
梁敬彬
福富研究院副理事长
《收获,不止SQL优化》作者
福富特级专家,负责数据库优化、设计及培训等相关工作,国内一线知名数据库专家,公司唯一四星级内训师
主题简介:
1、谈SQL优化的方法论
2、SQL改写优化的技巧
3、SQL改写优化的误区
4、经典案例与实战落地
SQL优化的本质就是减少访问路径。相信大家都有学到了很多减少访问路径的思路,比如增加索引从全表扫描转换成索引范围扫描,比如把表改造成分区表从而从全表扫描转化成局部分区扫描,这些都属于不需要改写SQL就能完成的减少访问路径的思路。当然,在很多场景下,我们必须要完成一些等价改写,比如Case When改造、Rownum分页改写等等。
除了减少访问路径外,还要注意避免外因的影响,比如一些执行计划不稳定、所在环境的资源不足等等,这些也是我们需要注意的。
总体思路如下图:
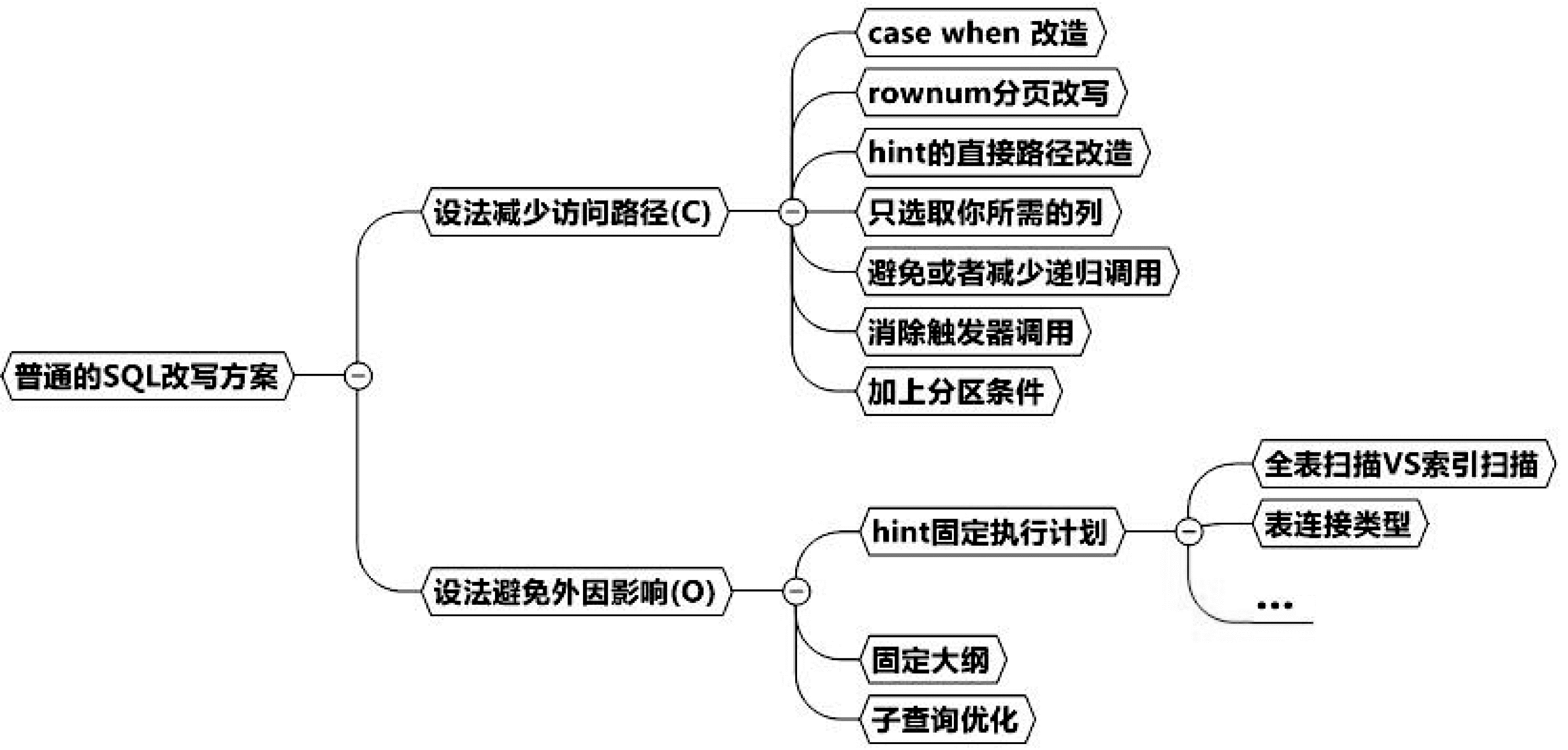
一、设法减少访问路径
接下来我们从Case When、Rownum、Hint直接路径改造、只取所需列、避免递归调用、rowid优化这6个案例展开,向读者展现不同写法前后的优化效果。
1、Case When改造
