
本文根据DBAplus社群第148期线上分享整理而成
讲师介绍
陈凯明,具有多年从事大数据基础架构工作经验。目前担任饿了么数据平台研发团队资深数据工程师,主要负责饿了么离线平台及底层工具开发。
饿了么BDI-大数据平台研发团队目前共有20人左右,主要负责离线&实时Infra和平台工具开发。其中6人的离线团队需要维护大数据集群规模如下:
Hadoop集群规模1300+
HDFS存量数据40+PB,Read 3.5 PB+/天,Write 500TB+/天
14W MR Job/天,10W Spark Job/天,25W Presto/天
此外还需要维护Hadoop、Spark、Hive、Presto等组件饿了么内部版本,解决公司400+大数据集群用户每天面临的各种问题。
本文主要介绍饿了么大数据团队如何通过对计算引擎入口的统一,降低用户接入门槛。如何让用户自助分析任务异常及失败原因,以及如何从集群产生的任务数据本身监控集群计算/存储资源消耗,监控集群状况,监控异常任务等。
目前在饿了么对外提供的查询引擎主要有Presto、Hive和Spark,其中Spark又有SparkThrift Server和Spark SQL两种模式,并且Kylin也在稳步试用中,Druid也正在调研中。各种计算引擎都有自身的优缺点,适用的计算场景各不相同。
从用户角度来说,普通用户对此没有较强的辨识能力,学习成本会比较高。并且当用户可以自主选择引擎执行任务时,会优先选择所谓的最快引擎,而这势必会造成引擎阻塞,或者将完全不适合的任务提交到某引擎,从而降低任务成功率。
从管理角度来说,大数据集群的入口太多,将难以实现统一管理,难以实现负载均衡、权限控制,难以掌控集群整体对外服务能力。并且当有新的计算需求需要接入,我们还需要为其部署对应的客户端环境。
用户使用多种计算引擎
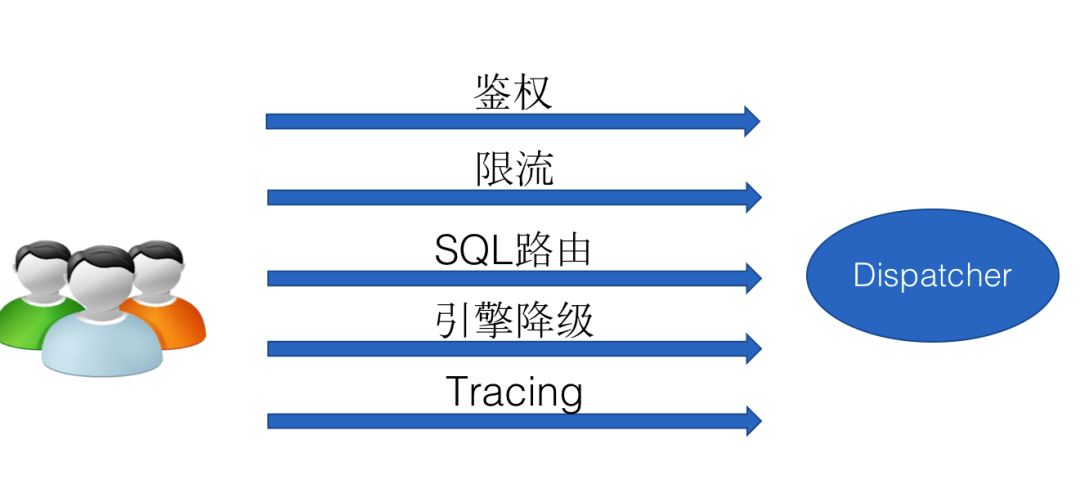
Dispatcher功能模块
用户所有任务全部通过Dispatcher提交,在Dispatcher中我们可以做到统一的鉴权,统一的任务执行情况跟踪。还可以做到执行引擎的自动路由,各执行引擎负载控制,以及通过引擎降级提高任务运行成功率。
