
译者:新炬网络浙江大数据团队
作者:Adit Deshpande,UCLA
原文:https://adeshpande3.github.io/adeshpande3.github.io/Applying-Machine-Learning-to-March-Madness
导读:本文为大二学生Adit Deshpande在美国大学生男子篮球锦标赛的开赛前的预测。目前四强已经尘埃落定,虽然Adit放出了机器学习的大招,但是也预测错了(so sad,奖金泡汤)。正如Adit所说,建模是含有偏见的,而我们能做的是在建模的过程中尽量剔除个人因素,选择能够代表全量的数据集。看看Adit的思路,能给我们以后的预测带来哪些启发呢?

3月13日,NCAA“疯狂三月”的68强球队名单正式出炉,这也意味着每年NCAA备受瞩目的“疯狂三月”正式拉开序幕。
“疯狂三月”指美国一年一度的大学生男子篮球锦标赛。比赛由68个大学队组成,采取单场淘汰制。为了赢得总冠军,一支球队必须赢得6连胜。
比赛分为4个区域。每个地区有17支队伍,排名从1到17。这个排名由NCAA委员会根据每个球队的常规赛季表现决定。由17号种子和16号种子先比赛,胜者和一号种子队伍比,2号种子和15号种子比,以此类推。

赛程安排结束后各个球队开始积极紧凑的备战,而球迷就会开始玩Bracket,也就是全国锦标赛的对战表,球迷可以预测每一轮,每一场,某一支比赛的胜负,填写bracket已经成为了球迷不成文的习惯和传统。从数学上讲,可以有
263种结果。
2014年股王巴菲特出资10亿美元奖励bracket完全预测正确的球迷,只可惜,近千万份预测在经过首轮的角逐后有70%都没办法全对,最终准确率最高的也熬不过第三轮。
作为体育迷,预测比赛的结果是我们的天性。三月疯狂的魅力来自这样一个大型的淘汰赛的不可预测性。
预测问题
在运用机器学习之前,让我们来想想体育项目的预测,似乎不是很复杂。例如以下这种情况。
你作为一个预测者,什么样的因素会影响你对比赛结果的判断?
A说:Pats在NFL的统计里有最好的防守,带球进攻码数第四,失误差第三,他们能赢。
B说:100个NFL的ESPN分析师中有72个选择Pats赢,所以我也选他们。
C说: 因为Pats有Tom Brady,而我喜欢他。
D说: 我的前女友喜欢底特律猎鹰队,所以我选Pats。
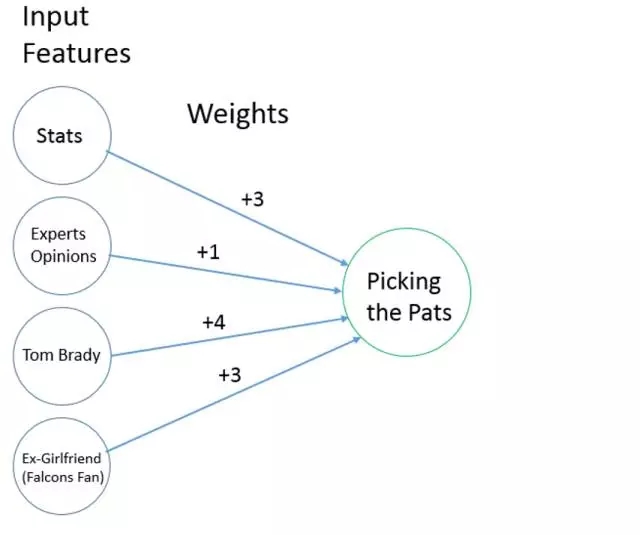
看看这些回答,你会发现每个人基于自己特殊的感情会在选择中把不同的特征安排不同的权重。A依赖于常规赛季的统计数据。B考虑到NFL分析师的意见。C表现出个人对Tom Brady的偏爱,导致他/她选择Pats。D可能从来没有看过比赛之前,选择PATS因为一个特定的人。
我们都有不同的预测方法,在做决定时会考虑不同的因素,所以我们对体育比赛的预测也有不同的方法。这些不同让我们在比赛前会有激烈的争执、可能让我们沉浸在自己幻想的成功中,或者让我们重新思考我们的预测过程。
但我们所有观点中的一个共同点就是我们有偏见。我们每个人都有不同的偏见,因为对于“什么是好的预测”这个问题没有明确的答案。我们应该看统计数据吗?应该注意无形资产吗?我们应该忘记所有这些,仅仅根据个人的感受做出预测吗?没有一个简单的解决方案。
所以,我们需要机器学习。
机器学习能帮助预测吗?
看看我们是否可以建立一个ML模型,能够看训练数据(过去的NCAA篮球比赛),找到一个团队的成功和他们的属性(统计)之间的关系,对未来的比赛输赢做出预测。
首先,我们有大量数据。在过去25年的时间里,有超过100000场NCAA常规赛,我们通常都有很多关于每个赛季球队的统计数据。因为有所有这些数据,我们可以尝试使用机器学习来找出赢得比赛的团队在统计上的特征。如果球队得分少于60分,他们能赢得比赛吗?如果一个球队丢球超过15次,他们会输给一个护球很好的球队吗?这些类型的问题,我们希望数据分析和机器学习可以解答。
(所有的分析数据的代码可以在这找到
https://github.com/adeshpande3/March-Madness-2017/blob/master/March%20Madness%202017.ipynb)
基础模型
我们的ML模型使用了两个团队信息(团队1,团队2)作为输入,然后输出1队赢得比赛的概率。

