
作者介绍
汪涉洋,来自美国视频网站hulu的工程师,毕业于北京理工大学计算机专业,目前从事大数据基础架构方面的工作,个人知乎专栏“大数据SRE的总结”:http://dwz.cn/7ygSgc。
一、背景
在目前规模比较大的互联网公司中,总数据量能达到10PB甚至几十PB数据量的公司,我认为中国已经有超过了20家了。而在这些公司中,也有很多家公司的日数据增长达到100TB+了。
所以我们每天都要观察集群的数据增长,观察是否有哪一天、哪个路径增长过猛了,是否增长了很多垃圾数据;继续深挖下去,看看是不是可以删掉无用的数据。
此外我们还要做“容量预估“,把未来的数据增长规划出来,主要是依靠数据增长斜率计算出未来一个季度后的数据量,再把机器采购需求汇报出去。
在上一篇《基于FsImage的HDFS数据深度分析》(https://zhuanlan.zhihu.com/p/32203951)中,我们创建了基于Fsimage的HDFS数据分析仓库,并创建了一些分析图表,比如“HDFS增长趋势图”,充分地解决了发现“数据增长异常”的问题。
今天,我们会探讨以下4个问题:
怎样观察“数据增长”
怎样治理“数据过快增长”
怎样清理“无用的冷数据”
怎样管理“数据存活时间”
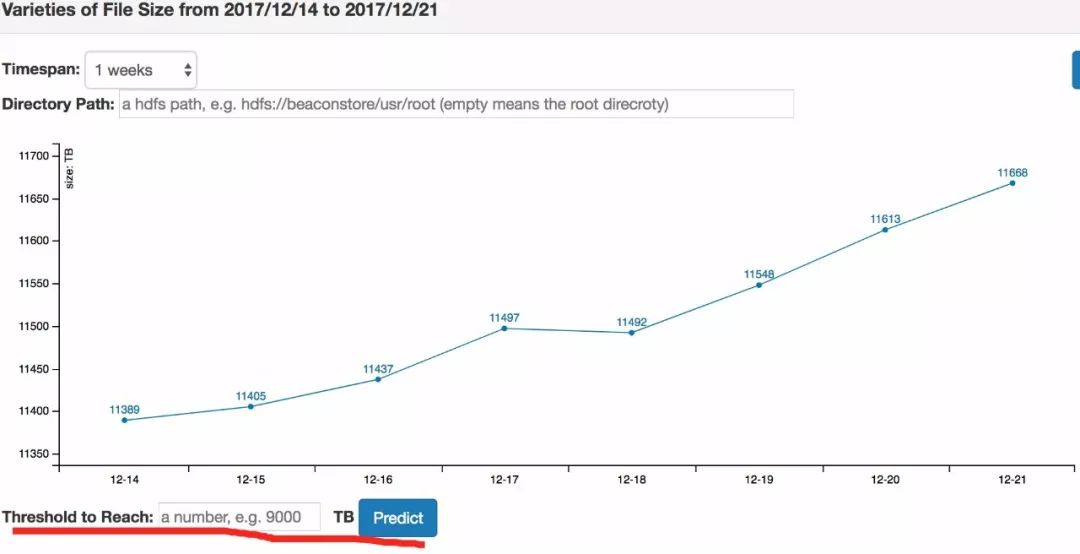
HDFS增长趋势图
先来算一笔账:当下,一台不错的Datanode机器配置,能挂12-16块盘,每块盘挂上比较大的3TB的硬盘。单台机器的存储量大致在50TB。若按每天增长100TB算,就需要2台机器;按每天增长500TB,则是10台机器。这个数字实在是Terrible !
数据疯狂增长带来的问题
1、加机器对公司的财务预算要求很高
服务器再便宜,也是钱。以一周买几十台服务器这种速度来看,即便是财务运转再好的IT公司也不愿意看到数据增长失控。
2、对集群负载的压力
Hadoop是一个可以水平扩展的技术栈,且大多数分布式系统也都是把“水平Scalable”作为主要的功能点设计, 但在工程中,是否真的能做到“无限水平扩展”呢?
首先Hadoop中有一些“Master节点”,这些 Master 节点要实时地和所有“ Slave节点 ”保持心跳通信。在集群规模较小时,由于“心跳”只做简单的网络通信,且所有的 Datanode 都互相错峰汇报“心跳”, 所以网络元数据交换并不是 Hadoop 系统水平扩张的瓶颈。
但在Hadoop集群的规模达到了大几千甚至上万台后,网络就是Namenode的瓶颈。这些心跳的RPC请求会和“用户Client”的RPC请求一起抢占Namenode有限的CPU资源。
3、对运维团队的运维压力
运维团队每周/月都要安装新机器到Hadoop集群里。做这些事情是重复又无聊的,即使自动化做得再好,也需要人来处理某些环节。脏活累活对追求“高技术密集度”的精英工程师团队,是有危害的。
那为什么我们会有这么多数据增长问题?直接删掉无用的数据不就行了吗?这个事情在公司内部很难做吗?
为什么这个问题在公司难做?
对于数据的增长,Hadoop Admin应该要对此负责的,但很多公司并没有做好这件事情,原因如下:
1、一些公司在自己的数据量级并不是很大的时候,不愿意重视这个问题。对他们而言,与其请2个人去做这个事情,花掉半年时间, 不如先把钱拿来买机器,这样的情形大多发生在 B轮/C轮的公司里。
业务增长是主要矛盾。数据每天增长5T,两个程序员半年的成本确实大于买一些机器先解燃眉之急。 等到公司业务越来越大,问题暴露得越来越严重时,公司才开始意识到严重性,这往往已经晚了,毕竟建立整套的HDFS分析系统和报表系统也不是一时半会就能搞定的。
2、受限于管理上的问题。在公司里,“业务事业部“和 “基础架构部”是平级的,那作为“基础架构部”的普通员工,哪怕是“基础架构部”的领导,都很难推动其它“业务部门”去Clean他们的数据存储。比如:
清一下没用的冷数据
给用户行为日志加一些 Data Retention策略
“业务部门”总认为自己的核心任务就是业务开发,能为公司产生更大的利益,因此在做数据清理的任务时,总把排期靠后或是设定为低优先级,总有“干不完”的开发任务,所以清理数据在公司内部很难推动。
3、Hadoop Admin 能拿出足够的证据,让“业务部门”删除冷数据吗?实际上,“业务部门”通常会这样搪塞:
/path/a 到底最后访问的时间是什么时候,凭什么说没人用了?