这里精心构造一个经典案例,其中CNT_TEMPORARY_Y、CNT_CREATED_NEW、SUM_ OBJID_STATUS_V、SUM_OBJID_GENERATED_、SUM_OBJID_GENERATED_M、SUM_OBJID_GENERATED_Q这6处是构造的列,作为结果集要展现出来。实战写法中T表被访问了多次,具体如下:
环境构造:
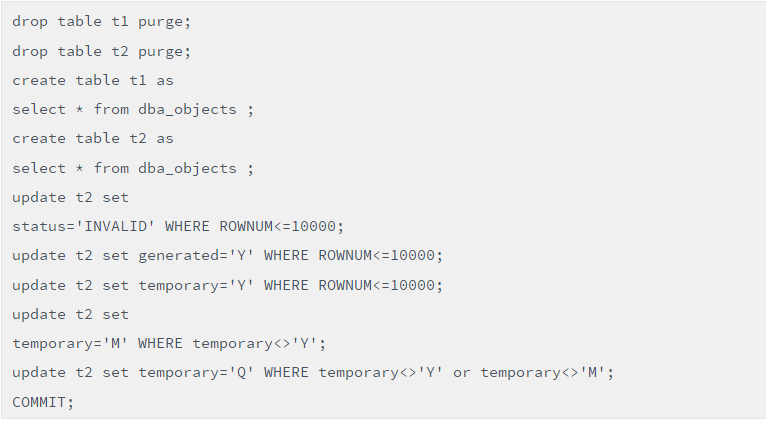
写法1:

对应的执行计划:

脚本(让表被访问多次的低效写法)
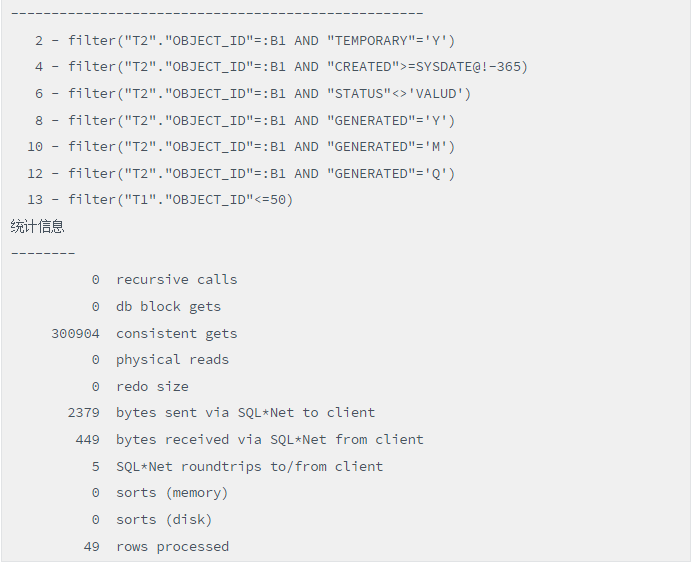
这里通过执行计划,可以看出T2表被访问了6次,该SQL语句的逻辑读高达300904!来,看看Case When改造的写法2,如下:

写法2执行计划如下:
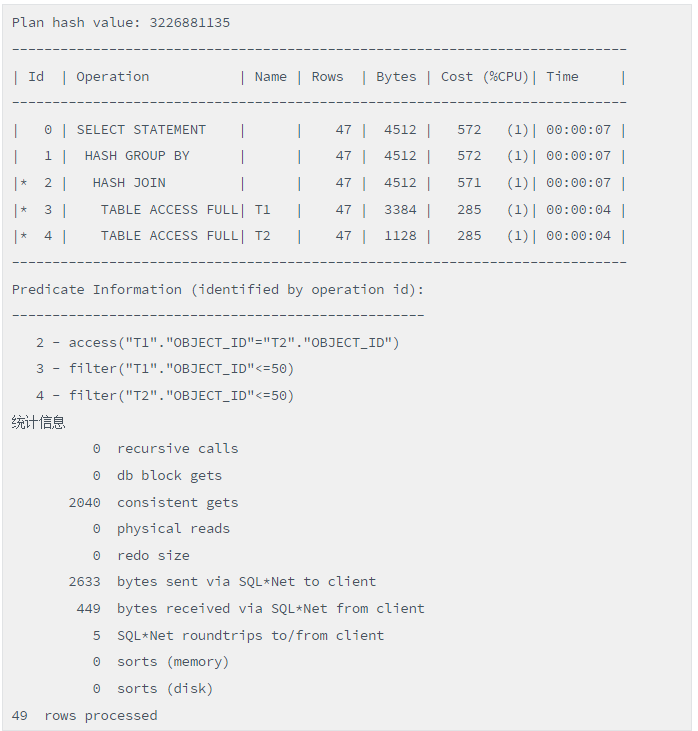
脚本(Case When改造后的高效写法)
观察写法2的执行计划,我们发现T2表的访问次数仅1次。而且逻辑读为2040!差异如此巨大的本质原因就是写法2通过Case When的经典写法,将这些查询进行了合并,减少了表访问次数,自然就大幅度提升了性能!
