

(点击底部链接获取杨建荣演讲完整PPT)
讲师介绍
杨建荣,DBAplus社群联合发起人。现就职于搜狐畅游,Oracle ACE、YEP成员,近10年数据库开发和运维经验,擅长电信数据业务、数据库迁移和性能调优。持Oracle 10G OCP、OCM,MySQL OCP认证,《Oracle DBA工作笔记》作者。
今天分享的内容是技术发展解读,还有一些学习的建议,其实更多的是一些点,我希望把这些内容串成一个面,让大家通过我提供的这些小故事、例子、技术小测试等能有所感悟,我的目的就达到了。

首先分享的是一个简单的小问题,这也是我很早之前做DBA时碰到的一个坑。
说简单些就是把MySQL重启一下,而当时碰到这个问题的背景比较复杂,有一个同事要离职了,他说这个库跑了很多年都没什么问题,有一个主从的环境,都是正常的,其实不用管了,好多年了一直没有出过问题,他这么一说,我就不敢去动了(其实也是幼稚)。结果这个环境没有多长时间,有一天我们收到一个报警,说这个从库服务器宕机了,要保证数据的高可用,于是准备搭建一个备库,却发现主库的binlog没有开启!所以那个备库其实是一个假的备库,而这个问题真是细思恐极。到底是流程交接的问题还是个人的问题,都有,很多问题如果细剖起来有五花八门的问题,如果没问题都万事大吉,所以在这种情况下我申请了维护时间重启主库。
但是发现重启之后数据库起不来了,数据字典也有一些问题,这个也花了一点功夫修好,算是有惊无险。但是后面有一些应用的同学说数据库连不上,就查各种原因,一个看起来很简单的重启竟然带来了这么多的问题,最后排查发现有一部分应用连接之前就有问题,也是通过以前的日志去推理。所以一件很简单的事,最终引发出这么多的问题,这是我入行碰到的一个印象很深的问题,也是一个比较大的坑。
所以,通过这个事情我做了一些基本的反思,作为一个新人,不光是要基础知识掌握扎实,你还需要去掌握一些其它方面的技能,比如沟通,比如学习方法等。我自己也开了一个微信公众号,经常有很多朋友在后台留言,有些是刚入行有些困惑,有些是入行有些年后有些迷茫,会问我怎么办,怎么样去调整一下自己的状况。
对于学习,我引用Oracle行业非常有名的专家Jonathan Lewis说的一段话,收录在《Oracle的核心技术》里面,有一段话我看了以后非常受启发。这也是我给大家学习的一个基本态度:

对我们绝大多数人来说,他认为在这种学习中始终要懂得去权衡,很多东西对于数据库来说大体知道引擎的工作,有一些不必要的细节就不用特别细究,注意,不要浪费时间去研究不必要的细节,而是要找到折中的办法,使你所掌握的知识足以预判Oracle在你没见过的场景中会怎样做。我更倾向于从实际问题出发,能够牵扯出来更多学习的点,然后逐步去深入,由此达到一个面,最终形成自己的知识体系。
明确了学习态度,我们来看看一个技术发展的基本情况,以下是MySQL被收购后,开发团队成员的一个去向图。
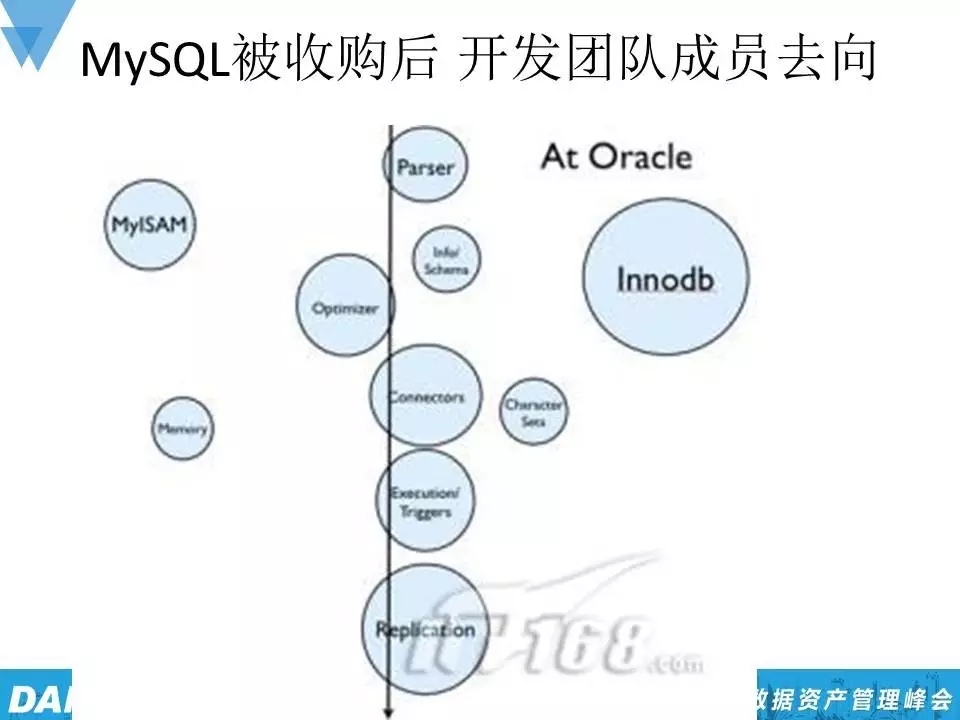
而MySQL被Oracle收购后的发展大体是这样的一个比例,右边的开发人员是Oracle公司的,左边的则是原来的MySQL团队的。
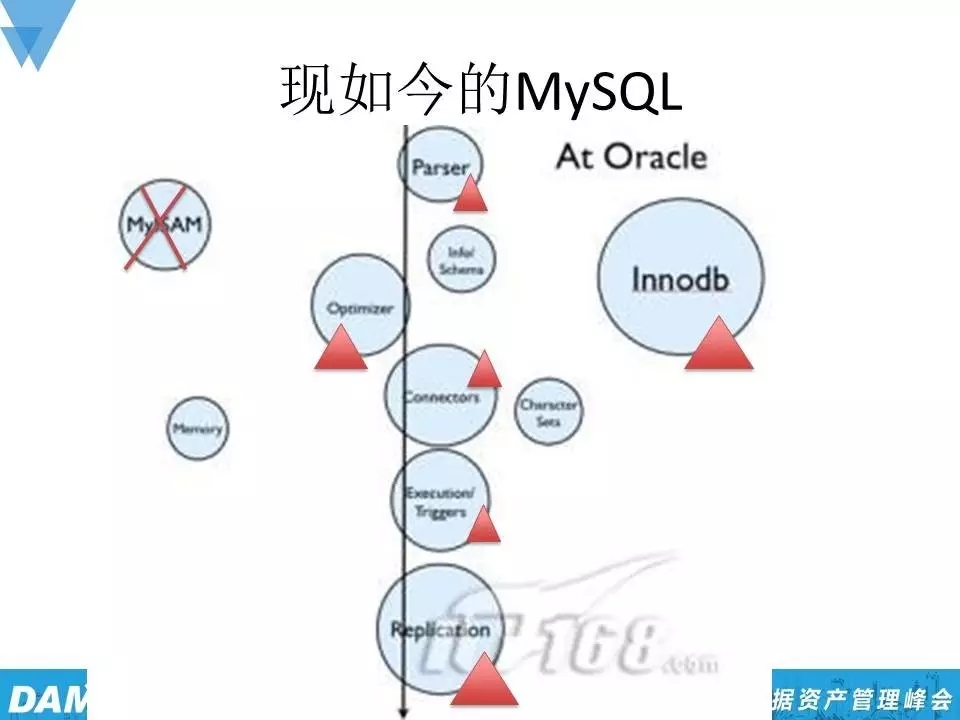
过了些年,我做了一个标识,在MySQL8.0中会最终抛弃MyISAM,InnoDB发展很快,优化器也有了很大的改进,通过这样一些小的细节你会发现整个技术的发展非常快,但其实也就短短几年的时间。所以通过这些我们可以看到,技术是不断发展的,在这个过程中,我们就需要像司机一样,不断根据道理情况来适度调整学习的方向,不要花太多的时间在一些废弃、过时的特性上。
因为我也从事DBA工作,经常跟很多同学交流,有些同学不了解我们DBA做什么,其实让我们很尴尬。很多人说DBA不就是建一个表,修改一下数据,听起来好像也没什么特别要做的事情,下面我通过以下五个层面去解读一下DBA工作内容和技术建议。

