

讲师介绍
黎嘉豪,百度资深敏捷教练,曾任职华为资深云计算专家,负责云计算中资源调度的设计和研发。加入百度后聚焦于产品级CI和DevOps,从方案、技术、工具等层面全面持续交付能力的建立,先后在百度开放云、度秘、Simeji日文输入法、百度杀毒等产品实施研发改进工作同时也是百度技术学院《持续交付》《研发工具链》等课程的讲师、软件匠艺小组讲师。
互联网时代对软件交付的诉求
从传统的ICT企业进入到互联网企业后,身边的人总会问我,我们现在处于一个什么样的时代?这里我引用之前听过的一个词,我们现在处于的时代是一个叫做VUCA的时代。
VUCA是什么意思呢?在过去的一两年,我们的衣食住行都产生了很大的变化,例如我们从自己开车变成打车,从加班吃方便面变成叫外卖,跟团旅游变成自驾游,我们的需求在变,用户在变,业务模式也在变,就是说,我们在做互联网产品时,所处的环境具有易变性、不确定性,复杂性和需求的模糊性。准确来说,什么都是不确定的,除非用户满意。
因此,很多时候,我们做产品都是在balance两个要素,一个是效率,一个是质量。它们贯穿于持续交付的整个流程,也是评价的标准。这两个词大家应该很熟悉了,我这里快速过一下。

效率是什么?大家应该都听过互联网的七字诀,就是专注,极致,口碑和快。另外一个点,也是最近比较潮流的观点——“只有第一,没有第二”。通过优酷和土豆、美团和大众点评的合并,可以看到互联网的世界是十分残酷的。如果你比别人慢,那不好意思,你就失败了。关于质量方面,作为互联网跟用户比较贴近的一个场景,就是我们会比较讲究用户体验、细节,还有就是缺陷必然导致用户的卸载跟差评,此外,服务的故障必然导致市场的丢失。
但有些时候,如果为了加快产品推出市场速度,反而会适得其反。三星新手机Note 7,就是一个活生生的例子。网上有一个段子说,也许三星三个月之前就知道苹果7这次的发布会没有任何功能的更新,没有亮点,所以他们花了三个月的时间把所有的黑科技全部放在Note 7里,这使得三星不断压缩渠道生产质量,进而导致了电池爆炸和召回事件。可想而知,最后Note 7成为国人最容易获取得到的大规模杀伤性武器。
看到这种案例,我觉得非常痛心,因为在互联网做产品时,这样的事情经常发生。所以今天的分享,我会以之前支撑过的一个项目作为背景(具体产品不便透露),讲述项目最初发现的问题以及我如何带着他们实践持续交付,最后罗列一些从中得到的启发,希望能对各位有所帮助。
团队的挑战
如何让持续交付成为新产品的成长思维,一般的套路就是开始吹嘘持续交付如何牛逼,如何让一个产品成功。但这个我真不敢讲,IBM大型计算机之父Fred Brooks曾说过,由于软件的复杂性本质,没有任何一项技术或方法可以使软件工程的生产力在十年内提高十倍。简单来讲,持续交付也不是银弹。

去年年初,有一个项目找到我们,他们当时正处于上图的浅绿色阶段,也就意味着他们已经在国际化的市场深耕了一段时间,积累了一批重视的用户群体,希望我们能协助他们完成用户的快速增长。
当时,我的搭档和我一起进入这个项目,他主要负责敏捷、精益等思维的导入,我则从工程实践方向来看,如何能帮助这个团队。

首先,我发现该团队已经简单地在用敏捷,迭代地方式开发产品,对比过去瀑布的发布方式,敏捷的引入让团队上线部署的频率从过去的半年、三个月缩短到一个月甚至两周。这种模式遵循的一个实践就是,上线的粒度越少,上线的频率越快,同时这样的模式比过去的瀑布发布方式更加安全。从理论来讲,这没有问题,但从实际操作来看,团队在短时间内较难达到快速上线和质量保证同时并存,而且控制不好的话,反而会造成Dev和Ops之间的矛盾加深。