/path/b 有100TB,可我都是有用的数据,别人也这么大,为什么不删别人的?
你总让“我们部门”删数据,我们到底用了多少存储空间?别的组如果比我们更多呢?
带着上面这三个问题,继续往下看。
第一个问题似乎是一个很难避免的问题,需要CTO有掌舵的能力,那笔者则希望有志于利用起Hadoop技术栈的中小公司CTO在看了这篇文章后,都能增加这个意识。
第二个问题是管理上的问题。一般牵扯到制度上的变革,最好是要有Involve更高层领导参与的。多和高层提“成本”和“省钱”,少提“技术”,我认为高层会意识到这个问题的价值。
第三个问题是本文的重点,即如何摆事实、拿证据证明我们可以针对Path做数据优化呢? 哪些Path可以删掉?哪些Path应该加Data Retention 策略?
二、行为(Action)
我们需要定期进行一些行为,来保持集群的数据可控。
每日行为
每天来到公司,做这样几件事:
集群增长常规日分析
当集群“日增长有异样”时,分析具体哪个Path增长占主导
发现“异常路径“属于哪个User或Team
发送邮件给对应User/Team,给出Solution
季度行为
每个季度结束时 :
哪个Team增长最猛,统计Team日增长平均量
找到“环比”增长最猛的Team,找到本季度“新增数据最猛”的新路径,一般为一些新Hive表
发邮件给对应Team,给出Solution
要做到上述行为,我们要对每个Team,每个Path的“数据增长”都有详尽的数据支持。试想一下,在理想情况下,我们需要有哪些数据才能搞定?
针对“每日行为””,我们需要确定:
每天增长最大的文件是哪些?
针对确定的“异常日增长路径”,能查到这个路径的历史数据增长,因为要清楚“平均增长值”,才能看出“某日增长量为异常”,然后再查到其下哪个子路径贡献了最大的增长,进一步深入查找问题。
针对“季度行为”,我们需要:
1、所有“数据团队”对集群存储的使用情况,按HDFS的使用量做KPI考核;不仅了解每一个“数据团队”都有哪些“重要路径”,还需要知道这些路径的“增长状况怎么样”。
TeamA 一共使用的存储空间,占公司总量有多少?
TeamA 过去一个季度的环比增长速度如何?
TeamA 过去一个季度的绝对增长量如何?
TeamA 下的路径里,是否新建了很多新数据,比如新Hive表?是否有 Data Retention策略?
2、针对一个Team新增的“异常增长路径”,我们要能查到这个路径的历史数据增长,要知道“平均增长值”,才能看出“某日增长量为异常”,然后查到其下哪个子路径贡献了最大的增长,进一步深入查找问题。
3、针对“某些”很大的、Size很久没有变化过的Folder,我们要知道这个Folder最后的访问时间是什么时候、它超过半年没访问过的文件占比有多少、超过1年没访问过的文件有多少,然后我们才能和所属的Team联系,优先决定是否能删除它。
在前文《基于FsImage的HDFS数据深度分析》(https://zhuanlan.zhihu.com/p/32203951)中 ,我们建立了HDFS数据仓库,这相当于我们存下了HDFS每一天的快照,所以每一条Path的元数据历史问题解决了。
再来说说Team Level,每一个Team的数据,都是由一些文件夹下的数据组成的。比如“推荐系统团队”,在/hive/warehouse/reco.db下,所有的推荐相关的表数据都存在于这个下面。另外/user/reco下也存放了很多这个组的数据,这几个路径,都属于“推荐数据组”的“顶级路径”。 所有“顶级路径”的“增长聚合”,就是整个组的“数据增长”。
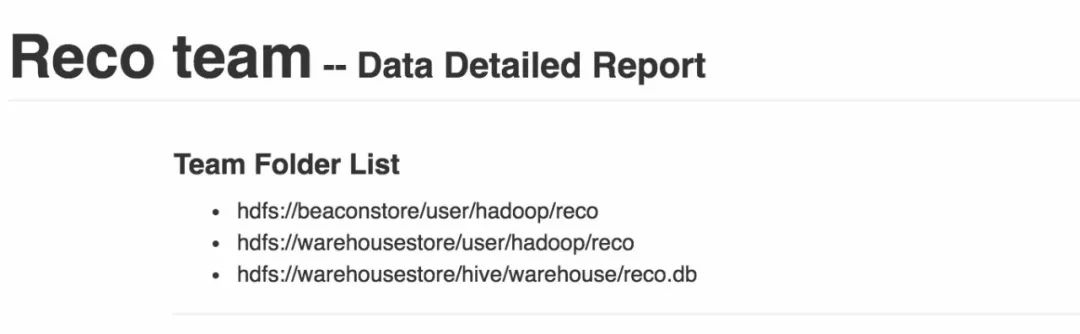
数据组的顶级路径
每个Folder聚合其下每一个文件的Last_access_time,作为最终这个Folder的Last_access_time.
