

(点击“这里”获取欧阳辰演讲完整PPT)
讲师介绍
欧阳辰,超过15年的软件开发和设计经验,目前就职于小米公司,负责小米广告平台的架构研发。曾为微软公司工作10年,担任高级软件开发主管。热爱架构设计和高可用性系统,特别对于大规模互联网软件的开发,具有丰富的理论知识和实践经验。个人公众号:互联居。
大家好,我是来自小米公司的欧阳辰。早先我有幸进入微软公司,在那工作了10年,做了两个项目,一个是搜索,一个是广告平台。去年我又加入了本土的小米公司,做一些大数据平台的工作。此次大会的主题是“Gdevops”,其中的“G”代表了Global,而我正好在微软、小米积累了一些全球化的经验,今天就自身所得给大家分享一下。
本次演讲包括以下内容:
什么DevOps
微软是如何做DevOps
小米是如何做DevOps
如何成功向DevOps转型
DevOps的基础架构
一、什么是DevOps
我对DevOps的4个观点
第一,所有竞争性软件公司终将采用DevOps。
第二,DevOps不是银弹,从本质来看,它是一个工作效率的问题,哪种工作效率好就采用哪种方式,不管是叫DevOps、OpenStack,还是敏捷开发、敏捷测试都无所谓。
第三,大量专职运维和测试职位可能慢慢会减少,转化成一种DevOps的模式。(这块后面我会解释为什么)
第四,“靡不有初,鲜克有终”。可能很多人会有转型的观点和想法,但执行起来有很多的困难。
“测试已死”?!

2011年在印度召开的谷歌测试大会上,作为谷歌工程非常重要的一个人物——Alberto Savoia在会上发表了一个开题演讲,这个演讲的题目就叫“Test is Dead”(测试已死)。他的观点很明确,在互联网世界,如果你发布一个产品没有任何质量问题,这样的产品是失败的,而且也发布得太晚了。他认为,很多测试的质量问题实际上在测试实验室里是发现不了的。Alberto Savoia还有很多有趣的观点,有空大家可以找来看看。
但是,我今天不是来宣布“测试已死”或者“运维已死”,我主要想和大家分享一个观点。
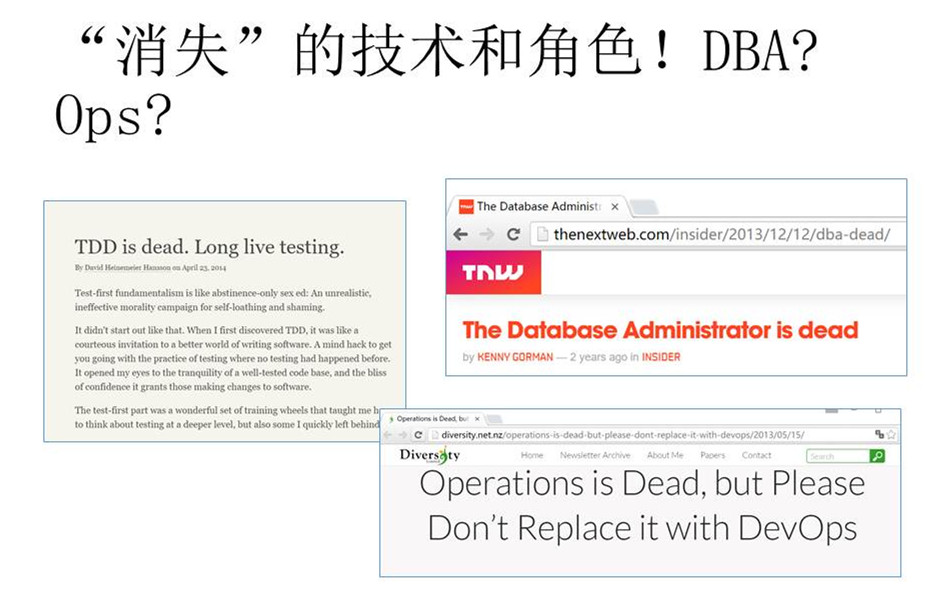
这个观点其实也不是很新鲜了,毕竟最近有很多这样的热门讨论,包括 “DBA已死”、“Ops已死”等类似的观点。在我看来,这些角色可能会慢慢地减少,但不意味着他们的任务就消失了,代表的职责就消失了,他们只是变成另外一种工具和形式。