Dispatcher的逻辑架构如下图所示:
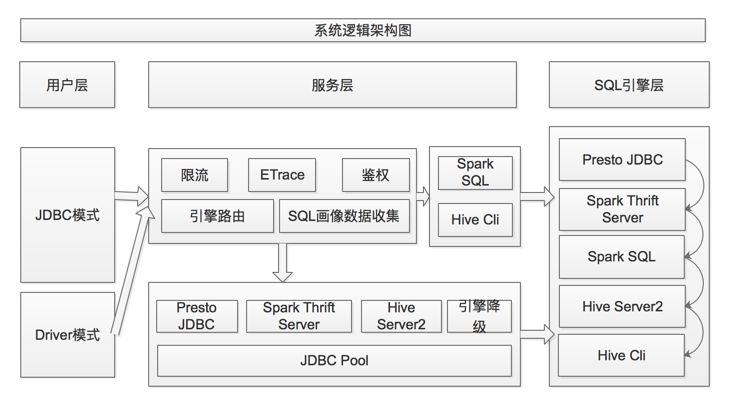
Dispatcher系统逻辑架构
目前用户可以通过JDBC模式调用Dispatcher服务,或者直接以Driver模式运行Dispatcher。Dispatcher接收到查询请求后,将会统一进行鉴权、引擎路由等操作将查询提交到对应引擎。另外,Dispatcher还有SQL转换模块,当发生从Presto引擎降级到Spark/Hive引擎时,将会通过该模块自动将Presto SQL转换成HiveQL。
通过Dispatcher对查询入口的统一,带来的好处如下:
用户接入门槛低,无需再去学习各引擎使用方法和优缺点,无需手动选择执行引擎;
部署成本低,客户端可通过JDBC方式快速接入;
统一的鉴权和监控;
降级模块提高任务成功率;
各引擎负载均衡;
引擎可扩展。
引擎可扩展主要是指当后续接入Kylin、Druid或者其他更多查询引擎时,可以做到用户无感知。由于收集到了提交到集群的所有查询,针对每一个已有查询计划,我们可以获得热度数据,知道在全部查询中哪些表被使用次数最多,哪些表经常被关联查询,哪些字段经常被聚合查询等,当后续接入Kylin时,可以通过这些数据快速建立或优化Cube。
在Dispatcher中最核心的是SQL画像模块,基本流程如下图:
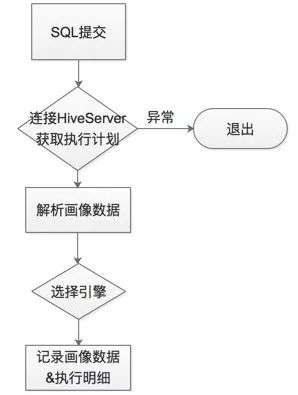
SQL路由模块
查询提交后,通过连接HiveServer对查询计划进行解析,可以获取当前查询的所有元数据信息,比如:
读入数据量
读入表/分区数
各类Join次数
关联字段多少
聚合复杂度
过滤条件
……
上述元数据信息基本上可以对每一个查询进行精准的描述,每一个查询可以通过这些维度的统计信息调度到不同引擎中。
Hive对SQL进行解析并进行逻辑执行计划优化后,将会得到优化后的Operator Tree,通过explain命令可以查看。SQL画像数据可以从这个结果收集各种不同类型的Operator操作,如下图所示:
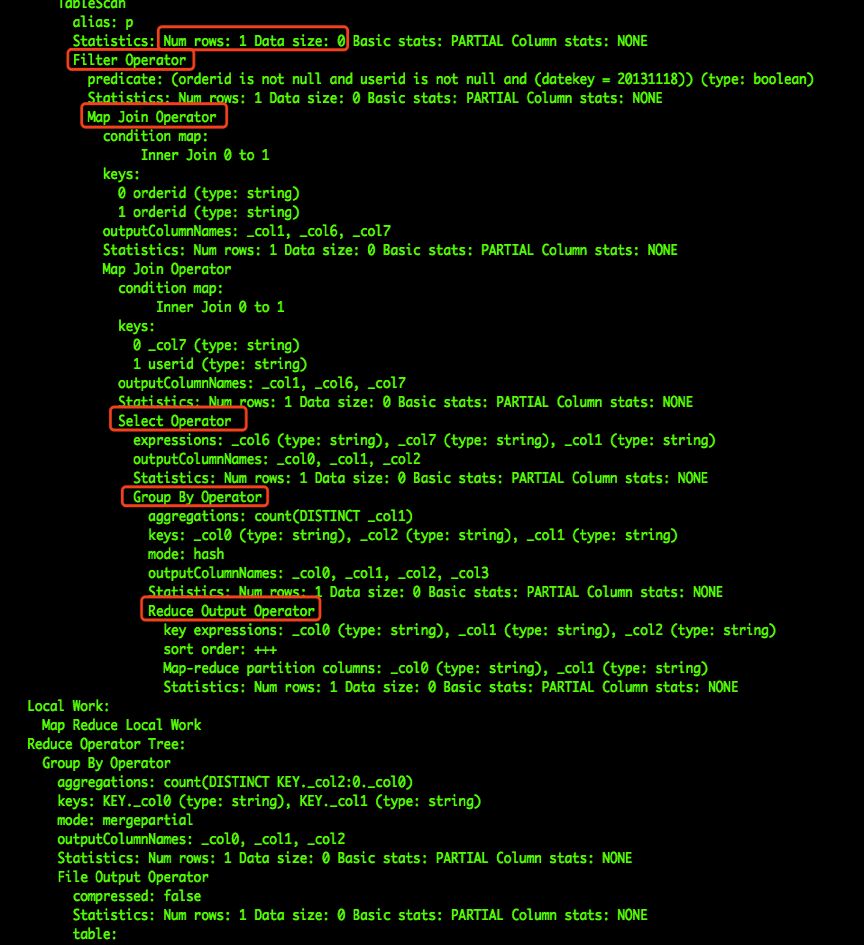
SQL解析示例
从直观的理解上我们知道,读入数据量对于引擎的选择是很重要的。比如当读入少量数据时,Presto执行性能最好,读入大量数据时Hive最稳定,而当读入中等数据量时,可以由Spark来执行。
各类计算引擎数据量-执行时间分布
在初始阶段,还可以通过读入数据量,结合Join复杂度,聚合复杂度等因素在各种计算引擎上进行测试,采用基于规则的办法进行路由。执行过程中记录好每一次查询的SQL画像数据,执行引擎,降级链路等数据。基于这些画像数据,后续可以采用比如决策树,Logistic回归,SVM等分类算法实现引擎的智能路由,目前饿了么大数据团队已经开始了这方面的尝试。
目前在饿了么的应用中,由Dispatcher统一调度的Ad Hoc查询,由于增加了预检查环节,以及失败降级环节,每天总体成功率为99.95%以上,整体PT90值为300秒左右。目前Presto承担了Ad Hoc查询的50%流量,SparkServer模式承担了40%流量。
饿了么大数据集群每天运行的Spark&MR任务25W+,这些数据详细记录了每一个Mapper/Reducer或者Spark的Task的运行情况,如果能够充分利用,将会产生巨大的价值。充分利用集群本身数据,数据驱动集群建设。这些数据不仅可以有助于集群管理人员监控集群本身的计算资源、存储资源消耗,任务性能分析,主机运行状态。还可以帮助用户自助分析任务运行失败原因,任务运行性能分析等。
饿了么大数据团队开发的Grace项目就是在这方面的一个示例。
对集群任务运行状况详细数据没有明确认识的话,很容易当出现问题时陷入困境,从监控看到集群异常后将无法继续进一步快速定位问题。
当经常有用户找你说,我的任务为什么跑失败了?我的任务为什么跑的这么慢?我的任务能调一下优先级么?不要跟我说看日志,我看不懂。我想大家内心都是崩溃的。
当监控发出NameNode异常抖动,网络飚高,block创建增加,block创建延时增大等告警时,应该如何快速定位集群运行的异常任务?