一个是数据管理,这个是基本功,一定要做好做深。架构设计方面,就是数据库架构师,要学会如何从应用设计需求去做一些工作,如果能把那个“库”字去掉就更好了。开发扩展,其实对DBA比较高的要求,不光有脚本开发能力,还有掌握开发语言。技术前瞻,可能你的技术目前没有问题,但如果从前瞻的角度来看,可能在几年之内会有什么样的发展和隐患。最后是综合能力,我会举一个Oracle迁移的例子,告诉大家怎样去做一个迁移的优化。
总体来说,现在对DBA的要求也在变高,如果能够把DBA打造成一个“特种兵”的角色,对个人和公司都是双赢。
1、数据管理

MySQL无法创建表的问题,对DBA来说很简单,用脚本创建一个表,这是我一个同事碰到的问题,他说这个问题好奇怪,有个创建表的需求,创建了10多个表,结果有2个表创建不了。我的一个猜测,可能是大小写的原因,可能是数据类型、触发器、外键导致的,也很有可能是一个Bug,而根据perror的结果来看可能是属于外键,不过暂时没有找到任何线索,所以我们逐步排除。

我做了一些简单的测试,发现给这个表后面再加一个S就可以了(其实就是给表改了个名字)。或者是改用小写,当然开发的同学不同意了,说不太好改,而且问题没有根本解决,只是把这个问题规避了一下。

我们又做了一些排查分析,最后发现开发同学是用Navicat工具间接导致,这个工具可以做查询,比较方便。不是说这个工具不好,而是在变更前,这个工具默认会加这么一个选项,Setforeign_key_checks=0,这样外键的检查就不生效了,所以在部署脚本的时候,有两个表始终有问题。当然这个案例我们也做了总结,一个是第三方工具多多少少可能会有一些影响,需要评估。第二,开发同学提供这个脚本,当时提供的列表得不是很完整。比如说变更的表12个,他只提供了10个表的变更,他认为另外2个表已经有了就也不提供了,结果最后发现它们之间有一些关联,导致了一些问题。
所以很多时候我们做这个工作还是不断地去规范,有同学说这个问题有一定的局限性,那我们不用第三方工具,那我们再来一个更简单的,我们看一下MySQL字段长度怎么去设计。
2、架构设计

MySQL里面的页是16k,这个存储是用IOT的方式存储,字符集很丰富,有latin1,支持火星文,还有一些gbk还有utf8。如果你是gbk,表里含有一个字段,可以指定为32766字节,如果再长一些就不行了,gbk类型,行长度是最大为65535,则varchar列的最大长度算法就是(65535—2)/2等于32566.5。
下面是一个简单的小测试,能够马上看到效果。

而对于latin1,长度范围会广一些,如下图所示。

而对于utf8,因为对应3个字节,所以算下来长度范围就小一些,简单测试如下图所示。

所以我们在工作时,开发同学提供一个语句,你看起来也没有什么差别,但是前期设计时一定需要把这些细节考虑到。当然大家的表不可能是只有一个字段,这时候牵扯到这样的一个问题,那就是更实际的问题,我来抛出一个问题。