这个功能对Hive表非常好用。 有些Hive表很久都没有人访问过,后面我也会详细叙述如何清理Hive表。
三、例子
接下来我将用我司的自动化运维系统中的一些报表来做解决问题的展示。
这些报表都是我们根据解决问题的方法论创建出来的,我们希望贯彻“让一切人的决策基于数据”这一宗旨。让我们判断问题、找到问题,甚至说服“数据团队”,都用Data Driven。
每日行为例子
1、查看集群每日增长,发现没什么大问题。
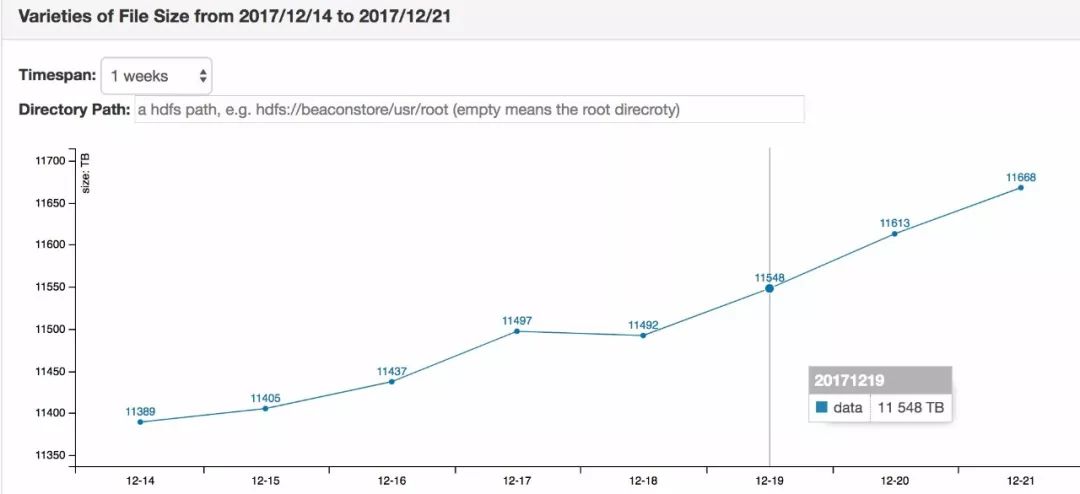
2、查看增长贡献,发现几个/User下的用户增长过猛。
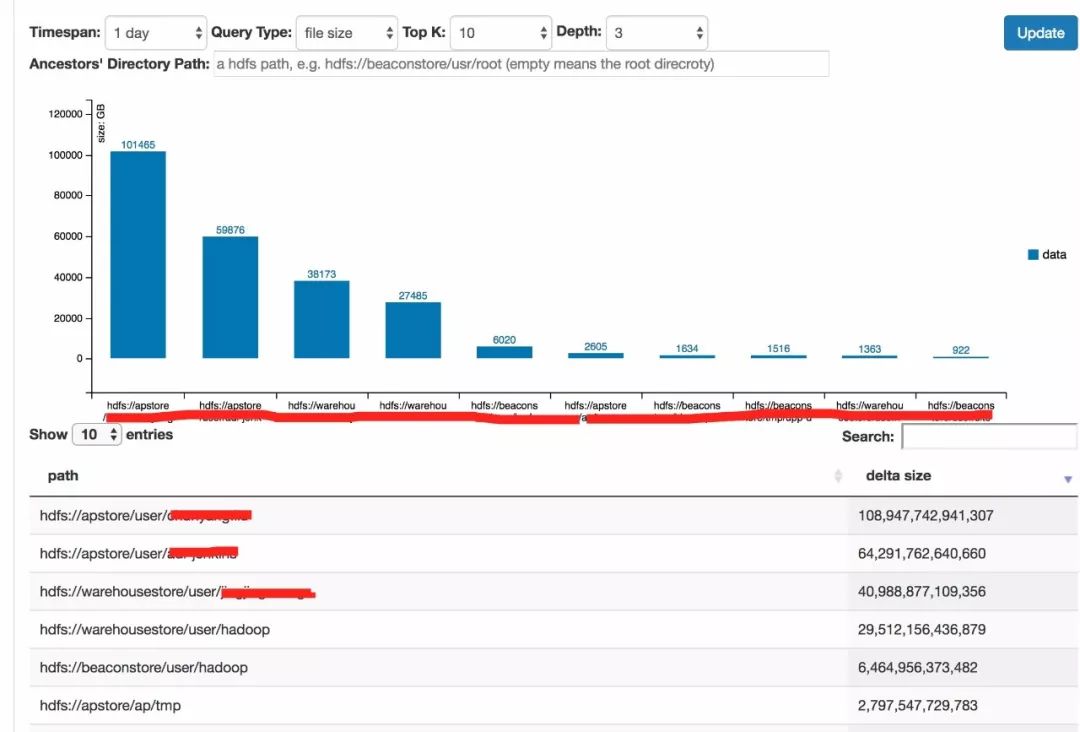
3、查看这个路径,与本路径历史增长做比较,发现昨日确实是在不正常地增长。
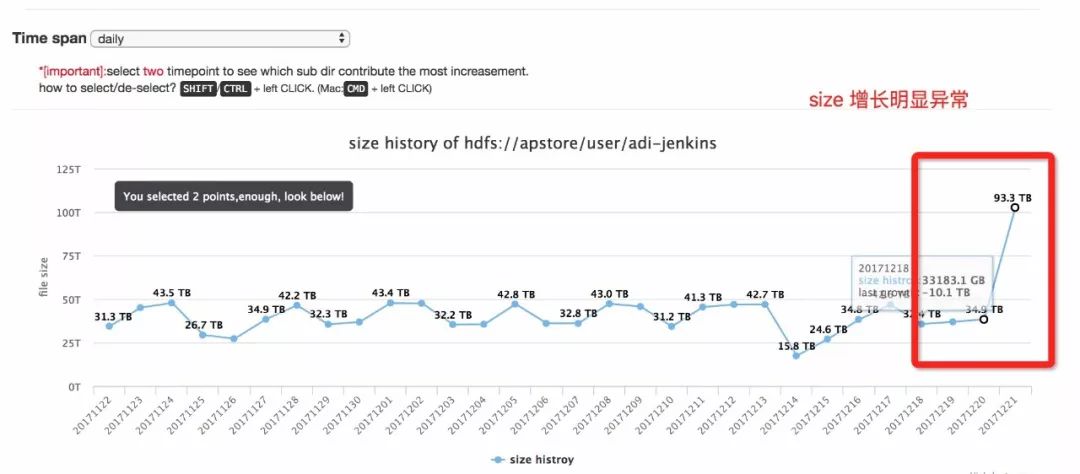
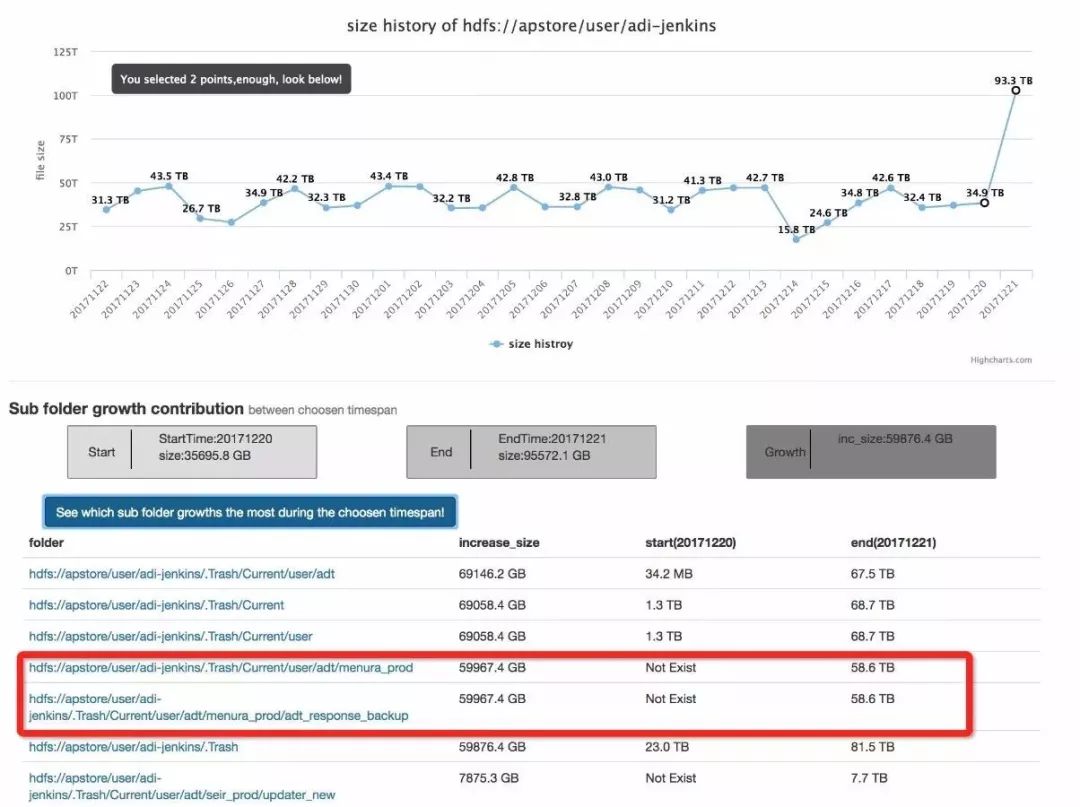
4、分析具体是什么子文件导致了这个目录的异常增长。
原来是这个用户删除了一些其它路径的大文件,划归到User目录自己的~/.Trash下了。那这就不用太担心,因为HDFS第二天会自动清理掉~/.Trash下的垃圾文件。
季度行为例子
1、分析“数据团队”季度增长量