百度是一个非常讲究数据、而且具备数据挖掘DNA的公司,所以早在两年前精益创业和精益数据运营的方法论就在这个项目推广开来,并且有了初步的效果。图中左边是一个精益的循环图,刚才也讲到了,精益能给团队带来的好处是很明显的,可以不断、低成本、快速地验证想法。
但这给团队造成了一个困惑:价值传递。数据监控的任务变得更多,造成用户服务的不可用,或者会出现一些奇怪的兼容性问题。验证、分析数据这样试探螺旋前进的方式,让团队的不少成员很难适应。
具体来讲,那个时候同时灰度发布验证的版本会有3~4个,过多的分支管理造成团队节奏上的失控,开发人员一方面在新一轮的迭代中开发需求,一方面又得为上一轮迭代收集数据和Review。所以一个同学早上可能在开发代码,突然下午就插个需求说,你要把上一个小流量版本做一下分析,看一下效果怎么样。当这样的情况不断切换时,团队的同学们可能就开始有点崩溃了。
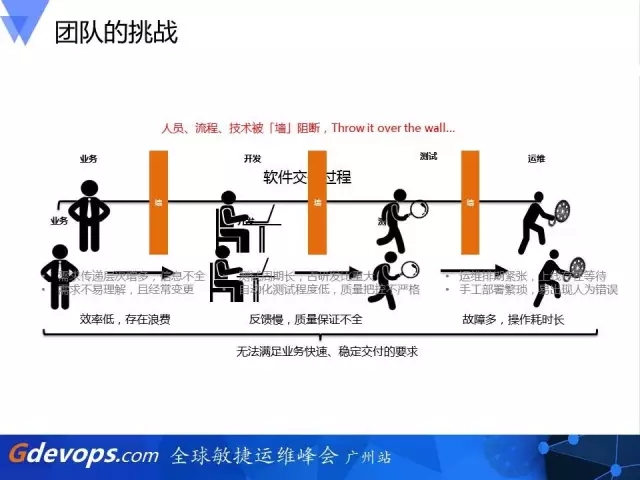
这是我们软件不断发展时角色的分工变化。最开始还是小团队时,我们可能一个同学就担任了几个角色,他可能既是一个开发,又是一个测试,产品也可以做,对这样的工程师我们有一个称呼,叫全栈工程师。这样老板请一个人就能全部包办了对不对?这样的情况下其实特别美好,因为在整个架子的流转过程中,没有任何数据的丢失。当我们团队开始人多时,这种小完美的状况就有种一去不复返的感觉了。
因为团队成员的增加,一方面我们要投入培训的成本,另外人多后,同一个团队不同职能的同学容易陷入烟囱式的发展。当大家各自的出发立场不一样时,就会发现在一个团队不同职能的小组里,开始出现了一堵无形的墙。当开发、测试、运维相互价值流动时,就变得像以前在学校传纸条那样丢过去,这样的模式无疑是低效、并且常常会在传递的环节造成信息的浪费与丢失,无法满足我们业务快速稳定的增长。
回顾这几年的发展,特别是研发(RD)和运维(OP),我们来看看他们的演进。

这里有一张图,从左边到右边过一遍。在开发领域里面,我们经历了从传统的瀑布方式到敏捷再到DevOps模式的演变。关于技术架构,我们也不断地更新,最早时的架构我们叫大合创,就是所有的代码支撑、构建部署、交给客户、上线都是那一个,这样的产品庞大起来之后,就变成了中间一个多层次的分层架构。到了这几年我们发现分层也有瓶颈,现在推行的是微服务的架构。微服务架构能带给开发的一个好处就是,服务的粒度更小,而每个功能都有单独的API接口,开发和部署周期越来越短。
在运维领域,有两个点很重要,一个是部署和打包的变化。最早我们是直接部署在物理机里,慢慢地改成部署在云主机,再到现在的容器。部署的方式不一样,底层的基础设施架构也在升级,从最早的自己组建数据中心、到之前听到的魅族把主机寄投在其他IT机房里,再到现在压根就不用我们去管机器,直接用云这样的模式变迁。

