
作者介绍
林伟壕,网络安全DevOps新司机,先后在中国电信和网易游戏从事数据网络、网络安全和游戏运维工作。对Linux运维、虚拟化和网络安全防护等研究颇多,目前专注于网络安全自动化检测、防御系统构建。
网络入侵前、进行中与入侵后的安全防御应该属于全程联动、环环相扣的,所以对于服务器的安全检测与阻断,笔者认为需要有一套统一的安全审计系统实现。这里的“审计”,并非一种亡羊补牢式的补救,而是融合了威胁发现、威胁分析和威胁消除的“三位一体”的安全防御体系。
本文将从安全审计的初心、设计理念、实现方式、应用和延伸等5个方面解析服务器安全审计系统的设计与实现之路。
一、为什么要安全审计
就像一套系统需要有端口监控、服务监控一样的道理,我们需要在服务器上派驻自己的“哨兵”,实时了解服务器安全风险状态。它不同于其它的运维监控agent,而是“专岗专用”,专门做安全监控,在性能消耗、功能、实现方式上都会有传统的运维监控agent不同。那么,安全审计能给我们带来什么?为什么“非它不可”?
试想,一般的服务器监控程序只收集硬件信息、系统性能、服务状态等数据,至于机器上运行什么操作系统内核、跑什么进程、开什么端口、有什么用户、有什么crontab,绝大部分监控程序通常无法收集,而这些信息却又随时可能告诉我们服务器可能发生的安全风险或威胁。
一般的日志收集关注的是业务数据,比如访问成功率、pv、uv等数据,但是隐藏在访问日志里的攻击数据,又往往淹没在正常访问中,这时通过常规的日志收集、分析程序是无法发现入侵数据的。
另外一种情况,如果服务器被入侵,运气好时还能去服务器查找到攻击日志,运气不好的话,攻击者直接删除history、syslog,这时要做入侵回溯难度立马上了一个level,所以,必须有实时日志转发,安全应急响应或监控程序时才能通过分析日志及时发现系统入侵痕迹或检查到用户su/sudo记录是否合法,或者机器被黑、故障发生前都做了什么操作。
服务器上跑的服务千差万别,种类繁多,基本上运维很难通过了解服务配置、端口开放情况,更别提可视化检查、管理访问控制了。因此,需要专门对iptables和常见服务的访问控制是否安全合理进行审计,最好通过操作系统或者应用安全基线制订了配置模板后,通过对比发现访问控制疏漏,结合外部漏洞扫描程序双管齐下。
2016年过去不久,“脏牛漏洞”席卷超过95%的Linux系统,让普通用户想提权就提权,这样的内核级漏洞,即便是BAT也头大,那么问题来了,如何及时发现这种远程检测不出来的本地漏洞,或者软件包存在漏洞未及时升级的问题,是不是也得靠服务器内部的“安全哨兵”去主动发现呢?
如果有一天,你的服务器半夜流量爆了,不是被DDoS,而是出现入向大流量,那是咋回事?很明显机器被黑,沦为别人DDoS的肉鸡,而你却一脸懵逼,查了半天不知道怎么被入侵的。有时候,即便有流量监控,也只是做入向监控,更有甚者,机器沦为肉鸡,还是运营商找IDC机房找到的机器,直接拔网线,这事在CNCERT底下也不是没发生过。
上面介绍了为什么“非安全哨兵不可”的原因,于是有同学说要不我找个开源的安全监控程序装一下。但是,这些开源的安全监控程序,就这么跑到你的生产环境,你做了代码审计了么,程序对系统性能消耗怎样,它的监控报警机制能否跟企业现有的运维监控报警机制结合,而不是发封邮件?当你有几台服务器的时候可以手工安装,可是当你有几千台几万台甚至十万台服务器,也还是手工安装吗?万一以后出了新版本要更新呢?
二、设计怎样的安全审计系统
所以,安全审计系统是需要被重新定义与设计的:它需要结合企业现有的运维体系,融合已有的批量部署手段、监控报警方式,通过组织代码审计、性能测试之后才能引入企业生产环境。此外,一旦部署规模上去了,对系统的调度、性能的考虑就要上升到架构上了。如何从企业实际情况触发,结合业界经验,去构建一套符合自己的安全审计系统显得很有必要。