2、Rownum分页改写
写法1:
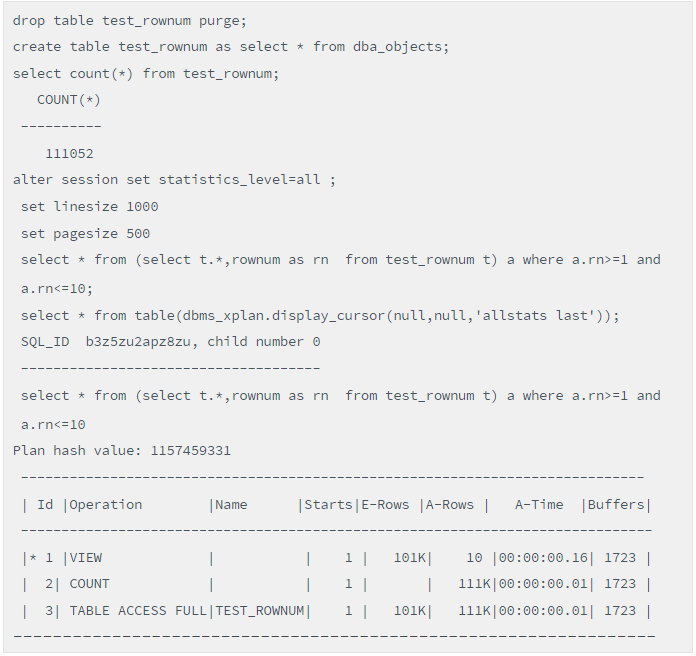
脚本(Rownum分页的普通写法)
写法2:
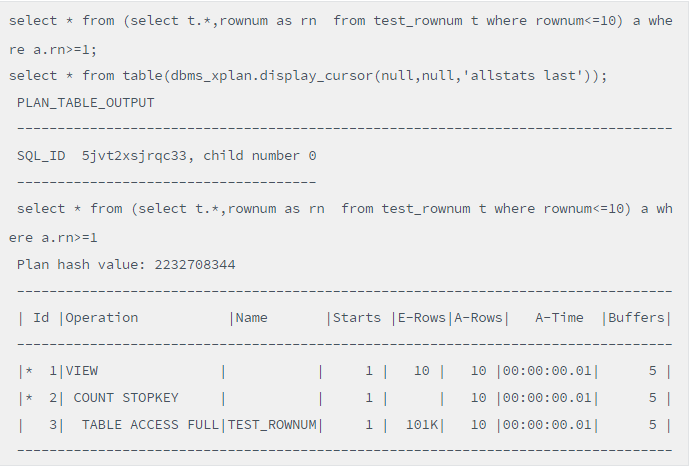
脚本(Rownum分页的高效写法)
写法1的Buffers是1723,而写法2是5,为啥会有如此巨大的差异!认真看执行计划就能明白其中的原委。写法1的执行计划ID=2处的Operation对应的关键字是COUNT,而写法1的执行计划ID=2处的Operation对应的关键字是COUNT STOPKEY。写法2对应的A-ROWS是10,这意味着该SQL仅扫描10条记录,显然是局部扫描。而写法1是111K,这意味着全表每条记录都扫描了。
3、Hint直接路径改造
构造环境:
脚本(Hint直接路径改造的环境构造 )
比较两表插入的速度:
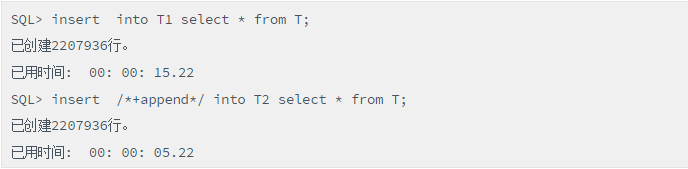
脚本(普通插入与直接路径写的性能差异)
插入T1表和T2表的速度差异如此之大,说明绕过SGA的直接路径访问性能提升非常明显,值得在特定的场合下使用。
4、只取你所需的列
(1)只取所需列,访问视图变快
环境准备,建一个视图v_t1_join_t2:
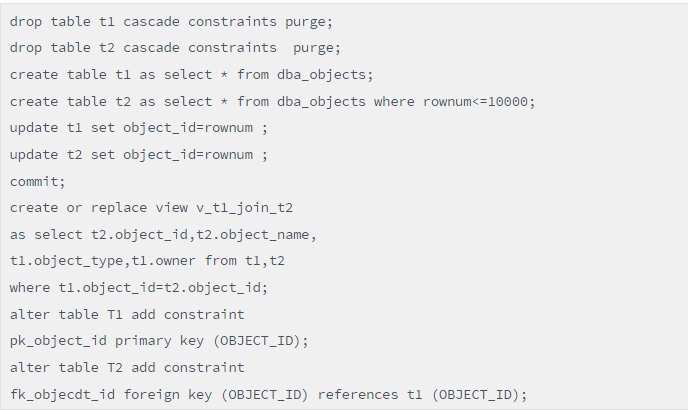
执行select * from v_t1_join_t2语句,必须要访问T2和T1表,如下:
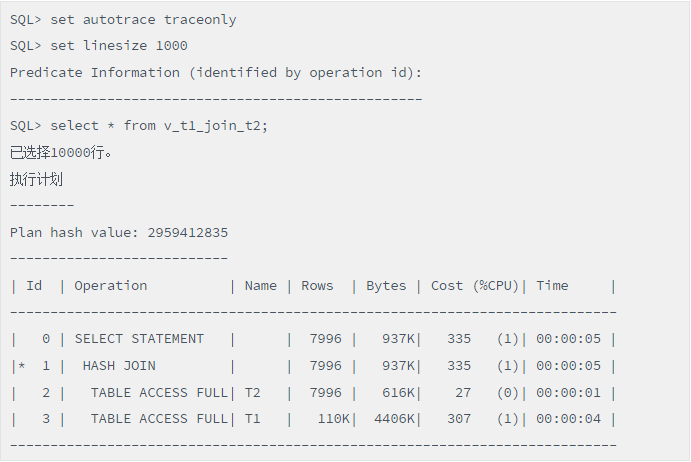
但是有时会出现这样的情况:开发人员实际只需要取object_id、object_name两个列,但是他们为了简单,直接使用select * from先把所有列取回本地,再过滤object_id、object_name这两列,这时其实select * from v_t1_join_t2语句是等同于select object_id,object_name from v_t1_join_t2的。那我们看看这个语句执行后是啥情况,如下:
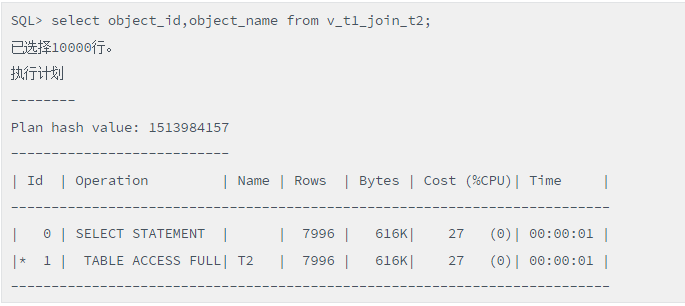
脚本(普通访问视图的写法 )
我们惊奇地发现,这个语句只访问了T2表。这是为啥呢?因为object_id、object_name这两个列全部来自T2表,而且这个视图中的T1和T2表有主外键关联,确保了只取T2表记录且不会取错。这样Oracle既保障了高效又确保了记录的准确。
(2)只取所需列,索引无须回表
场景1,一个普通的利用索引查询的SQL语句,如下:
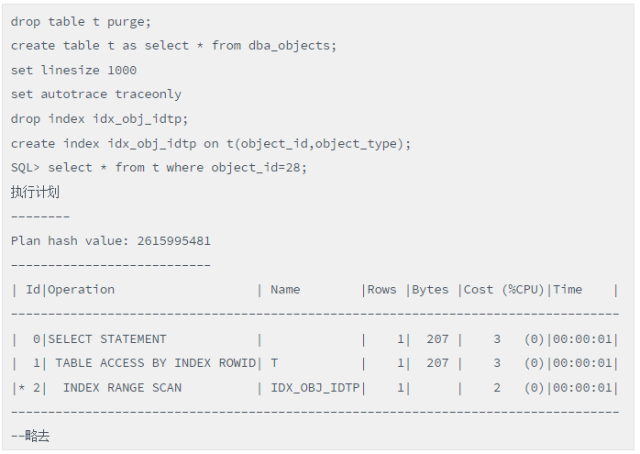
该语句通过IDX_OBJ_ID定位到了rowid,然后通过TABLE ACCESS BY INDEX ROWID回到表中,获取到了object_id列为*的信息,然后将结果展现。不过假如这里的情况和上述的情况类似,开发人员只是通过select * 把所有列都取回来,再取object_id、object_type两列,实际和select object_id,object_type from t where object_id=28等价。但是这么写性能可不一样了,由于object_type列的信息在索引中已经有了,所以就无须回表了。如下:
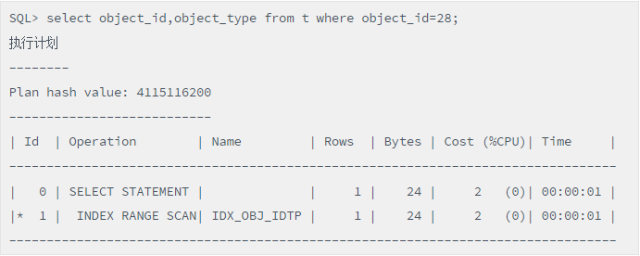
脚本(只取部分列后,访问视图有变化)
(3)避免或者减少递归调用
避免或者减少函数调用,这一个是非常重要的优化要点,也是一个非常常用的优化手段,现实中类似的案例场景也非常常见。一般来说,能避免函数调用就选择避免,一般是将函数调用改写成表连接的模式。但是有的时候函数调用不可避免,比如一些非常复杂的逻辑封装在函数中,一般人员实现起来比较困难,且使用面又广,那就只有使用函数调用。不过遇到这个场景,我们依然可以优化,那就是通过写法的优化,将函数调用的次数降低。