所以我们看到,在这几个领域里面,开发和运维都在不断更新各自的工具,开发因为技术的提升,部署的节奏粒度越来越细,部署的频率则越来越快;运维的同学们则希望线上稳定,对上线的代码时刻警惕,担心会破坏线上服务。
独立的两个团队如果发展有一段时间的话,他们所用的工具和技术就会有隔阂,具体讲就是相互不太理解对方的工作方式和原理,久而久之,就会在上线或者代码回滚的流程中出现一些问题。通常来讲,这不会出现在一般的上线流程中,但在小流量的上线或上线失败时,RD同学就会因为不熟悉工具踩到一些坑。
所以在项目组里,我们深信有一条路,这条路可以让项目组的同学轻松一点,但这条路也不是那么平坦,也存在很多问题。
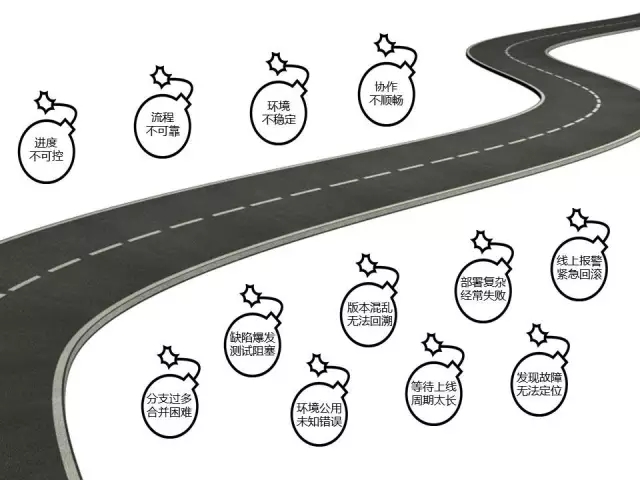
例如进度不可控,在我们的项目里面,会经常听到RD同学这样说。第一天RD同学很开心地说他已经完成了60%,第二天他仍然很开心地说已经做完了90%,那按往常来讲,这个东西到第四天、第五天肯定可以上线了,可事实不是这样的,在第三、第四天我们会发现RD同学的表情开始有点惆怅了,然后他在汇报进度时会说还是有问题。为什么呢?因为RD和项目经理对需求的概念不一样,RD更多觉得做需求就是看开发的进展怎么样,他没有考虑到系统测试、提前测试和上线的一些因素,导致了项目的进度比较难把控。
第二点是流程不可靠。当一个小完美团队往大团队发展时,必然有几个支撑RD和运维的人站出来,由他们来掌控产品的整个流程。整个产品怎么开发,怎么上线,只有他们最清楚,其他的同学都不太清楚。这就会导致整个团队运作不起来,特别是如果这些同学离职了更会给团队造成明显的压力。
第三点是环境不稳定。我们经常会听到这么一句话:这个软件在我的机器里部署没有问题,为什么到了你的机器那就有问题了?当我们没有统一机器的时候,这类问题经常发生。而且对RD来讲,这个问题要不要去定位是很难把握的,因为有可能这个问题出现了一次后就不再出现了。
第四点是协作的不顺畅。就像前面讲到的,每个角色在价值流动时,都会有一堵墙,把信息中断了。还有很多问题,例如分支过多、合并困难,缺陷爆发、测试受阻,环境公用、未知错误,以及版本混乱无法回溯等等。
所以,当时我一直思考,用什么方式能帮助项目组解决这些问题。
我们的目标

让我们回到敏捷宣言的第一条,我们做产品就是为了快速、持续不断地将有价值的软件交付给客户,并且希望他们满意。这是指导项目进行软件开发的价值准则。所以,版本我们要发,稳定也是需要的。怎么做到这个最终目标呢?这里项目组当时和我一起分解了几个小目标。

