
目录:
【RDBMS家族】
Oracle
12c Release 2文档发布
12c Release 2特性解读
MySQL
MySQL 5.7 新特性解读
MySQL分支Percona
Percona 5.7.16-10发布
MySQL分支MariaDB
MariaDB 10.1.19 发布
SQL Server
SQL Server 2016 SP1补丁包发布
SQL Server On Linux版本发布
PostgreSQL
PostgreSQL 9.6发布
PostgreSQL 9.6.1 patch发布
DB2
DB2 LUW V11.1 发布
Greenplum
GPCC3.0发布
GPText 2.0发布
感谢名单
RDBMS家族
一、Oracle
12c Release 2文档发布
Oracle Database 12c Release 2文档在2016年11月中旬公开发布, 12c Relese 2离公开下载的日子又近了一步,如果想了解新版本、新特性,可以从文档开始了。
http://docs.oracle.com/database/122/index.html
相比于12c Release 1,Release 2在Multitenant、In-Memory、Spatial and Graph、Sharding几个方面有了加强和改进。
12c Release 2特性解读
Oracle 12c R2从云端首先支持。下面是整理的一些新特性,发布时间以官方发布时为准。
1、Oracle Core Database
Oracle将针对Linux提出一个新的安装版本Oracle Core Datbase,这意味着你安装Oracle Core Database只需要一条命令yum install oracle-core-database。
与之前Oracle发布过的Oracle Express版本Oracle XE看起来有些相似,但是有巨大的差别,Oracle XE是免费的,没有官方支持也没有补丁。而Oracle Core database是需要license许可证,同时官方也提供支持和补丁。
Oracle Core Database版本将区别于Oracle企业版的较高价格,主要是为了让用户能从sharding中充分获得横向扩展能力,Core Database可以大幅降低其license成本费用,达到Oracle EE企业版的几分之一乃至几十分之一的价格。
2、Oracle Sharding
简单来说,Oracle的Sharding技术就是通过分区(Partioning)技术的扩展来实现的。以前一个表的分区可以存在于不同的表空间,现在可以存在于不同的数据库。不同分区存在于不同数据库,这就将数据隔离了开来,Sharding就此实现。
在Sharding的架构里,存在一个“Shard Directories”目录库来管理Sharding的分布,当应用通过Sharding Key来访问数据时,连接池就会给出访问路径,快速指向需要访问的Shard。如果应用不指定分区键访问,则需要通过协调库-Coordinator DB来协助判定。
3、关联组件 — 全局数据服务(GDS)
在Oracle 12.1版本中增加的一个新的产品组件GDS - Global Data Services,通过GDS可以构建一个访问“连接池”,为后端的数据库访问提供代理和路由服务,前面提到的Shard Directories,正是在GDS中配置的。在12.2中,Sharding中的重要作用就日益凸现出来。
4、多租户增强
12.2中多租户支持更多的PDB共存,从上个版本中的252增加到4096个;在便利性上,支持Hot Clone,支持Refresh,支持在线的Tenent转移。PDB的Hot Clone可以让数据库在业务负载运行时进行Clone拷贝,并且实时同步变化数据,从而使得数据不断追平,进而实现在线切换,这极大的改善了上云的迁移过程。对用户来说是简化,并且在OEM的管理之下,所有工作可以近乎自动的完成。
5、IMO组件更新
In-Memory Option在12.2上也获得了增强,这一特性在ADG上的增强使得读写进一步分离,由于ADG的只读属性,备库上的内存数据又可以和主库不同,比如备库在内存中可以存储更广泛的数据,实现实时计算。而在性能和易用性上改进也值得称道,In-Memory在12.2中支持根据热图自动向内存进行数据转移,也可以动态的清除冷数据以释放内存空间,简化用户管理。
6、Oracle DataGuard增强
DBCA备库创建 - 在备库主机安装软件启动监听,则可以通过DBCA来创建备库,指向主库来获取文件,创建备库更加简单。
7、口令文件维护增强
在主库上口令文件的修改变更,将自动复制到备库上去,不再需要手工复制文件了。
8、AWR支持远程快照
AWR支持捕获远程数据库的信息,包括ADG。在之前的ADG中,备库只能通过Standby Statspack、in-memory ASH、tkprof来进行性能分析和诊断,现在可以支持AWR了。
