
一、结合业务需求拆解架构图
先把上一章已经讲过的架构图再贴一次:
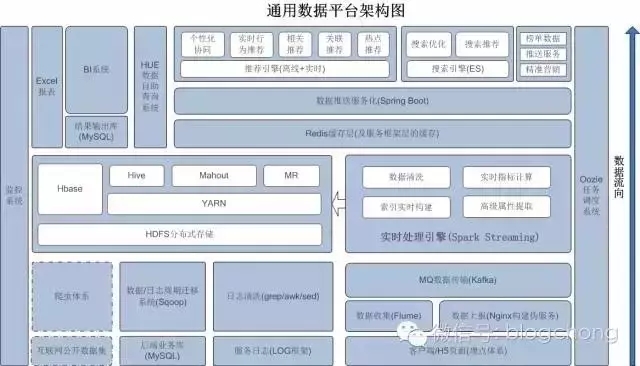
从架构图中可以看出,在我们整个数据架构中,需要做的事情很多。随着数据的流向,从下到上,主要分三层:
第一层是数据收集层,负责基础数据的收集工作;
第二层是数据存储与处理层,负责数据存储、对数据进行深度处理、转换及价值的挖掘等;
最上层是应用层,基于下面的数据处理,进行价值转换;还有贯穿整个过程的监控以及任务调度相关的工作。
第一层中,主要有四个数据来源:用户行为埋点上报数据、服务日志的数据、后端的业务数据、互联网的公开数据。
第二层中,我们主要的核心框架是Hadoop的核心生态,基于HDFS的存储(本质上hive的存储也是基于HDFS),以及基于Spark部分实时处理的需求场景,主要是平台级的架构。当然,至于说具体的处理以及数据的加工、挖掘详细数据业务,后续其它章节再详述。
第三层中,我们直接面向的是业务方。一方面是数据生态中最基础最常见的的数据智能商业化分析,我们以excel封装成邮件日报周报的形式提供。另一方面是平台化的BI系统,以及高度自助性的数据自助查询系统。
在深度挖掘方面,推荐是一个大方向,基于数据的当代搜索也是数据生态的重要组成部分,同时还有业务画像、用户画像(绝对核心价值所在)等。除了以上这些,还有一些基于数据的推送服务、榜单数据、精准营销系统等,都是数据进一步有效应用,以及数据化价值的直接体现。
收回话题,在时间、人力有限,并且基础是0的前提下,事情解决的顺序就显得尤为重要了。
想要使用数据,前提是有数据。所以,我们第一个需要解决的问题是数据源,核心的驱动价值因素是我们的业务需求。
我们第一个业务需求就是从数据上洞察产品的运营效果,电商的各种数据运营需求,指导内容数据化运营、电商数据化运营以及通过数据改进产品。
跟业务强相关的基础数据是产品的业务数据库,这个是现成的,只要打通数据流通即可。与用户行为强相关的则是最直接的用户行为埋点上报数据,以及用户使用服务,在应用服务中留下的访问LOG。
基于服务日志LOG解析数据,一方面如果需要从服务LOG中清洗出有用数据,前提是服务中已经有意识的进行相关信息的LOG落地,这一点,很遗憾,当时并没有这个前瞻性。其次,从服务LOG中清洗数据的代价略高,且信息量有限。所以,在这个阶段中,我们并没有打算直接从服务LOG中清洗数据,因为在服务LOG中埋入数据收集点位,也是一个巨大的改造工程,但效果并不一定好。
我们将最快限度地打通业务数据库与数据中心的通道,然后以最快速度的对业务方提供可参考性的数据化日报。打通行为数据到数据应用的链路,结合用户行为数据,进一步优化数据化运营体系,以及为产品优化迭代提供数据支撑。构造最基础的数据中心平台,打通数据收集到数据分析应用的链路,为业务方、决策层提供数据化运营决策方案,为产品迭代提供最真实的数据反馈支撑。
这是我们数据部门第一个战略目标,像深度挖掘、推荐系统这些在这时通通不要想太多,饭需要一口一口的吃!