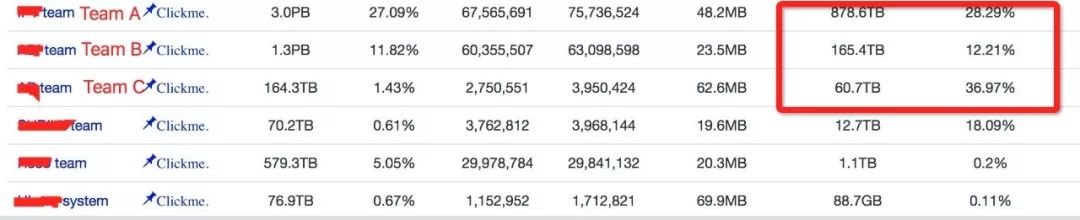
可以看到:
TeamA的数据总量很大,环比增长也很大,是首要的分析目标。
TeamB 和 TeamC 相比,虽然TeamB绝对值增量比TeamC大了很多,但还是一个数量级,但TeamC环比增速太高,很可能业务上发生了很大的变化,所以 TeamC是第二目标。
在运维人员有限的工作时间内,一定要把“精力”花在刀刃上。对一个Team的数据进行深度分析,往往要用去个把小时,一定要在单位时间上产出最大化。
2、深度分析Team数据
深度分析也是遵循“单位时间产出最大化,抓最主要矛盾”这一思想。接下来还是拿我司的“推荐“团队做例子:
这些所有的顶级路径,都代表了某种业务的“细分”顶级路径。

在每个细分“顶级路径”下,我们要观察:
哪些路径的“绝对数据量”很大,一头大象体重增长10%比一只老鼠多生一窝产生的体重多得多;
所有“第二档次数据贡献量”的路径,分别调查其“日增长量”和“环比增速”,即“增速”的相对值和绝对值。
还是拿Recoteam数据来举例子:
根据数据统计,我们分出第一轮目标和第二轮目标。
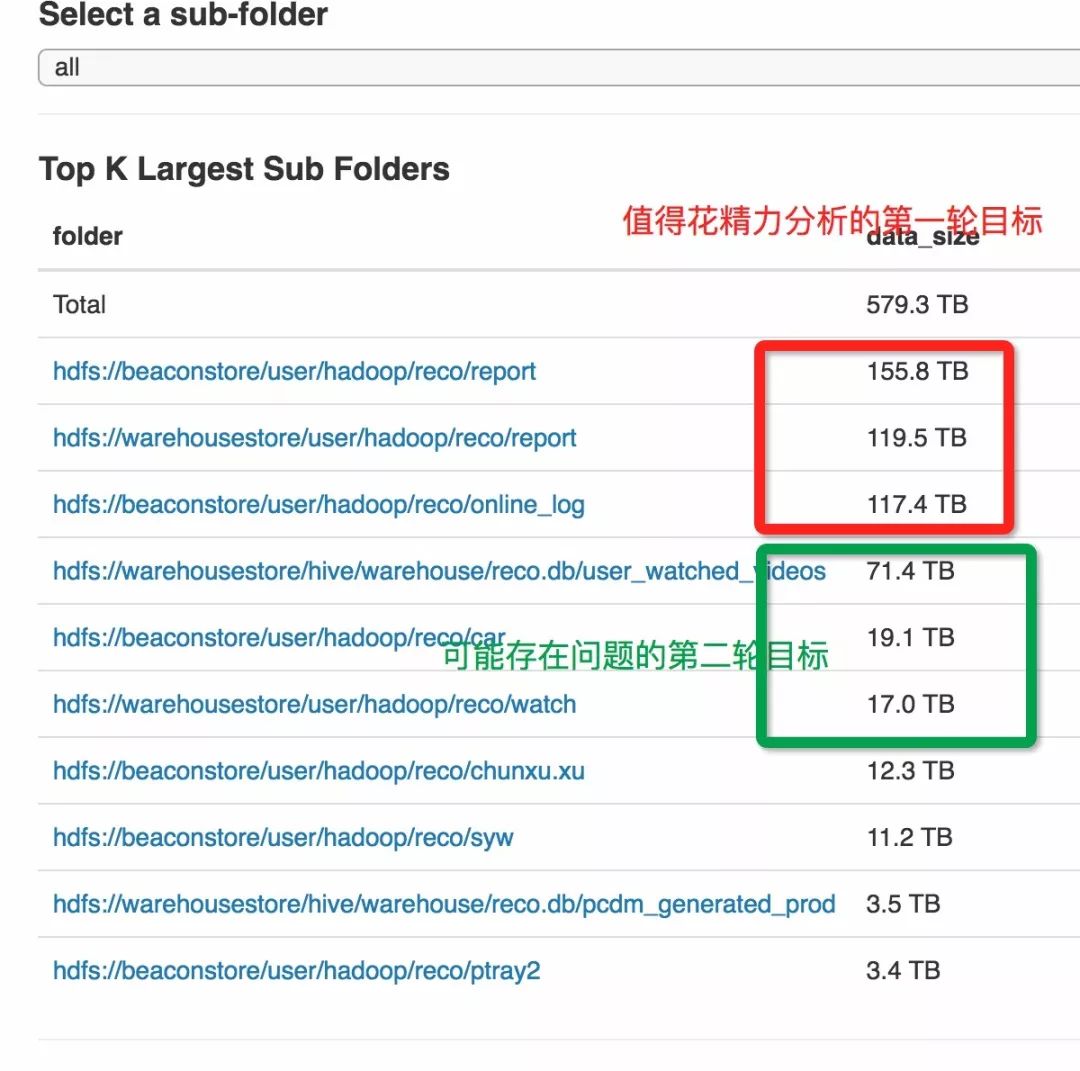
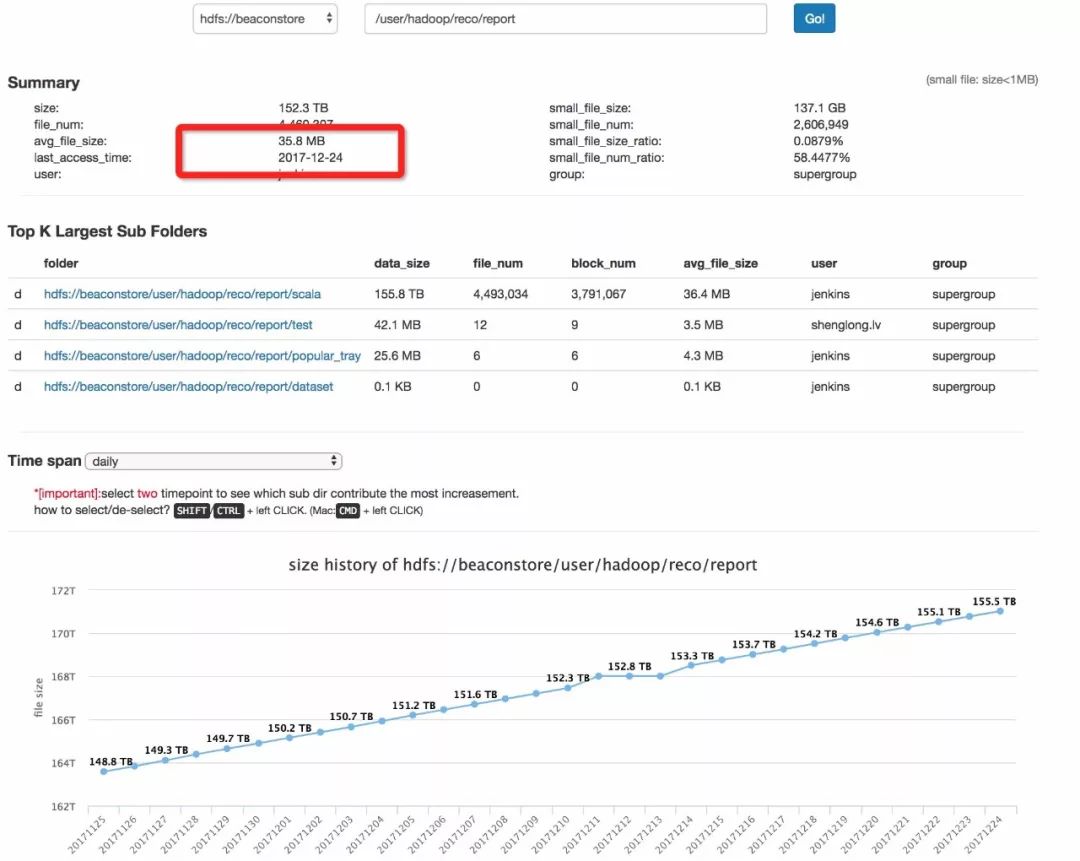
