
作者介绍
黄浩,现任职于中国惠普,从业十年,始终专注于SQL。在华为做项目的两年多,做过大大小小的SQL多达1500个。闲暇之余,喜欢将部分案例写成博客发表在华为内部数据库官方社区,反响强烈,已连续四个月蝉联该社区最佳博主。目前已开设专栏“优哉悠斋”,成为首个受邀社区“专家访谈”的外协人员。
公元2016年8月1日晚上,朋友圈流行着这样一个段子:特想摸清台风“妮妲”的威力有多大,一专业人士说:只须一句话就能让你深刻理解。遂追问,答曰:“就连华为都通知放假了?”感谢“妮妲”,让深圳这座高速运转的城市在星期二这天暂停了;感谢华为,让我这个来深10年,为生活奔波劳顿的人也能倚在窗前,眼观疾风骤雨之变,心游惊涛骇浪之中。
8月3日,一同事转来一个SQL,我打开文件,发现整个代码多达347行。




在DB中执行,时耗达到了4分多钟,再往下钻取,如同蜗牛一般,根本钻不动,14分钟过去了,还只钻取到了800行。
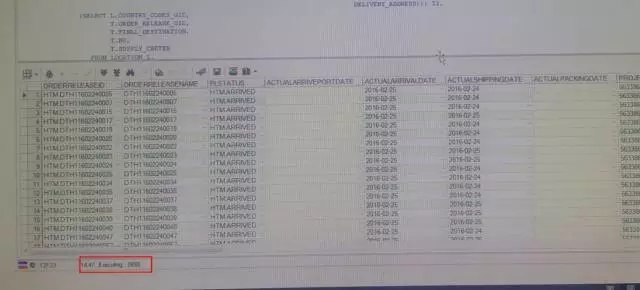
由此该SQL的性能表现为“两慢”:首条返回慢、下钻提取慢。大多数情况,我们只会遇其一,要么快速返回出现性能瓶颈,要么全部提取出现性能瓶颈。这回好了,都齐全了。透过窗户,望着被“妮妲”肆意狂虐后叶颤枝乱的树木,心里不禁在想:服务器也被“妮妲”肆虐了?
此时,台风“妮妲”疯狂过后的温馨凉意,也没能让我心如止水,毕竟这个优化任务看起来有些棘手。

