agent(聚合Agent)的Flume Agent上,该Flume Agent的数据落地方式为输出到HDFS。
在我们的HDFS中,可以查看到其采集的日志:

后面我们的工作正是要基于Flume采集到HDFS中的数据做离线处理与分析。
四、数据清洗:将不规整数据转化为规整数据
刚刚采集到HDFS中的原生数据,我们也称为不规整数据,即目前来说,该数据的格式还无法满足我们对数据处理的基本要求,需要对其进行预处理,转化为我们后面工作所需要的较为规整的数据,所以这里的数据清洗,其实指的就是对数据进行基本的预处理,以方便我们后面的统计分析,所以这一步并不是必须的,需要根据不同的业务需求来进行取舍,只是在我们的场景中需要对数据进行一定的处理。
原来的日志数据格式是如下的:
appid ip mid userid login_type request status http_referer user_agent time
其中:
appid包括:web:1000,android:1001,ios:1002,ipad:1003
mid:唯一的id此id第一次会种在浏览器的cookie里。如果存在则不再种。作为浏览器唯一标示。移动端或者pad直接取机器码。
login_type:登录状态,0未登录、1:登录用户
request:类似于此种 "GET /userList HTTP/1.1"
status:请求的状态主要有:200 ok、404 not found、408 Request Timeout、500 Internal Server Error、504 Gateway Timeout等
http_referer:请求该url的上一个url地址。
user_agent:浏览器的信息,例如:"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36"
time:时间的long格式:1451451433818。
但是如果需要按照省份来统计UV、PV,其所包含的信息还不够,我们需要对这些数据做一定的预处理,比如需要,对于其中包含的IP信息,我们需要将其对应的IP信息解析出来;为了方便我们的其它统计,我们也可以将其Request信息解析为Method、request_url、http_version等,所以按照上面的分析,我们希望预处理之后的日志数据包含如下的数据字段:
appid;
ip;
//通过ip来衍生出来的字段 province和city
province;
city;
mid;
userId;
loginType;
request;
//通过request 衍生出来的字段 method request_url http_version
method;
requestUrl;
httpVersion;
status;
httpReferer;
userAgent;
//通过userAgent衍生出来的字段,即用户的浏览器信息
browser;
time;
即在原来的基础上,我们增加了其它新的字段,如Province、City等。
我们采用MapReduce来对数据进行预处理,预处理之后的结果,我们也是保存到HDFS中,即采用如下的架构:

数据清洗的过程主要是编写MapReduce程序,而MapReduce程序的编写又分为写Mapper、Reducer、Job三个基本的过程。但是在我们这个案例中,要达到数据清洗的目的,实际上只需要Mapper就可以了,并不需要Reducer,原因很简单,我们只是预处理数据,在Mapper中就已经可以对数据进行处理了,其输出的数据并不需要进一步经过Redcuer来进行汇总处理。
所以下面就直接编写Mapper和Job的程序代码:
AccessLogCleanMapper

AccessLogCleanJob

执行MapReduce程序
将上面的mr程序打包后上传到我们的Hadoop环境中,这里,对2018-04-08这一天产生的日志数据进行清洗,执行如下命令:
yarn jar data-extract-clean-analysis-1.0-SNAPSHOT-jar-with-dependencies.jar\
cn.xpleaf.dataClean.mr.job.AccessLogCleanJob \hdfs://ns1/input/data-clean/access/2018/04/08 \hdfs://ns1/output/data-clean/access
观察其执行结果:

可以看到MapReduce Job执行成功。
上面的MapReduce程序执行成功后,可以看到在HDFS中生成的数据输出目录:

我们可以下载其中一个结果数据文件,并用Notepadd++打开查看其数据信息:

五、数据处理:统计分析规整数据
经过数据清洗之后,就得到了我们做数据的分析统计所需要的比较规整的数据,下面就可以进行数据的统计分析了,即按照业务需求,统计出某一天中每个省份的PV和UV。
我们依然是需要编写MapReduce程序,并且将数据保存到HDFS中,其架构跟前面的数据清洗是一样的:

现在我们已经得到了规整的数据,关于在于如何编写我们的MapReduce程序。
因为要统计的是每个省对应的PV和UV,PV就是点击量,UV是独立访客量,需要将省相同的数据拉取到一起,拉取到一块的这些数据每一条记录就代表了一次点击(PV + 1),这里面有同一个用户产生的数据(通过mid来唯一地标识是同一个浏览器,用mid进行去重,得到的就是UV)。
而拉取数据,可以使用Mapper来完成,对数据的统计(PV、UV的计算)则可以通过Reducer来完成,即Mapper的各个参数可以为如下:
而Reducer的各个参数可以为如下:
根据前面的分析,来编写我们的MapReduce程序。
ProvincePVAndUVMapper
package cn.xpleaf.dataClean.mr.mapper;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper<LongWritable, Text, Text(Province), Text(mid)>
* Reducer<Text(Province), Text(mid), Text(Province), Text(pv + uv)>
*/
public class ProvincePVAndUVMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
if(fields == null || fields.length != 16) {
return;
}
String province = fields[2];
String mid = fields[4];
context.write(new Text(province), new Text(mid));
}
}
ProvincePVAndUVReducer
package cn.xpleaf.dataClean.mr.reducer;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
/**
* 统计该标准化数据,产生结果
* 省 pv uv
* 这里面有同一个用户产生的数|据(通过mid来唯一地标识是同一个浏览器,用mid进行去重,得到的就是uv)
* Mapper<LongWritable, Text, Text(Province), Text(mid)>
* Reducer<Text(Province), Text(mid), Text(Province), Text(pv + uv)>
*/
public class ProvincePVAndUVReducer extends Reducer<Text, Text, Text, Text> {
private Set<String> uvSet = new HashSet<>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
long pv = 0;
uvSet.clear();
for(Text mid : values) {
pv++;
uvSet.add(mid.toString());
}
long uv = uvSet.size();
String pvAndUv = pv + "\t" + uv;
context.write(key, new Text(pvAndUv));
}
}
ProvincePVAndUVJob

执行MapReduce程序
将上面的mr程序打包后上传到我们的Hadoop环境中,这里,对前面预处理之后的数据进行统计分析,执行如下命令:
yarn jar data-extract-clean-analysis-1.0-SNAPSHOT-jar-with-dependencies.jar \
cn.xpleaf.dataClean.mr.job.ProvincePVAndUVJob \
hdfs://ns1/output/data-clean/access \
hdfs://ns1/output/pv-uv
观察其执行结果:

可以看到MapReduce Job执行成功。
上面的MapReduce程序执行成功后,可以看到在HDFS中生成的数据输出目录:
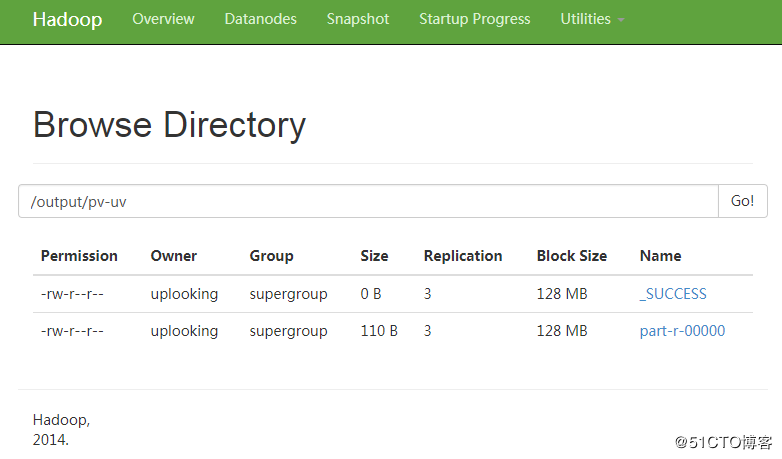
我们可以下载其结果数据文件,并用Notepadd++打开查看其数据信息:
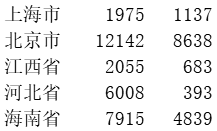
至此,就完成了一个完整的数据采集、清洗、处理的离线数据分析案例。
相关的代码我已经上传到GitHub,有兴趣可以参考一下:
https://github.com/xpleaf/data-extract-clean-analysis
作者:xpleaf
来源:http://blog.51cto.com/xpleaf/2095836
DBAplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