当有一个大目标时,我们需要把目标进行拆分,进一步拆分为阶段可实施、成果可见的阶段性目标,在这里同样适用。
并且,记住,你的老板是不懂技术的,他才不会管你的平台又建设到什么程度,集群又搭建了多少台,他只会问,这都一两个月了,你们数据怎么还没有给公司带来价值啊?!(哈哈,有点黑BOSS的感觉了)
不过这肯定是现实,不同位置上的人关注的核心重点不一样。可能你需要关注整体的进度,而业务层只关心你的产出给他带来什么帮助。是的,拆解大目标有利于我们快速入手启动项目;成果阶段化,更具有鼓励性,成就感;最后就是阶段性目标的实现情况更容易量化你的效率。
从人力的需求评估角度上说,也是有道理的,只有随着你的体系一步一步完善,你才知道哪个环节真正的缺人,缺什么人,这点很关键。不过最本质的问题,还是投入与产出比。
我们在做任何一件事情的时候,都需要注意投入与产出的比例,在一定的时间段内、投入一定的精力、产出一定比例的成果。有这种价值观,处理事务才更有效率!
二、如何做机器需求的评估
想要打通数据收集到数据分析业务的输出链路,那么你需要一个数据平台进行支撑,甚至后续你将持续开挖的数据核心价值,这些都是基于平台做的。
所以我们需要一个数据平台,而说到平台,则机器资源是绕不过去的一个问题。那么,如何去评估你的集群需要多少台机器呢?每个机器又是以一个什么样的角色存在的呢?
在评估之前,你首先应清楚了解到平台上需要承载的业务,包括内部的处理业务以及对外暴露的数据业务。其次,你需要考虑后续的可扩展性,即后续数据量上涨的情况下,机器的横向扩展当然是没有问题的,但部分角色机器的资源需求是在纵向。
举个简单例子,Hadoop的datanode可以在横向上进行扩展,但是Namenode的资源需求则无法做到。
至于说如何进行机器资源评估,在了解自身业务需求的前提下,这里所说的业务需求,不单纯是业务范围,也意味着业务范围承载的数据量是什么情况。在了解自身数据量的情况下,多查找其他公司的案例,与其他同行多交流沟通,借鉴其它公司的数据量与集群规模,来评估自身所需要的机器资源。需要注意一点的是,对于电商行业,经常会出现节日性、活动性质的流量暴涨。
所以,你的机器资源一定是需要考虑这些实际场景负载的或对于这种场景,若你有其它的方案进行处理也OK。
三、使用Nginx做数据上报伪服务
上面说到第二个重点,那就是用户行为数据的上报。
了解数据上报以及埋点相关逻辑的朋友应该清楚,其实所谓的SDK,其本质也是一个接受数据上报的服务。直接往上报服务中丢数据,跟封装成工具SDK,本质的意义是一样的,我们需要提供一个对外的数据上报服务。上报什么数据,数据以什么格式上报,这个在下一章的“数据上报体系”部分详细阐述,这里只是对上报服务这块进行讲解。
那这意味着,我们需要为客户端或者H5的童鞋提供一个统一的上报服务接口,让他们在用户特定行为操作的时候。比如浏览了某个页面,操作了某个按钮等之类的操作,进行这种信息的收集统一上报。说白了,封装用户的行为数据,在适当时候调我们的接口,把用户的行为数据给我传过来。
那这看似就是一个后台服务,用于处理上报过来的数据。但是请注意,不管你是一个服务也好,伪服务也好,一般情况下绝不会直接把获取到的数据直接落地的,这是传统的思维路子。
要知道上报的业务流量是很大的,特别是你的点位足够丰满的情况下,在流量高峰期,你要是敢直接进行数据落地,它就敢直接把你的服务给搞死。一所以一般情况下,我们都会把数据丢给缓存,以解耦上报与落地两端的压力。
既然如此,在人力资源有限、项目时间有限的前提下,为何要花这么大的精力去维护一个服务呢?于是,有了伪服务设想。