首先我们看看函数调用避免的手法和对应案例。
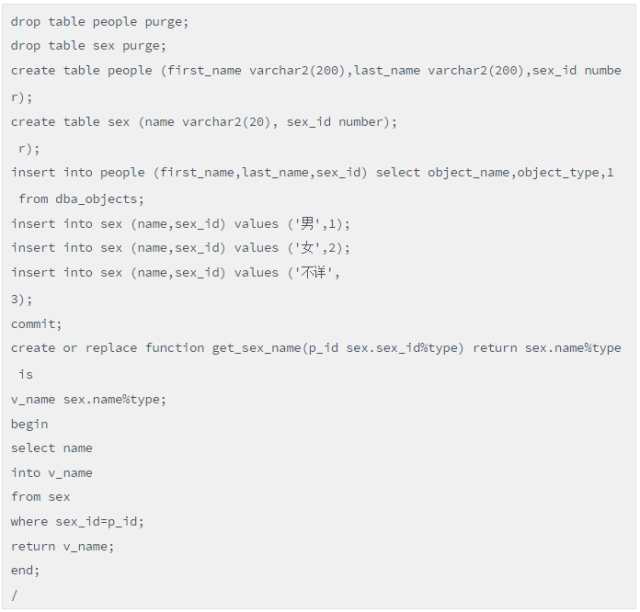
脚本(函数调用性能研究的环境准备)
以下两种写法是等价的,都是为了查询people表信息,同时通过sex表,获取人员的性别信息。
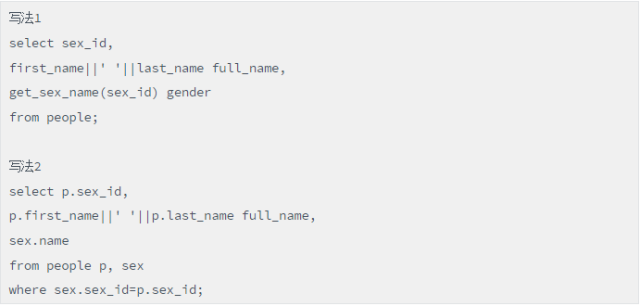
脚本(函数调用和两表关联两个等价写法)
通过autotrace比较观察,发现两种写法在性能上存在巨大差异,首先跟踪写法1:
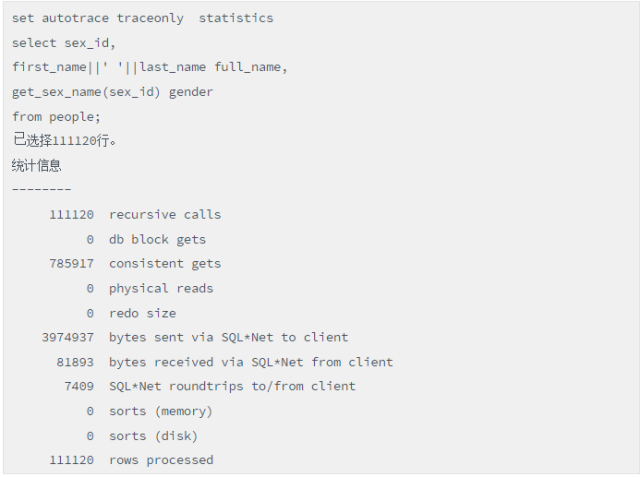
脚本(函数调用写法的性能)
接下来跟踪写法2:
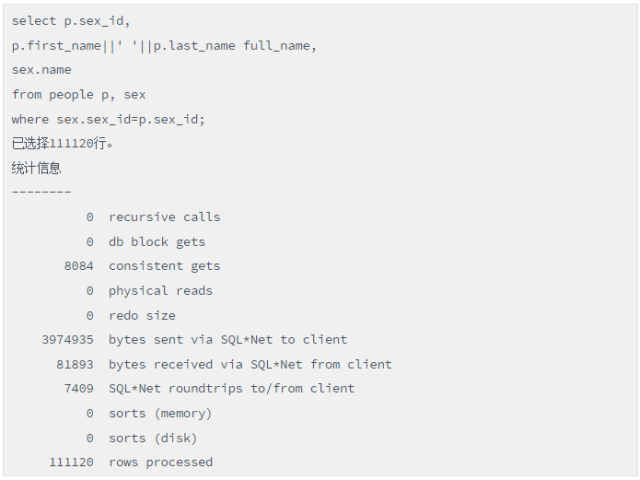
脚本(两表关联写法的性能)
结论:这里的性能差异非常明显,究其本质原因,就是写法1进行了过多的函数调用。
前面说过了,很多时候函数调用不可避免的时候只有想办法降低函数调用次数。而降低函数调用次数有两个主要思路:
尽量将函数写在聚合汇集结果集后而不是写在之前,显然聚合后调用会降低调用次数。
当函数在取值条件的位置时,可以考虑函数索引来减少递归调用。
函数写法的位置
首先我们研究第一种场景,构造两个函数f_deal1和f_deal2。这两个函数其实是一模一样的,构造这个仅仅是为了说明函数索引可以减少递归调用,具体试验如下:

脚本(构造环境,建函数)
我们观察如下两个等价语句的性能差异,首先看写法1:
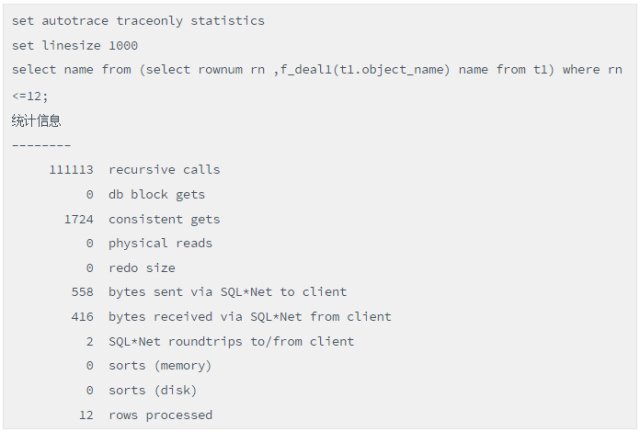
脚本(函数调用在汇集结果集之前)
接下来看写法2:
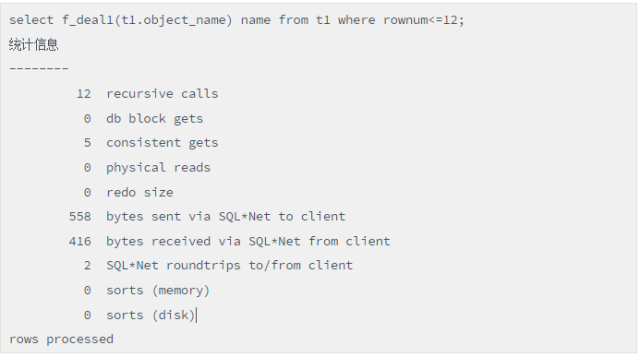