缩短提交代码正式部署上线时间,降低风险
能够自动的、快速地提供反馈,以便及时发现和修复缺陷
能够让软件在整个生命周期处于可部署的状态
能够按一下按钮,就能将任意版本、按需部署在任意环境中
能够让整个交付过程变成一种可靠、可预期、可视化的过程
打造一条可视化的持续交付流水线
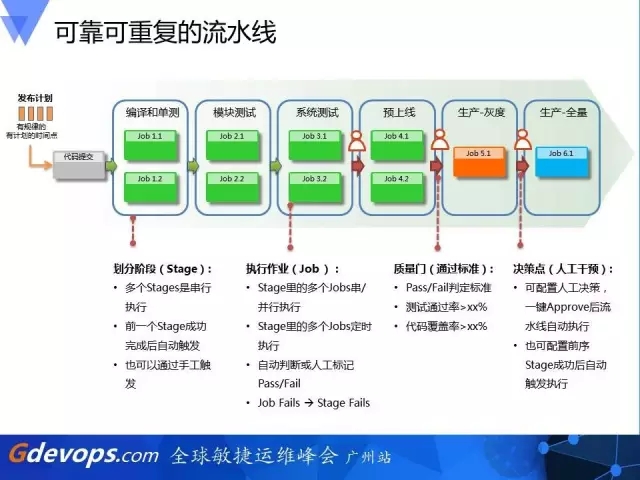
首先,我把团队所有的人都拉在一起,有RD、QA和运维,让大家脑袋里面的想法通过落地于流水线而让全部的成员知晓。这是当时画的一个图,这个图中还有一个特殊的点,就是我们要组建自动化,但不能说把所有东西交给机器,必须设置一些小人即我们人工review的环节来确保版本上线时是可控的。
例如,那天的讨论会就能听到上线环节复杂时,RD在体测环节还有发上线单环节提出了自己的怨声,说好几次填错版本号,运维的工具也没有提示这个版本是没有经过QA测试的,导致上线了错误的版本。而且回滚的时候还需要填写历史的版本,为了查询上一次的版本号信息,又耽搁了十几分钟。
当RD说完这番话之后,运维的同学就开始跳起来,说为什么不安排他们的同学来上线,RD说申请了,但是等待上线的任务太多,版本需要紧急上线,来不及了。
所以,后面我们以敏捷宣言的准则,和RD、QA、运维的同学画出了下面的流程图,对比上面的环节,我们可以看到整个流水线的步骤增加了不少,但是每个流程之间基本都是自动触发的,而且每个角色的同学都很清晰自己负责的范围。一旦这个流水线建设好了之后,与会的所有同学便都有信心来操作上线步骤。这个在过去是无法做到的,大量的上线任务都只能靠运维或者RD来执行。

如何组成这样一条流水线?我这里讲6个点,不是很多,但这每个点都是必不可缺的。包括配置管理、构建管理、持续集成、测试管理、环境管理和部署管理。每一个元素在流水线上都有它存在的意义。接下来我挑几个来讲一下。
配置管理

传统来讲,我们认为配置管理就是代码的管理,实际上它的定义远大于这个。凡是我们引进研发里的所有变更,都属于配置管理的内容。除了版本管理,还要组建依赖管理,我们依赖的第三方组件的版本是什么,这些都要记录下来。另外一个点就是软件配置管理,一般来讲软件和配置是分开的,为了适应多环境的部署,在这里要管理起来。最后经常被遗漏的一点就是环境管理,很多时候我们想部署回去两个月或者一年前的版本,但是失败了,就是源于我们的内核和基础设施的变更。凡是这些相关的都要管理起来。
在这里,除了刚才讲到的全面配置,再把配置管理里面我觉得比较重要的点分享一下。
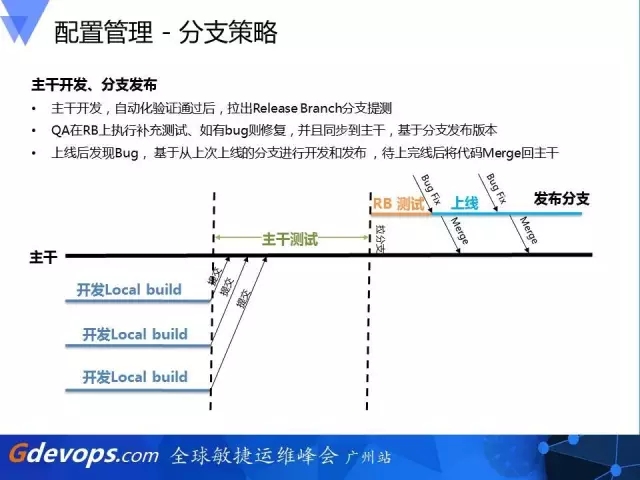
这是我们的分支策略。
在百度内部,我们推荐主干开发、分支发布这样一个模式,我们希望QA在分支上进行一个补充测试,如果有bug的话,我们的RB测试就会在分支和主干里面进行修复。如果上线发现bug的话,我们也可以很清晰的有一个分支与之对应。
前面我提到精益到了一个团队里面会出现一个问题,就是很多线上的访问无法跟踪,很多跟着跟着上线后就死掉了,这时候我们引入一些叫feature flag(特性开关)的功能到架构里,希望能够让一个branches里面的产品在线上根据机器的不一样来展现不一样的特性,从而满足精益试验的效果,减少过去特性分支的拉取。所以我们会比较严控地去拉分支,避免线上过多版本的跟踪。