我们直接使用Nginx对外伪装成一个Web服务,提供Restful API,但我们不对上报的内容做任何处理,直接落地成Nginx的日志,再通过Flume对日志进行监控,丢到Kafka中。这样我们就迅速地搭建起一个上报“服务”,提供给客户端童鞋以及H5的童鞋,制定好数据上报的规范,然后就可以坐等数据过来了。
关于数据的合理性校验、规范性校验、有效性校验、以及进一步的解析,我们都放到Spark Streaming这一层去做。其实当时也是调研过lua的,在Nginx这一层也是可以做到数据完整性以及有效性校验的,但为了不至于给Nginx端带来过大的负荷,我们把复杂的逻辑处理放到后端。
基于这种伪服务的设计,还有一个好处就是,即使后端链路出现故障,但我的原始数据是落到LOG中的,只要我进行数据的回溯,再通过LOG清洗出异常的部分就行了。这也是我们后续实时数据容错的核心依据所在,所以,重点推荐。
四、用Spark Streaming做实时数据清洗
紧接上面的上报,我们在后端一层使用Spark Streaming做数据校验、进一步清洗的。
如果业务对于实时性要求不高,我们完全是不必要做数据的实时链路,只需要周期性地把Nginx中的上报日志进行批量清洗入库即可。但是,一方面基于部分对实时性稍高(其实也不高,分钟级别),例如电商活动期间对数据的实时监控;另一方面来说,实时性的数据上报链路是最终的目标,为了业务的时效性,迟早是需要做的。
由于我们需要在后端的处理环节中,对数据的有效性、规范性做校验,并且做进一步的属性解析,例如通过IP解析地理位置之类的,因此承载的业务逻辑还是蛮复杂的。
所以,我们打算引入一个实时处理框架来做这件事。关于实时框架这块,我想,熟悉的朋友都会想到两个:Storm与Spark Streaming。在这里跟大家分享我之前翻译过的一篇文章《Storm与Spark Streaming的对比》。(英文原文:http://xinhstechblog.blogspot.com/2014/06/storm-vs-spark-streaming-side-by-side.html)
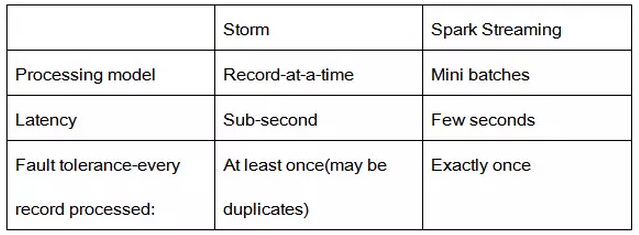
虽然这两种框架都提供了系统的可扩展性和可容错性,但是它们的数据处理模型从根本上说是不一样的,处理模型则决定了它们的实时性。
Storm可以实现真正流式实时的处理数据,例如每次处理一条消息,这样延迟就可以控制在秒级以下,实时性很高。而Spark Streaming的本质还是批量处理,只是这个批量是微批量,在短的时间窗口内进行数据实时处理,通常延迟在秒级左右,实时性相对较弱。
在数据容错能力方面,SparkStreaming做的比Storm好一些,它的容错是通过状态记录去实现的。(译者注:熟悉spark的童鞋都知道,spark会将所有的处理过程状态都以log的形式记录下来,即血统,出现错误的时候,可以根据血统进行数据的恢复)
而Storm则不一样,Storm对每一条数据进行处理标记,从而进行跟踪数据的处理情况,它只能保证每条数据被处理一次,但实际情况是,在发生错误时,这条数据是被处理多次的。
这意味着,更新多次时可能会导致数据不正确。
而Spark的批处理特点,能够保证每个批处理的所有数据只处理一次,保证数据不会在恢复的时候错乱(批处理重新执行)。
Storm提供的Trident库虽然能够保证在数据容错时只被处理一次,但它很大程度上依赖于事务的状态更新,并且这个过程相对较慢,更甚者,这个过程是需要用户自己去实现。(译者注:Spark的数据安全性是毋庸置疑的,虽然当年Storm能够从多个开源实时处理框架中脱颖而出,ack/faild机制的功劳巨大,但是跟Spark比,数据容错能力还是差了一筹)