9、连接保持
在ADG中实现了Failover、SwitchOver中的连接会话保持,减少了重新连接的开销,极大的改善了用户体验。
10、自动块修复增强
ADG自动块修复自11gR2引入,现在已经非常成熟,修复的类型大大增加。在新版本中,各种类型的坏块支持增量修复。即使是原来11g不支持的datafile header块,新版本中也可以修复了。
11、DataGuard中并行日志应用
在12cR2之前,DG的备库只能由一个实例通过MRP进程进行应用,现在可以在多实例并行进行。多实例应用,可以在所有Mounted或者Open的实例上并行进行,对比一下单实例应用和多实例应用的架构对比,在常规模式下,多实例的备库,可以有多个Remote File Server (RFS)进程进行Redo Thread的日志接收,但是仅有一个实例进行Managed Recovery Process (MRP)应用恢复。当然,在单个实例上,仍然可以启动多个MRP进程,进行并行的恢复。在Oracle 12.2的版本中,多实例并行MRP恢复被支持,这一改变将极大的提升DataGuard的效率和可用性。
12、BIG SCN
在12cR2中将引入BIG SCN的特性,SCN的格式将从6个字节变成8个字节存储,这意味着更高的SCN上限 以及能满足更快的SCN增速。
13、Cross-Endian Dictionary Project
跨Endian的数据字典项目,使得在AIX等Big Endian平台上生成的Oracle数据字典可以在Little Endian上读写,反之亦然。 Cross-Endian Dictionary让PDB plug-in可拔插数据库和表空间传输(XTTS)更方便。另一个方面Cross-Endian Dictionary跨Endian数据字典让跨Endian的ADG active data guard 变成可能, 这意味着 AIX上的primary库,可以使用X86的pc server作为standby。
14、Other
在V$SQL 中加入redo size字段,即可以显示每一条SQL语句产生的redo量。
表和列的名字上限从30字符提高到128字符。
表在整个移动过程中,仍然是可以访问的。此外,还可以自动更新索引有效。
二、MySQL
MySQL 5.7新特性解读
关于5.7的新特性会从安全性和功能性两方面来解读。
1、5.7版本的用户表mysql.user要求plugin字段非空,且默认值是mysql_native_password,并且不再支持mysql_old_password。
2、增加密码过期功能,DBA可以设置任何用户的密码过期时间,到期之后必须更改密码,从而增加密码账号的安全性。具体保留时间由 default_password_lifetime控制,如果为0,则说明永久不过期,生产环境则建议关闭该参数。
3、DBA可以通过对用户加锁/解锁进一步控制其访问db,具体例子如:alter user yang@'%' account lock;
4、MySQL 5.7版本提供了更为简单SSL安全访问配置,并且默认连接就采用SSL的加密方式。
5、使用更安全的初始化db的方式,并且废弃mysql_install_db的安装方式,使用initialize代替(mysql_install_db <5.7.6<= mysqld —initialize),使用initialize参数初始化数据库有如下特性:
只创建一个 root账号,并且生成一个临时的标记为过期密码。
不创建其他账号。
不创建test 数据库。
1、从MySQL5.7.8开始,MySQL支持原生的JSON格式,即有独立的JSON类型,用于存放JSON格式的数据。JSON格式的数据并不是以string格式存储于数据库而是以内部的binary格式,以便于快速的定位到JSON格式中值。
在插入和更新操作时MySQL会对JSON类型做校验,已检查数据是否符合JSON格式,如果不符合则报错。同时5.7.8版本提供了多种JSON相关的函数,可以方便的访问目标数据而不用遍历全部数据。
创建:JSON_ARRAY(), JSON_MERGE(), JSON_OBJECT()
修改:JSON_APPEND(), JSON_ARRAY_APPEND(), JSON_ARRAY_INSERT(), JSON_INSERT(), JSON_QUOTE(), JSON_REMOVE(), JSON_REPLACE(), JSON_SET(), and JSON_UNQUOTE()
查询:JSON_CONTAINS(), JSON_CONTAINS_PATH(), JSON_EXTRACT(), JSON_KEYS(),JSON_SEARCH().
属性:JSON_DEPTH(), JSON_LENGTH(), JSON_TYPE() JSON_VALID().
