
邹德裕,轻维软件首席数据库专家,DBAplus社群联合发起人,OraZ产品作者。10年以上运维管理经验,Oracle OCM,精通Oracle9i、10g和11g数据库技术及Linux Unix技术。对数据库系统架构具有深刻的理解,并在数据库诊断、故障排除、优化、架构设计等方面具有丰富的经验。
对于特大场景应用环境中,Zabbix本身对某些方面的性能并未考虑周全,本文就从代码级别二次开发优化入手来达到我们的需求。
从选择更好的硬件配置,如大容量内存、更快速的SSD固态磁盘、改raid配置等硬件角度优化,效果会立竿见影,不过大部分这些操作都是在规划阶段完成,后期往往通过软件优化为主。
Zabbix本身是一个高性能的分布式服务器集群监控系统,其基本结构是在多台被监控机上安装agent客户端,由agent端通过trapper不断捕获数据发送到server端,server端对捕获上来的数据进行解析再分别入库到后台数据库表中(Zabbix可以支持MySQL、Oracle、PostgreSQL等数据库),然后在前端管理界面上来访问相应的页面,并展现各台被监控机上的各项性能指标的情况,它的各种指标性能的展现所需数据的主表基本上是一个历史数据表,如下图样例:
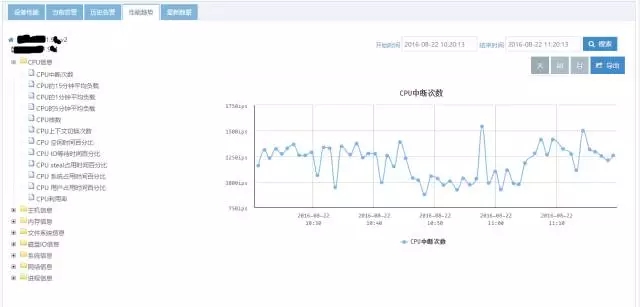
上面图中所展示数据就来自于历史表之一history,此表基本结构如下:
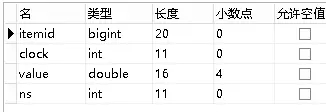
(注:Zabbix原始表里没有为其添加任何主键和索引。)
其它的各种性能指标的展现所依赖的数据表结构基本如上表,只是value列类型不一样,而且表名不一样而已。
为何Zabbix的原设计者要如此设计这些表呢?我想是基于这样的原因:就是希望它能快速地进行数据入库和数据展现。因为,如果为表加主键或索引,则入库速度肯定会变慢一些,在管理成百上千台机器时,且管理指标项目又很多时(一个host下可以有多个不同类型的被监控项item),单位时间产生的数据量是相当可观的,如果入库一条记录稍微慢那么一点点,那在特大场景应用环境中就会几何倍数放大,收到的数据无法及时入库,并且可能造成Zabbix server内存积压,而连带使Zabbix server本身收集数据的能力变慢(甚至Zabbix server因内存不足而崩溃),最终会导致采到的性能数据丢失,Zabbix的作用就大打折扣,所以入库速度是它第一要考虑的问题。
另外,设计者为何要对不同类型的数据实行分开存放呢?我想他同样是为了增加入库速度的目的,也是为了提升查询展示的速度,因为不同数据类型分开存放后,一个表就“专用”化了,方便治理,也有利于将大表拆分成小表,减低单表压力,对入库速度和查询速度都是有利的(特别是有利于降低对表锁的争抢)。
好了,我们已经明白,为了管理大量的机器,我们必须要求Zabbix入库速度要尽可能地快,且查询对入库的影响要尽可能地小,为了这个目标它也有了比较多的考虑,但是经过我们的测试并梳理后,发现在展现最新数据时,仍旧是十分缓慢,我们观察了一下最新数据的展现机制,发现它是要从历史表中拿出最新入库的数据来展现,展现示例界面如下:
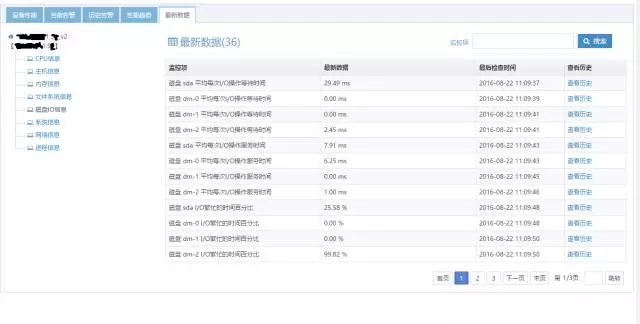
其查询语句大致如下:
(注:以上语句是一个根据显示数据的情况写出的示意语句,不是原始的语句,且是基于MySQL,但实际用到的语句与此相似)
在数据量很大的情况下,基于现有的数据库设计,上面语句很明显会很慢。
1)它需要关联查询items表和hosts表,而如果没有主键,关联查询的性能肯定是相当慢(特别是数据量又相当大的情况下),而一般情况下,历史表中的数据量肯定是相当巨大;
2)需要用到group by查询和order by查询,在没有索引或主键且获取的数据量很大的情况下,其速度也肯定是很慢的;
3)因为前述问题,后台又要不断往历史表中插入数据,会争抢表或行锁,于是查询和入库之间会互相影响,导致大家都不好过。
4)要是多人同时打开界面查看与历史表相关的其它数据呢?那不是互相之间又产生更多影响。
于是,要让最新性能数据的展现显示得快,又对其它查询和入库不产生影响,非常有必要对最新数据的展现这一块进行优化,要设计一种方案来优化。