当监控发出集群中Pending的任务太多时,用户反馈任务大面积延迟时,如何快速找到问题根本原因?
当用户申请计算资源时,到底应该给他们分配多少资源?当用户申请提高任务优先级时如何用数据说话,明确优先级到底应该调到多少?当用户只管上线不管下线任务时,我们如何定位哪些任务是不再需要的?
还有,如何通过实时展示各BU计算资源消耗,指定BU中各用户计算资源消耗,占BU资源比例。以及如何从历史数据中分析各BU任务数,资源使用比例,BU内部各用户的资源消耗,各任务的资源消耗等。
以下示例展示一些Grace产出数据图表。有关BU、用户、任务级别的数据不方便展示。
1)监控队列
从下图可以方便的看到各队列最大最小资源,当前已用资源,当前运行任务数,Pending任务数,以及资源使用比例等,还可以看到这些数据的历史趋势。
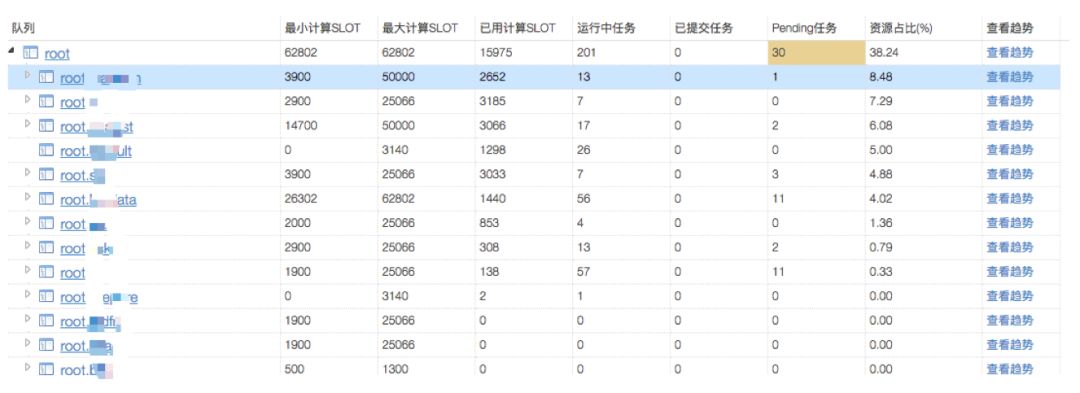
各队列任务情况
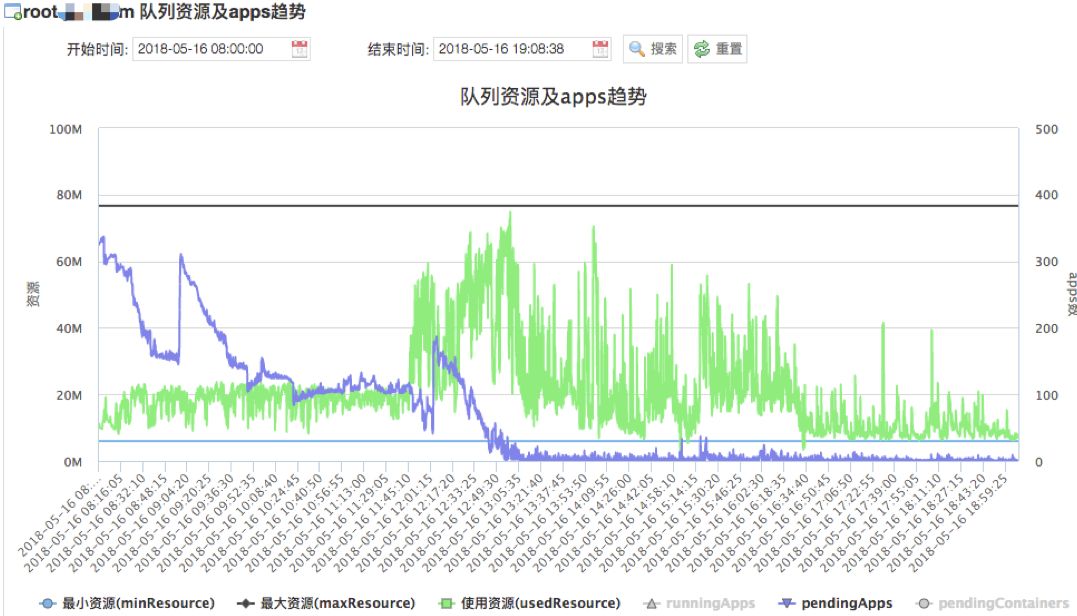
队列资源使用趋势
2)任务监控
可以查看指定队列中运行中任务的任务类型,开始时间,运行时长,消耗当前队列资源比例,以及消耗当前BU资源比例等。可快速定位计算资源消耗多并且运行时间长的任务,快速找到队列阻塞原因。