2、MySQL 5.7版本新增了sys数据库,该库通过视图的形式把information_schema和performance_schema结合起来,查询出更加令人容易理解的数据,帮助DBA快速获取数据库系统的各种纬度(如谁占用资源最多,实例的内存分布,某个ip访问占用的iops和io延迟时间)的元数据信息,帮助DBA和开发快速定位性能瓶颈。详细的信息请参考《官方文档》http://dev.mysql.com/doc/refman/5.7/en/sys-schema.html
3、innodb表支通过ALTER TABLE语句以in place方式修改varchar的大小且无需table-copy。但存在限制:表示varchar长度的字节数不能变化(如果变更前使用1个字节表示长度,变更后也必须使用1个字节表示),即只支持0~255内的或者255以上的范围变更(增大),如果字段的长度从254增到256时就不能使用in-place算法,必须使用copy算法,否侧报错。
4、online DDL语句重建普通表和分区表:OPTIMIZE TABLE、ALTER TABLE … FORCE、ALTER TABLE … ENGINE=INNODB等操作支持支持使用inplace算法。减少了重建时间和对应用的影响。
5、支持新的DATA_GEOMETRY空间类型的数据:InnoDB现在支持MySQL-supported空间数据类型。也即,之前的空间数据是以binary BLOB数据存储的,现在空间数据类型被映射到了一个InnoDB内部数据类型DATA_GEOMETRY。
6、innodb buffer dump功能增强:5.7.5新增加innodb_buffer_pool_dump_pct参数,来控制每个innodb buffer中转储活跃使用的innodb buffer pages的比例。之前的版本默认值是100%,当触发转储的时候会全量dump innodb buffer pool中的pages。如果启用新的参数比如40,每个innodb buffer pool instance中有100个,每次转储每个innodb buffer实例中的40个pages。
注意:当innodb发现innodb后台io资源紧张时,会主动降低该参数设置的比例。
7、支持多线程刷脏页:MySQL 5.6.2版本中,MySQL将刷脏页的线程从master线程独立出来,5.7.4版本之后,MySQL系统支持多线程刷脏页,进程的数量由innodb_page_cleaners参数控制,该参数不能动态修改,最小值为1,最大值支持64,5.7.7以及之前默认值是1,5.7.8版本之后修改默认参数为4。当启用多线程刷脏也,系统将刷新innodb buffer instance脏页分配到各个空闲的刷脏页的线程上,如果设置的innodb_page_cleaners>innodb_buffer_pool_instances,系统会自动重置为innodb_buffer_pool_instances大小。
8、动态调整innodb buffer pool size:从5.7.5版本,MySQL支持在不重启系统的情况下动态调整innodb_buffer_pool_size。resize的过程是以chunk(每个chunk的大小默认为128M)的为单位迁移pages到新的内存空间,迁移进度可以通过Innodb_buffer_pool_resize_status查看。记住整个resize的大小是以chunk为单位的。innodb_buffer_pool_chunk_size的大小,计算公式是innodb_buffer_pool_size / innodb_buffer_pool_instances,新调整的值必须是innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的整数倍。如果不是整数倍,则系统则会调整值为两者乘积的整数倍且大于指定调整的值。
9、升级innochecksum:innochecksum--离线的InnoDB文件校验工具,新增新的选择项或扩展的功能,如可指定特定的校验算法、可以只重写校验值而不进行验证、可指定允许的校验和不匹配量、显示各类页的个数、导出页类型信息、输出至日志、从标准输入读取数据等。从 5.7.2 起可支持校验超过2G的文件。详细的用法参考《innochecksum 官方文档》。
10、支持原生的分区表:在MySQL 5.7.6之前的版本中,创建分区表时MySQL为每个分区创建一个ha_partition handler,自MySQL 5.7.6之后,MySQL支持原生的分区表并且只会为分区表创建一个partition-aware handler,这样的分区表功能节约分区表使用的内存。对于老版本创建的分区表在升级到新的版本之后怎么处理呢?莫慌,5.7.9之后,MySQL提供了如下升级方式解决这个问题:ALTER TABLE ... UPGRADE PARTITIONING.