如果是gbk字符集,含有下面的几个字段,则memo字段是varchar类型最大长度是多少,这是一个很常规的问题,如果把这些连接起来去演算一下,数值型是4个字节,字符型乘以2,含有字符型的长度小于255,所以减去1即可,这样下来就是32743。
有的同学说我们这个表设计字段也不多,可能几个就可以了,那行,我们继续聊一个更有挑战的,有有一些公司的开发同学对binlog有一些需求,他们会用解析binlog去做一些基本的搜索,他们去做的时候有个疑问,对于数值类型,是分为有符号和无符号两种,那怎么在binlog去体现这个差别,这个就需要去验证一下了,我们还是拿出基础知识,下面是一个数值类型的范围表。
3、开发扩展

其实数值类型还有更多对于这样的情况binlog它是怎么去展现的,是有符号还是无符号的,你把这个搞明白,数据处理的时候就有思路了,我们来看看进制转换。

我简单做了一个小的测试,—1是十进制的,另外一个是最大值,如果从10进制转成二进制,就是一个数据临界点,他们两者转成二进制以后得到这个值都是一样的,看起来这个—1和最大值是没有差别的,但是如果是实际的场景是天壤差别,这个差别非常大。
在此我们可以简单做一个小测试,创建一个表,加两个字段,我们把这个最大值和—1都插入进去,会生成一些binlog记录,我们解析binlog,来看看binlog里面是怎么处理的。

Mysqlbinlog解析后的内容如下:

到这里我们能够得到一个基本的结论,有符号和无符号的数都会按照无符号去处理,如果你有这样的开发需求,你就需要去了解这样的一些边界。
4、前瞻
再来看看前瞻的内容,还是一个四两拨千斤的小案例。
是关于时间类型的默认值的问题。有一个同学提了一个数据变更,他说自己测试没有问题,但是我这边线上环境运行的是有问题的,最后发现他的环境是MySQL 5.5,我是MySQL 5.6,同样的语句下,在MySQL 5.5有问题,MySQL 5.6没问题,显示是时间字段在不同版本的处理方式不同。