Check in dance, 这是多人开发、代码合并、持续集成的俗称说法,有8个点。作为一个RD你要提交一个代码时,你要check out代码,执行本地构建没问题了,再check out代码,避免跟别人冲突。在执行本地构建没问题后,再提交到主干,等待主干上的编译、持续集成的结果,如果失败了,不好意思,你要再来一次。
但是到了敏捷,我们不再走这样一个老套路。我们引入了Gerrit的评审流程,把更多的东西交给机器去处理,准确来讲,我们的RD只有两个键,一个是拿去代码,另一个是提交代码,这里和过去有什么区别呢?意味着我作为一个RD,我只需要把我的代码提交到库上面去,可这时代码是没有入库的,我们的评审系统会很智能地把主干上最新的代码加上RT这一次提交的代码,自动合并成一个提交、评审,再交给自动化测试流程。只有自动化测试流程通过了,我们的RD经理才会让它评审通过,并且具备合并到主干的权限。合并到主干的权限后,还有下一个持续集成的流程,去验证我们的产品集成后有没有问题。
构建管理

接下来讲一下构建管理的优化。在我们原来的编译中,构建管理是自己的本地机器或项目组里的机器去进行的,后来项目组为了缩减原来12分钟的编译时间,设置了一个叫“1-5-10”的法则,我们希望的构建是一分钟最好,5分钟是一个比较优秀的阶段,超出10分钟是不能接受的。我们引入公司的编译集群,把我们的编译用户分发到公司所有可以接这个业务的机器上面去做,并且这些机器都是针对编译进行过CPU的优化。
同时,我们的构建任务也一改过去的Push,改成拉取的状态,这是个很有意思的问题。举个例子,过去想编译一个版本,我们的组件可能会依赖三个外部的库,我们一次构建,会拿外部的库的代码下来,然后触发构建,再一起build,这样的模式我们称之为Push。构建自己的模块时,也需要把外面的库构建一遍,比较浪费时间。后来我们就改成Pull,只care自己的那一块,其他人可能会随时开始触发构建,并把最新稳定的编译结果放到一个产品库里,当我们需要构建时,只需对它们进行一个拉取编译,速度比过去快了很多。
持续集成
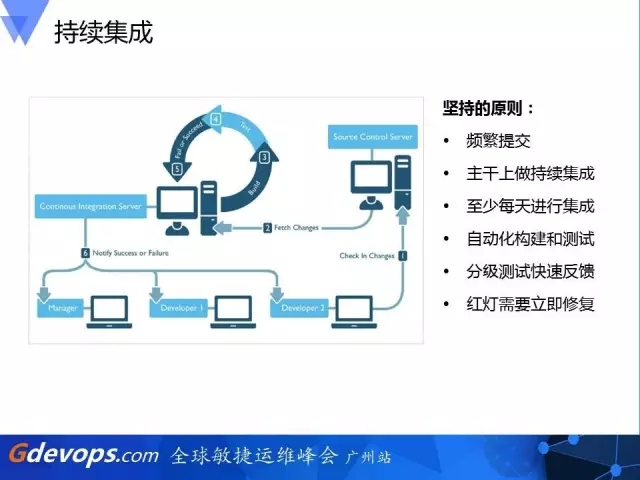
持续集成的话,就是给团队不断深化,这里也给出了一些原则,包括:
频繁提交
主干上做持续集成
至少每天进行集成
自动化构建和测试
分级测试快速反馈
红灯需要立即修复
测试管理