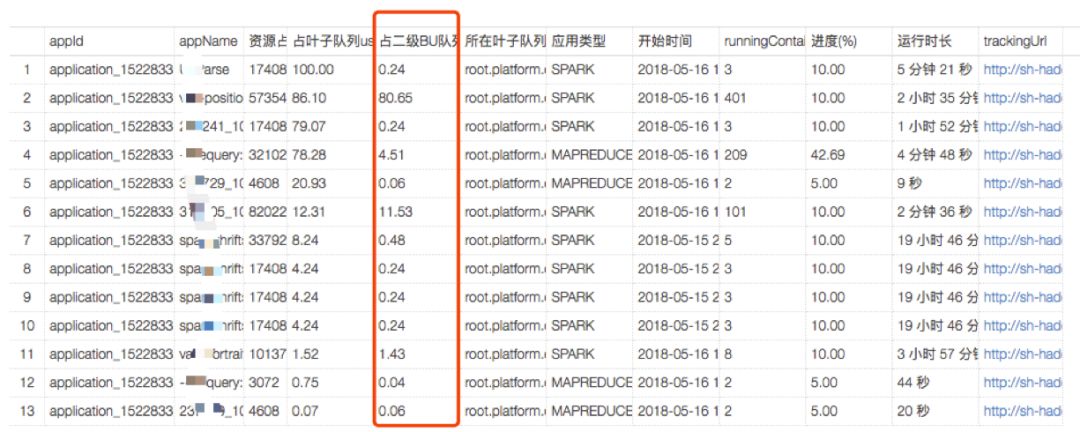
指定队列任务情况
3)监控主机失败率
可以监控集群所有主机上的Task执行失败率。已有监控体系会对主机的CPU,磁盘,内存,网络等硬件状况进行监控。这些硬件故障最直观的表现就是分配在这些有问题的主机上的任务执行缓慢或者执行失败。运行中的任务是最灵敏的反应,一旦检测到某主机失败率过高,可触发快速自动下线保障业务正常执行。后续可以结合硬件监控定位主机异常原因。
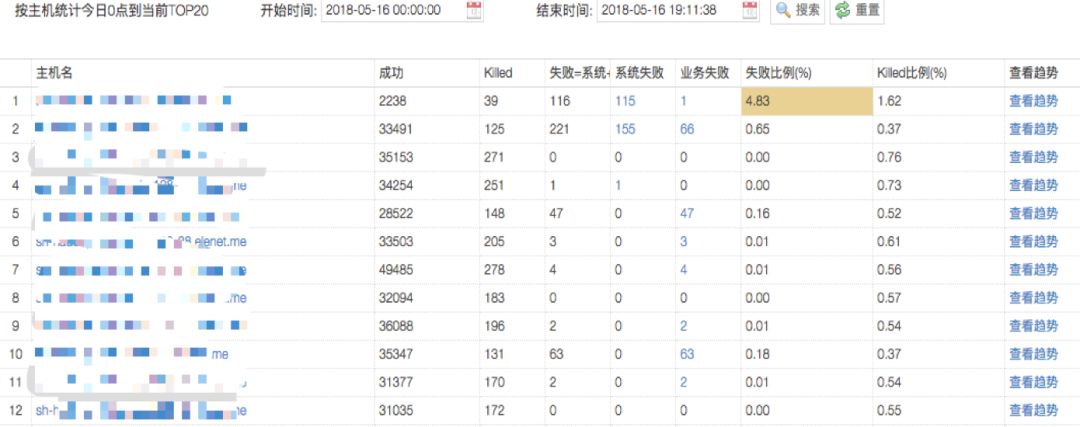
主机失败率监控
4)任务性能分析
用户可自助进行任务性能分析。
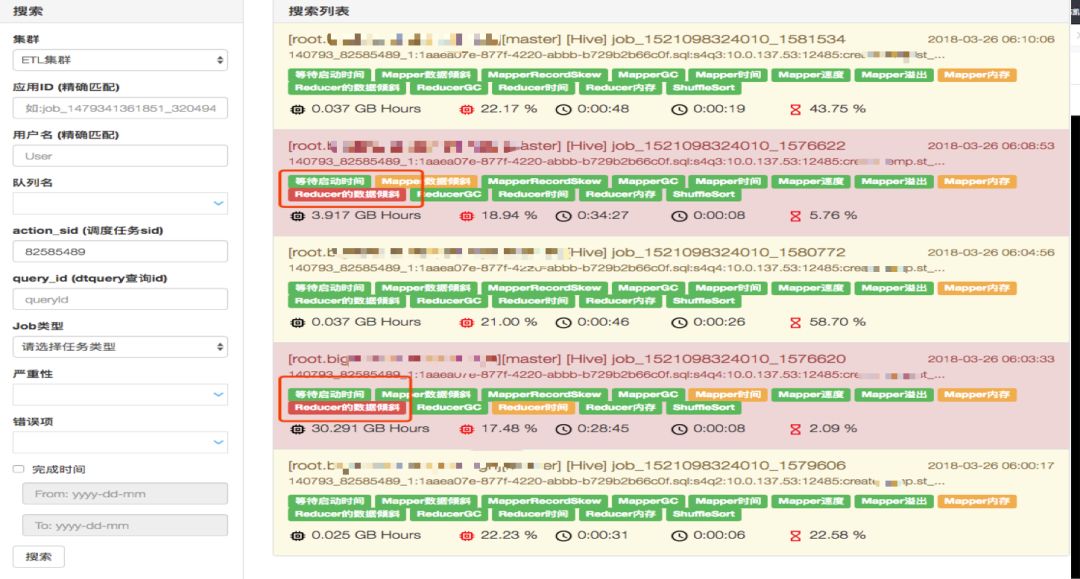
任务性能分析
并且可以根据异常项根据以下建议自助调整。
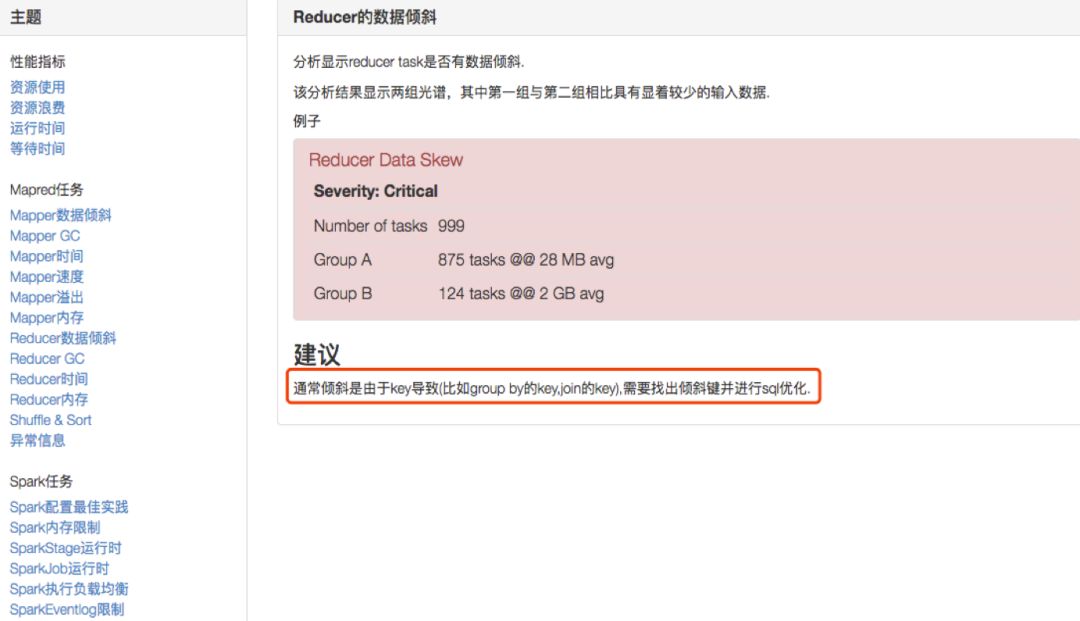
任务自助优化方案
5)任务失败原因分析
对于失败的任务,用户也可以按照以下方法快速从调度系统查看失败原因,以及对应的解决办法,饿了么大数据团队会定期收集各种典型报错信息,更新维护自助分析知识库。
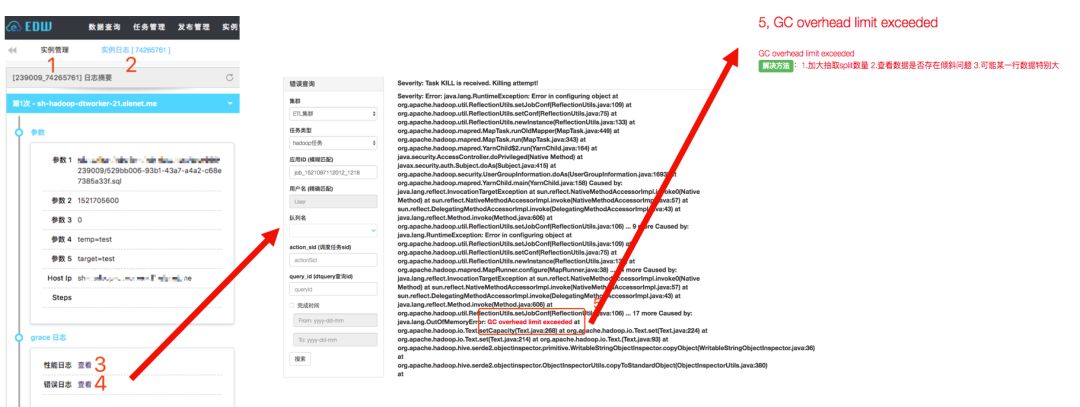
失败原因自助分析
