
前言
大家好,我是林水彬,来自腾讯互动娱乐事业群的DBA。很高兴今天能有机会在这里跟大家一起交流讨论TokuDB在业务中的一些相关实践。
本次主要有3个议题想和大家交流讨论下:
背景
压力测试
运营经验
让我们从使用TokuDB的背景说起。

这幅图层现了当前我们大部分的游戏架构,今天要讨论的角色在左下角—logdb,logdb(又叫tlog),顾名思义,存储的是玩家的一些流水日志,譬如,登陆/登出;购买的道具记录等。
非技术的现状:
随着游戏的运营策划,拉新留存,不断滚服,不同区服在线不均,导致资源浪费;
策划希望保留更多的数据,X业务单区甚至能达到 2T。
技术的现状:
采用InnoDB,一般是游戏大区:Tlog = 1:1;存储的硬件成本高;
采用MyISAM,虽然能节省一半空间,但无法在线加字段,而加字段的变更又是占游戏日常变更的大块头。
TokuDB:InnoDB = 1:10
TokuDB:MyISAM = 1:5
MyISMA:InnoDB = 1:2
这是一组经验数据。
2015年上半年,当时部门正在搞成本优化,借着这把火,我们发起了一个项目,叫:端游Tlog成本优化。以项目的方式,以TokuDB为技术,以业务的诉求为基础,按KPI驱动,逐步建设,逐步迭代,快速落地。
目前接入TokuDB的业务20+,实例200+。

这幅图是我们最开始推动接入TokuDB的5个业务,节省机器数 150台,按照tlog机型每个月运营成本980/月,这5个业务每个月也可以节省15万。也许这是技术变现的另一层意思。
接下来我们正式介绍下TokuDB。
TokuDB作为MySQL的一个存储引擎,业务侧不需要修改任何代码,开发可以像使用InnoDB一样选择TokuDB。它有如下几个优点:

上线现网前我们对TokuDB进行了一些调研,主要包括:
高压缩比
查询
更新
业务查询
业务入库
第4、5是我们基于tlog业务个性化的考虑出发的。
我们先看下TokuDB为人称道的高压缩特性。
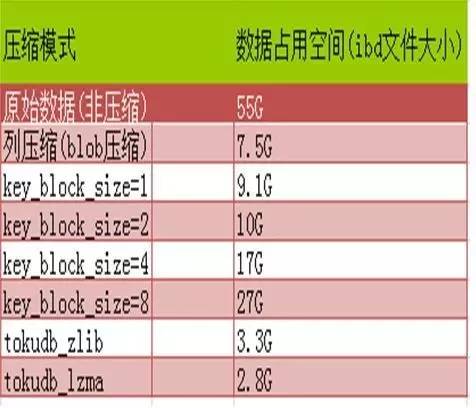
这是我们从现网来的一组压缩数据。
TokuDB之所以比InnoDB有较高的压缩优势,可能原因有:
TokuDB默认块大小为4M,更适合压缩。
InnoDB需要将压缩后的数据pad到固定大小的padding 空间里,这会降低所能达到的压缩效果,而TokuDB是unpadded。
InnoDB可能存在碎片,而TokuDB没有这个问题。
关于压力测试,我们使用的工具是自研的test_server:
查询的测试SQL:SELECT id FROM test.big_tb WHERE id= ?
原地更新的测试SQL:update test.big_tb set col1=col1+1 whereid = ?
非原地更新的测试SQL:update test.sml_tb set col13 =substr(sha1(rand()), 1, ceil(rand()*8)) where id = ?
首先是select。
MySQL配置
innodb_buffer_pool_size=15G
innodb_flush_log_at_trx_commit=0
sync_binlog=0
row_format=lz_ma(TokuDB)
tokudb_cache_size=15G
全cache
row 2000000 innodb 2.4G tokudb 20M
非全cache
row 40000000 innodb 48G tokudb 754M

结论:
全cache下TokuDB是InnoDB的2/3
非全cache同等数据用tokudb后只有754M,所以tokudb 内存能缓存大部分数据下,TokuDB几乎是InnoDB的10倍
其次是更新。
MySQL配置
innodb_buffer_pool_size=15G
innodb_flush_log_at_trx_commit=0
sync_binlog=0
row_format=lz_ma(TokuDB)
tokudb_cache_size=15G
全cache
row 2000000 innodb 2.4G tokudb 20M
非全cache
row 40000000 innodb 48G tokudb 754M
结论:
全cache下无论原地更新或非原地更新对于TokuDB的表现均无太大差别
全cache下原地更新TokuDB是InnoDB的1/2,非原地更新TokuDB是InnoDB的2/3
非全cache同等数据用tokudb后只有754M,所以tokudb 内存能缓存大部分数据下,无论原地更新或非原地更新,InnoDB是TokuDB的1/5
同时,我们也回放了现网tlog的查询模式。