所以能够根据很简单的测试总结出来,是动态的默认时间值的支持不同。如果细分一下,会发现datetime和timestamp类型还是有很多差异的地方。

大家如果观察得比较仔细,会发现这个数据类型是datetime和timestamp都是时间字节,datetime是8个字节,timestamp是4个字节,大家去设计的时候也要去考虑。这个问题的解决简单总结一下,一个是对于版本为了保持兼容,那我就不需要加默认值了,第二个对这个问题做了一个权衡之后,他们觉得用timestamp目前可以解决我碰到的问题。
5、综合案例
最后是一个综合案例,我就说一个Oracle数据迁移的优化方案吧。
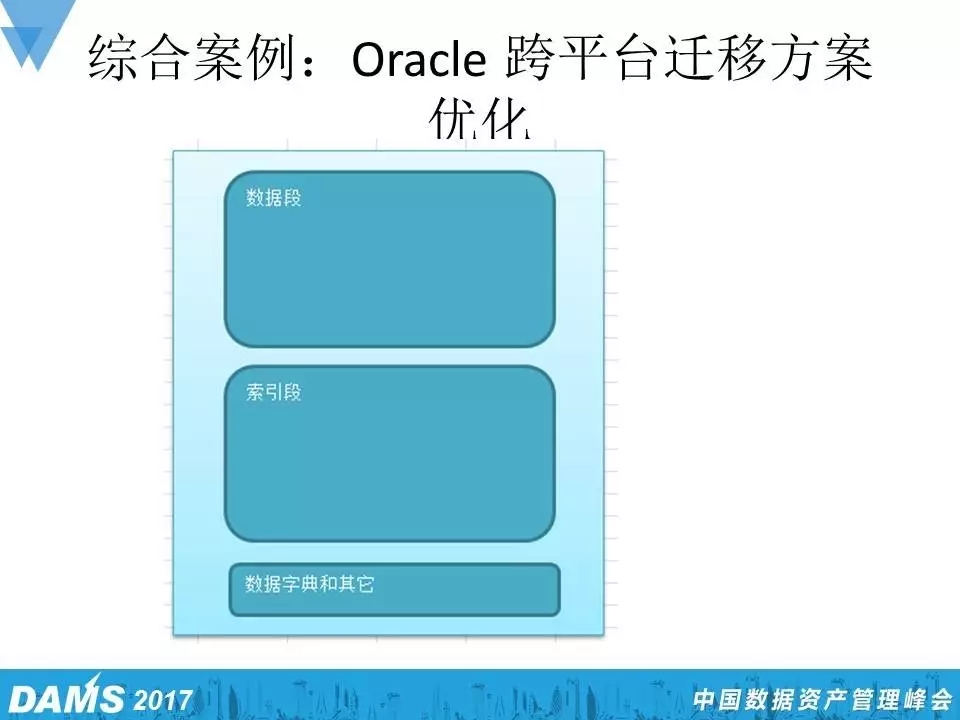
简单分享一个迁移的小案例,这是一个小机的环境,迁移到X86,数据量倒不大,800多G,但是这个环境硬件非常老,跑了很多年了,也没有什么业务增长,大多数是数据查询。这样的一个业务又是一个全局的核心业务,迁移的工作最终是拖了很多年,而在后期迁移的时候,还是碰到了很多纠结的问题。数据迁移我也想了很多的方案,因为版本比较老,维护窗口时间很短,就想怎么尽快迁出来。我们当时做了一些更细节的评估,这样一个数据库,发现数据段和索引段占的比例是比较高的,占到了90%以上的比例,剩下的是数据字典和其他数据,不到10%,如果是这样的一个平滑迁移的话,把索引段这部分的工作先做好,整个迁移的数据量少了近50%。
所以我们不断拆分,于是有了下面的这个比例图。
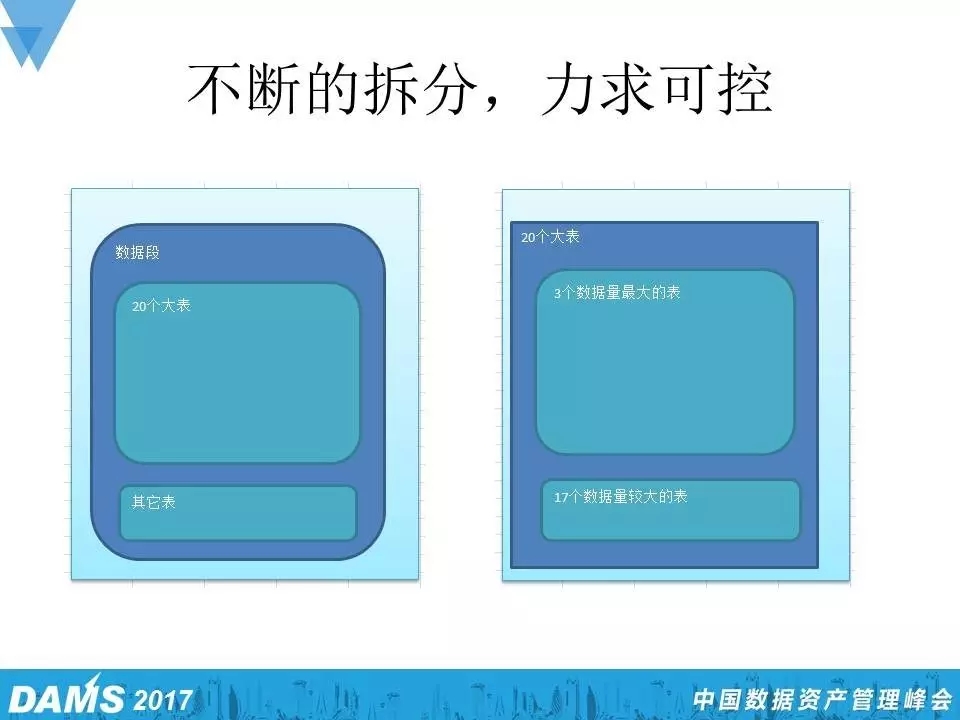
我们发现这个库里大概有20多个表是相对比较大的,一些其他的表是比较小的,基本上占到了90%的一个比例。对20个大表又做了一个基本的评估,我们发现这20个大表里面有3个表特别大,占到了整个数据量的90%。这几个大表虽然大,但是做查询比较多,基本没有写入,最后用OGG的方式去同步,占比很高的数据同步工作就做好了,而对于剩下的17个表,因为单表数据量也不大,就采用物化视图的prebuilt方式来创建,达到增量刷新的目的,当然如果用OGG同步也是可以的,里面有一些其他方面的考虑。所以这样的一个迁移,到了后期就逐步拆分,归类,最后的迁移只需要真正迁移5%的变化数据。所以说数据迁移没有最好的方案,只有最合适的方案。我讲了这么的案例,很多都是比较小的案例,看起来挺简单,数据类型都是比较小的案例,能够通过这些小的地方能够不断的去打磨自己。
掌握了上面的技能,你的竞争力就会大大增加,公司会愿意把一件事情交给你来负责,而不是说让你去做某一个很具体的工作。所以我再来说说人才的评价标准。