除此之外,我们还可以实时监控每个任务的计算资源消耗GB Hours,总的读入写出数据量,Shuffle数据量等。以及运行中任务的HDFS读写数据量,HDFS操作数等。
当出现集群计算资源不足时,可快速定位消耗计算资源多的任务。当监控出现HDFS集群抖动,读写超时等异常状况时,也可通过这些数据快速定位到异常任务。
基于这些数据还可以根据各队列任务量,任务运行资源消耗时间段分布,合理优化各队列资源分配比例。
根据这些任务运行状况数据建立任务画像,监控任务资源消耗趋势,定位任务是否异常。再结合任务产出数据的访问热度,还可以反馈给调度系统动态调整任务优先级等。
上述示例中使用到的数据都是通过Grace收集的。Grace是饿了么大数据团队开发的应用,主要用于监控分析线上MR/Spark任务运行数据,监控运行中队列及任务明细及汇总数据。逻辑架构如下:
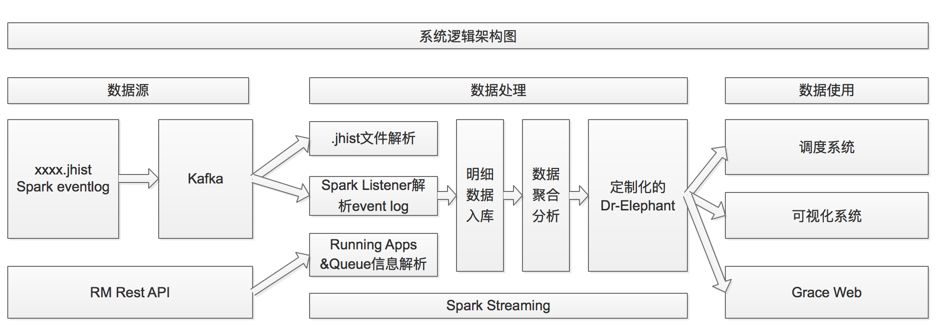
Grace逻辑架构
Grace是通过Spark Streaming实现的,通过消费Kafka中存储的已完成MR任务的jhist文件或Spark任务的eventlog路径,从HDFS对应位置获取任务运行历史数据,解析后得到MR/Spark任务的明细数据。再根据这些数据进行一定的聚合分析,得到任务级别,Job级别,Stage级别的汇总信息。最后通过定制化的Dr-Elephant系统对任务明细数据通过启发式算法进行分析,从而给用户一些直观化的优化提示。
