
本文根据DCOS联盟第7期线上分享整理而成。
张亮
当当网架构部负责人
目前负责搭建分布式中间件及私有云平台
主导两大开源项目:Elastic-Job和Sharding-JDBC
主题大纲:
1、私有作业云技术栈选型
2、作业云的关键功能点
3、Mesos和Java业务系统结合的痛点
在私有云的技术栈越来越普及的情况下,当当决定将业务平台逐渐迁入私有云。作为入云的第一步,选择合理、风险易控的方向很重要。经过多方面权衡,我们选择了基于Mesos + 自研Framework的作业云方案。
本次分享将介绍当当私有作业云平台的开发、搭建过程,包含开发一个基于业务系统的作业调度Mesos Framework碰到的问题和一些思考。
私有作业云技术栈选型
我们开始作业云技术栈选型是2016年5月份的事情。在作业云平台搭建之前,当当有一个分布式调度框架——Elastic-Job,它提供了基于分片的分布式处理能力。它可以将一个Job根据分片总数拆分为多个Task,每个Task被分配到一个分片项,业务开发者通过分片项决定如何拆分业务。通过分片概念可以做到弹性的扩容缩容。比如一个Job设置分片总数为100,由10台Server执行,那么每台Server会获取到10个分片,如果增加到20台Server,每台Server需要执行的分片则下降到5片,这样就可以通过Server的增减控制整个分布式Job的吞吐量,以达到动态扩缩容的目的。Elastic-Job还提供了高可用、失效转移等分布式协调功能。它是一个java开发的jar(类似于Dubbo),本身并不具备自动部署以及资源管理的能力。
在云平台选型时,公司已经有不少项目使用Elastic-Job,我们希望完全兼容Elastic-Job的原有API,所以Chronos等作业调度框架并不能满足我们的需求。我们要做的是将Elastic-Job结合到云平台,并增加结合硬件资源的掌控,以及部署发布自动化等功能。Elastic-Job本身包含Quartz,可以直接进行Job定时调度。因此,我们的最初想法是将Elastic-Job作为常驻服务启动,用Kubernetes或Mesos + Marathon运行。
但Elastic-Job当时并未考虑Cloud Native,设计本身存在一个问题,那就是分片是基于IP地址的。如果运行在私有云,每个Job实例一旦分配到同一台Server,同样的IP地址会导致Job分片冲突。虽然用CNI等网络解决方案可以处理这方面的问题,但我们希望提供更加轻量级的解决方案。原因是我们不希望仅搭建公司级别的私有云,更希望遵循公司的一贯理念,将整个体系开源。
既然需要对Elastic-Job进行修改,那么其他需求也如雨后春笋一般冒了出来。最关键的需求是作业云平台应该可以同时支持常驻和瞬时两种作业。常驻作业就是之前提到的将Elastic-Job放到Marathon运行的形态。它由作业jar本身负责定时任务的调度,无论作业是否在执行,都会一直占有资源。常驻作业适合执行间隔短或初始化时间长的作业,以业务作业居多。比如订单拉取作业,需要初始化Spring容器,建立各种资源的连接,然后执行复杂的业务逻辑,并且订单拉取的时间间隔不会太长。另一种瞬时作业就像Chronos处理的方式,由中心调度,每次调度执行结束后都释放占用的资源。它适合间隔时间长,资源占用高的作业,以报表作业居多。
涉及到中心调度的需求,就不能仅使用Mesos + Marathon,或者Kubernetes做简单的治理了,需要自研一套框架来解决这些事情。当时的Kubernetes刚刚推出Multiple Scheduler,并未经过太多的验证。因此自研的灵活度上,采用Tow-Level调度体系的Mesos比较容易满足我们的需求。我们最终选定Mesos + 自定义Framework的方案搭建作业云平台。为了与Elastic-Job兼容,作业云沿用了Elastic-Job的API,新的基于Mesos的Framework叫做Elastic-Job-Cloud,原Elastic-Job更名为Elastic-Job-Lite。
作业云的关键功能点
Elastic-Job-Cloud包括Mesos Framework的Scheduler和Customized Executor两部分。