先来谈谈什么是质量,有很多定义。以前我们的定义是怎么找Bug,后来软件大了,我们会定义怎么去找matches,怎么去度量每千行软件代码的Bug数,或者说满足这些需求输出的规范程度。这是早先的定义,但在最近几年,很多定义在慢慢淡化,我们更加强调软件的质量就是它满足客户需求、提供用户体验的一种感觉。质量相当于一种经济竞争性,如果你做得快,迭代得快,很多时候会占优势。

其实做DevOps的核心问题就是提高工作效率,提高工作效率算是个老生常谈的话题了。大家可以读一下德鲁克写的这本《21世纪的管理挑战》,俗话说“文无第一,武无第二”,简单来说就是无论哪个领域,你很难找到一个大师级的人物是排名世界第一的,但是在管理领域中有个例外,就是德鲁克,他的排名永远是第一的。他的这本著作中写了很多关于IT信息技术公司应该怎么去管理的思考。
他讲到,在一个好的公司或者以生产效率为初衷的公司,其实他们更多的是在营造一种气氛,让大家提高运维效率、工作效率,而不是去做各种角色,把角色做得细,把人变得像流水线上的一个工人。他更多地强调一种跨界的角色,要不断学习和教导,强调质量优于数量。
因此,我所理解的DevOps很简单,就是一种产品的责任心,提升生产力,碰到问题、解决问题的一个过程。

二、微软是如何做DevOps的

接下来讲一下我在微软的研发过程,以及微软DevOps是怎么转型的。
以前,微软可以说是一个非常强大的测试公司。在微软里,测试工程师的招聘跟开发工程师是完全一样的,需要写代码,写很多的测试,待遇也是一样的。当时比尔·盖茨说,微软是世界上最大的测试公司,这是毫无疑问的。因为它当年有12000名的测试工程师,覆盖了各种产品的测试,有大概7、8个vp for test,就是测试可以直接做到vpm。这是2009年之前的情况。
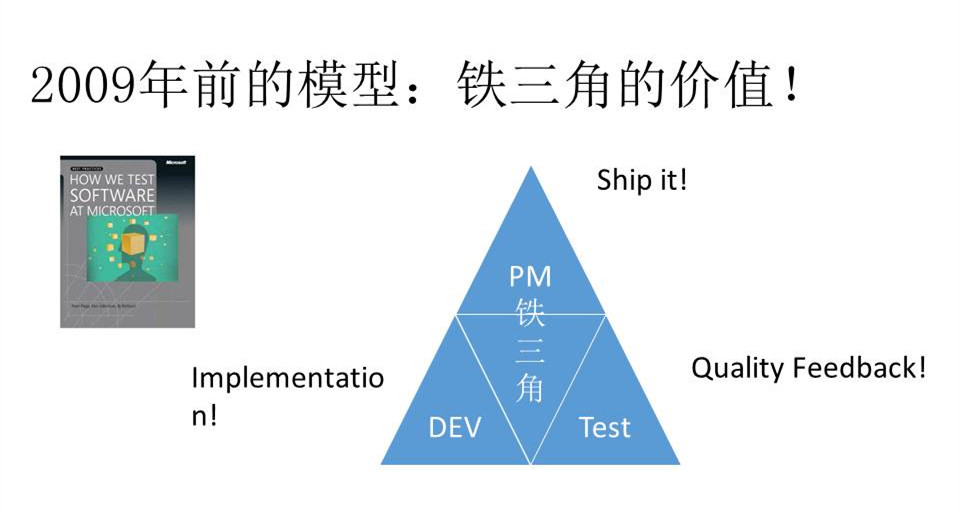
比尔·盖茨也说,微软不光是个软件公司,更多的是个测试公司,因为微软早年的软件就是靠质量支撑的。在2009年以前,微软有三个非常重要的角色,我们称之为铁三角,一个叫产品经理PM,另外两个是开发和测试。当时这三个角色都非常强大,而且每个角色都有自己的行为目标。