对于Dr-Elephant,我们也做了定制化的变动,比如将其作为Grace体系的一个组件打包依赖。从单机部署服务的模式变成了分布式实时解析模式。将其数据源切换为Grace解析到的任务明细数据。增加每个任务的ActionId跟踪链路信息,优化Spark任务解析逻辑,增加新的启发式算法和新的监控指标等。
随着大数据生态体系越来越完善,越来越多背景不同的用户都将加入该生态圈,我们如何降低用户的进入门槛,方便用户快速便捷地使用大数据资源,也是需要考虑的问题。
大数据集群中运行的绝大部分任务都是业务相关,但是随着集群规模越来越大,任务规模越来越大,集群本身产生的数据也是不容忽视的。这部分数据才是真正反映集群使用详细情况的,我们需要考虑如何收集使用这部分数据,从数据角度来衡量、观察我们的集群和任务。
仅仅关注于集群整体部署、性能、稳定等方面是不够的,如何提高用户体验,充分挖掘集群本身数据,用数据促进大数据集群的建设,是本次分享的主题。
Q:能简单介绍一下调度系统吗?管理上万个任务不容易。
A:调度系统说起来挺复杂的。就提几个关键点吧,一个是任务之间的依赖,一个是血缘关系,一个是任务与实例,还有集群反压、分布式调度、底层环境统一。
其中血缘关系应该是必须的,因为当你集群规模大了之后,用户配置任务时根本无法完整地添加依赖。
通过血缘系统,对任务进行解析,当用户配置好新任务后,自动推荐前置依赖,保证任务有序运行。
Q:如何得出集群的每天读写规模?Hadoop有接口?
A:集群读写规模是通过前面介绍的Grace收集的。因为我们会分析每个mr task或者spark task的HDFS数据读写量。还包括spill到磁盘的数据量、shuffle write、shuffle read数据量,以及每个任务的GBHour信息。
其实这些数据你通过YARN或者Spark的WEB UI页面都能看到,你需要做的只是实时地去解析,收集这些数据。这也是本次分享介绍中提到的,从数据角度运维集群。
除了业务数据之外,集群本身产生的数据也很有价值。
Q:这个就是从大数据本身产出的数据来精细化运维集群吧?
A:是的。如果你也从事数据架构方向的话,可以回想一下自己每天的工作内容。我们只不过是把人肉分析变成自动化,然后再加入一些实时性。
https://m.qlchat.com/live/channel/channelPage/2000000411799213.html









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