第一个路径:
hdfs://beaconstore/user/hadoop/reco/report
它的特点是每日增速固定, 但最近访问时间“很新”,且“平均文件大小”偏小。
所以策略可能是 :
“每日数据量优化”;
“减少天分区数”;
未来对“文件平均大小”做优化。因为文件数量很多,可以节省出很多内存。
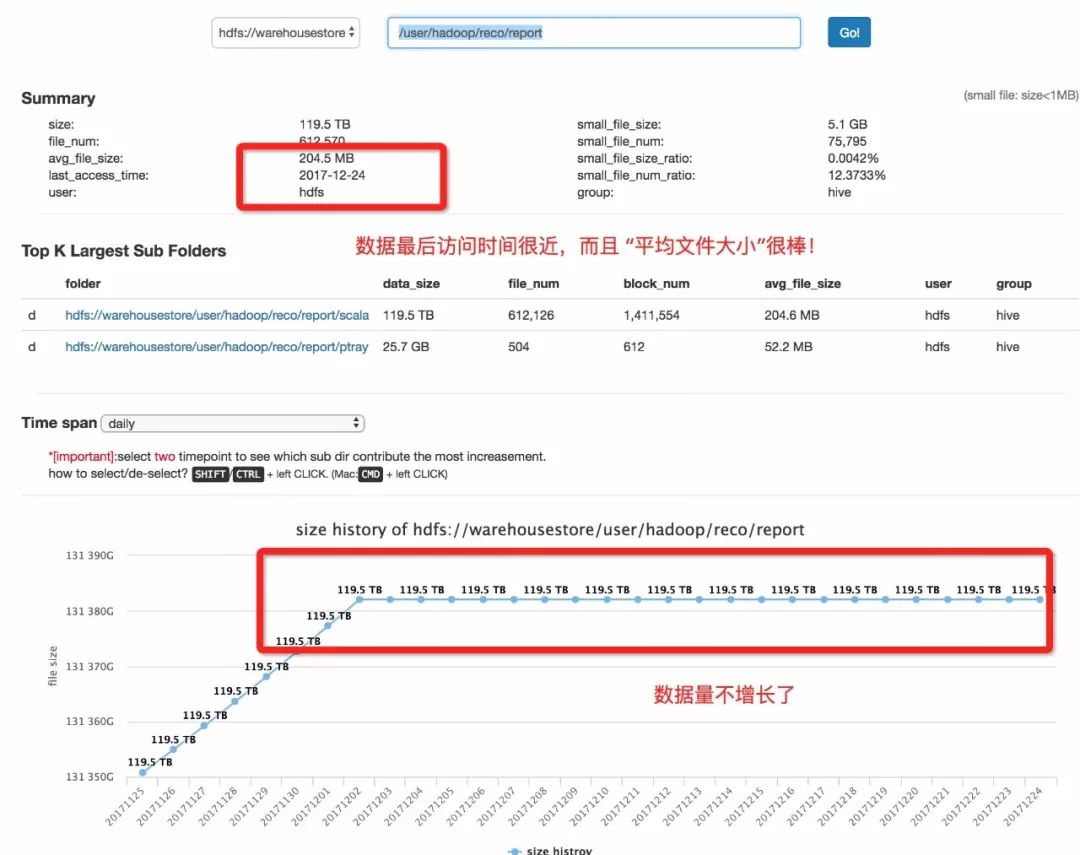
第二个路径:
hdfs://beaconstore/user/hadoop/reco/report
它的特点是已经许久不新增数据, 但最近访问时间“很新”。
所以策略可能是 :
找到哪些子数据经常访问;
删掉不访问的子数据 ;
是否有生命周期,有的话记得在未来删除。
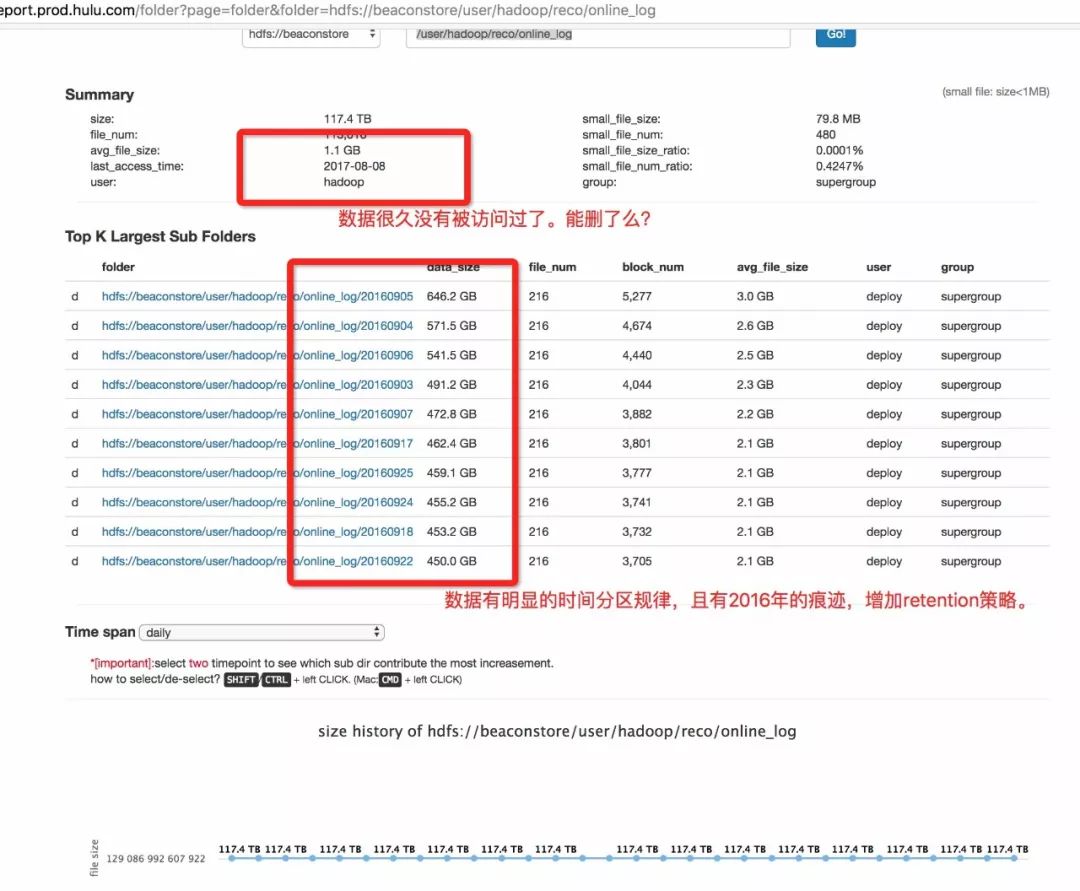
第三个路径:
hdfs://beaconstore/user/hadoop/reco/online_log
它的特点是很久很久不新增数据, 且最近访问时间“很老”。
策略是——建议删除。
可以看出,不同的HDFS路径,其存在的问题不尽相同,这真的需要具体问题具体分析。
如果通过分析“第一目标清单”,已经能够达到控制集群存储的目的,大幅降低数据存储,那么可以适当地忽略“第二目标清单”,记住那个目标“单位时间产出比”。这时可以把时间省下来做更多有意义的事情。