11、支持truncate undo logs:MySQL 5.7.5版本开始支持truncate undo表空间中的undo log。启用该特性必须设置innodb_undo_log_truncate=[ON|1]。大致原理是系统必须设置至少两个undo表空间(初始化的时候设置 innodb_undo_tablespaces=2 ) 用于清理undo logs的切换。该特性的好处是解决5.6之前虽然将ibdata和undo表空间隔离,但是undo log文件一直增大的问题,减轻系统的空间使用压力。详细信息参考《官方文档》。
12、新增内置的Full Text插件,支持中文、韩文、日文全文索引。之前的版本只能依赖单词之间空格进行分词,对于依赖于语义分词而非空格分词的其他语言种类,5.7版本的引入支持解析中文、韩文、日文的全文索引--ngram full-text parser解决了该问题。
13、支持在线调整Replication Filter,可以online调整REPLICATE_IGNORE_DB,REPLICATE_WILD_IGNORE_TABLE,REPLICATE_WILD_DO_DB,REPLICATE_WILD_DO_TABLE,无需重启slave。
14、支持多源复制,通过channel支持一个从库复制多个主库。
15、支持事务级别的并行复制,区别于5.6版本基于schema级别的并行复制,5.7版本基于group commit(slave-parallel-type=LOGICAL_CLOCK)做到真正的并行复制,降低了slave延迟的风险。
16、半同步增强:1)增加ack thread解决5.6版本异步复制主库dump thread必须等到slave返回消息之后才能接受新的事务请求,提高事务处理能力;2)增加after sync模式,事务是在提交之前发送给Slave(默认,after_sync),当Slave没有接收成功,并且Master宕机了,不会导致主从不一致,因为此时主还没有提交,所以主从都没有数据。MySQL5.7也支持和MySQL5.5\5.6一样的机制:事务提交之后再发给Slave(after_commit)。
17、GTID 增强:1)支持在线修改gtid 在线开启GTID的步骤:不是直接设置gtid_mode为on,需要先设置成OFF_PERMISSIVE,再设置成ON_PERMISSIVE,再把enforce_gtid_consistency设置成ON,最后再将gtid_mode设置成on;2)存储GTID信息到表中,slave不需要再开启log_bin和log_slave_updates。表存在在mysql.gtid_executed,MySQL5.6上GTID只能存储在binlog中,所以必须开启Binlog才能使用GTID功能。
三、MySQL分支Percona
Percona 5.7.16-10发布
Percona Server为MySQL数据库服务器进行了改进,在功能和性能上较MySQL有显著的提升,Percona在近期推出了5.7.16,该版本基于MySQL 5.7.16。同时Percona提供了近300页的文档说明。
主要变更如下:
1、过时的插件
Metrics for scalability measurement这个特性已被废弃。因为会有一些crash的情况发生,用户如果安装了这个插件但是还没有使用到会被建议卸载。
2、Bug 修复
当存储程序会调用如下的管理命令,如OPTIMIZE TABLE, ANALYZE TABLE, ALTER TABLE, CREATE/DROP INDEX时,参数log_slow_sp_statements的值会被log_slow_admin_statements锁覆盖,Bug fixed #719368
如果参数innodb_force_recovery设置为6,并行double write文件存在的情况下,数据库在崩溃后无法启动,Bug fixed #1629879
线程池中的线程如果溢出导致无法创建线程,这些信息现在会及时反馈到日志中。Bug fixed #1636500
在TokuDB中INFORMATION_SCHEMA.TABLE_STATISTICS和 INFORMATION_SCHEMA.INDEX_STATISTICS 这两个表数据不够准确。Bug fixed #1629448
3、其他Bug修复:#1633061, #1633430, and #1635184
四、MySQL分支MariaDB
MariaDB 10.1.19发布
MariaDB是MySQL源代码的一个分支,主要由开源社区在维护,采用GPL授权许可。2016年11月7日发布了MariaDB 10.1.19版本,MariaDB 10.1是目前的稳定版本,这在10.0版本的基础上有几个全新的特性,还有一些是基于MySQL 5.6,5.7改进和重新实现。