不知道大家有没有想过产品经理的核心价值是什么,在我看来,他的核心价值就是发布产品,不管用什么手段什么方法,只要搞定产品发布就OK了。而开发的核心价值在于实现代码。那么,测试的角色是什么呢?很多时候在不同人眼中,会有不同的答案。但在当时,微软把测试的核心价值定义为提供质量反馈,也就是Quality Feedback。意思就是测试团队要不断提供测试的反馈,包括代码、Bug、生产效率的低下、运行效率的提高、用户体验等等。
总的来说,当时微软的模型就是这样,但这种模式有很大问题:
第一,在产品方面,产品发布节奏太慢了,测试发现很多问题之后踢给开发,开发又返给测试,整个周期非常长。
第二,在流程方面,很多时候我们有design、review,还要写一些Spec,非常累。我记得当时测试和设计两个文档,每个文档光模板就有77页,想想就算只填满7页都已经要花多少时间了。
第三,在招聘方面,微软虽然有一个很庞大的测试团队,但是招测试人员也会遇到很大压力。因为一些功底比较好的测试工程师更愿意找一些开发的工作,而不是测试,虽然待遇是一样的。
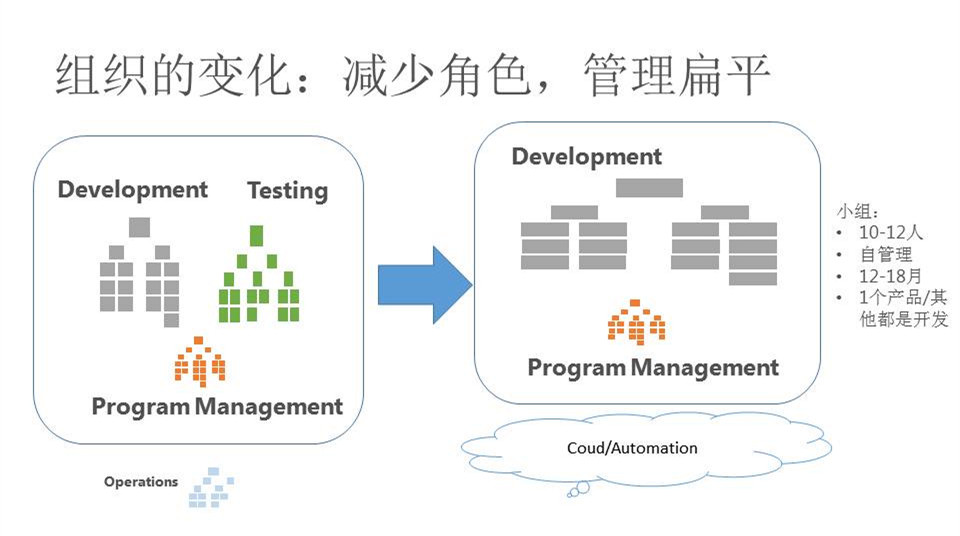
后来在2009年,微软提出了一个思想:Combine the engineer,基本想法就是把开发和测试合成一个角色,而名称还是沿用了“开发”这个名字。也就是说,在转化后,测试和开发全部合在一块了,测试工程师变成了开发工程师,而测试经理变成了开发经理。
微软整个DevOps转化过程分为三个阶段,碰到过很多问题。比如说,转化后整个团队更扁平了,可能以前有些主管就不再带人了,也可能以前有的人在测试领域是非常擅长的,可产品的部分他不太熟悉。还有包括运维,以前运维是个非常大的独立团队,但现在也全部转化到Combine the engineer去。
微软的第二阶段大概花了四年的时间,这时总体来看,开发和测试合在一起了,而运维还相对独立些。以前只有运维可以上线,但在第二阶段开发和测试也能上线了,不过数据库的一些部署主要还是由运维来上线。
到了第三阶段,也就是2013年之后,微软的运维角色已经非常少了,后来主要就集中在一些机房里。因为机房里有成千上万台机器,每天都有大量的硬盘坏掉,所以他门的工作就是换硬盘,每天推着一个手推车在机房里窜来窜去。
