
导读:通常引起IO升高的因素很多,比如高并发或大字段写入、硬盘老化有坏块、Raid卡电池损坏或充放电、硬件自检等都会引起IO升高。本文主要对硬件自检导致的IO问题排查做简要说明。
现象
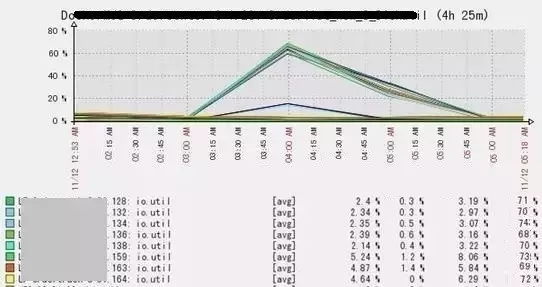
监控报警,IO最大利用率达60%+,应用TP99超时,成功率降低,如下为当时监控图:
遇到此问题的排查方向
第一, 定时任务导致。
先看时间,是否为定时任务导致,比如备份。如果binlog之前生成较多,过期后自动清理也会导致IO升高,可以通过磁盘空间监控查看。
第二,并发较大写磁盘频繁。
一般此问题不会造成IO util 50%以上。如果事物较大或者并发较大,general log或slow log会有记录,我们可以先看下当前线程连接情况,再结合general log或slow log查看是哪些SQL导致。是否需要优化SQL还是控制并发,以及调整数据库刷新频率置成双0模式。
第三,硬件因素导致。
IO util 50%以上,很大几率是硬件问题导致,磁盘是否有坏块。最常见的就是Raid卡电池损坏(充放电),如果电池损坏没有开启写缓存,则会直接写磁盘,IO会升高。我们可以通过如下命令检查,除HP服务器外其他采用MegaCli查看硬件信息,HP采用自带hpssacli命令查看,切记不要使用老命令hpacucli,此命令会导致部分HP型号服务器操作系统直接Hang。
服务器大多是LSI的MegaRAID卡,MegaCli兼容服务器命令
查看磁盘坏块:

查看缓存策略:

此种状态为BBU损坏时不写Raid卡缓存
修改为BBU损坏时写Raid卡缓存:

生成自检及电池充放电日志:

打开物理磁盘缓存:

HP服务器hpssacli命令
HP查看电池状态:
hpssacli ctrl all show status
HP查看缓存策略:
hpssacli ctrl all show detail|grep -i Cache
查看插槽号和逻辑磁盘号:
hpssacli ctrl all show config detail|egrep -i 'Logical Drive:|slot:'
打开物理磁盘缓存:
hpssacli ctrl slot=0 modify drivewritecache=enable
查看阵列号及SSDSmartPath:
hpssacli ctrl all show config detail|egrep -i 'Array:|HP SSD Smart Path'
SSD需要注意:(打开逻辑缓存需要先关闭SSD Smart Path功能)
hpssacli ctrl slot=0 array A modify ssdsmartpath=disable
打开逻辑磁盘缓存:
hpssacli ctrl slot=0 logicaldrive 1 modify caching=enable
在没有电池的情况下开启raid写缓存:
hpssacli ctrl slot=0 modify nobatterywritecache=enable
设置读写百分比:
hpssacli ctrl slot=0 modify cacheratIO=10/90
了解以上服务器命令后,分析三种情况:
无Raid卡电池(损坏)
查看Raid卡电池状态:
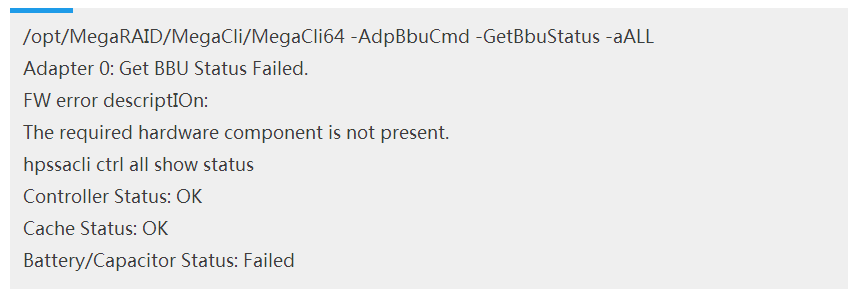
这种情况,如果没有修改默认WriteCache OK if Bad BBU模式或者No-Battery Write Cache: Enabled,在电池损坏时会转换成WT模式。从而导致IO非常高。