主要变更如下:
1、XtraDB更新至5.6.33-79.0。
2、TokuDB更新至5.6.33-79.0。
3、添加了Ubuntu 16.10 yakkety软件包,可以使用配置工具添加MariaDB的Ubuntu软件库到你的系统中。
4、修复了以下安全漏洞:
cve-2016-7440
cve-2016-5584
更多的变更信息可以参考官网链接:
https://mariadb.com/kb/en/mariadb/mariadb-10119-changelog/
五、SQL Server
SQL Server 2016 SP1补丁包发布
SQL Server的所有版本在安装了SP1补丁包之后将具有以前企业版才有的所有与开发相关的特性,这些特性包括:
行级加密
动态数据掩码
更改跟踪
数据库快照
列存储
表分区
表压缩
In Memory OLTP
总是加密
PolyBase
数据库审计
multiple filestream容器
SP1补丁包还包含下面一些主要新功能:
1、数据库克隆
DBCC CLONEDATABASE命令是DBCC命令家族的新成员,这个命令允许你只克隆数据库的表结构、统计信息,query store元数据,而不会克隆/拷贝数据,利用这个克隆可以帮助DBA和微软技术支持团队更好的排查数据库问题
2、CREATE OR ALTER新语法
这个新语法可以使用在存储过程、触发器,用户定义函数,视图,这个功能也是跟某些开源数据库学习所做的改进。
3、新的USE HINT查询提示
格式 OPTION(USE HINT('
xml执行计划里增加了内存授予警告,能够显示单个查询允许的最大内存,开启的trace flags信息查询所有cpu时间,查询消耗时间,top waits和参数的数据类型,对性能调优有很大的帮助。
5、新增的动态管理函数sys.dm_db_incremental_stats_properties
sys.dm_db_incremental_stats_properties能够显示分区表里每个分区的增量统计信息的情况。
6、新增EstimatedlRowsRead属性
在showplan XML里新增加EstimatedlRowsRead属性,可以更好排查查询计划是否使用了谓词条件下推。
7、对Bulk insert大容量插入数据场景开启TF715会自动添加TABLOCK提示
Trace flag715只在没有非聚集索引的堆表生效,当开启TF715之后,大容量拷贝数据到一个表的同时bulk load操作会申请bulk update(BU)锁。在保持Bulk update(BU)锁的情况下,SQL Server会开启多线程并行大容量加载数据到表里,BU锁可以阻止其他大容量加载线程访问被插入表。SQL Server2016以前需要手动指定TABLOCK提示才能使用多线程并行大容量加载,现在SQL Server2016已经默认帮用户添加上TABLOCK提示,使得SQL Server2016更加人性化。
8、优化Hekaton 存储引擎的错误日志输出
当使用了内存优化表之后,SQL Server错误日志会增加非常多的Hekaton存储引擎相关的错误日志,甚至淹没整个SQL Server的errorlog。根据社区反馈,从SQL Server2016 SP1开始优化并减少Hekaton存储引擎的错误日志输出。
SQL Server On Linux版本发布
目前只是技术预览版CTP1,并且名字也有所改变,叫做SQL Server vNext CTP1,多了一个vNext。安装之后的内部版本号是14.0,而现在已经发布的SQL Server2016的内部版本号是13.0,意味着这是下一个版本的SQL Server,而不是沿用SQL Server2016这一个版本。
微软为了在Linux上使用SQL Server,创建了从Drawbridge演变而来的SQL平台抽象层(SQLPAL)。正因为有了这个SQL平台抽象层(SQLPAL)更加加快了SQL Server的移植速度,官方宣布在2017年年中SQL Server vNext会正式GA。
目前来看,SQL Server vNext采用了组件化安装,核心数据库引擎安装包才138MB,安装和使用都非常方便。
对SQL Server vNext感兴趣的同学可以到官方网站查看安装教程,安装试玩,地址:https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-overview