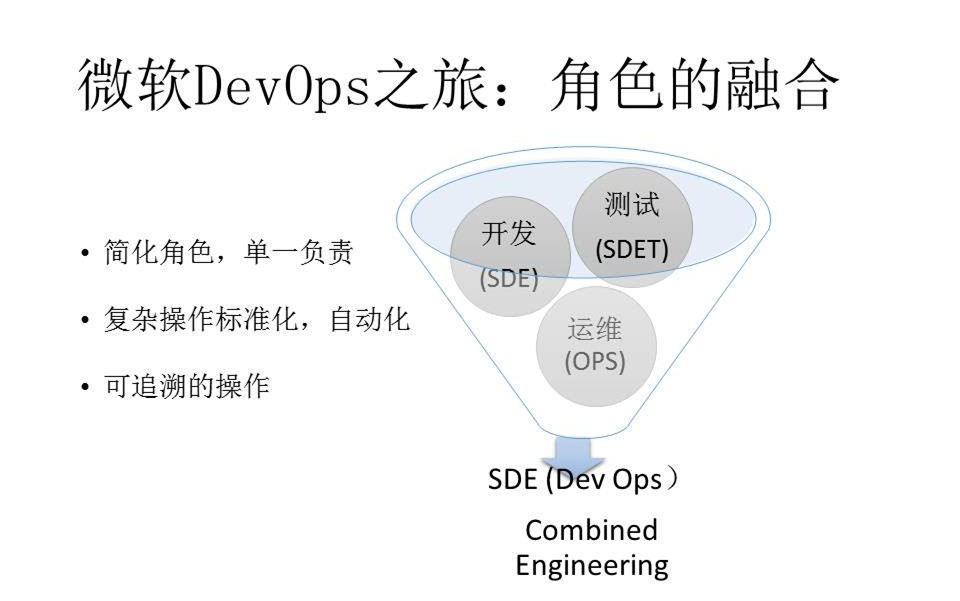
所以微软在融合的过程,把开发、测试、运维都变成一个角色。这样简化角色有一个好处,就是责任比较清楚,产品出问题了就是找你。以前产品出问题,经常要打电话给运维,但运维需要一个很长的路径才能接到电话,所以后来就改成所有线上问题都打给开发。反正你做了开发、做了测试、做了部署,都是你的事,那你也把这个事情搞定就好了。而开发人员也可以在整个过程中体会到怎么做产品,学到很多很重要的东西。
这是微软以前一些角色和任务的转移:
在工作方式上,也从以前的服从计划变成一种主动的探索。
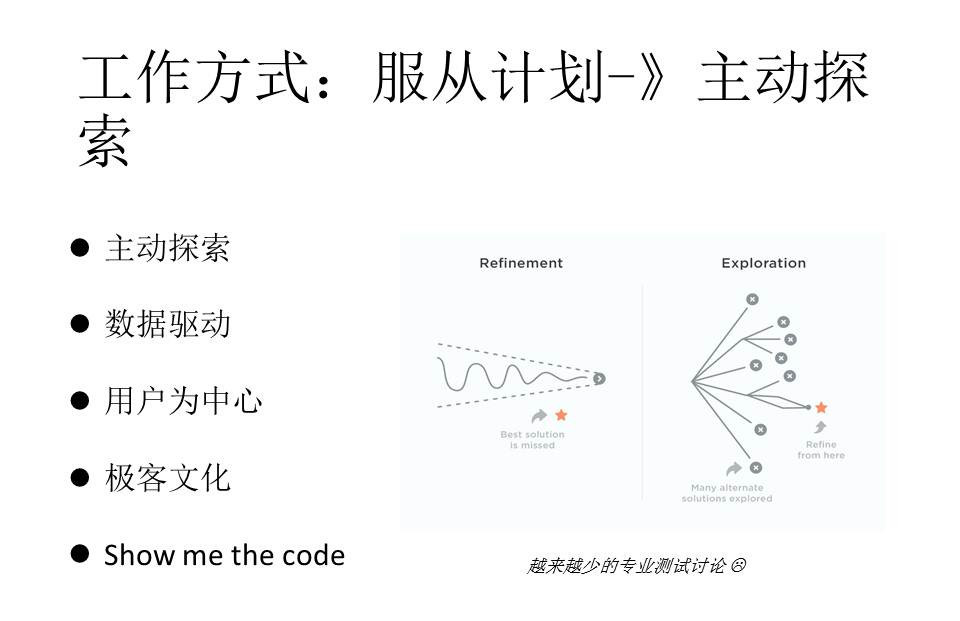
以前,微软都是产品经理定好了工作方向,然后大家一起努力,加班加点,往这个方向去做。因为觉得方向肯定是对的,所以只要用最好的算法、最努力的态度去搞定就好了。但后来发现,其实你做出来的东西在市面上不一定受欢迎,而且竞争压力也很大。
在微软改成DevOps模式以后,工作方式转变成主动探索,我们会去尝试不同的方向,也不会认为哪个方向就一定是对的,我们还会做一些取舍,找到最终需要用到的方向。这也显示了一个极客文化,包括我们有很多黑客,大家找两天一起编程,实现一些好的idea。同时,这也强调了微软的一种代码文化,就是少说话,有什么想法show me code。

微软的Combined Engineering从效果上来看,使得产品发布节奏明显加快,以前我们讨论“做和不做”,现在是讨论“如何做得更快”。大家都会去交流生产力问题的焦点,体现了一种线上产品的主人翁精神。转型之后,我们内部还做了一个调查,发现开发者的工作效率、工作热情都有正面的上升。
微软在实现整个转型的过程中有几个原则:
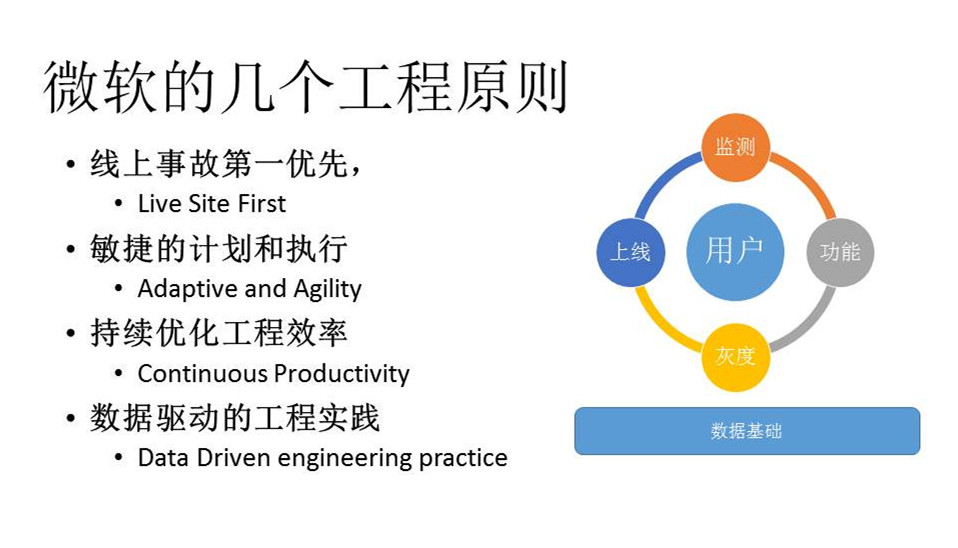
第一个原则叫Live Site First,就是说线上事故永远是第一位的,而且是需要写代码的人第一时间负责处理,不能推托给别人。
第二个原则是计划永远会变,不要讨价还价,要保持一种心态,主动去适应这个变化。所以后来,关于timeline这个东西,我们越做越简单了,而且做计划时基本上想到两三个月的目标就可以了,很多时候不会想得太远。因为想得太远,中间就会出现更多变化。