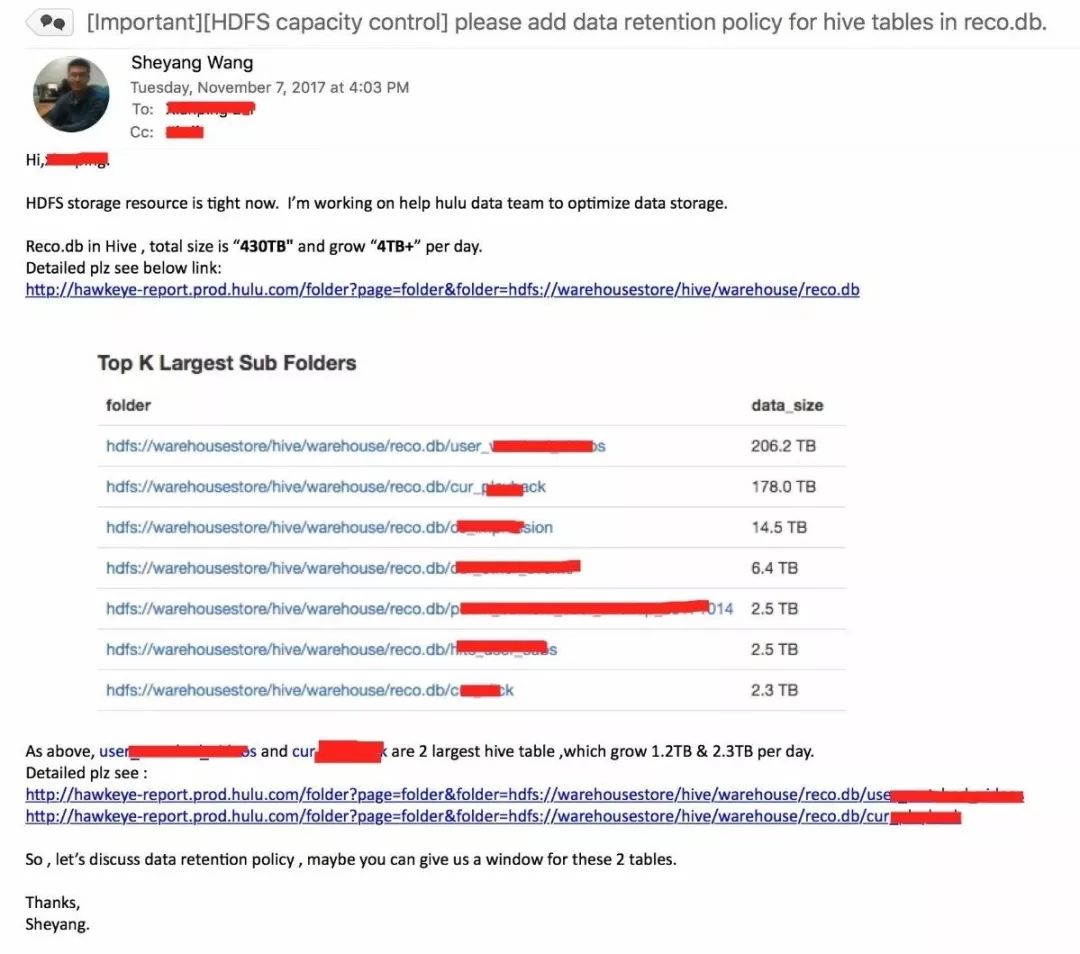
3、最后我们会出具一个Report,给相关的组发送Email,指明应该做哪些优化。
四、数据增长之Hive篇
前文在讲述治理HDFSS的数据增长问题时提到了:
每日独立“异常路径”数据增长治理
每季度数据增长过快的“异常数据Team”的深度数据治理
现在我们就把目标锁定到Hadoop的数据仓库Hive,谈谈数据增长之Hive。
方法论
笔者认为Hive的“数据增长治理”,也分为两点:
每日观察“新增Hive表”,查看“每日增速过快的”以及“总量过快的”。新增的Hive表,被限定在30天(一个月内)新创建的Hive表。Hive表的创建时间,在Hive-metastore的数据里可以得到。
每季度观察“冷Hive表”,重点抓“Size最大的,最冷的Hive表”。
找到可优化“目标Hive表后”,按照前文提及的步骤来优化Hive表背后的HDFS路径,一个控制增量,一个优化存量。
细节
1、控制增量
Hadoop管理员每天早上花时间扫一眼最近一个月新建的Hive表里有没有很大的表。
这里的“大”指的是:
30天总量达到10个TB。 这个很好理解,"月总量值"是可配的,可以随着业务增长放大。