脚本(函数调用在汇集结果集之后)
用函数索引优化
当函数在where 条件下调用,且在没有建函数索引时,结果如下:
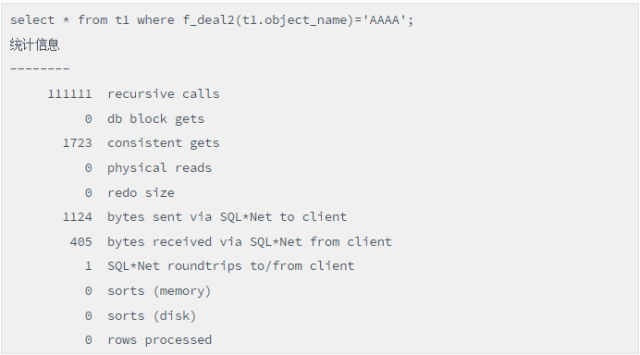
脚本(未建函数索引的函数调用)
当函数在where 条件下调用,且建了函数索引,结果如下:
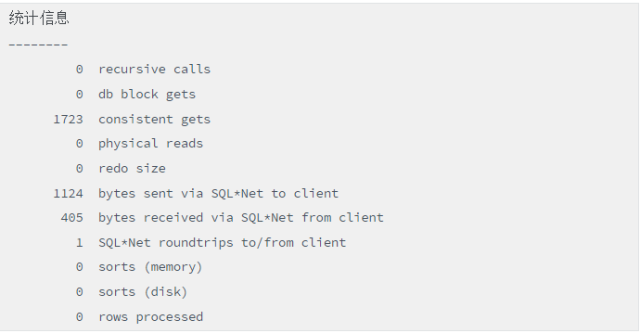
脚本(建函数索引的函数调用)
当没有建函数索引时产生111111次递归调用,而建了后递归调用为0,性能得到大幅度提升。
(4)避免使用触发器
建表触发器:
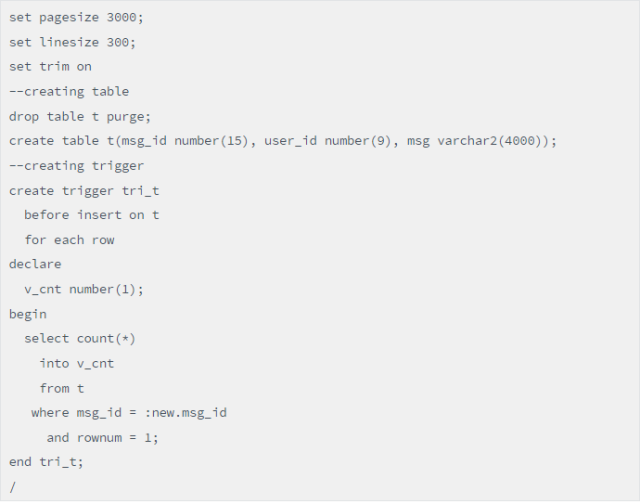
脚本(建表触发器)
写法1,T表有触发器时,插入耗时46s:
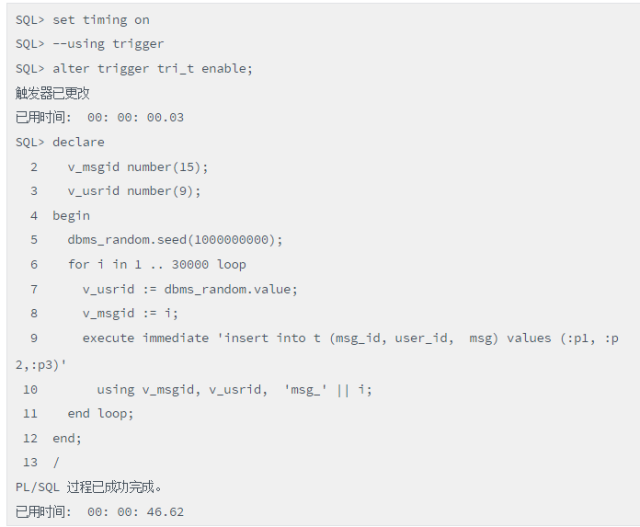
脚本(触发器生效时的插入性能)
写法2,触发器失效的情况,插入耗时仅1s多:
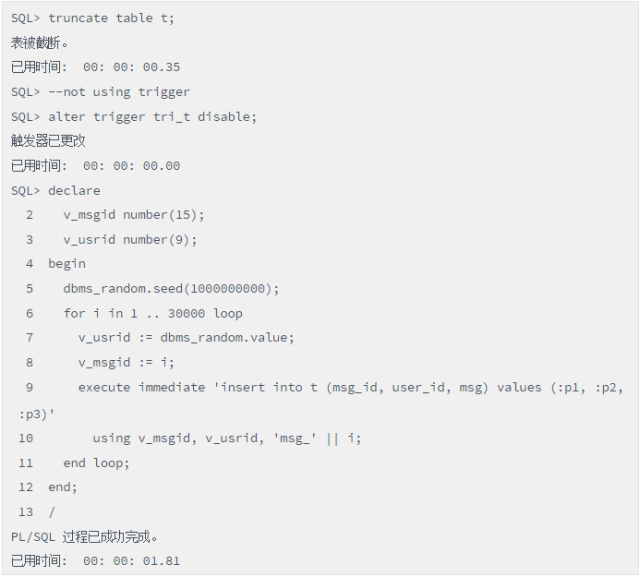
脚本(触发器失效时的插入性能)
性能为何差异如此之大,很明显就在于:写法1每插入T1表一条记录,就调用触发器完成一次统计查询,从而产生了大量的递归调用;而写法2则是消除了触发器。这是现实中的一个案例,后续和开发人员确认该统计可以去掉,去掉后性能得以大幅度提升。
类似地,如果触发器调用的是更新语句,那么可以将其修改成程序批量完成,而非每条触发,性能也能大幅度提升。
(5)rowid优化应用
rowid是一个伪列,既是一个非用户定义的列,而又实际存储于数据库之中。每一个表都有一个rowid列,一个rowid值用于唯一确定数据库表中的一条记录。因此通过rowid方式来访问数据也是Oracle数据库访问数据的实现方式之一。由于Oracle rowid能够直接定位一条记录,因此使用rowid方式来访问数据,访问数据的效率非常高!