第三个原则是持续优化工程效率,包括引入持续集成、持续部署,这些概念都很好,核心问题在于什么时候引入这个概念,以怎样的投资去做,是大家边做边试还是其他方式。
第四个原则是数据驱动的工程实践,就是指后来我们不依赖测试了,那怎么去保证它的质量呢?怎么判断这个工程能用?这涉及到后面的监测环节。

微软大概是做了这么一个DevOps转型,而很多互联网公司其实也是这么做的。
比如说Facebook,Facebook是没有测试的,强调“NO Testers”这种文化,也是做单元测试、灰度测试为主,都有开发人员来做,但没有测试人员。
再比如谷歌,以前一个微软同事去了谷歌,写了一本介绍谷歌测试的书。书的内容其实很简单,就是说谷歌测试团队归于开发效率团队,职责是指导开发人员怎么去写测试用例之类的,他们开发和测试的比例大约是10:1,即10个开发对1个测试。
亚马逊还有一些测试功能,主要是集中在一些业务场景。
Facebook: Staged Data Acquisition
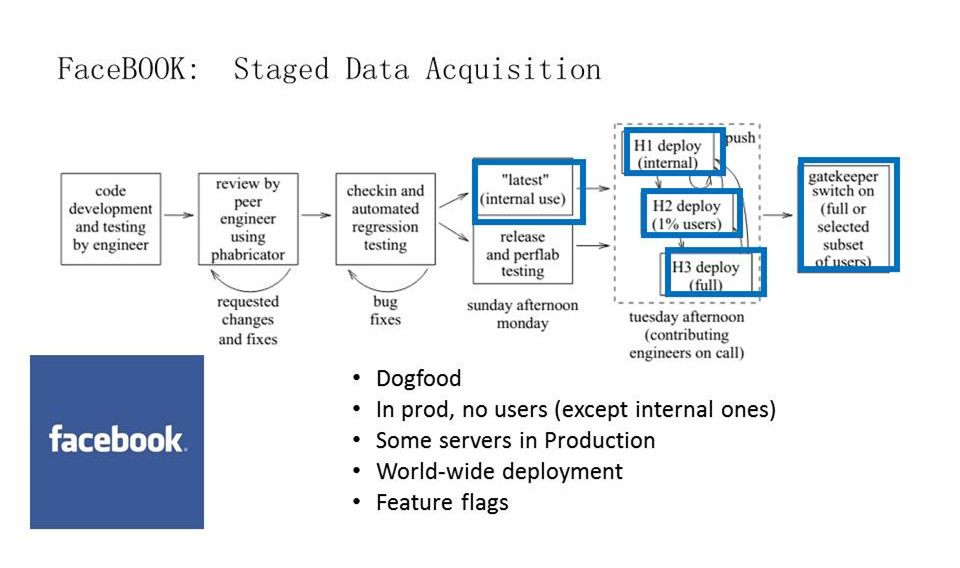
大家可能都知道,Facebook每周有一个灰度发布的过程。每周日晚上它会发布一个完整的build,星期一早上可能会推大概1%-2%到线上,然后星期二下午看看效果,没有问题的话星期三把它推到全线。每周都有这样一个节奏,并通过反馈的指标来看效果好不好。
Google Runtime Analysis and Testing
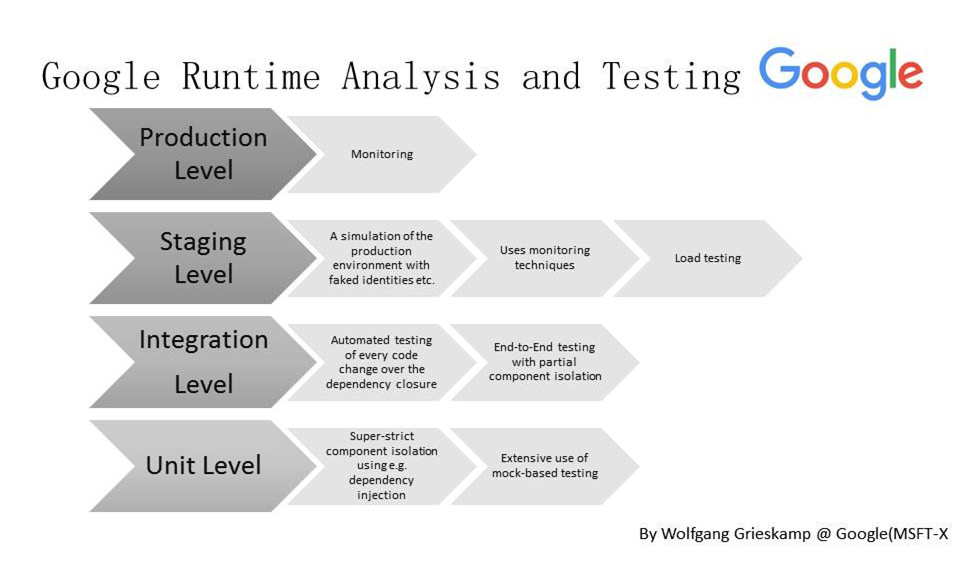
谷歌的测试也没有什么神秘的,就是有单元测试、集成测试、Staging测试等。
在互联网公司中,可能有一个传统,就是我们可能更愿意把一些测试从发布前挪到发布后,换句话说,就是发布后再测试。发布前可以做一些单元测试、功能测试、探索性测试,发布之后可以边做集成测试边做系统测试。
比如我在微软时有一个项目就是做性能测试,很多时候我会利用微软晚上机房里一些流量比较低的机器。我会启动这些机器,模拟一些流量,直接打到线上产品的服务器上,再看它的效果。这时就可以充分利用线上的一些服务器来帮助你做一些测试,看很多指标,你还可以邀请用户去帮你做一些测试,比如β测试,可以邀请少量的用户使用3%或5%的流量enable the feature,然后观察这些用户的关键指标有没有变,比如用户时长、返回的响应时间等。