Elastic-Job-Lite采用Zookeeper作为注册中心,用于处理Job的高可用、分片、失效转移等分布式协调功能,每个使用Elastic-Job-Lite的应用都需要与Zookeeper建立长连接。这样会造成Zookeeper的连接过多,容易成为分布式系统的瓶颈。Elastic-Job-Cloud放弃了采用Zookeeper作为注册中心的方案,转而采用Mesos Framework API提供的statusUpdate方法处理。statusUpdate的治理能力还是非常不错的,通过对Executor回传状态的解读来处理高可用、重新分片以及失效转移等功能。Zookeeper在Elastic-Job-Cloud中彻底退化为存储媒介,仅用于存储Job的Metadata和待运行队列等状态数据。之所以仍然采用Zookeeper是为了避免采用过多的第三方依赖,保持和Mesos使用统一的技术栈。作业运行的实时状态,由于大量的读写请求,放在Zookeeper会极大的影响整个作业云的性能,因此直接放在内存中。未来我们希望将Job Metadata以及队列状态迁移至etcd,希望Mesos支持etcd作为配置中心的版本尽快出现。
Elastic-Job-Lite分片逻辑有2个部分需要调整,是IP地址和资源分配。Lite根据IP地址抓取所在服务器的分片,IP地址不冲突是前提条件。Elastic-Job-Cloud采用中心节点分片,直接将分片任务转化为Mesos的TaskInfo,这样就屏蔽了IP地址的限制。
资源分配在Lite中是缺失的,Mesos这样的平台可以将硬件资源和业务应用有机结合。我们最初开发的资源分配策略十分不稳定,无论是优先向一台Server分配,还是整个集群平均分配,算法都比较复杂,而且分配的维度不止一个。目前我们对CPU和Meomry资源进行管理,Disk、GPU资源等暂时未关注。经历了几次压测,整个系统的资源利用率极不稳定,直到采用了由netflix开源的Fenzo,一个专注于Mesos资源分配的框架,一切问题迎刃而解。吐槽一下,这是用Java写Mesos Framework的福利,Fenzo至今还未有其他语言的版本。Fenzo除了能够提供便利的资源分配策略之外,还能提供弹性资源伸缩分配等功能。但Fenzo使用不当会造成内存泄漏,关键点在于Fenzo会在内存中存储当前已分配的Task,Task运行结束后需要释放。但添加Task时,直接使用Fenzo生成的TaskAssigner对象,释放时却需要提供TaskID。
Elastic-Job-Cloud的业务逻辑中TaskID中会包含Mesos的slaveID,用于通过TaskID回溯运行时状态。但Fenzo需要分配Server前即提供TaskID,因此我们的解决方案是先提供一个伪造的SlaveID,在分配完成后替换为真实的SlaveID。这样在记录Task时,由于Fenzo API的关系,不太容易注意到TaskID的作用,注销Task时使用真正的TaskID是无法清除的,而Fenzo未提供任何报错或日志,非常容易造成内存泄漏。
Elastic-Job-Cloud的作业调度采用两个队列,Offer队列用于收集Mesos分配的资源,Job队列用于堆积待执行作业。当待执行作业可以从资源队列中匹配到合适的资源时,才会分配并生成TaskInfo执行。这种方式对于运行在同一Mesos集群中的其他Framework不太友好,可能在作业需求不多的情况下造成Offer的囤积。但对于Offer收取和Job执行同为异步的情况下,也没什么其他更好的方案了。
Mesos和Java业务系统结合的痛点
Scheduler开发是自研Mesos Framework的必需品,而Customized Executor则不然,很多Mesos Framework直接使用Default Executor,已经能满足基本需求。我们采用Customized Executor主要是两方面原因。第一个原因是为了兼容Elastic-Job-Lite的API,另一个原因是为了做到更合理的资源利用。这两个原因的根源在于Java。公司的很多项目都是Java开发的,Elastic-Job的API也是基于Java,它根据Mesos分配好的分片处理相应的业务逻辑。像下面这样:
public class JavaSimpleJob implements SimpleJob {
@Override
public void execute(final ShardingContext shardingContext) {
}
}
更合理的资源利用说起来比较复杂。Java的生态圈非常繁杂,用于支撑业务的作业框架不能只做到简单的能够触发调用,还需要和Spring这样的容器深度融合,至少需要通过依赖注入获取Spring容器中的bean。