"每天平均日增量"达到1个TB。 因为有些表的生命周期可能只有几天,日增量大的表,都要进入“待观察”列表,最好都能强制“被管控”(Data Retention 策略,TTL等)

2、优化存量
Hive表的底层数据,是存储在HDFS上的文件夹。我们可以通过使用SQL,从Hive-metastore这个MySQL数据库里,查询到Hive表的HDFS路径,Owner等元信息。
select TBL_NAME, location, owner, db.NAME from TBLS tb left join SDS s on tb.SD_ID=s.SD_ID left join DBS db on tb.DB_ID=db.DB_ID
在查找到Hive表 -》 HDFS路径的对应关系后,我们又可以根据前文 《基于FsImage的HDFS数据深度分析》所建立的HDFS文件系统数据仓库,查询到HDFS路径的“Last_access_time”,以及路径的Size,平均文件大小等元数据,这保证并确认了hive表的“最后访问时间”是可知的。
最后,Hive表的几项元信息,都会被缓存到另一张经过ETL后的的数据表Hive_meta_after_etl。这张表的结构如下:
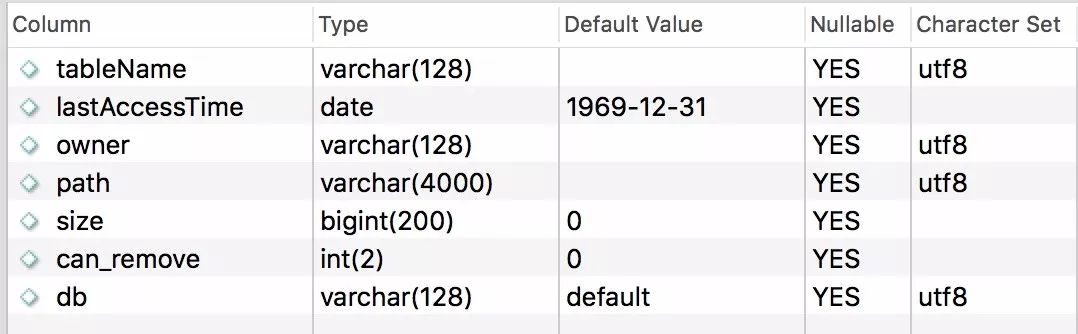
hive_meta_after_etl
有了Hive_meta_after_etl表元数据的数据库,我们就可以设计查询入口:

在选出了运维的目标Hive表后,按照前文中分析HDFS“异常路径”的方法,进行进一步分析即可。
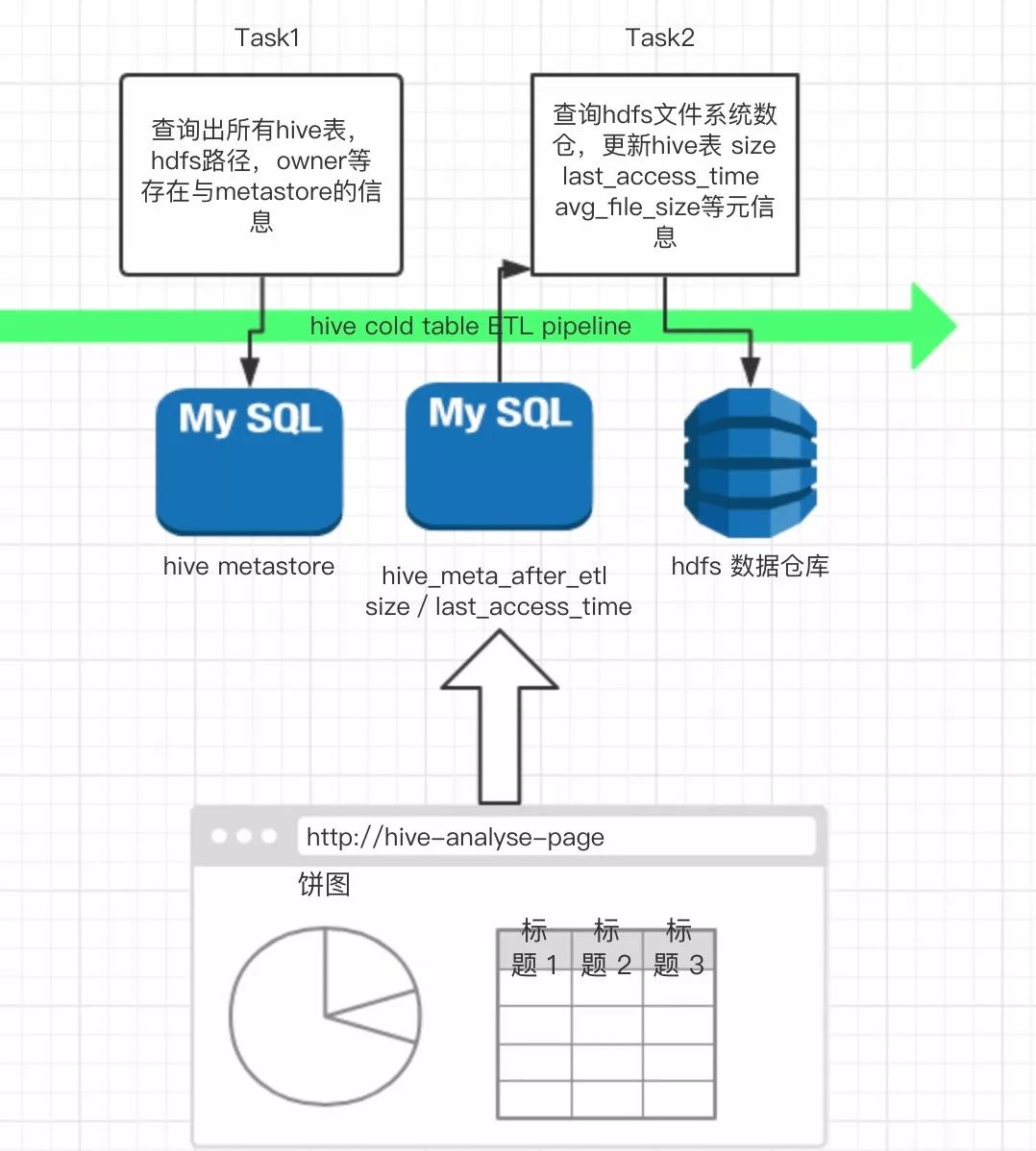
架构
总结
总之,为了防患“无止境的数据增长”,公司最好每天都观察数据增长5分钟,并在每个季度Review每个数据Team的增长。
这里总结了一些通用的原则,供大家参考:
要明确谁占用的“资源多”,谁Cost的成本高,方便给CTO汇报。
要打通数据分析系统,在数据团队有疑问、甚至不配合工作时,给他们摆事实、讲道理。
要把不同数据团队的KPI做排名、做比较,让数据存储上做得差的团队有“羞耻感”。
在推动整体数据治理这件事时,有必要Involve更高级别的领导,甚至CTO。
要梳理清楚Team的顶级路径,严格规定路径的使用。承诺只有放在Team顶级路径下的文件是安全的,否则都可能在系统过载时被管理员删除。
在有限的时间内,让产出最大化,把精力花在最有价值的点上。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721