或者到微软Azure公有云,微软Azure公有云上已经提供了相应的SQL Server vNext虚拟机镜像,地址:https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-azure-virtual-machine
六、PostgreSQL
PostgreSQL 9.6发布
PostgreSQL 9.6于2016年9月29日正式发布,包含了许多里程碑式的新功能。
1、多核并行执行
可以利用多核实现JOIN,全表扫描,聚合操作的加速。达到线性性能提升的效果。企业的很多报表需求,完全可以在业务低峰时将所有的硬件资源利用起来,快速完成报表的需求。
2、强一致任意多副本同步复制
允许用户选择事务的可靠性级别,配置任意多副本强同步。例如1主2备,用户可以要求事务结束的REDO发送到至少任意一个备库,才返回给客户端事务结束。
3、增加remote_apply同步级别
对于对读写分离的数据一致性要求非常严格的场景,用户可以将事务的同步级别设置为remote_apply,那么事务在结束前,会确保它的REDO已经在任意数量(用户配置)的备库apply后,才返回客户端。
4、全文检索支持phrase
全文检索支持文本相似度,支持文本的位置信息,支持按位置匹配,例如'速度与激情' 可以与 '速度 <1> 激情' 匹配。实现精准的匹配规则。
5、全文检索拼写字典增强
支持拼写纠正,例如stories、story、big, bigger、biggest、doing、do、done、hack、hacking、hacked都会转换为原来的单词。
6、postgres_fdw支持JOIN、SORT、UPDATE、DELETE下推至远程数据库
通过postgres_fdw,可以支持数据库的sharding,计算和filter条件都可以下推到远程数据库执行。10.0的版本已经增加了聚合的下推。
7、高并发性能增强
可以充分发挥硬件的性能,满足高并发时的高TPS需求,单机(72HT)实现180万tps。
8、VM增加freeze bit识别
增加VM的freeze识别,从而大幅降低静态历史数据的FREEZE的扫描。
9、支持等待事件
新增了69个等待事件的监控,用户可以根据等待事件统计信息,找出数据库的瓶颈。
10、排序增强
排序的内核性能增强,充分利用CPU CACHE。
11、snapshot time out
支持快照过旧。
12、IO调度优化
支持检查点排序,降低离散IO。支持checkpoint, bgwriter, wal writer, backend writer进程的平滑IO调度策略。
13、相同算子的聚合子函数复用
通过复用同算子的聚合子函数,在多个聚合中,性能提升非常明显。
14、支持bloom任意列索引
支持对整行的所有列建立一个bloom索引,支持任意列的组合查询,满足前端无法固定的多变的查询条件需求。
更多材料可以参考:
https://github.com/digoal/blog/blob/master/201610
https://www.postgresql.org/docs/9.6/static/release-9-6.html
https://yq.aliyun.com/articles/51131
PostgreSQL 9.6.1 patch发布
2016年10月27日发布了9.6的第一个patch,以fix为主。
七、DB2
DB2 LUW V11.1发布
2016年6月15日,IBM正式发布DB2 LUW新版本11.1,提供了满足各种业务需求的新功能部件和增强功能,从而使数据库更有效率、更简化且更可靠。全面的企业安全性、简化的安装和部署、更高的易用性和适用性、顺利的升级过程、对超大型数据库的增强功能以及对BLU加速的显著改进是此技术提供的主要益处。
1、对分区数据库环境的按列组织的表支持
下列特定增强功能与分区环境中按列组织的表有关:
列矢量处理引擎的MPP感知查询计划和优化
分区之间纵列数据交换的优化向量格式
允许数据跨网络保持压缩状态的公共表字典
为实现多核心并行性而设计的优化通信基础结构
在DPF多分区环境中支持列存储表,在多服务器集群环境中分析型负载的扩展性得以大幅提升;获取的益处包括:最少的建模设计和查询调优、行业领先的数据压缩、分析型查询性能大幅提升等。
列存储表上支持NOT LOGGED INITIALLY语句,针对列表的INSERT、UPDATE、DELETE语句运行速度更快。
INSERT/INGEST/IMPORT过程中自动字典生成(Automatic Dictionary Creation, ADC)序列化得到增强,数据字典得以更早生成,大数据量表初始化操作(使用INSERT … SELECT…方式)的压缩率(PCTENCODED)更高、查询性能更好、高并发作业的吞吐量更佳。