环境准备:

首先我们来看看最普通的访问方式,全表扫描访问:

脚本(全表扫描)
接下来我们来看看索引扫描方式:
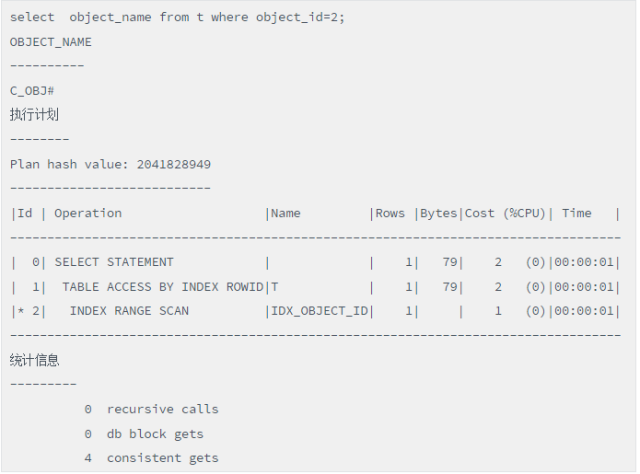
脚本(索引扫描)
最后看看rowid扫描方式:
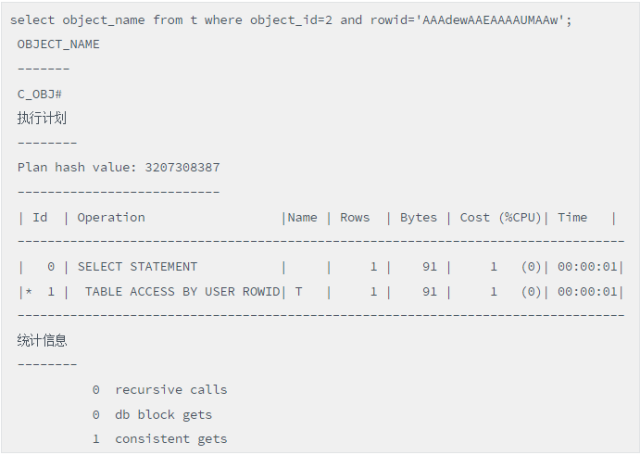
脚本1(rowid扫描)
全表扫描 consistent gets为1724,索引访问 consistent gets为4,而rowid访问的consistent gets为1,三者的性能差别巨大。TABLE ACCESS BY USER ROWID确实是最高效的访问方式,性能最高!
这里要特别注意使用rowid访问的应用场景。举个例子,我们通过索引找到了某条记录,然后要进行更新,如果不用rowid一般是update tab set …where索引条件,如果刚才在查询的过程中顺带获取到rowid,语句则改变成update tab set …where索引条件和rowid=xxx条件,有了这个rowid=xxx条件,更新性能将进一步提升。
不过值得一提的是,一般情况下rowid是不会变化的。当然,如果做了alter table move的动作,rowid显然就改变了。此外分区表的分区条件内的数据发生了分区转移(比如以地区为分区,厦门的数据转移到厦门来),rowid也会产生变化。
二、设法避免外因影响
1、Hint改写确保执行计划正确
我们在前面的章节中描述过关于Hint改写的内容,主要从Hint、固定Outline、重新收集统计信息三个方面来左右执行计划,从而让不正确的执行计划变得正确。这里的Hint部分也算是对SQL进行特定的等价改写。具体的写法不再累述,略去。
2、避免子查询的错误执行计划
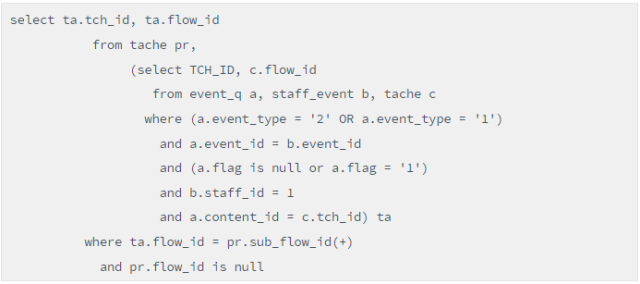
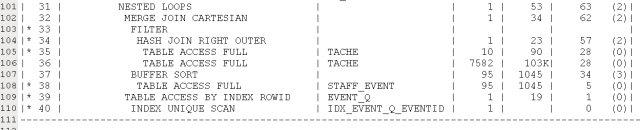
原因看出来了,因为结果集ta里的tache表和外围的tache表先关联,但是之间却没有关联条件,从而导致出现了笛卡尔乘积,所以性能大幅度下降。
因此我们要避免结果集ta的tache表和外围的tache表先关联,就是说让结果集ta内部的三个表先完成关联,再往外关联。那如何实现呢?