根据前面对问题的分析,我们需要实现以下几点:
对最新数据的查询要尽可能地快;
必须不能影响对历史表的入库;
保持对现有数据的结构。
基于以上目标,我们容易想到的方案是:在历史数据入库时,找出最新的数据并另存一份到一个独立的结构相同的最新数据表中,最新数据的展示查询时,只到这个独立的表中去查询,这样就可以解决上述三个问题。
1、首先必须设计几个与历史表对应的用于存放最新数据的表。
last表(对应history表):
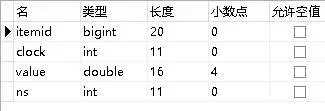
last_unit表(对应history_unit表):
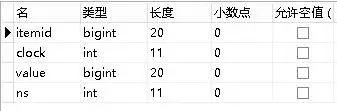
last_str表(对应history_str表):
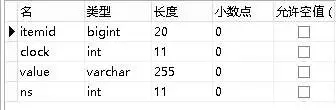
其它还有两个字串型表就不罗列了。
以上各个表的结构基本一样,与原对应的历史表数据结构也是一样的。
2、为上述表添加主键索引
根据前面问题背景分析里所述的查询语句,最新数据查询时会关联到items表和hosts表,为了加快数据查询展示速度,需要为上面新加的这些表的itemid列添加主键索引,即将itemid列设为主键列,在入库时每个itemid只有一行数据,就是最新的那条性能数据,同时要为相关的items.itemid列、hosts.hostid列添加主键索引(如果它们没有被加上的话)。
3、修改Zabbix server源码,添加对最新数据的入库,并做一些历史数据的入库优化。
找到Zabbix server程序的源码中同步历史数据的代码处(即:将内存数据刷入数据库的过程),根据其逻辑添加对最新数据的入库逻辑,以下是修改后的对history表数据入库的代码逻辑过程:


其它表的数据入库过程与此类似,参考代码略。
简单解释:
在上面代码里:ADD_HISTORY_PART_MID1(dbl, value.dbl)这一行展开的过程里会有以下代码:

上面的这一行dc_add_last_dbl(phis->itemid, &(phis->ts), phis->vf, 0);就会向存最新数据的数据表中插入最新的性能数据行。并且,上面过程看出,对同个itemid的数据行,只会执行一次记录插入(根据分析,在调用入库逻辑过程前,同一批历史数据是按itemid排好序了的,所以这样做是可以的),另外,dc_add_last_dbl(phis->itemid, &(phis->ts), phis->vf, 0)过程(代码略)在插入数据时,在插入语句里加了 "on duplicate key update value=values(value), clock=values(clock);" 这么一个子句,通过这个子句来实现插入时对已经存在的相同itemid数据进行修改,而不是插入一条新数据,这实现了数据的减量,但又不会增加插入性能消耗,因为表上只加了itemid主键。
改好后,重编译安装Zabbix server,再启动即可。
4、更改前端界面的查询
前面修改好后,还需要把前面展现最新数据的界面那里的原来的数据查询语句修改一下,将原来的从历史表中查询的方式改为从最新数据表中查询(就是前面新加的表),修改时相当简单,直接把前面问题背景分析里所述的查询语句里的表名改掉即可,如:history改成last,history_uint改成last_uint即可,以此类推,因为新加的表的结构与原来对应的历史表结构一模一样。
经过上述修改后,我们发现,最新性能数据展现那里已经可以十分快速地打开界面了,这说明上面的做法起到了相当明显的优化效果,同时,从这个效果里我们也看到解决了背后的一个问题:历史数据的入库也不会受到因对历史表的group by/order by/关联查询的影响而变得快速了,不会因为查一下历史表里的最新数据,就让入库都受到影响而变慢。
总结起来就是:要尽量让客户端捕获上来的数据尽快收集起来并能快速插入到数据库中,要尽量避免在历史表中使用可以避免的影响速度的查询,否则可能会影响到入库(同时查询本身也会慢)导致采集到的数据丢失。
相关专题:
◆ 近期热文 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721