三、小米是如何做DevOps的
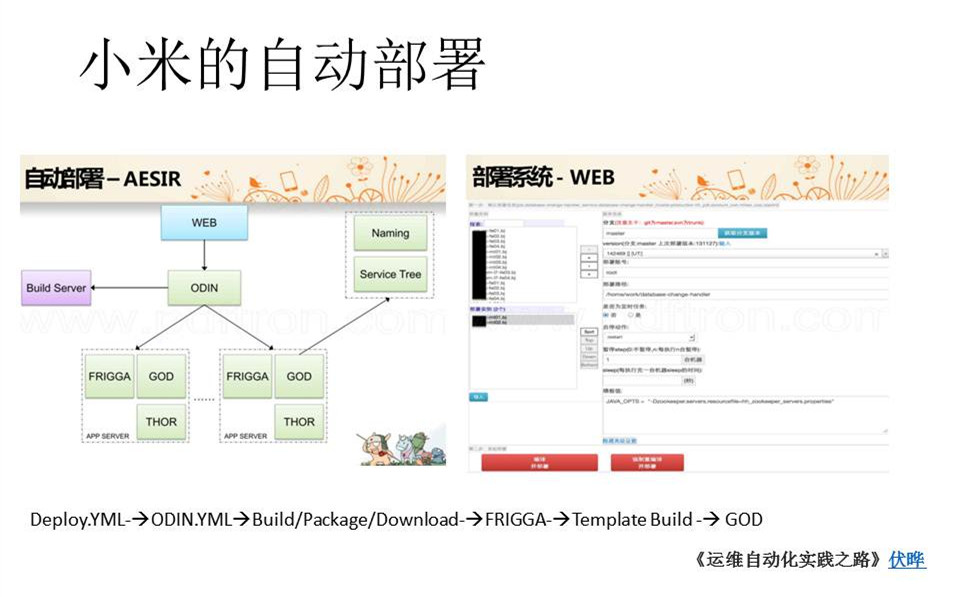
大家应该知道小米手机的软件是一个深度定制的Android系统,叫做MIUI。以前很难想象一个手机操作系统可以做到每个星期更新一次,甚至在列目板块,操作系统每天都有新的版本,包括我的手机使用的就是MIUI的内部版本。每天都是最新的版本,但基本上没有影响过我打电话、玩一些常用的软件。所以小米MIUI也有几个版本,体验版是每天发行,开发版是每周五下午发行,稳定版是每一两个月发行一次。能把操作系统做得这么快,这是我们非常重要的一个目标。
包括应用也是。以前应用都是跟MIUI ROM操作系统一起发布,但这样太慢了,后来就改成单发,每个应用自己发版,不需要走系统ROM的发版。后来还是觉得慢,就开始用Hybrid的H5做了。大概就是主要页面有一些用H5的,这样调整更方便,可有些体验相关页面还是要用native code来写。整个过程围绕如何做得更快更好来写,这就是DevOps的核心问题。
在部署方面,小米自己开发了一套自动部署系统。没有什么神秘的地方,基本上每台机上有些后台进程帮你去从代码拉服务器,拉完代码帮你做build,build完之后一台一台机器上线,上完一台会给你发一些消息,做一些测试,没问题继续上。这个系统叫AESIR。
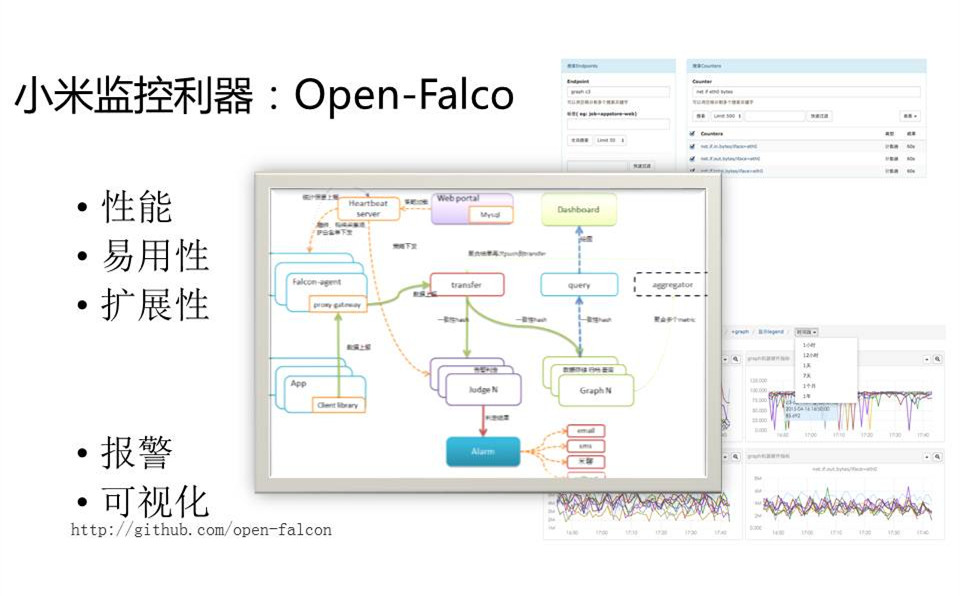
小米也有自己的监控系统,叫Open-Falco,是我们去年11月开源的一个系统。大概也是在每个机器上装些agent,agent把performance counter收集起来,包括机器性能打到中间服务器里面,后面有HBase和MySQL,提供一些界面帮你去查询这些图表、趋势,大家有空可以看一下。Opensource也有很多解决方案,例如OpenTSDB等类似的解决方案。Open-Falco是我们开源的内部使用得不错的一款系统,它可以定义很多查询条件,做些定义的图片,报警了就发到你手机上。
四、如何成功向DevOps转型
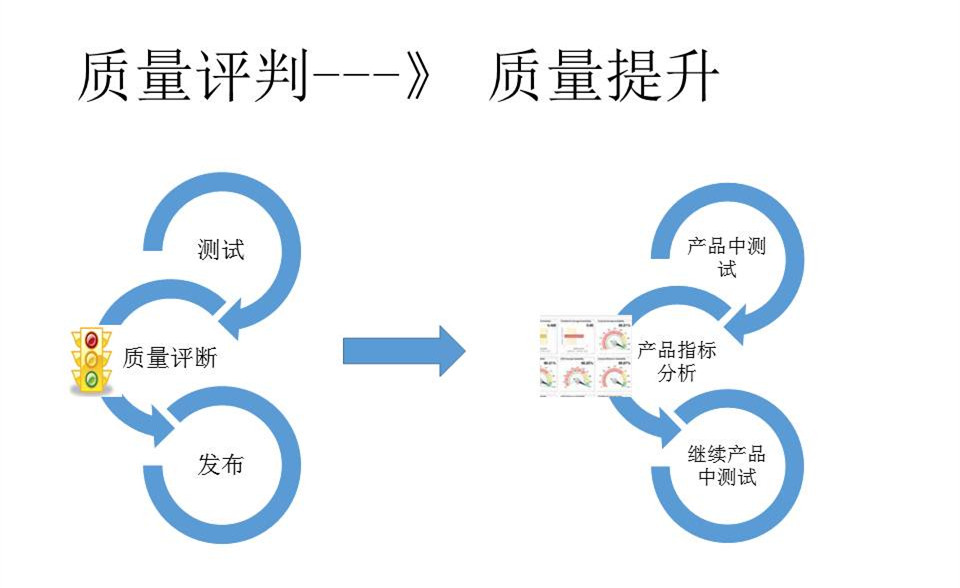