关于测试,我们组建了一个分级的Jenkins,严格把握时间的分级测试。此外,我们通过建立分级测试体系,保证编译和测试结果尽量保持在10分钟之内就有一个基本的校验。
环境管理
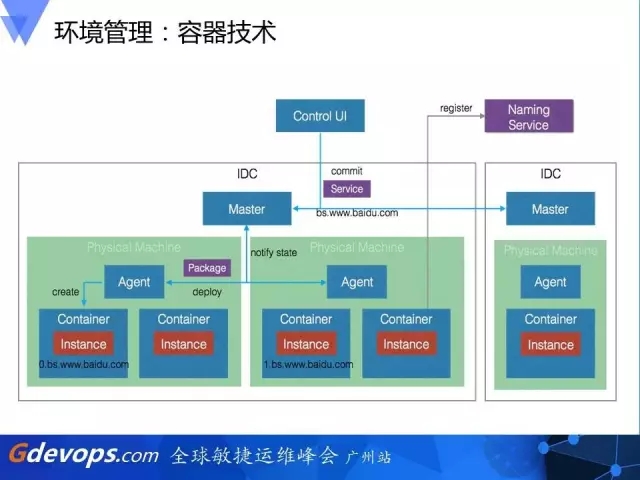
这是百度内部容器管理的架构图。我们OP和RD的同学组建了三个层级的容器服务,包括服务管理、资源管理和机器管理。这样的好处是让OP和RD都有自己的视图去看他们关心的东西是否良好,从而避免过去运维系统的复杂和难使用。

对比容器和虚拟化,这里讲一下我的经验,因为我过去在华为和百度里面很明显看到这样的区别。过去我在华为做私有云、公有云产品时,经历过最早的物理部署、虚拟化部署的环节,虚拟化部署时有一个问题,就是当软件OK了之后我们要进行虚拟机的镜像,这个过程一般是40分钟,打出的虚拟机镜像大概是6个G。一般来讲这没什么问题,但我有一次在德国给客户演示,发现这个等待的过程是痛苦的。
所以容器技术诞生的时候,它把虚拟化这个难点给解决了。容器做拉取不用一分钟,你的服务就OK了。然后去编译打包这个容器时,也很快,跟平时的编译时间差不多。还有就是它非常的小,一般600~700M就一个容器的镜像了。
部署管理

我们把部署管理里面的流程变成可配置化,把它作为一个表述语言的方式来控制话,从而达到某一个目标。

这是我们的灰度发布,通过组建,将线上的一些环境分成等级,让我们的部署系统可以先发布一部分的流量,验证没问题了,再去做流量的发布,并且小流量的发布也基于这样的策略来实施,这样的发布好处是让整个过程一目了然,并且回滚的策略也已经配置好了。所以每个同学都会很有信心地去操作。
最后,这是我在百度里面跟同事一起归纳总结的关于持续交付几个管理的实践总结:

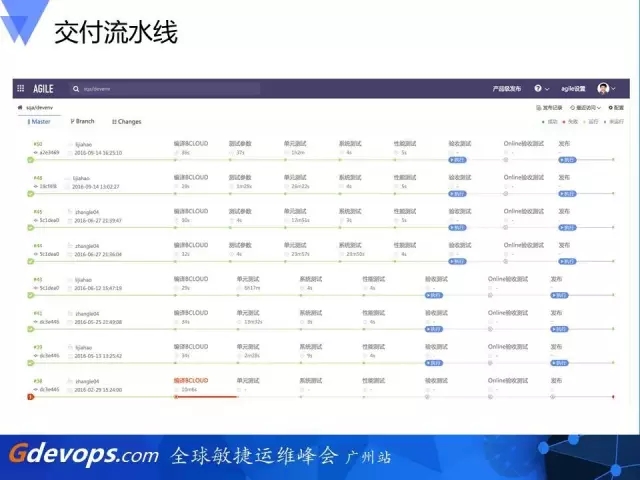
这是我们的系统,整个从构建到发布为一条线。大家可以看到右边有一些点,就是员工的审核点,都需要在员工的验证之后才能进行下一步操作。每个同学的情况也很清晰,究竟我的这次提交挂了没有。
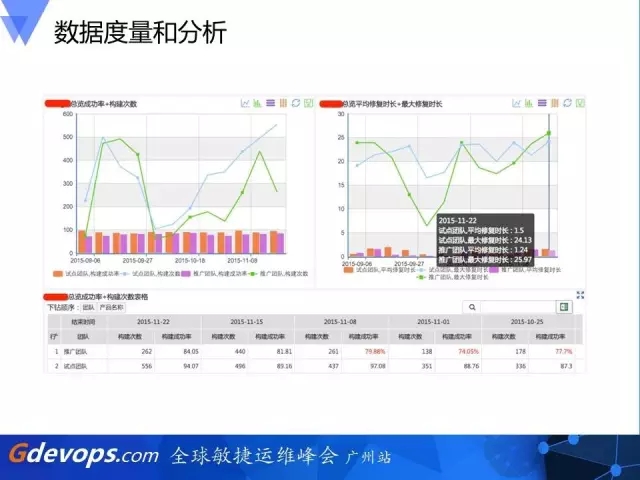
这是我们数据分析的报表。因为信息的问题,我只能截一些抽样的图。我们可以很快地看到上线的效果是怎样的。
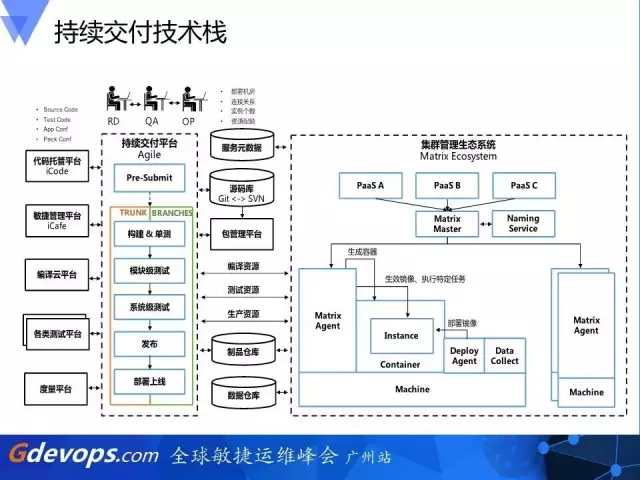
这是比较复杂的一张图,包含了百度整个工具链,从开发、运维和测试的一整个平台。左边是开发,中间是测试,右边是线上容器和部署平台。DevOps的技术有很多,我们只选取我们所需要的,组成这么一个架构来满足团队的使用。

这是一张持续交付效果图。从过去一个比较长的发布周期,到缩短了一半的时间,这是很了不起的效果。当我统计了后跟其他人分享,都觉得这很不错,因为我们没有刻意去引入一些什么事情,我们就是把整个工具链建立起来,把DevOps的思想安利给团队,结果我们就得到了两倍产值的提升。

测试周期、部署、交付也得到了一个非常好的变化。以前我们一天只部署三个,因为再多, OP受不了了,现在所有组件加起来,我们一天基本部署10次左右。开发到上线交付的周期缩短了53%,并且各个角色基于交付流水线紧密协作。最后做到的效果就是快速交付,保证质量,降低风险。

最后给各位,也是给我的老大汇报时的一个Judgment,你吹了那么多BB,怎么知道你的持续交付就这么厉害?我们只有两个评价的标准,第一个,修改一行代码从修改到上线需要多长时间;第二个,我们这个流程是否是可重复且可靠的。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721