所以,如果你的业务场景对实时性要求比较高,同样对数据容错也有所要求,那么Storm将是一个很好的选择。当然,如果你希望对每次实时处理的过程进行掌控,那么Spark Streaming提供的状态记录会清楚地描述出数据处理的过程,并且数据的容错能力也很不错。
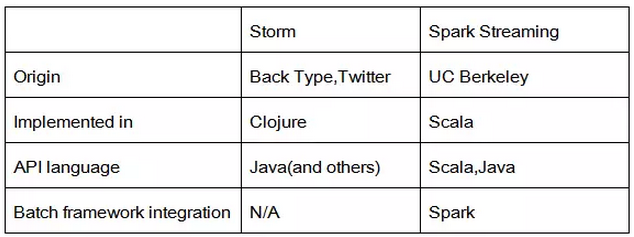
假如你想深入源码中研究,你需要清楚的是:Storm是由Clojure编写的,而Spark Streaming则是Scala。
Storm是由BackType和Twitter开发的,而Spark Streaming则是由UC Berkeley开发的。
在语言支持上,Storm提供了Java API,同时也支持多语言。(译者注:在多语言的支持上,虽然支持,但是通常除了Clojure、Java、Python等几种语言,其它语言进行开发还是很困难的,最常用应该是Java)Spark Streaming支持Scala、Java、Python等几种语言。
(译者注:这点是针对于Spark Streaming来说的)
Spark Streaming一个很大的优势就是,它是基于Spark框架上做的,这样的话,熟悉Spark操作的人就能很轻松的像进行其它批处理操作一样,进行操作Spark Streaming。这意味着你不用进行额外的编写处理代码,更为便捷。
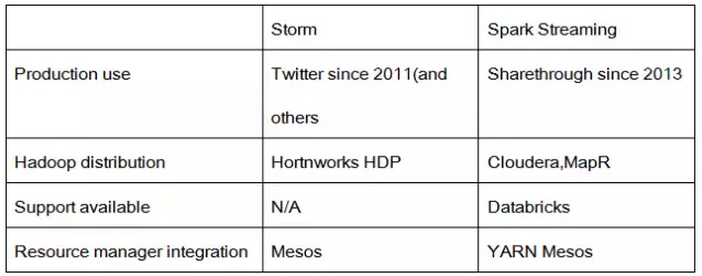
Storm开源得比较早,自2011年起,推特就在使用Storm了,其后更多的公司使用它。而Spark Streaming是一个比较新的项目,在2013年的时候,仅仅被Sharethrough使用(据作者了解)。
Storm是Hortonworks Hadoop数据平台中的数据流式处理的解决方案,而Spark Streaming出现在MapR的分布式平台和Cloudera的企业数据平台中。
此外,Databricks公司还专门为Spark提供技术支持,当然,其中也包括了Spark Streaming。
最后在依赖框架来说,Storm可以在Mesos上运行, 而Spark Streaming可以在YARN和Mesos上运行。
Storm比Spark Streaming更有实际应用的优势,但Spark有专门的公司维护它并且提供技术支持,包括它与Yarn的结合等。
其实Storm在处理领域上还是有一定的差异的,Storm比较擅长实时性较高的数据处理,而Spark Streaming则偏向于内存处理(注意严格来说内存处理跟流式处理并不是完全一样的)。
在数据安全性方面,不作过多的评论,数据安全Storm虽然没有Spark streaming强大,但从目前来看已经够用了,要知道很多业务数据在这种场合下是允许丢失部分数据的。
关键点在于资源的管理,虽然最近发布的Storm 0.10.0-beta号称在资源管理上已经做了不小的优化,但在个人看来还远远不够。Spark Streaming依赖于Spark的环境,而Spark在Hadoop2.0时代以后,资源管理方面得到了巨大的提升,这侧面的衍生了大量类似Yarn的组件。
虽然Storm也可以运行在Yarn上,但目前并没有一个很稳定可用于生产环境的开源版本。所以,在资源管理方面storm还有很长的一段路要走。
在两者的选择上,从当前实际应用看,Storm已经越来越多的生产实例了,而Spark Streaming更多还处于预研或者试用阶段。
相对来说,在流式处理上,Storm有着不可比拟的优势,而在大批量内存处理的方面,则是Spark Streaming占着不小的优势。
所以具体使用方面,一般情况下Storm足够了,而Spark Streaming的话,慎用,毕竟任何开源的稳定性以及其价值,都是需要时间来检验的。