传统的质量评判,是在测试环节结束后,测试机体会跳出来说质量已经满足了我的要求,OK,按绿灯,发出去。这感觉是一种好像没有人阻止你上线,但是后果由你自己承担责任的模式。出于这一考虑,开发人员就会有很大的动力去增加更多产品的指标,进而达到质量提升,这是一个比较健康的模式。

那么,产品质量到底能不能度量呢?这是一个很有趣的问题。有本书叫《数据化决策》,里面认为所有的事情都是可以度量的,可以用数字化去表示。比如他说可口可乐的口味是可以度量的,他通过邀请20万人去做可口可乐新口味的调查,最终得出结论。再比如说,他设定一种方法,推断出幸福的婚姻相当于你年收入增加2万美元。总之,它运用了很多方法和指标。
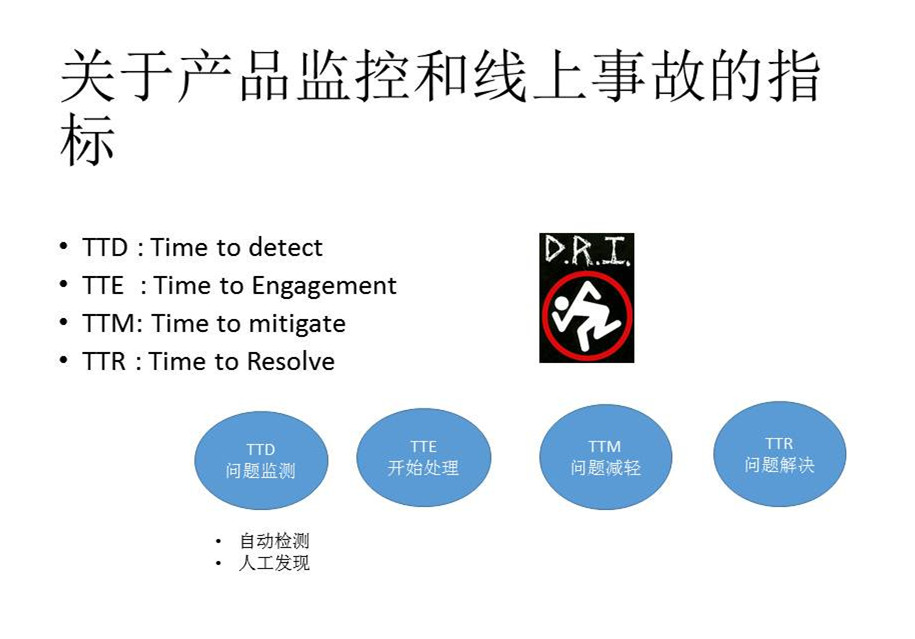
小米在这里会强调几个事情:
第一个是Time to detect,也就是你什么时候发现问题。
第二个概念叫Time to Engagement,发现问题以后你隔多久去处理这个问题,好比你在手机上看到这个问题,你要多久才能到网络去处理这样一个问题。
第三个是Time to mitigate,即你花多少时间去减轻这个问题,比如你把这个数据库变成备用数据库,把问题减轻了,这是一个指标。
最后一个是Time to Resolve,就是什么时候把这个问题彻底解决了。整个工程都是围绕DevOps来解决线上的问题。
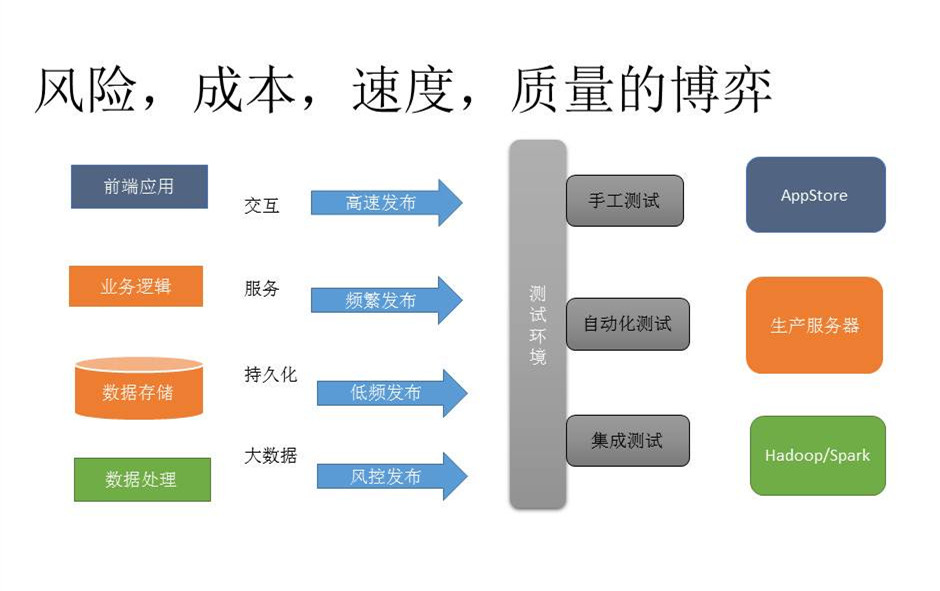
那么,不同性质的应用程序,它们的发布节奏分别是怎样的呢?我们在这一块有很多想法,也做了很多事情。
前段应用
一个是前端应用的发布会比较频繁,基本会达到每天去发布,然后测试会依赖一些手工测试。
业务逻辑
业务逻辑也是会比较有节奏地去发布,特别是Java的一些逻辑。这个时候就会去依赖一些自动化测试。
数据存储
数据库方面的测试会更加谨慎一些,特别是一些schema的改变。会比较低频率地发布。
数据处理
数据库的测试很多时候会依赖于集成测试,在表的设计上会尽量减少线上影响的方式去改数据库,包括我们只增加不减少,很多时候我们的质量不是通过测试来保证,而是在设计上进行保障。
五、DevOps的基础架构和工具