笔者认为,一套称得上企业级的安全审计系统,至少应该考虑下面几个方面:
安全审计至少应该包含日志审计和系统安全审计,日志审计可以收集任意应用程序的日志,系统安全审计可以获取服务器系统内核版本、进程状态、端口开放情况、用户和crontab任务信息、已安装的软件包版本及其配置,通过自定义解析方式去格式化、清理数据,这个我们称为数据清洗。之后,将数据发送到统一存储,建立索引,方便用于后续的分析,这个我们称为数据存储。最后,各种需求方从统一存储提供的接口获取数据,进行各个维度的分析,然后产生统一报告,这个我们称为数据分析。
考虑到功能迭代的需要,从架构到组件上,安全审计系统都应该具备易扩展性。
为了大规模部署和升级,同时掌握各组件运行状态,安全审计系统需要具备易部署、易升级的特点。
毫无疑问,安全日志分析,也属于大数据的一个应用范畴。为了保证对大数据量的实时或离线处理,系统设计应当具备前瞻性,数据处理的性能应当是基本保证。
此外,一套合格的安全审计系统,应当至少包括以下几个组件:
Client:
需要考虑部署、更新以及数据收集分析呈现等;
需要考虑客户端是要c/s架构还是别的方式:使用Crontab或者Daemon;
需要考虑自研还是使用开源的,如果没有自研能力,就要采用具备丰富的社区支持和扩展性的开源实现方案。
Collector:
采集器要求高性能、高可用,在海量日志面前,采集器的性能是重中之重,一旦发现数据丢失,或者高时延,后面的数据越积越多,“木桶效应”会极其明显。
Storage:
海量数据存储,存储容量要大,IO性能要高。
Analyzer:
数据分析这部分,最主要的还是常见报表输出,比如可以针对服务器信息进行统计,输出一份整体分析表格,方便决策。
Scheduler
这么多组件上的任务调度以及配置推送,需要有一个“大脑”进行管理。当然,每个组件本身也可能是一套子系统,它也有自己的调度层,这两者没有冲突,反而使系统具备层次性,降低了系统耦合度。
为了方便后面介绍如何实现安全审计系统,下面提供一个安全审计系统的简单架构图。
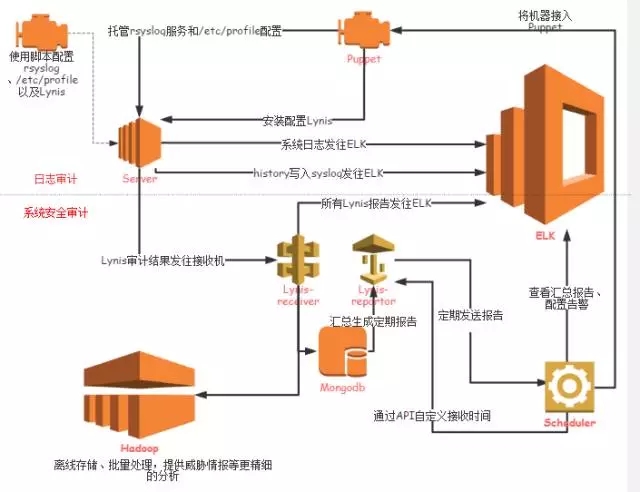
其中,日志审计通过记录用户命令和关键的系统syslog并转发给日志接收端,系统安全审计通过本地信息收集和漏洞扫描将服务器安全状态报告发送到相应接收端。
接收端进行处理分析后将关键信息生成报表并根据报警规则触发报警。
三、如何实现安全审计系统
通过上面的简单架构图,我们可以看到它的技术选型方案,上面提到的主要组件都有覆盖。
这里可能会有人问一个路线选择的问题:自研还是开源?笔者认为,任何不做二次开发,结合企业实际情况的开源应用本地化,都是耍流氓。所以,从实现成本上看,建议经过前期的开源方案调研后,结合企业情况做二次开发,是为上策。
说起开源安全审计工具,业界最知名的恐怕就是Cisofy主导的Lynis和社区主导的Ossec,两者各有千秋,是否一定要2选1,笔者认为这个没有统一答案。当然,在本文中,会有一个对比,然后给出建议。
系统安全审计
Lynis:*nix系统上使用Shell编写的系统安全审计工具
安装方式:
Debian:apt-get install lynis
Ossec:支持全平台的主机入侵检测系统
安装方式:
Debian:apt-get install ossec-hids/ossec-hids-agent
Windows: ossec-win32/64-agent.exe
功能对比

