
作者介绍
张秀云,网名飞鸿无痕,现任职于腾讯,负责腾讯金融数据库的运维和优化工作。2007年开始从事运维方面的工作,经历过网络管理员、Linux运维工程师、DBA、分布式存储运维等多个IT职位。对Linux运维、MySQL数据库、分布式存储有丰富的经验。
最近开始负责财付通数据库的相关维护工作,其中有几套系统使用的Spider引擎,为了以后能更好地对这套系统进行维护,对Spider做了一些功课,将Spider引擎的功能、使用场景、部署、实战测试等做个简单的总结,希望同学们看完本文后能对Spider引擎有个更深入的了解。
先来说两个我们DBA经常遇到的场景:
场景1:有两个分布在不通实例上的多张不通的表,想要通过某个字段关联,做一个统计,或者想将分布在不同实例的表,合并到一个实例中来做一些查询。
场景2:由于数据库容量的瓶颈或者是由于数据库访问性能的瓶颈,将某一个大库、大表或者访问量非常大的表进行拆分,然后分布到不通的实例中。
这两种场景覆盖了我们DBA经常接触的垂直拆分和水平拆分,在这种场景下往往面临着如下几个窘境:
这些表的访问和存取需要额外的路由规则,复杂度很高。
需要做数据汇总或者统计的时候,非常麻烦。
我们想到的解决办法可能有如下几种:
(1)使用数据库中间件(MySQLfabric/TDDL/Cobar/Atlas/Heisenberg/Vitess)
这个似乎是大公司专用的,由于存在各种各样的限制,小公司往往使用起来非常不方便,对于里面存在的各种坑也没办法很好规避。
(2)使用MySQL分区表
无法解决磁盘空间瓶颈以及服务器性能瓶颈。
(3)使用Galera Cluster for MySQL
支持数据库的高可用以及能实现读请求的扩展,但是对于写请求无法实现性能上的突破。
(4)使用MySQL的多源复制
仅仅适合将多个实例的数据聚合到一起,用来做数据统计,但还是存在磁盘空间的瓶颈。
(5)使用federated
可以实现将数据聚合,对于水平分割的场景并不适用,并且性能方面也存在比较大的问题。
(6)MySQL Sharding和Spider
MySQL Cluter是MySQL Sharding的一种,对于这种需求是个比较好的解决方案,不过使用于生产环境的案例比较少。还有一个Spider分布式引擎方案,非常适合前面我们讨论的两个场景,下来将会做深入的介绍,该引擎目前已经集成到了MariaDB中,目前最新的版本是Spider 3.2.37。
本文就是基于Spider的分布式数据库解决方案,下面就来详细介绍:
1、Spider引擎是什么
Spider引擎是一个内置的支持数据分片特性的存储引擎,支持分区和XA事务,该引擎可以在服务器上建立和远程服务器表之间的链接,操作起来就像操作本地的表一样。并且后端可以是任何的存储引擎。Spider引擎根据表的设置的规则以及server表的规则自动进行智能路由,实现对后端数据库不通的表或者数据分片的访问和修改。因此该引擎对业务是完全透明的。
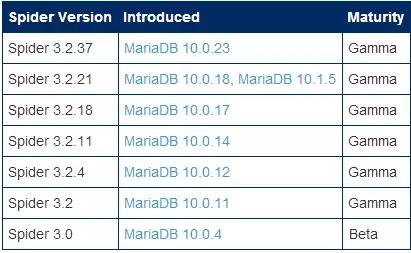
目前Spider引擎已经集成到了MariaDB中,安装使用非常方面,目前最新的版本是Spider 3.2.37。更多信息可以访问:https://mariadb.com/kb/en/mariadb/spider-storage-engine-overview/,具体的版本历史如下图所示:
2、Spider架构图
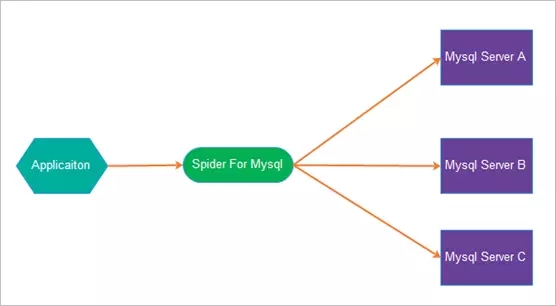
3、Spider的优势
对业务完全透明,业务不需要做任何的修改。
对于分库分表的逻辑业务不需要关心,只需要通过Spider作为代理入口,访问数据对应在后端哪台server上spider自动帮你处理。
方便横向扩展,能解决单台MySQL得性能和存储瓶颈问题。
对后端的存储引擎没有限制。
间接实现垂直拆分和水平拆分功能。
通过spider和后端的数据库连接,可以是独立的表,也可以是基于分区表,分区表支持哈希、范围、列表等算法。
完全兼容MySQL协议
由于MySQL特殊的插件式存储引擎架构,server层负责SQL解析、SQL优化、数据库对象(视图、存储过程等)管理;存储引擎层负责数据存储、索引支持、事务、buffer等,两者之间通过约定好的handler接口进行交互。SQL解析、优化与执行交给server层处理,几乎支持执行任意类型SQL访问。
4、Spider的劣势
Spider的表本身不支持查询缓存和全文索引,不过可以将全文索引添加在后端数据库中;
如果采用物理备份,Spider无法备份后端的数据,因为数据本身是存放在后端。可以对后端的MySQL一一做物理备份;
Spider本身是单点,需要自己做容灾机器,比如通过VIP的方式;
多了一层网络,性能上会有一些损耗,尤其是跨分区、跨表查询性能会差一些。
1、垂直分表的场景和解析
垂直分表场景图
垂直分表场景解析
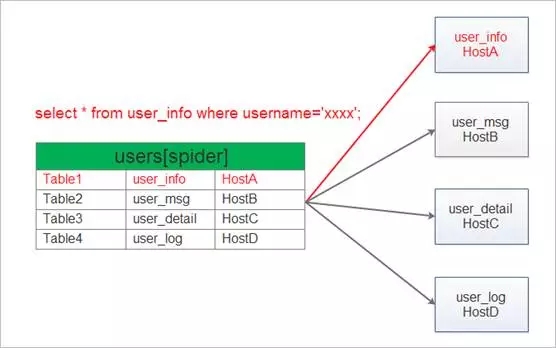
从上图可以看出,Spider后面接4台DB server,可以将不通功能的表分布到后端不通的DB server中,比如user_info的表专门存放在HostA中,user_msg表存放在了HostB中,user_detail表存放在了HostC中,user_log表存放在了HostD中。