DevOps有很多工具,然而我觉得在每个团队里,核心问题并不在于你比我用了更好的库的工具,而是在于在适当的时候解决适当的问题,用简单的方法解决团队的大问题。不是用很重的工具去解决,而是把大问题分解成几个小问题去突破。
整个自动化基本架构包括持续集成、持续部署、shell、Service等,持续集成和持续部署就不说了。Service非常重要,就是需要把一些好的服务变成一个共享的服务去使用,包括DNS、申请虚拟机等。以前我们申请虚拟机都要去找运维,后来我们就跟运维强调,所有申请的机器直接让开发人员去做,不用找运维等运维再同意,让整个过程的效益再快一点。
DevOps有很多开源工具,相信大家都比较熟悉了,这里就不一一介绍。这些都可以在网上搜到,基本上一个工具可以解决一个小问题。主要还是要看自己的团队具体需要解决什么问题。

六、小结
1、我对DevOps的4个观点
竞争性软件公司终将采用DevOps
DevOps不是银弹,是关于效率的文化,自动化的技术
大量专职运维和测试将消失和减少
“靡不有初,鲜克有终”
2、我理解的3大核心问题和2个非核心问题
三大核心问题:
自动化发布:灰度发布(Staged Deployment)
自动化监控:产品监控和报警
自助PaaS(基础平台服务):存储,容器,队列,认证等
两个非核心问题:
持续集成CI(Build->Test)
持续交付CD (Ready for deployment)
3、DevOps和适应变化
DevOps实际上是一个关于适应的文化。动物学家达尔文曾说过:“世界上进化下来的动物,并不是最强大的动物,也不是最聪明的动物,而是那些最能适应变化(Responsive to change)的动物”,比如说老鼠、蚊子、蚂蚁等等。软件系统也一样,能够传承发扬的软件,必定能够快速适应变化。所以很多时候公司需要有一个适应力非常强的工程师,才能帮助公司、团队解决业务问题。
最后,DevOps转型不是一蹴而就的,这个过程可能是漫长的、持久的,但也是必须的,与时俱进的!走在DevOps转型路上的每一位前行者,唯有坚持不懈地去探索,才能不忘初心,方得始终。
相关专题:
◆ 近期热文 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会上海站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721