高并发作业的性能和扩展性增强,频繁访问公共数据页面的高并发作业性能得以增强,小表查找和频繁索引页面访问(如嵌套表关联时)的门闩(DB2 Latch)明显降低,交易延时和锁等时间明显降低,这些改进可以明显提升高并发作业的扩展性。
行列安全控制(RCAC)支持列存储表,将传统行存储表上的安全控制机制推广到列存储表,控制用户访问具有权限的数据行、数据列或数据单元,是对数据库授权机制的补充。
2、企业加密密钥管理
原生数据库加密支持集中式密钥管理,支持集中式密钥管理器来存放原生加密主密钥,支持任何使用KMIP 1.1或以上版本的任何密钥管理产品。还通过已与DB2 V11.1 集成的企业密钥管理来支持硬件安全性模块(HSM),以向用户提供各种HSM选项。
3、DB2 pureScale特性增强
支持HADR的同步和准同步模式;
统一工作负载管理,支持定义成员子集的备用成员;
GDPC双活增强,支持ROCE和TCPIP,支持AIX,REDHAT和SUSE操作系统,每个CF和MEMBER支持多卡多口以提升带宽和增强可用性;每个站点支持双交换机模式;
GPFS复制增强,通过db2cluster命令进行GPFS复制配置,简化GDPC双活配置过程;
pureScale健康检查,db2cluster –verify命令用于pureScale产品安装后的健康检查,包括:TSA和GPFS集群的配置检查,member和CF见通讯检查,文件系统复制检查,文件系统中每个磁盘状态检查等。
八、Greenplum
Greenplum数据库是由Pivotal公司基于Postgres开发的分布式数据库。架构采用了MPP无共享架构,集群中的每个节点都有自己的资源,节点之间的信息交互是通过节点互联网络实现的。Greenplum数据库支持高并发,线性扩展,高可用性,向客户提供高性能的超级数据引擎,并将强大的并行计算能力融入到大规模数据仓库分析领域中。
2016年10月,Greenplum 4.3.10.0引入了S3可写表,开启了Greenplum对亚马逊S3的全面读写支持。用户可以非常方便地在亚马逊云平台上使用到Greenplum大数据服务,并且可以快速读写存储在S3上的数据。近日,Pivotal又刚刚宣布了Greenplum数据库对微软Azure云平台的支持,用户可以在微软Azure云平台上方便地使用到Greenplum提供的各项专业高效的大数据服务。
GPCC 3.0发布
2016年11月,新版GPCC 3.0的发布,给用户提供了一个更好的管理Greenplum数据库的工具。 管理员可以通过GPCC查询系统的性能指标,查看当前在系统中运行的查询,监控资源使用情况,并且方便问题诊断和报告。GPCC 3.0改进的部分包括但不限于:
GPCC 3.0彻底抛弃了过时的Flash技术,使用了对浏览器更加友好和安全的HTML5方案;
采用Pivotal UI 风格,与Pivotal相关产品保持了外观、操作等的一致性;
采用响应式布局设计,增强了与图表间的交互式操作;
采用Go语言设计开发了RESTful API的服务端,实现了平台无关性,优化了查询性能,降低了GPCC对Greenplum系统的资源占用;
采用测试驱动开发,并使用持续集成保证产品的质量,实现产品的持续交付。
GPText 2.0发布
2016年12月,GPText 2.0发布,集成了SolrCloud 6.1,增强了高可用特性,提供了启动、配置、扩展、备份、恢复等管理工具。GPText是Greenplum的一个扩展,它深度集成SolrCloud企业搜索功能和Madlib数据分析库,结合Greenplum的大规模并行处理机制为用户提供快速、便捷的文本搜索和分析服务,用户只需要通过熟悉的SQL命令调用相关的UDF函数就可以完成文本数据的索引、查询和分析。
最近的发布持续改进查询优化和查询执行,特别是基于ORCA的新Pivotal Query Optimzer,对于多个连接操作的语句、带有子查询的语句和包含IN的语句的优化可以减少查询执行时间,对于查询预处理的改进可以减少复杂查询的优化时间。 也包含了大量工具如gpfdist、gpcheckcat、gpcrondump等性能和功能的增强。
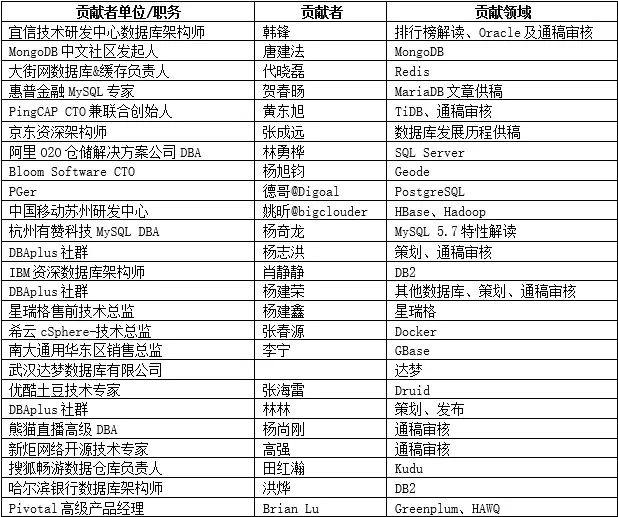
感谢名单
感谢本期提供宝贵信息和建议的专家朋友,排名不分先后。
回复“newsletter”至DBAplus社群订阅号(dbaplus)可下载本期Newsletter完整版
欢迎提供Newsletter信息,发送至邮箱:newsletter@dbaplus.cn
欢迎技术文章投稿,发送至邮箱:editor@dbaplus.cn









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