Lynis工作原理
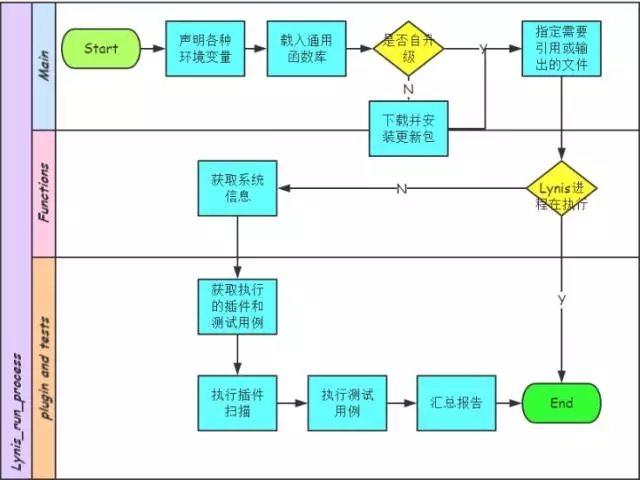
Ossec工作原理

client功能展示
Lynis

Ossec
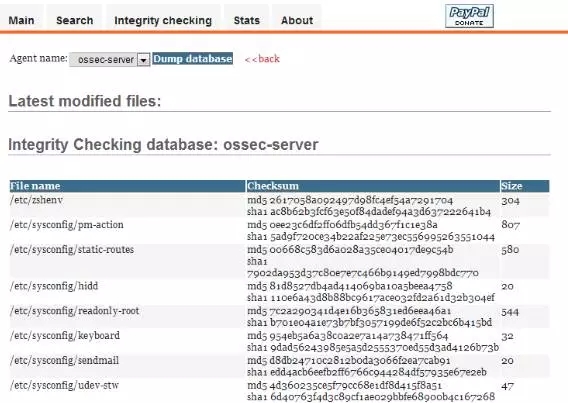
通过上面的对比,相信大家会发现,论功能和平台兼容性,Ossec优于Lynis,支持Windows上,而且毕竟Ossec是C/S架构,作为HIDS的实时性也会更好。
但是,如果你想审计Ossec,它是C写的;如果你不想在自己服务器跑agent,可它偏偏要跑。你怎么选?所以,按笔者考虑,为了充分利用两者的功能,将Lynis的自定义性强、性能消耗低、纯Shell脚本的优势和Ossec的跨平台性与实时性结合起来,可以在不同平台分别部署,这里会有一个异构问题,但是别忘了,两者对应的方案有一个交接点,就是Lynis+ELK和Ossec+ELK,我们可以按平台部署,比如Windows上部署Ossec,Linux上部署Lynis,将数据统一发送到ELK,剩下的实时日志分析、预警就交给ELK来做了。
日志审计
不管是Windows还是Linux,它们都支持rsyslog,所以可以将各自日志转发到syslog。当然,Ossec本身就是支持Windows日志审计的,所以这里的日志审计我们主要考虑Linux平台,实现上很简单,就是修改rsyslog与profile配置。
syslog配置:将指定Facility的syslog转发
'echo \'kern.*;security.*;auth.info;authpriv.info;user.info @x.y.z.com:514 \'> /etc/rsyslog.d/logaudit.conf && /etc/init.d/rsyslog force-reload'
用户行为日志:记录用户执行命令
'echo "export PROMPT_COMMAND=\'{ echo \"HISTORY:PID=\$\$ PPID=\$PPID SID=\$\$ USER=\${USER} CMD=\$( history 1 | tr -s [[:blank:]] |cut -d\" \" -f 3-100)\" ; } | logger -p user.info \'"> /etc/profile.d/logger_userlog.sh; source /etc/profile.d/logger_userlog.sh'
功能展示
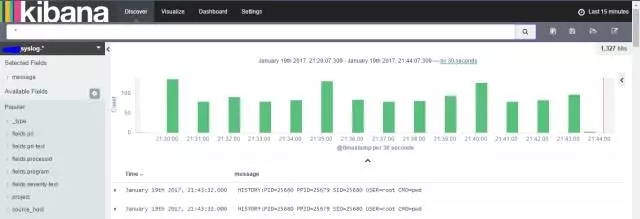
下图可看到用户执行命令已被记录并转发:


上图可以发现syn flooding攻击报警,下图可以发现kernel level的报警也被触发,用于硬件报警也不错呢。

ELK(Logstash-Elacsticsearch-Kibana)是目前日志处理最著名的方案之一,因为方案开源而且功能非常丰富,同时有Elastic公司背后支持,前景非常不错。这里的日志收集、存储与分析就是用这套架构来实现。
核心功能:存储、分析、展示系统
依赖:
logstash-2.3.2
elasticsearch-2.3.2
zookeeper
kafka
kibana_4.5.1
数据处理流图:
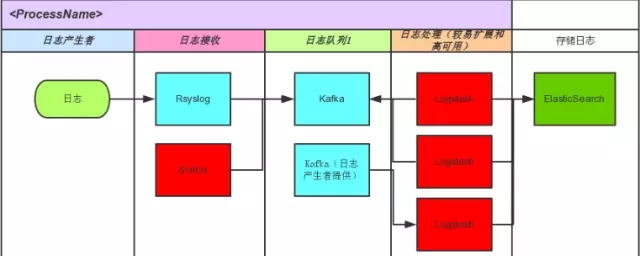
下面是各种角色说明:
Logstash:收集,分为shiper/receiver等多种角色
ElasticSearch:存储,支持实时查询(索引)与api
Kibana:UI,用于数据分析和展示
Kafka:分布式消息发布订阅系统,用于处理活动流数据和运营指标数据的消息缓存中间件
ZooKeeper:调度,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等
ELK效果展示
但是,这样就够了吗?有没有发现少了什么?细心的读者会发现在一开始的架构图里还有Hadoop的身影。那么,为什么要用Hadoop?
因为ELK的方案优势在于事实日志检索,但是对于非实时的、可以离线分析的数据,其实并不需要一直放在ELK上,毕竟Kibana的前端性能并不怎么好,我们可以另辟蹊径,从Hadoop走出一条数据离线批处理,用于海量数据分析的新道路。
下面给出一个Hadoop的应用案例,结合Python的mrjob库可以做自定义分析。
Hadoop离线分析日志
from mrjob.job import MRJob
from mrjob.step import MRStep
import heapq
class UrlRequest(MRJob):
def steps(self):
return (MRStep(mapper=self.mapper,
reducer=self.reducer_sum
),
MRStep(reducer=self.reducer_top10)
)
Hadoop功能展示

Python+Flask+Bootstrap
这里使用flask提供restful api供报告的增删查改:
#根据name获取资源中的某一个
@app.route('/language/<string:name>')
#POST创建资源
@app.route('/language', methods=['POST'])
#PUT,PATCH 更新资源
#PUT动作要求客户端提供改变后的完整资源
#PATCH动作要求客户端可以只提供需要被改变的属性
#在这里统一使用PATCH的方法
@app.route('/language/<string:name>', methods=['PUT', 'PATCH'])
#DELETE删除
@app.route('/language/<string:name>', methods=['DELETE'])
由于Scheduler需要自己写,为了做到高可用、高性能,建议使用HAProxy/Nginx+Keepalived的方案实现Scheduler,不需要代码上的支持,只是部署上使用wsgi加一层转发而已。
下面以Nginx为例提供配置模板:
location / {
proxy_connect_timeout 75s;
proxy_read_timeout 300s;
try_files @uri @gunicorn_proxy;
}
location @gunicorn_proxy {
log_format postdata '$remote_addr - $remote_user [$time_local] '
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" "$request_body"';
access_log /home/test/var/log/access.log postdata;
proxy_read_timeout 300s;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_pass http://127.0.0.1:8001;
}
核心功能:调度系统展示