每次Job启动都初始化Spring容器是很大的浪费。Elastic-Job-Cloud的Executor在第一次启动时即实例化Spring容器,以后每次Job调度都复用Spring容器即可。
以何种维度复用Executor是个值得探讨的问题,一开始我们采用每个Job的维度复用Executor,如果一个Job分为10片,分配到2台Mesos的Agent,那么每个Executor会开启多线程执行被分配到的分片项,而不同的Job则开启不同的Executor。但是应用的需求是无止境的,这种方式针对某些需求就不合适。如果发生很多Job只是名字以及配置不同,但Jar相同,而这种Job又很多的情况下,为每个Job创建独立的Executor就会造成资源过度浪费。
举个具体的例子会更容易理解:系统监控作业,监控各种RESTFul API的可用性,有的每分钟监控一次,有的每5分钟监控一次,而各API的URL又不同。每个监控作业都是一个独立的Job,有不同的name和cron,但它们均来源于同一个Jar。针对这种情况,我们采用以Jar的App URL为维度复用Executor。成百上千个类似的Job汇聚成线程而不是进程,进一步节省资源。
Mesos基本能满足我们的需求,但是也确实有些地方值得探讨。对于JVM类型的应用,部署到Mesos Exeutor运行,需要分配Executor相应的资源,主要是Memory。而JVM类应用为了能够合理的利用资源,一般会在启动脚本中定义Xmx等内存配置项。这个配置只能定义为Executor分配的初始Memory大小。每当为Executor分配一个Task,都会继续追加Task所分配的资源。但这个资源是无法被JVM继续使用的。因此,弹性的利用Executor(1 Executor + n Tasks)还是静态的使用Executor(1 Executor + 1 Task)我们还很纠结。目前的做法是尽量增大Executor的内存,而减少Task的内存。未来我们会考虑将Executor的使用方式分为静态和动态相结合的方式,对于同一App URL衍生的海量作业使用动态Executor的方式;对于同一App URL少量作业采用静态Executor,以Job Name + Sharding Item为维度启动。
经过刚才的描述可能会让人产生Elastic-Job-Cloud只能支持Java Job的误解。其实不然,它可以支持Java和Shell两种作业,只是针对Java Job做了优化,如Executor复用,以及前文未提到的Dataflow等类型作业,用于更加容易的处理数据流类型的Job。Shell Job和Java Job最大不同在于分片上下文传输的方式,Shell Job通过命令行参数以Json的形式传入分片上下文,Java Job则是使用TaskInfo的方式传入。
Elatic-Job-Cloud提供了全部的Job Event Trace功能,通过Job执行事件发布的方式,将Job所有的状态变更以及执行历史记录都存入数据库,目前只是简单的存入关系型数据库,未来会开放Hbase等支持,由于作业数量巨大,历史记录也非常多,我们根据作业的重要程度对历史轨迹采样记录,用于以后的分析。
除了Mesos + Elatic-Job-Cloud,私有作业云还需要很多其他工作,如app repo的搭建、日志中心、权限、上线流程、运维监控相关,不一一细说了。
通过Elastic-Job-Cloud的开发,获得了一些Mesos Framework相关的经验,为了让Mesos更加强大,社区更加完善,在这里提几点可能对Mesos提高的建议:
增加使用Etcd作为Mesos注册中心的选项。
官方提供类似于Fenzo理念的一站式资源分配模型,让Mesos framework的开发更容易。
增加对JVM友好性的支持,现在用Java开发业务系统的公司仍然占据大多数。
最后分享一下开源,这次分享的所有东西都可以在github上找到。Elastic-Job的两个分支——Lite和Cloud已经开源一段时间了,地址是:https://github.com/dangdangdotcom/elastic-job,我们会持续同步更新和维护。 开源给公司带来了很多的好处,除了提升公司知名度等与技术本源无关的益处之外,还会对项目本身的代码质量、设计方案、演进路径等带来良性促进。附上我们从作业云选型到上线的全部时间轴,欢迎指点。
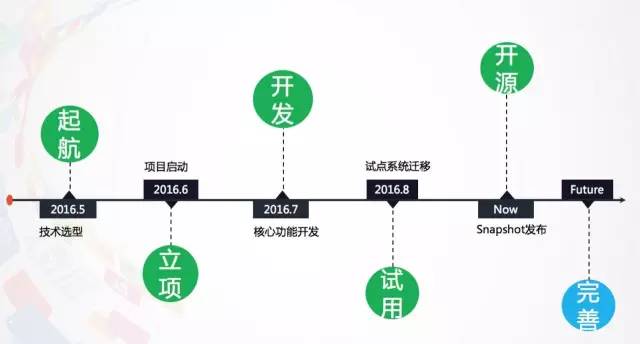
Q1:从最后的时间轴来看,这个项目其实进度还挺快,有多少人参与研发?另外安全性方面是怎么考虑的?