改写如下:

原理:为保证Rownum值的准确性,保证该子查询不会移到外面去拿部分表和tache表先关联。
三、所在环境的资源不足等问题
这个问题主要表现为三种可能:
主要是体现在机器的配置比较低,内存CPU及IO的资源不够;
外部某应用程序耗尽了主机的资源,导致主机资源不足;
内部程序大量使用并行操作,资源争用导致所在的环境资源不足。
Q1:Oracle行转列,使用传统的case when还是pivot函数? 哪个性能更好?
A1:关键是执行计划,写法的差异也是体现在执行计划上。不过一般来说特点函数语法的SQL内部有过优化,会减少一些访问路径,会更快一些。
Q2:DBlink语句应该怎么优化了?
A2:这个没有什么特别的,差别就是网络的性能。
(接上问)
Q3:您说的通过索引:,在把rowid 值取到是最快的,可否有具体的例子呢。
A3:有,刚才我举的就是这个例子,回头可以看脚本。试验一把。
Q4:那个笛卡尔乘积还没消除呢。
A4:新的写法已经消除了,加rownum后。
Q5:SQL优化的过程中,遇到的问题大部分是全表扫描加索引,或者更改SQL的连接方式。有的时候会加Hint,也会采用固定执行计划的方式,想问一下,加Hint和固定执行计划的区别在哪儿?固定执行计划的脚本有一部分内容看不太懂,老师有相应的资料参考吗?
A5:其实无论加Hint还是固定执行计划,都是比较危险的操作,因为随着表记录的变化,统计信息在变化,表和索引的访问方式会随着变化,固定了就容易出现执行计划不对。两种的差别在哪里,其实本质没啥差别。大纲比较隐式样一点。
Q6:梁老师,为什么有的时候会产生2个执行计划呢?
A6:比如WHERE ID=:X 其中=1 返回1条,=8返回10万条。前者走索引,后者走全表扫描,就是2个执行计划了。
Q7:我们事先又不知道rowid,怎么用rowid取数?
A7:1. 如果你是2次操作,第一次查询,第2次更新。查询后需要肉眼来判断是否是需要改的,再改的时候,如果能用顺便获取到的ROWID来定位,就快了。2.对入库的数据进行更新的时候。
Q8:我在日常的优化SQL过程中,也就是通过CPU的消耗排序或者是跑一些报告的方式看TOPSQL,然后对其进行优化,老师一般对数据库优化的话采用的是那种方式,或者有一些可供参考的脚本吗?
A8:先整体,后局部。先确保整体数据库没问题,再解决局部SQL的优化。
Q9:加hint和固定执行计划的使用区别我感觉主要是能不能改写SQL?
A9:好吧,算对:)点个赞。
Q10:梁老师,12c的优化有没有什么新的地方需要注意?
A10:12c的执行计划更加智能,对开发人员来说写SQL会更轻松一些。
Q11:针对select * from 表名 这样的SQL语句怎么优化呢?
A11:你是说没条件的语句吗,这个确实很难优化。返回所有的记录?那就是压缩表,加大并行这类的方式,因为无法减少访问路径。
Q12:梁老师,实际调优过程中,对于那些性能过差,需很多个小时才能跑完的语句,有没有必要配合10053事件查看?
A12:一般都不需要用10053,复杂SQL语句的优化一般都在业务层面得到解决。
Q13:梁老师,in 在执行计划中一般都转化成or了,那in和or的效率差不多嘛,写法上要区别吗?
A13:如果我们去考虑这个东西,哪有什么时间去深入研究业务,这种东西就是交给ORACLE自己内部去优化,最终成为相同的执行计划,你们的担忧是因为早先版本的问题导致的。
Q14:使用rowid更新,有一定的风险吧?如果我查过这条SQL后,进行在原来的值上进行update,在我更新之前另一个session更新了,那数据是不是就不能保证一致性了?是不是要先进行for update?
A14:是有这个问题,我刚才说的这个情况,也是特定的场景,说得非常好!
Q15:资源不足还加大并行?并行本来就是消耗资源?
A15:如果机器的资源不足,那并行肯定有问题。如果是程序的处理能力不足,机器资源充足,用并行就没问题。当然也要注意争用的情况。
Q16:DBlink 远程一个大表的数据,distinct 比较慢怎么优化?
A16:这个主要还是远程的问题。如果本地没问题,网络就是主要因素,在数据没有要求很一致的时候,可以考虑同步。另外DISTINCT语句本身也比较耗性能。
Q17:经常会听到这样的问题:怎么进行SQL优化?或者写出最优SQL? 梁老师认为哪几点最重要?
A17:首先要知道优化空间,如果优化空间不大,就没必要优化。我们一般可以分析出来的。 然后就是要明白语句的执行计划,这很关键。最后就是好的SQL往往和业务的了解清晰有关系,业务需求理解很重要。最后不得不提高级SQL,Oracle的一些特定语法的SQL可以有效的进行内部的优化
Q18:除了distinct 还有什么比较好的去重方式?
A18:看具体的SQL需求是什么,MINUS UNION 等等在特定场合下也是有好DISTINCT等价的地方。
1、如需回听直播,请戳:
http://m.qlchat.com/topic/270000367017849.htm?isGuide=Y
密码:888
2、在DBAplus社群订阅号回复“收获”或登录云盘:https://pan.baidu.com/s/1o84YoyA,即可抢先试读梁敬彬老师新书《收获,不止SQL优化》!









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721