人生若只如初见,初见往往是美妙的,让人心旷神怡的。而与该SQL的初次交流,画面却是暗潮涌动杀机四伏:
动辄千万上亿的数据量,近40次对象访问,还不包括VIEW中的表对象。
从SQL代码上看,出现了聚合函数,因此可以断定是批量数据处理。
以上两点,按经验,能2分钟跑出来就不错了,现在是要求2~3S,看起来是一个不可完成的任务。
在初步分析中,ORDER_RELEASE和ORDER_RELEASE_REFNUM两个表是最抢眼的,数据量分别是千万级和亿级,访问次数更是惊人的达到了10次以上。好奇心我决定以这两个表为切入口,探究下是如何被访问的?
借助于NOTEPAD++编辑神器,很快定位到了这两个表的访问情况:
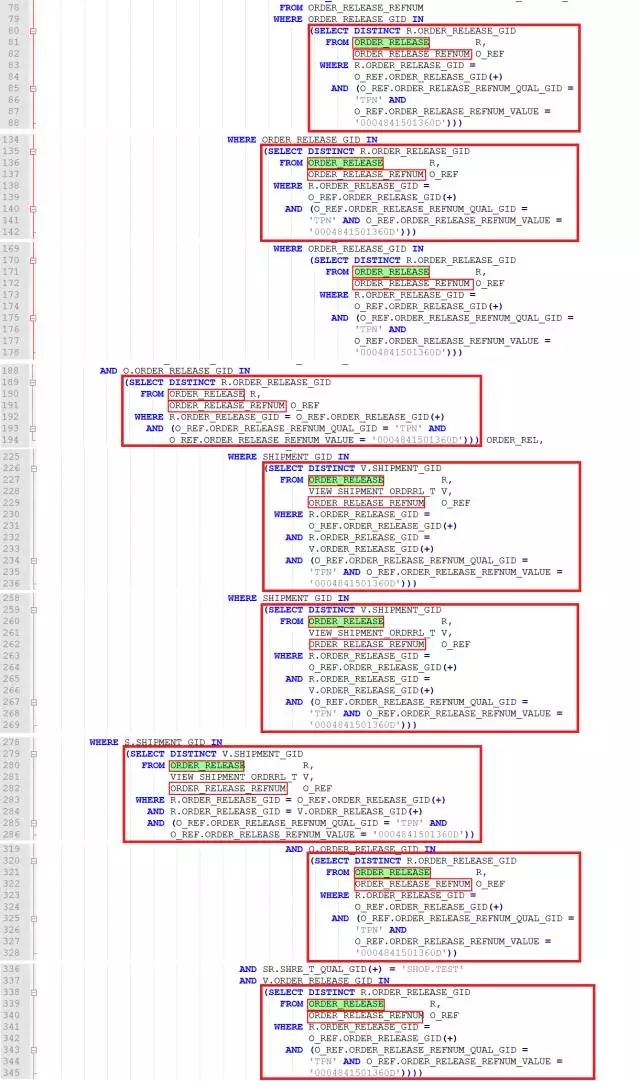
初步一看:
这两个表的访问基本上都是在子查询中,而且都是成对出现
仔细对比了子查询后,发现这些子查询可分A、B两类
A类子查询共有5个的代码都是完全一样的,如下:

4、B类子查询共有3个的代码都是完全一样的,如下:

深入子查询内部,无论是A类子查询还是B类子查询,ORDER_RELEASE R和ORDER_RELEASE_REFNUM O_REF的关联方式都是一样的,关联字段是ORDER_RELEASE_GID。此时,结合两个表的命名,按多年的经验,我猜想:
ORDER_RELEASE_GID为ORDER_RELEASE表的主键字段
ORDER_RELEASE_REFNUM与ORDER_RELEASE表存在主外键约束,字段就是ORDER_RELEASE_GID
为了验证我的假设,我VIEW了ORDER_RELEASE_REFNUM的表结构,如下:

果真如此。那么问题来了,即便如此,我们又能做什么呢?答案很简单,这两类子查询中,ORDER_RELEASE表可以被“砍掉”。等价的SQL如下:
A类:

B类:

再看看这个子查询的数据量:
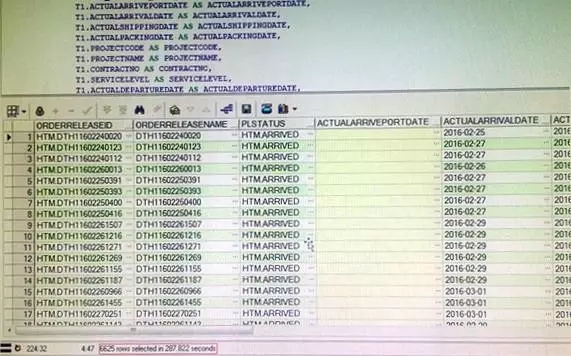
只有8千多条,相对于千万上亿,已经是非常少的数据量了。
结合上述分析结果,我对SQL做了如下调整:
将A、B类子查询用两个with子查询代替,这样就能减少大表的访问次数;
在A、B类子查询中,将ORDER_RELEASE表“砍掉”,减少表关联带来的IO开销;
由于子查询的数据量非常小,将之前的IN子查询改写为INNER JOIN,这样就可以形成小结果集驱动大表的效果。
调整后的代码如下:



对于这次的优化,我并没有抱什么希望,因为这仅仅是常规性的精简,还没有深入到代码内部。或者说,这还仅仅是规范性改写。
果真,执行仍然需要耗时4分多钟,但是,这次的精简并不是没有任何收益。因为当往下钻取时,速度非常快,钻取完6625条记录不到10S。
不知不觉中,已到了下班时间。台风过后,残阳西下,不再燥热,难违暖意,别有一番韵味。
第二天一上班,就开始接着昨天的节奏继续优化。
SQL的精简并没有为快速返回带来任何收益,我决定看下执行计划,尝试着从执行计划中得到更多的信息。果真,F5后看到的执行计划中,一个VIEW的COST犹如“鹤立鸡群”,特别的扎眼:

从执行计划看,Oracle对这个视图做了传统的处理,没有合并,也没有谓词推入。所以视图中的表基本上都是table access full。此时,突然想起在当时统计表对象的时候,记得只有一个视图,而在昨天在精简B类子查询的时候,也出现过一个视图。那这两个视图应该是同一个了。而昨天B类子查询的速度是非常快的。
我赶紧将执行计划定位到了B类子查询,如下:
原来如此,在B类子查询中,该视图被merge了。
受此启发,我也计划将主查询中的VIEW通过HINT进行MERGE,但是HINT似乎并不生效,始终都无法改变现有的执行计划。无奈之际,只有深入SQL,实地窥探这个VIEW到底“何德何能”,会让ORACLE优化器如此“死心塌地”的“维持原判”。

从上图中可以看出,该视图与A类子查询进行了关联,而事实上,B类子查询就是该视图与A类子查询关联的结果呀。怎么在这里又要临时关联呢?难道昨天做精简的时候还存在漏网之鱼?
再看代码:

原来这里需要获取该视图的两个字段,而在B类子查询中,我们只获取了SHIPMENT_GID一个字段。那是否可以直接在B类子查询中加一个字段呢?
我们再来看看B类子查询的代码逻辑:

在这里,我们获取了SHIPMENT_GID字段,并对该字段通过DISTINCT去除了重复值。这样做的目的在于,在后面调用该子查询时,以该子查询为驱动表,驱动关联其他表对象。因为子查询的结果集很小,而被关联的表对象都是千万上亿级别的。
很显然,如果我们在B类子查询中增加ORDER_RELEASE_GID字段,就会影响到SHIPMENT_GID的唯一性,这样,在后续的关联查询中,就不能直接用B类子查询驱动关联。这会直接破坏掉已经建立好的驱动关系。
既然增加字段之路行不通,那就尝试着再增加一个WITH子查询,代码如下:

与此同时,对访问该视图的代码也进行了适应性的修改,修改后的脚本如下:




再次执行,耗时2:28,虽然与秒级的性能要求相距甚远,但是至少性能提升了近50%,其意义并在于提升的效果,而在于证明了优化方向是正确的,即在大表林立群狼环视虎视眈眈的环境中,要快速准确的定位出驱动表,需要明确将驱动表数据准备好。
性能尚未达标,优化仍需继续。
先看看执行计划:

从COST列,并没有看到成本特别高的操作。所以,我放弃了继续在执行计划上做文章,转而深入分析SQL代码逻辑。
经过一番抽丝剥茧起承转合后,SQL的整体代码逻辑也呼之欲出,发现顶层的逻辑设计非常简单明了,就是三个子查询的结果集内连接,如下图所示:

接下来,我做了一件被人“鄙视”的小儿科的事,就是分别执行了这三个子查询。原本想着总会有一个慢的,我就重点优化慢的那个子查询。而结果却出人意表,三个子查询都是在2S左右就能完成执行,而且数据量都在1万以内。那为何三个子查询关联在一起,性能会如此受影响呢?要知道,如果是三个1万以内的表关联,即便是无任何索引,那也是秒出呀。
那么问题出在哪里呢?没的说,肯定是执行计划并没有按我们预想的去执行这个SQL。此时,我也没有心思去仔细分析执行计划,而是直接祭出了第三板斧通过with子查询的方式将ORDER_REL、SHP、REL三个子查询封装成结果集,改写后的SQL如下:





再看执行计划:
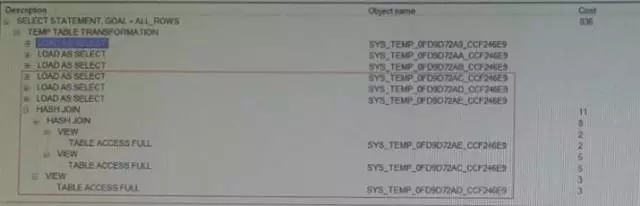
看起来与我们预期的效果一致了,而关键还是要看执行的效率。
3.5S,再往下钻取,也不到10s皇天不负有心人,终于可以画“句号”了。此时,已经是第三天上午,距离拿到原始SQL将近2天的时间了。台风“妮妲”早已销声匿迹,来也匆匆去也匆匆。你方唱罢我登场,立秋前的烧烤模式再次以胜利者的姿态,歇斯底里的“蒸烤”着这片大地。而躲在空调房的人类,也在尽情的透支着地球赐予的有限资源,最终会如同这个SQL一样,终有一天会引发灾难;而再去治理,再去挽救,需要花费更多的资源与精力。
从4分钟到3.5S,从钻取卡顿到一泻千里,整整经历了近2天时间,耗时之长在以往的优化案例中实属少见。事实上,当一开始拿到这个SQL时,尤其是在了解到这个SQL及背后的数据环境时,我心里面是直打鼓的。可以说,是硬着头皮拿下了这个SQL,现在回想起来仍然后怕。然而,除了后怕,更多的是该案例优化过程中所体现出的SQL(优化)精髓:精简之道、驱动为王、集合为本。
大道至简、简单即高效、复杂的事情简单化等等这些我们喜闻乐见的生活常识,同样适用于SQL(优化)。记得SQL优化大师曾说过:不要让ORACLE做多余的事。而对于ORACLE而言,多余的事情是什么呢?多余的表关联、重复的表访问、冗余的关联(过滤)条件、不必要的DISTINCT\ORDER BY\GROUP BY、曲折的访问路径。虽然ORACLE优化器引擎也在努力识别并消除这些“多余的事 ”(可参见博客,然而,在面对复杂的SQL时,ORACLE也往往束手无策。因此,SQL优化的首要之事就是精简SQL。
有这样一句话:一头狮子领着一群羊,要胜过一头羊领着一群狮子。这就道出了“领头”的重要性,在ORACLE优化器中,就是“驱动表”。驱动表的意义有如木楔子,只有薄如纸片锐如刀刃的楔子,才能轻而易举的插入坚硬木桩中。如果给你一个圆头的木头,任凭你力气再大,也不能插入。这就要求驱动表的数据量要足够的少。尽管ORACLE优化器也在努力寻找合适的“领头”,而有的时候,ORACLE优化器会被腰里别了杆枪的老鼠给骗了。比如本案例中的A类子查询,起初是通过IN子查询进行过滤的,这就存在很大的性能风险。关于驱动表的优化案例有很多,后续会专题分享。
集合操作是二维关系数据库引擎在数据处理时的根本,单表是一个集合,多表关联后的结果也是一个集合,视图、子查询的返回结果还是一个集合,整个SQL执行完后的结果仍然是一个集合。
因此,一个高效的SQL一定有一个合理的集合运算结构。根据业务需求,结合代码逻辑,有的时候需要将代码片通过子查询封装;而有的时候又需要将子查询合并到主查询中;有的时候需要将大集合根据业务逻辑切片成多个小的集合;有的时候又需要将若干个小的集合预先合并成大集合。总之,在进行SQL(优化)时,一定要有集合的概念,用集合的思维指导SQL(优化)。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721