在图中的红色部分,当我们执行红色部分的SQL时,Spider会通过user_info表的映射关系以及HostA的IP映射关系,将查询user_info表的请求都转发到HostA上,HostA查询完成后再将结果发给spider服务器,Spider再转发给客户端。
2、采用水平分表的场景
水平分表场景图
水平分表场景解析
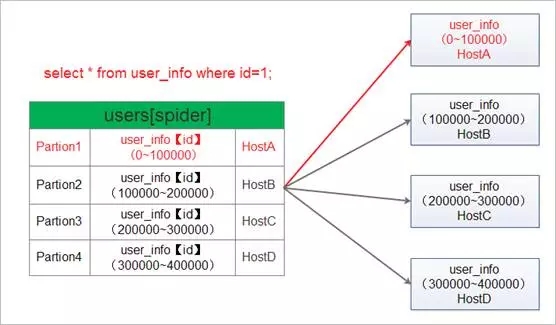
Spider支持多种水平分表的模式,目前支持hash分表(hash)、范围分表(range)、列表分表(list),我这里用range来说明水平分表的工作原理。
从上图中可以看出Spider对user_info表针对id进行了分区,将0~100000的记录存储在了HostA,100000~200000的记录存储在了HostB,200000~300000的记录存储在了HostC,300000~400000的记录存储在了HostD。当用户访问user_info的某条或者多条记录的时候,Spider会根据分区的情况,对相关的记录落在某台或者多台DB server上,再进行转发。比如select * from user_info where id=1这个SQL,spider在收到这个请求后,会跟进分区情况选择对应的DB server进行转发。这里会将该请求转发到HostA中。HostA处理完成后,再将结果返回给Spider server,Spider再将结果转发给发起请求的客户端。
1、Spider的安装部署
从Spider 10.0.0.4版本开始,Spider引擎就集成到了MariaDB中,集成后安装就非常的简单,安装步骤如下:
安装MariaDB到Spider Server以及后端多台DB Server上;
安装方法非常简单,这里不在赘述,具体可以参考:https://mariadb.com/kb/en/mariadb/getting-installing-and-upgrading-mariadb/
安装Spider引擎到Spider Server上(后端的DB Sserver不需要安装Spider引擎)
或者登录MySQL后执行
备注:install_spider.sql在share目录下面。
这个命令所做的事情如下:
创建Spider相关的系统表
spider_link_failed_log
spider_link_mon_servers
spider_tables
spider_xa
spider_xa_failed_log
spider_xa_member
创建Spider相关的表结构
加载Spider引擎
检查Spider引擎是否安装成功

如果出现上图所示的结果就说明已经支持Spider引擎了。
2、Spider的使用实战
备注:本实践环境基于tspider-1.8.5环境全部验证通过。
Spider实战拓扑图
在实战部分,我使用了2台DB Server,部署图如下:

实战前准备
a、创建Spider Server访问后端DB Server的权限(后面配置中需要用到)
b、创建Spider后端DB Server的配置
可以通过执行如下SQL的形式直接创建
create server backend1 foreign data wrapper mysql options (host '10.128.128.60', database 'test', user 'spider_db_all', password 'spider_db_all', port 3306);
create server backend2 foreign data wrapper mysql options (host '10.128.128.88', database 'test', user 'spider_db_all', password 'spider_db_all', port 3306);
也可以通过直接给mysql.servers表中直接插入相关的记录,不过后面执行flush hosts才能生效
insert into mysql.servers(Server_name,Host,Db,Username,Password,Port,Socket,Wrapper,Owner)values ('backend1','10.128.128.60','test','spider_db_all','spider_db_all',3306,'','mysql','');
insert into mysql.servers(Server_name,Host,Db,Username,Password,Port,Socket,Wrapper,Owner)values ('backend2','10.128.128.88','test','spider_db_all','spider_db_all',3306,'','mysql','');
创建完成后可以直接查询mysql.servers表,确认是否添加成功,如下截图所示:

b、创建基础测试表
在后端两台DB Server上创建基础测试表(在60和88上执行)
create table test_spider (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) engine=InnoDB default charset=utf8 comment 'spider test base table';