总之,Storm与Spark Streaming最本质的区分在于,Storm是真正实时处理,而Spark Streaming的处理本质则是微批处理。所以Storm能够将实时业务达到毫秒级,而Spark Streaming虽然也能达到亚秒级,但对于效率的影响会比较大,所以一般会用于秒级的数据处理。
目前就我们自身的业务需求来说,对于实时性并没有高到毫秒级的要求。
并且,为了维护系统平台的统一性(统一的平台架构,统一的YARN资源管理,同一个垂直生态),我们选择使用Spark Streaming作为我们数据清洗的入口。
使用Spark Streaming需要解决的一个问题就是,输出结果的高度碎片化。
正如上面所说,Spark Streaming其核心依然是Spark的路子,在微小的时间窗内,对微小批量的数据进行处理,达到类似实时的效果。
而其每一个批量处理之后都是以批量结果得以输出,于是,就会产生大量的碎片文件。
其实,解决这个问题也简单,那就是合并!进行周期性的文件合并,这点就不多说了。
既然说到了Spark Streaming,也就顺带着说一说Spark这个生态。
在很早以前,Hadoop、MapReduce经常会被人提到,但是随着Spark的兴起,已经越来越少人愿意使用MapReduce去批量处理数据了。
是的,Spark目前在Hadoop大生态中,已经形成一个比较完整的子生态:
包括与数据查询分析关联的Spark SQL;
实时处理领域的Spark Streaming;
正常内存处理可以替代MapReduce的离线批量;
还有集成大量机器学习包的MLlib;
以及还有什么图形处理的什么鬼(好吧,那个不是我擅长的)。
在效率至上的数据时代,MapReduce说抛弃就被抛弃了(哈哈,其实也没有这么严重,只是越来越多人弃用MapReduce,这肯定是事实)。
在体系支撑上,Spark依然成气候,数据的常规SQL分析,数据的内存处理、实时处理,以及数据的深度挖掘等,全部一起打包,好用的不得了,所以越来越得人心,也是木有办法的事。
关于IP地理位置解析,这里也可以分享一下。
IPIP.NET提供的IP库实在是值得推荐的,没钱的可以使用它提供的免费版,有钱的主可以考虑使用使用付费版。
免费版没有想象中那么不堪,只是它提供的服务没有这么多,更新的频次少点而已,大部分能解析到市一级,至于省份这一级,那是妥妥的没问题。
五、结语
本章主要阐述如何从局部入手,拆解架构图,进行阶段性的任务执行。其中,详细讲解了部分核心重点,包括架构图的拆解、机器资源的评估、Nginx的上报伪服务、以及基于Spark Streaming的数据清洗等。
但是个人认为,方法论远比现成的方案有用,授人以鱼不如授人以渔!更重要的是中间阐述一些问题的思考方式、价值观,诸如拆解整体规划的思考、扩展预留的思考、方案选择的对比衡量等。希望本文能对你有所启发。
作者介绍 黄崇远
本文转自数据虫巢(ID:blogchong)订阅号,经作者同意授权转载。
社群开启有奖征文,如有以下方面的原创文章欢迎投稿,被采纳并评定为优秀好文就有机会获得奖励。投稿邮箱:editor@dbaplus.cn
· 数据资产管理实践
· 运维对开发管控的具体手段实践案例
· 自动化运维实践
· 运维大数据分析实践
· 金融大数据应用实践
· Oracle Database on Docker深度测试
· Oracle 12cR2新特性深度测试或真实环境应用
· 技术管理的软技能
· 职场心得









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