
作者介绍
黄浩,现任职于中国惠普,从业十年,始终专注于SQL。在华为做项目的两年多,做过大大小小的SQL多达1500个。闲暇之余,喜欢将部分案例写成博客发表在华为内部数据库官方社区,反响强烈,已连续四个月蝉联该社区最佳博主。目前已开设专栏“优哉悠斋”,成为首个受邀社区“专家访谈”的外协人员。
在《一次耐人寻味的SQL优化:除了SQL改写,还要考虑什么? 》中提到的上一个迭代版本刚刚结束,一开发同事便找到我,说有个SQL需要优化,原以为是刚上线的SQL出现了性能问题,心里还咯噔了一下。详细了解后,才发现时虚惊一场,原来是本次版本的一个新需求产生了性能问题。
拿到SQL的时候,发现非常简单,如下:

在简短沟通后,得到如下信息:
该SQL的功能是从TM_TASK_T和TM_TASK_HIS_T表中找出相同的数据,即得到两个表的交集;
除了该SQL外,还存在另外9个类似功能的SQL,其共同点是获取当前表和历史表的交集;
该SQL耗时大约在20S左右,但是全部10个SQL的耗时加起来就超出了120S的超时阈值;
这一系列SQL的目的是检验数据的唯一性,即确保当前表和历史表的数据不重复。
1看执行计划
我开始对该SQL进行分析,SQL看起来非常简洁,就两个表关联,并且全部字段都来自于HIS表。执行计划如下:
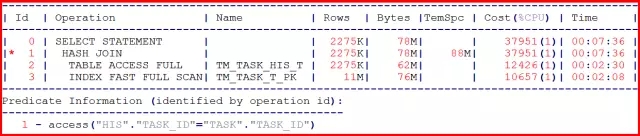
因为整个SQL中TM_TASK_T表只在关联条件上访问了TASK_ID字段,而TASK_ID上又创建了UNIQUE索引TM_TASK_T_PK,所以对TASK表的访问方式是:INDEX FAST FULL SCAN,也就是没有“回表”(table access by index rowid)。
我又查看了两个表的数据量,HIS的数据量为500万+,TASK的数据量接近4000万,TM_TASK_HIS_T为驱动表,并且与TM_TASK_T表HASH JOIN也是正确的选择。
因此,从执行计划上看,似乎没有什么优化的空间了。
2等价SQL改写
再回到功能上,SQL的功能是获取两个结果集的交集,再看看这两个结果集的关系,从表对象的命名上就可以猜出个大概:即TM_TASK_HIS_T表是TM_TASK_T表的历史表。而TASK_ID是TM_TASK_T表的主键,所以在取交集的时候,只需要TASK_ID字段。
那么,在TM_TASK_HIS_T表中TASK_ID是否也有索引呢?查看了表结构后,发现在TM_TASK_HIS_T表中,TASK_ID上也创建了主键索引:TM_TASK_HIS_T_PK。
此时,一个习惯性优化方案在脑海中闪过:可以通过这两个主键索引先获取TASK_ID的交集,再根据TASK_ID交集从TM_TASK_HIS_T表中获取字段信息。
根据上述思路,我将SQL改写如下:

改写后的SQL耗时在10S左右,性能提升了1倍。
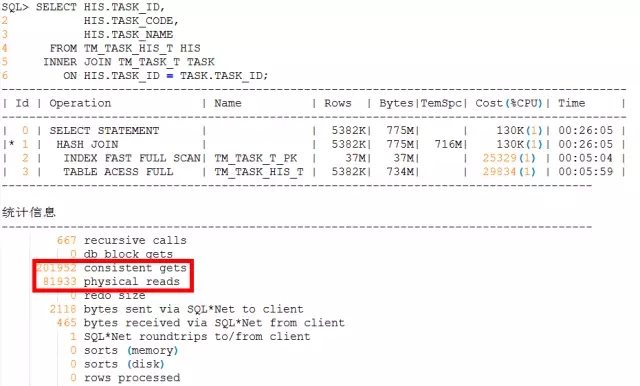
我们先对比下前后两个执行计划:
改写前的执行计划:
改写后的执行计划:
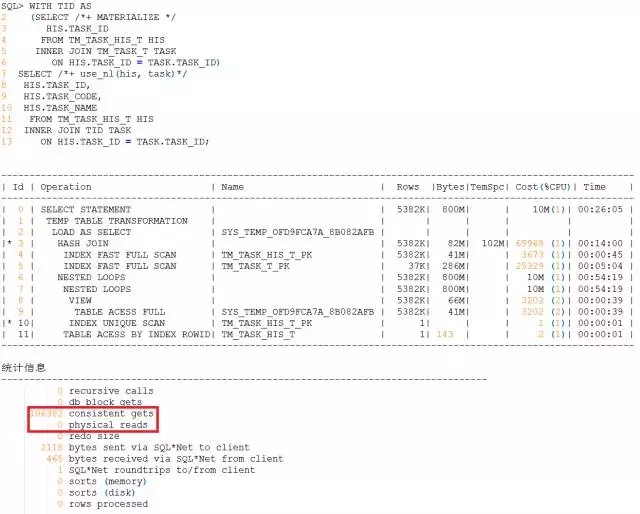
可以看出,改写后在IO读写上还是有很大提升的。但是,现在的问题是,这种提升似乎还是无法从根本上解决性能问题,仍然存在超时的风险,而且随着数据的增长,风险的概率也越来越大。
然而,基于SQL的优化空间在性能要求面前显得捉襟见肘。
3技术方案调整
既然SQL本身上无法突破,那就退一步,从功能框架上看看是否存在“突破口”。
此时,我想起了当时沟通是得到的一个信息:“除了该SQL外,还存在另外9个类似功能的SQL”。我进一步的了解到这10个功能点是相对独立的,即相互之间不存在依赖,也就是说,这10个原本串行执行的SQL是可以并行执行的,这样一来,耗时的计算方法发生了变化:

性能耗时从串行执行的求和变成了并行执行的求最大值,也就是说,如果选择了并行执行,只需要保证单个SQL的最大耗时不超过120S即可。而这点显然是可以完成的。但是开发同事则极力反对,反对的理由是:
这一系列SQL被应用程序封装成一个任务,该任务并非定时执行,而是人为手动执行,如果被拆分成10个任务,也就意味着需要用户手工触发10个任务,用户体验太差;
拆分成10个任务,不利于后期的维护管理。
以上的两个理由,尤其是第一个理由,的确无可辩驳。
4探究原始需求
看来由串行改并行,此路不通。尽管如此,生活还要继续,优化不能停止。此路不通,只能另觅他方,再退一步,回到SQL的最原始需求,从最原始的需求出发,看能否找到优化的空间。
解铃还须系铃人,再次与开发同事进行了深入沟通,了解到的信息如下:
在日常业务运营中,因为业务需求,需要从当前表清理掉一部分数据,在清理前,程序会将本次要清理的数据写入到历史表中,然后再清理;
由于一些异常情况,会导致被清理的数据写入了历史表,而没有从当前表中清理掉;
为了及时发现这些异常数据,在后台启动了一个定时任务,周期性的监控历史表与当前表的数据;
当监控到数据异常(即重复)时,就会手工触发这一系列的SQL清理数据。
此时,我的第一反应是:能不能跑增量数据?目前是全表判断是否重复,如果能做到增量判断,性能的提升肯定是质变的。我设想的增量方案是:以TM_TASK_HIS_T表为主表,获取到自上次数据修复到本次数据修复期间的TASK_ID,判断这些TASK_ID是否在TM_TASK_T表中存在?
增量的思路是让人兴奋的,但是如何做到增量呢?现有的模型结构是否能支撑增量方案呢?
说到增量,最先让人想到的是时间字段,在HIS表中有CREATION_DATE和LAST_UPDATE_DATE,我们一般都会用LAST_UPDATE_DATE来识别增量数据。HIS表中的LAST_UPDATE_DATE字段能用作本次的增量识别依据吗?
经过一番论证,发现不能作为增量识别依据,理由是:当数据从当前表写入到历史表时,LAST_UPDATE_DATE字段值是不会发生变化的,也就是说写入到历史表的LAST_UPDATE_DATE值是不连续的,自然就不能用作增量识别依据。除非我们在写入到历史表的时候,将LAST_UPDATE_DATE的值赋为sysdate,但是显然是不允许的,因为这样一改写,就破坏了数据的原始性。
LAST_UPDATE_DATE不行,CREATION_DATE就更加不行了。难道增量方案就这样夭折了吗?
5山重水复疑无路,柳暗花明又一村
目前,TM_TASK_HIS_T表缺少这样一个字段:能识别出数据写入到历史表的时间。如果有这样一个字段,我们就能用来作为增量识别的依据。既然没有,那么我们就可以新建这样一个字段,一方面记录了数据被清理到历史表的时间,以便后续核查;另一方面也满足了增量识别的需求。两相欢喜,何乐而不为呢?
一开始,开发同事也不反对,紧接着他好像觉察到了什么?很是抵制,连说三个“不行”。原因是增加了这个字段后,他需要同步修改涉及到新增字段的代码。我淡淡的说:不用担心,在创建字段的时候,增加sysdate的默认值就行了。
6总结
这个优化案例很简单,但是过程却有些曲折漫长,也显得有些另类,因为这不是一个典型的基于SQL的优化案例,它最终是通过优化业务逻辑来满足了性能需求,当然为了支撑这个业务逻辑优化,又涉及到了模型、SQL的变更。这个案例的意义在于它的整个过程涵盖了因SQL引发性能问题的解决方案的全路径:调整执行计划—>改写等价SQL—>优化技术方案—>优化业务逻辑。
在SQL优化的过程中,我们都习惯性地止步于改写等价SQL,一方面,80%以上的问题都能通过这两步来完成,另一方面这两步我们拥有完全的控制权。然而,当我们走完前两步仍然没有解决性能问题的时候,就需要考虑再往前迈一步,走出这一步,或许就海阔天空了。而迈出这一步是艰难的,原因如下:
迈出这一步后,我们就需要与更多的人员沟通,这是SQL优化人员的普遍通病,宁愿自己花10个小时闷头苦干,也不愿意花一分钟与相关人员沟通;
迈出这一步后,我们就失去了优化的完全控制权,我们需要面临利害相关人员的干预,甚至抵制,他们会说:这不行,那也不行。因为我们的优化方案会导致他们做适应性修改,触动了他们的利益堡垒;
迈出这一步后,我们就需要有一颗强大的心脏,随时准备与相关人员PK,接受他们对优化方案的质疑,并不断完善优化方案;
迈出这一步后,我们就进入了一个利害纠纷的圈子,为了实施我们的优化方案,就需要与涉及到优化方案的相关人员博弈。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721