Spider引擎实战
a、建立垂直表(远程表进行测试)
create table test_spider (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='server "backend1"';
创建之后,执行对应增删改查,看看是否对应的操作都发生在了backend1对应的DB Server上?
测试完成后,删除掉Spider 服务器上的test_spider表,你会发现drop掉Spider上的表,不会导致后端DB Server上的表被删除。
b、建立hash分区表
create table test_spider (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='wrapper "mysql", table "test_spider"'
PARTITION BY HASH (id)
( PARTITION pt1 COMMENT = 'srv "backend1"',
PARTITION pt2 COMMENT = 'srv "backend2"') ;
创建之后,执行对应增删改查,看看是否对应的操作都发生在了backend1和backend2对应的DB Server上?
测试完成后,删除掉Spider 服务器上的test_spider表,你会发现drop掉Spider上的表,不会导致后端DB Server上的表被删除。
c、建立range分区表
create table test_spider (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='wrapper "mysql", table "test_spider"'
PARTITION BY range columns (id)
( PARTITION pt1 values less than (100000) COMMENT = 'srv "backend1"',
PARTITION pt2 values less than (200000) COMMENT = 'srv "backend2"') ;
创建之后,执行对应增删改查,看看是否对应的操作都发生在了backend1和backend2对应的DB Server上?
测试完成后,删除掉Spider 服务器上的test_spider表,你会发现drop掉Spider上的表,不会导致后端DB Server上的表被删除。
d、建立list分区表测试
create table test_spider (
id int,
username varchar(20),
address varchar(128),
primary key (id),
key (username)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='wrapper "mysql", table "test_spider"'
PARTITION BY list columns (id)
( PARTITION pt1 values in (1,3,5,7,9) COMMENT = 'srv "backend1"',
PARTITION pt2 values in (2,4,6,8,10) COMMENT = 'srv "backend2"') ;
创建之后,执行对应增删改查,看看是否对应的操作都发生在了backend1和backend2对应的DB Server上?
测试完成后,删除掉Spider 服务器上的test_spider表,你会发现drop掉Spider上的表,不会导致后端DB Server上的表被删除。
性能测试可以采用sysbench来测试,和MySQL单台以及后端挂多台DB的场景进行对比,确认Spider引擎的性能和优势,由于手头没有合适的设备这部分等以后有时间再进行测试,maria'DB的官网已经有对应的测试方法和结果,有兴趣的可以去https://mariadb.com/kb/en/mariadb/spider-storage-engine-overview/查阅。
为了撰写本文,翻阅了不少资料,感谢前辈们的贡献,罗列如下:
1、https://mariadb.com/kb/en/mariadb/spider-storage-engine-overview/
2、https://mariadb.com/kb/en/mariadb/spider/
3、https://mysqlstepbystep.com/2015/04/03/spider-for-mysql-overview/
4、http://km.oa.com/group/18974/articles/show/143399?kmref=search&from_page=1&no=2
5、http://km.oa.com/group/17613/articles/show/217681?kmref=search&from_page=1&no=1
6、http://www.chriscalender.com/getting-started-with-the-spider-storage-engine/








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721