A1:8月之后其实也一直在进展,升级了4个小版本。之所以前期进展快是因为Mesos提供的理念和API确实比较清爽。前期是2个人开发核心代码,后期由于作业云整个上线,包括界面的开发、运维监控等,一共有8人参与。因为是私有云,安全性没有做过多考虑,是集成公司的SSO。
Q2:问一个跟作业云不太相关的事,当当网有多少MySQL数据库跑在Docker里了? 看介绍你们有自研的数据库中间件,也在容器里么?
A2:我们并未把数据库这种有状态的服务放入Docker,自研的数据库中间件是用于分库分表、读写分离和柔性事务。这个自研的中间件叫sharding-jdbc,顾名思义,它是JDBC层面的改造,因此sharding-jdbc是否放入Docker完全取决于使用它的业务应用,它和elastic-job-lite一样,都是以jar的形式提供服务。当当会分为四步走:作业云、web云、服务云和数据云,最后会都进入私有云,但不一定都放入容器中。
Q3:作业云目前大概是多大的规模?是计划中最小的云么?
A3:作业云目前正在跑的作业实例是4000个左右,9台用于放置元数据的服务器,3台mesos master,3台elastic-job-cloud,3台zk,剩下的都是Mesos的executor。目前是10台,以后会逐渐的增加。作业云按照体量来说确实是最小的云,但实现难度其实比web云要难一点。目前我们还未考虑将大数据类的作业迁入作业云平台,这也考虑到资源利用的安全性和平衡性。随着对Mesos的越来越熟练,我们希望最终将所有的业务跑在一个大的集群中,充分利用Mesos的削峰填谷的能力,不过目前还只是一些想法,分离在线业务和离线业务是当前无法逾越的鸿沟。
Q4:数据云是主要跑Spark之类的大数据分析应用?
A4:数据云主要用于处理在线业务数据,跑Spark的应该叫大数据云。目前在线业务和大数据还是分离的,数据云主要是数据库、Redis等。关于数据云目前我们还未考虑太多,随着技术的发展,有状态的容器治理方案会越来越成熟,到时会事半功倍的。
Q5:Mesos + Java如何优化?
A5:现在很多使用Mesos的人会把它当做yarn的替代品,用它处理大数据的居多。直到Marathon的出现,用Mesos + Marathon运行Nginx和tomcat的才逐渐多了起来。但现在微服务的出现,很多服务已经不是架在web容器上了。而国内用Java开发业务应用还是占有很大比例的,像刚才说的,如何提升Mesos和Java的契合度是个目前不太多的话题,目前我这里也没什么答案,希望将这个问题抛出来和各位共同探讨。
Q6:如何运营好一个开源产品?
A6:目前的Elastic-Job已经被Mesos官方收录到文档中,在github中也获取了1k的star。但是真正运营好一个开源的社区,还是需要花费很大的精力,文档、运营活动、技术支持等一系列行为需要花费大量的精力,这方面我也没有太多的经验,希望和大家共同探讨。










230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