可以使用Puppet/Ansible/Saltstack,考虑到实时性和扩展性,建议使用Puppet或者Saltstack,Ansible更适合初始化等重复性较少的工作。
Puppet
把相关功能模块化,接入时只需要include相关类即可。
lynis class:*nix系统安全审计
logaudit class:日志安全审计
ossec class:windows系统安全审计
四、如何应用安全审计系统
定期将服务器审计报告发送给相关人员,让他们保持对服务器安装态势的了解。另外,如果发现了安全风险,也可以让他们一并处理,形成一个良性的互动。
危险命令报警
message:chattr OR message:"touch -r" OR message:"pty.spawn" OR message:"nc -l" OR message:"*etc*passwd" OR message:SimpleHTTPServer OR message:http.server OR message:"ssh -D" OR message:"bash -i" OR message:"useradd"
系统漏洞检测:认证、文件系统浏览、应用漏洞、启动服务、防火墙、rsync服务、Webserver、数据库、文件系统权限、内核检查、SSH配置等。
获取漏洞机器IP、应用类型、归属信息用于确定报警与检查报告的分发
系统自监控与外部监控,用于保证系统自身的可用性和性能监控。
比如“脏牛漏洞”的批量检测,可通过收集所有服务器操作系统内核进行对比
webserver access.log分析,从中发现SQL注入或者getshell的敏感语句,推荐方案有Nginx+Hadoop或者Nginx+ELK。
蜜罐日志分析,在企业内外网部署蜜罐后,用来收集攻击特征库,做情报收集。推荐方案有:Beeswarm+ELK。
五、延伸和扩展
这套解决方案无疑在功能上属于集大成者,但还需要优化用户体验、降低客户端的异构性,这可以通过二次开发Lynis或者Ossec来实现。
是否推送修复补丁或者只提供修复方案。这个涉及到系统定位问题,本文一开始我们提到这套架构应该是“检测+分析+阻断”的“三位一体”方案,但现有的方案需要在检测与分析之后人工去做阻断,所以这套系统还需要进行扩展,比如与网关联动,将符合攻击特征的数据流直接抛弃,或者与黑名单系统联动,将自己发现的攻击特征上报黑名单系统,然后其他应用系统调用黑名单系统作为本地过滤的依据。这里web应用可以使用web application firewall(WAF),db应用可以使用Mycat等db proxy进行流量拦截。
通过这套系统,我们会发现很多系统、应用级别的漏洞,如何高效修复漏洞会是下一个亟待解决的问题。解决方案就是依赖业界经验和企业实战经验构建安全知识库,提供统一的安全基线、安全配置模板以及漏洞修复方案。然后依赖企业自动化运维框架去推送配置、升级系统或者应用。
对于安全知识库,之前我们可以用“某云”(已停摆),现在可以去https://github.com/hanc00l/wooyun_public上下载离线知识库进行研究。也可以结合公开的安全基线标准去构建自己的安全知识库和配置模板。
当然,终极大法还是爬虫:Python+Scrapy,通过搜索引擎把你想要的知识库爬取下来。也参考方案:http://www.cnblogs.com/buptzym/p/5320552.html
毫无疑问,这套方案注重于内部风险发现或者是站在内部去发现问题,所要构建全面的安全风险与威胁防御方案,还需要依赖外部扫描系统,还需要与CVE等公开漏洞库进行联动,甚至需要获取最新的威胁情报资源,在类似之前的MongoDB勒索问题大规模爆发之前,提前做好防御措施,不管是批量检测应用配置,还是批量扫描系统,只要能提前做好准备,其实都是一种胜利。
所以下面就外部扫描系统、自建CVE库和威胁情报收集提供一些解决方案,最终还是希望与这套服务器安全审计系统进行联动,实现安全风险与威胁的“检测+分析+阻断”的“三位一体”的目标。
外部扫描系统
自建CVE库
cve search:https://github.com/cve-search/cve-search
开源威胁情报
这三套解决方案的具体应用会在以后的文章详细介绍,结合企业应用场景来讲,敬请期待。
参考资料
OSSEC: http://ossec.github.io/
Lynis: https://cisofy.com/lynis/
PUPPET: https://puppet.com/
wooyun_public: https://github.com/hanc00l/
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会·北京站

报名链接:
http://www.bagevent.com/event/643565#website_moduleId_60229
峰会官网:www.gdevops.com








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721