ML算法通常由奇异矩阵或向量的形式输入。我们需要想办法把两个团队的信息在单个向量中封装。以2016 Kansas Jayhawks为例。

他们在赛季中表现很好,赢得了第十二次冠军,在联赛中是1号种子。我们考虑如何用一个特征来反映他们的赛季。在ML术语中,我们想要采用哪些特征?
让我们从常见的统计开始。
常规赛胜数:29
平均每场得分:80
30平均每场得分:67.61
平均每场3的比赛:9.21
每场平均失误数:14.39
每场平均助攻数:18.30
每场平均篮板数:43.73
平均每场抢断:7.66
然后,我们可以考虑其他因素
“Power 6”(NCAA的联赛)表现(Big 12, Big 10, SEC, ACC, Pac-12, Big East):1 Binary Label
常规赛季总冠军:1 - Binary Label
国际赛冠军:1 - Binary Label
我们再看看更多的度量。
简单评分系统(进度表和平均点差函数):23.87
赛程强度:11.22
一些历史因素。
1985以来比赛出场次数:31
1985以来全国锦标赛数:2
最后,我们用一个三元标签描述位置。
位置(-1代表球队1是客场,中立场为0,1代表球队1是主场):为了反映 2016 Kansas Jayhawks,我们可以将所有因素集成到一个16维的向量。

现在让我们再看看2016赛季的另一个队伍the Oklahoma Sooners。

The Sooners,由NBA第一轮选中的Buddy Hield带领,这个赛季获得25场常规赛的胜利,成为2号种子。我们可以看看他们的向量。

在NLP中使用深度学习方法team vectors和word vectors相似。在通过RNN或LSTM输入之前,我们首先必须将我们的句子或短语转换成可用的表示。
由于ML模型通常采取单一的输入,我们可以把每场比赛设为两组向量之间的差异(Team 1向量,Team 2 向量)。虽然有些人可能会选择连接两个向量,但是取而代之的是有助于强调团队彼此不相似的方式,这有助于确定对匹配结果有影响的统计数据类型。
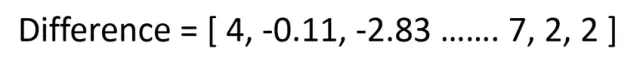
我们的模型将采取这个差异向量,并输出团队1赢得比赛的概率。
我们训练这种模式的方式是看过去的常规赛的结果,并通过观察两个竞争球队的团队向量。让我们看一个实际的训练例子。
Oklahoma和Kansas在2016赛季遇到了两次。第一次在Kansas的Allen Fieldhous,成为了大学生篮球赛所有赛季中最伟大的比赛之一。