现网回放的Top 7 SQL属于范围查询,而范围查询 TokuDB的表现要优于InnoDB。
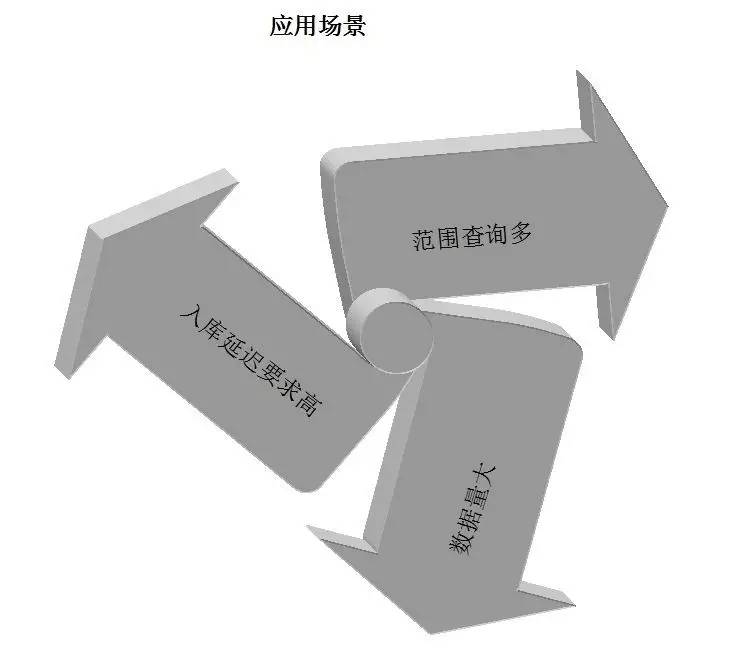
根据前面的压力测试环节,可以看出,TokuDB优势在于压缩和范围查询,点查询不是他的优势所在。所以,稍微总结下,建议TokuDB的应用场景如下:
说完压测,接下来我们讨论下踩坑的正确姿势。
第1个坑。
来自TMySQL用户,包括很多开发和GCS系统,都习惯mysql –u$USER –p$PASSWD 来执行,这条命令在MySQL 5.6会有个warning告警:
Warning: Using a password on the command line interface can be insecure
单据或者脚本解析到这个warning,则全部失败。
所以,为了向前兼容,我们在源码层面将这个warn关闭。

看第2个坑。
一般MySQL的升级方法包括:
导入导出
做一个slave
原地升级
根据数据量大小,如果100G内的,我们一般选择原地升级。
某天在某个高星级业务上业务运维发现TokuDB的加字段很慢。
TokuDB无法在线加字段的条件:
原地升级
表含有数据
表含有时间字段
TokuDB无法在线加字段的原因:
MySQL 5.6.4在Server层新增三种时间类型MYSQL_TYPE_TIME2,MYSQL_TYPE_DATETIME2,MYSQL_TYPE_TIMESTAMP2,并在InnoDB层以二进制的格式存储,用这种方式来实现时间类型支持小数精度并优化存储节省空间。如果直接使用加字段操作,alter table t1 add c1 int。
对MySQL 5.6中,通常情形下加字段的隐式行为是走的online ddl,即ALGORITHM=INPLACE。 如若t1满足上述3个条件,该SQL则隐式走ALGORITHM=COPY,即非在线加字段的逻辑。因此,在系统默认行为下,通过原地升级过来的旧版本MySQL时间类型会妨碍后续的online ddl行为。
修复的方式有2个:
alter table force,这种方式需要拷贝数据,成本太高。
avoid_temporal_upgrade 把这个参数打开即可,很赞,建议使用这种方式。
接下来看第3个坑。
某天有开发投诉,数据入库延迟严重,导致统计任务失败,重跑成本极高。
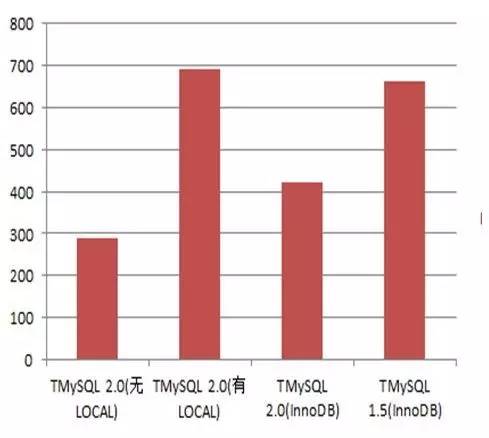
TokuDB官方宣称Load DATA比InnoDB强;并且我们在预研阶段也验证过的确如此,BUT WHY ??
查阅文档发现,原来是使用的姿势不对,Load DATA带不带local关键字区别很大。
有无local走的协议不同,有local,则是通过client读取后发送给server;无local,便是server直接读取。
下面看第4个坑。
现网TokuDB的部署策略是1:2或1:4个大区共用1个实例,正如这幅图所展示的:
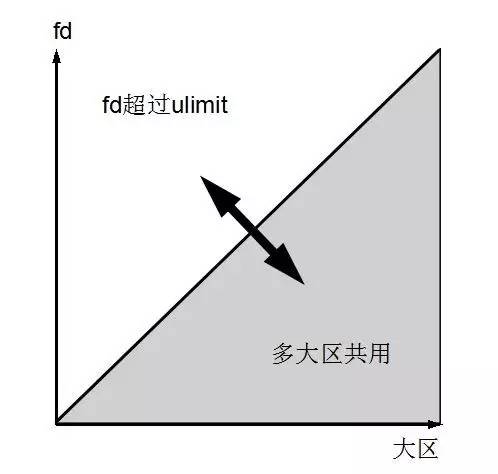
淘宝的MySQL内核月报提到TokuDB 分区表文件数目计算公式: 分区数目 * (1 + 1 + 索引数目),这么一算,fd不够用也就有理有据了,因为fd是进程级别的,所以我们只要进行如下调整即可。
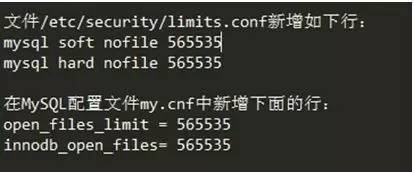
这是我们现网TokuDB实例上架的参数。
这个坑是业务运维的兄弟发现的,他们在查询时DB经常报:MySQL GONE AWAY。
接下来是最后一个坑。
数据安全是DBA的生命线,随着运营数据的与日俱增,逻辑备份压力越来越大。我们对比了业界的2种方案:
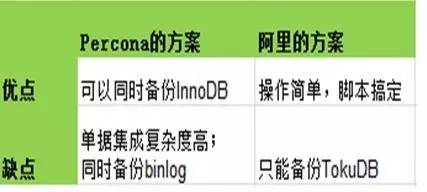
为了便于内部系统集成,我们采用阿里的方案。
TokuDB物理备份的步骤:
连接mysql,设置SET TOKUDB_CHECKPOINT_LOCK=ON;
加只读锁FLUSH TABLES WITH READ LOCK;
获取binlog位置,
拷贝tokudb的redolog和一些元数据文件(tokudb.****)
释放只读锁UNLOCK TABLES;
拷贝tokudb的数据文件和表结构
释放checkpoint锁,SET TOKUDB_CHECKPOINT_LOCK=OFF;
但我们发现,TokuDB把所有的数据文件的路径都写死了,这样不同实例跨端口的恢复就不会报错。
tokuftdump解析tokudb.directory:

从解析的内容可以看出,每个记录都是一个key,一个value,key就是对应的表名,value就是数据文件的路径,tokudb把所有的数据文件的路径写死,这样的话恢复到不同路径的话当然就会报错。
我们TMySQL 2.x对这个“bug”做了修复,使directory文件中只存相对路径,然后和数据文件的路径拼出完整的路径。
修复解析的内容如下:

至此备份的坑也就解决了。
Q1: Toku的缺点主要有哪些,因为目前innondb还是大量在使用,能否指点一二?
A1:缺点可以从压力测试的数据看下,主要是点查询比InnoDB差。
Q2:Tokudb的range query比innodb 好?还有原因是cache 命中高吗?
A2:从我们测试来看,TokuDB的范围查询比InnoDB要好;TokuDB能缓存大部分数据可能是一个原因;不过当我们把tokudb的内存参数调得比数据要小一点的时候,TokuDB的范围查询仍然比InnoDB要高一点。
Q3:阿里备份与percona备份有没详细一点的对比?
A3:第一个是官方提供的方案——https://www.percona.com/blog/2015/02/05/tokudb-hot-backup-now-mysql-plugin/。简单来说这个方案是做了一个插件,加载了一个so,拦截所有有关于文件的系统调用,然后一边复制一边将改动同时应用到拷贝上去。
第二个是阿里提供的方案——http://mysql.taobao.org/monthly/2015/12/06/,这个方案听起来相对简单,只要加锁然后拷贝文件就可以了。
Q4:方便的话请介绍一下硬件的配置,cpu (压缩算法对cpu 的要求),磁盘方面参数。
A4:我们tlog机型刚刚在背景那块稍微提了下,配置不是很高。

Q5:在这配置下,生产最高的QPS,TPS是多少,CPU user是多少?
A5:目前我们TokuDB大部分是在Tlog业务应用,而Tlog的查询不会太高,主要是周边系统拉取的,所以QPS这个指标我们之前不是很关注;这个之前我们采集的某高星级业务整点高峰的性能数据。

作者介绍 林水彬
目前就职于腾讯,主要工作包括MYSQL、Hadoop以及自动化平台建设;
TPUB版主,CSDN社区技术专家。
福利来了,在本文评论区留下足以引起共鸣的真知灼见,并在本文发布后24小时之内成为点赞数最多的前2名,可获得以下书籍一本哦~

特别鸣谢博文视点(www.broadview.com.cn)为本次活动提供图书赞助。
近期活动:Gdevops全球敏捷运维峰会北京站

原价169元的门票限时免费
原价599元的VIP票限时199元(优惠码:dbavip)
峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721