我看到微软评价人才的标准,我觉得讲得挺透彻的,大体就是学习归纳的能力,还有化繁为简的能力。
学习是一个持续的过程,都是以点到面,不断积累的过程。
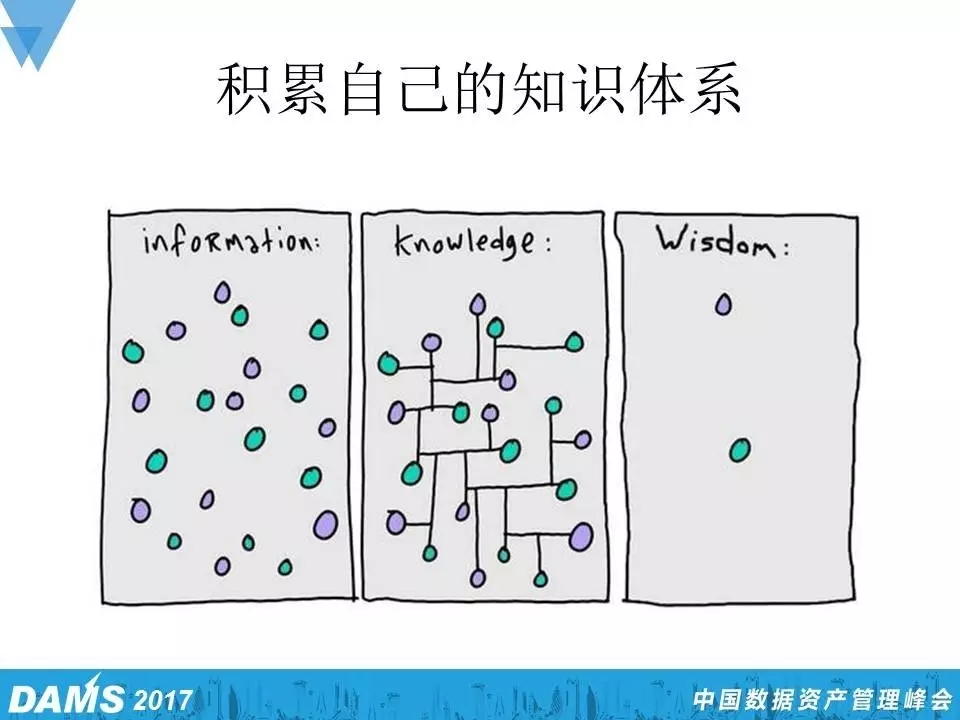
这个是我比较有感触的一个图,你碰到日常问题的时候有很多的一些总结,最开始碰到的比较零散的东西,然后你如果不断去总结去梳理形成一个知识体系,对某些方面有更多的深入就会变成财富。
而在这个过程中,矛盾和困扰也会并存,看了下面的图你可能会有一些顿悟的感觉。

这个图是我看《大话数据结构》时候发现的,我们学了很多的知识,但是很多和能够赚钱的知识是有差别的,我们应该学习的知识很多,但是它和能够赚钱的知识之间是有一个交集,这一定需要一个积累的过程。
我今天的分享就到这,谢谢大家。
PPT获取链接:http://pan.baidu.com/s/1c2epJEg








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721