1号种子VS 2号种子,三次加时,是的,那场比赛很激烈。这将是我们训练数据中的许多比赛之一。这场特殊的比赛会是什么样子?
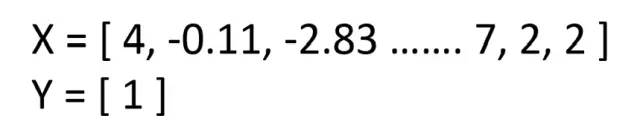
有意义吗?每个训练例子的X特征是两个队伍向量在那个赛季的差异。训练的Y特征是[ 1 ]或[ 0 ],代表球队1赢或球队2赢。
Sports-Reference和Kaggle dataset的常规赛和锦标赛的数据从1993季开始的,从1993到2016,有超过115000场比赛。对于x训练的维度是115113 x 16,y训练的维度是115113 x 1。
ML算法的应用
有训练集后,我们必须选择一个ML算法。从简单的logistic回归到随机森林到复杂集成,有各种各样的模型可以适合我们的任务。当你第一次启动一个数据集和一个预测任务,总是尝试一个非常简单的模型(如线性/ logistic回归或决策树或KNN),然后再尝试更复杂的神经网络和集成方法。将训练数据分成训练集后,我们训练模型(使用scikit学习功能)并评估测试集。
下面,你可以看到一系列我们的模型的表现。为了确保模型不只是幸运与简单的游戏进行分类,我们在随机划分训练集和测试集评估100次模型,并取平均值。
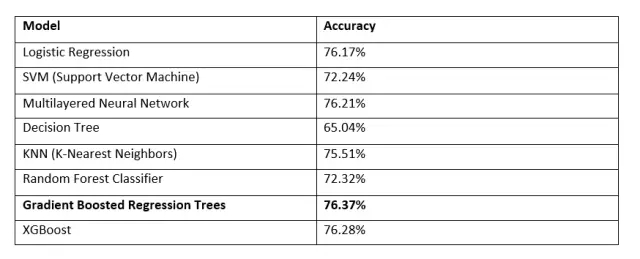
Gradient Boosted Trees
该模型在测试集上获得了最好的性能。该模型基本上是一种集成的网络,当你用multiple shallow regression或classification trees,当前树的建立是基于前面所有树的建立的。Gradient Boosted Trees对于异构数据(不同尺度上的数据)非常好,可以检测非线性特征的相互作用,这在我们的任务中是非常有用的。这种模式的一个有趣的属性是,我们可以分析每个功能的重要性的整体分类。通过查看每个特征在回归树上的位置,我们可以检查哪些特征在预测中的贡献最大。
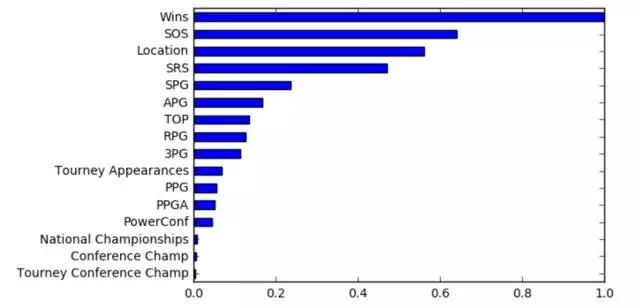
因此正如你所看到的,常规赛季的胜利同球队是否赢得比赛有很大的关系。直观地说,它不需要一个先进的ML模型或一个专家分析,球队有更多的胜利当然更有可能获胜。
然而,有趣的是,看看列表中的后续特性。以下两个特点是SOS(赛程强度)和位置。SOS也会产生直觉的感觉。即使一个团队没有大量的获胜,但他们本身很厉害,只是运气不好碰到了发挥更好的对手,这很有可能的。 比赛场地也是一个众所周知的影响因素,这是“主场优势”。
下一步
76.37%的准确率很高了,但我们能达到80%或85%吗?这是作为一个ML从业者的一个棘手的部分,没有一套明确的指导方针来改善你的模型。对于决策树,可以尝试增加树的深度。对于神经网络,你也可以尝试新的架构或经典的“只需添加另一层”的心态。有无穷多个参数你可以试试。
我将更多地关注数据的表示和模型本身。这里有一些调整,可能会产生更好的结果。
除了依靠共同的统计特征(PPG,APG,等等),可以尝试量化专家的意见,球迷投票,或投注线。
使用SVD或PCA降维和模型学习的简单功能从数据集预测。
考虑比赛结果的历史信息(12号种子种在第一轮季后赛战胜5号种子)。
用不同的方式把两个队的因素整合到一起(如concantenating,平均,等)。
使用RNN模型,关注时间序列数据。而不是把一个赛季作为一个单一的向量,可以尝试建模作为一个时间序列的团队的进展。因此,我们将能够找出哪些球队做得特别好。
关于ML模型中偏差的讨论
我现在想花一点时间来解决一个我认为对所有机器学习者来说非常重要的问题,这是训练集偏见。就像我在文章开头提到的,当我们谈到预测时,我们都是有偏见的。
在体育比赛中,我们对队伍都有自己的偏爱,有时候和统计的结果会有冲突。使用机器学习使我们能够利用大量的数据与预测任务。然而仍然会有偏见的问题影响我们。
偏见影响ML模型的方式是通过我们使用的训练集。作为ML从业者,我们有意识地决定用哪些训练数据使用。对于这个特殊的模型,我决定使用1993年以后所有的常规赛季和比赛的比赛数据。我可以决定只包括最近几年的数据,或者可以在1993之前查找有关的数据集。
在选择特征时也是同样的。我可以添加一些如罚球命中率或主场获胜次数等,但我没有。我创建的特征是因为我认为,这些是与一个队伍的胜利最相关的统计数据。
这种对数据集和特征选择的控制意味着我们对模型输出的责任比我们想象的要多。
虽然体育预测只是一个有趣的任务,有许多领域(医疗保健,法律,保险等)的机器学习模型的结果是非常重要的。我们需要时间来确保我们使用的训练数据是代表整个人口,不歧视某些人,该模型非常适合训练集和测试集的大多数例子。
ML模型对2017比赛预测
对于今年的比赛的预测,我使用Gradient Boosted Classifier model跑了每一轮比赛,并找到较高的概率提前到下一轮的团队。然后我重复了所有后续回合的过程,结果如下:

写在最后
四强大战将在4月2号打响,分别是冈萨加对决“黑马”南卡罗莱纳,北卡遭遇俄勒冈。祝愿明年Adit能改进模型取得胜利!









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