修改成WC模式后,IO使用率可以从99.6%降到2%左右,效果十分显著。
但这种情况下存在一个问题:因为没有Raid卡电池保护,即突然断电或者主板故障时会造成数据丢失风险。数据库服务器一般采用双电模式,掉电风险较低,但是主板故障相对较高,所以BBU坏时是否要打开Write Cache,需要根据业务情况综合取舍。
Raid卡电池处于充放电阶段
首先我们先了解BBU充放电原理:
BBU由锂离子电池和电子控制电路组成。锂离子电池的寿命取决于其老化程度,从出厂之后,无论它是否被充电及它的充放电次数多与少,锂离子电池的容量将慢慢的减少。这意味着一个老电池无法像新电池那么持久。也就决定了BBU的相对充电状态(Relative State of Charge)不会等于绝对充电状态(Absolute State of Charge)。
为了记录电池的放电曲线,以便控制器了解电池的状态,例如最大和最小电压等,同时为了延长电池的寿命,默认会启用自动校准模式(AutoLearn Mode)。在learn cycle期间,Raid卡控制器不会启用BBU直到它完成校准。整个过程大概1小时左右。这个过程中,会禁用WriteBack模式,以保证数据完整性,同时会造成性能的降低。
整个Learn Cycle分为三个步骤:
控制器把BBU电池充满电(该步骤可能是放电后充电或直接充电,如果电池刚好满电,则直接进入第二阶段);
开始校准, 对BBU电池执行放电;
放电完成后,完成校准,并重新开始充电,直接达到最大电量,整个Learn Cycle才算完成 。
注意:如果第二或第三阶段被中断,重新校准的任务会停止,而不会重新执行。
再来说超级电容:
超级电容优于锂电池,采用电容+Flash子板的方式来将非正常掉电后的脏数据刷入Flash中永久保存。超级电容在50℃环境下可以使用5年,而且故障率低,不用例行充放电。目前大部分raid卡厂商也转向使用超级电容+Flash的备电方案。
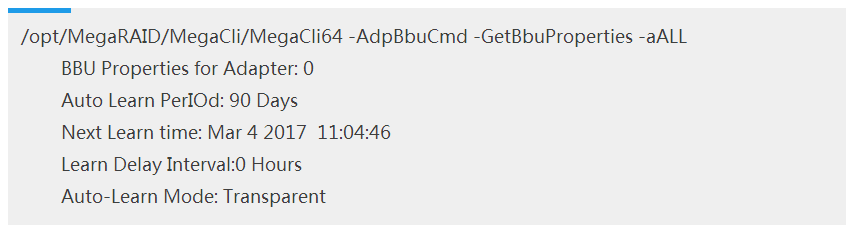
采用MegaCli方式查看电池充放电周期:
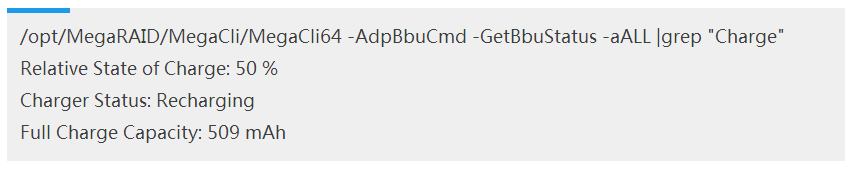
查看充电状态:
HP查看电容状态:

惠普服务器为何没有同类问题?
目前服务器除了HP服务器Raid卡采用镍氢电池、超级电容外,大部分服务器Raid卡还都采用的是锂电池。
镍氢电池、超级电容,它没有惰性,并且特性和锂电池不同,它并不需要通过完全放电来校准电量。
当镍氢电池由于自放电而导致电量降低时到一定程度时(比如80%),阵列卡控制器会感知到这一信息并对电池进行娟流充电以补充失去的电量,整个过程对用户是透明的,也不需要关闭缓存,因此并不会影响IO性能。
各品牌服务器充放电周期:
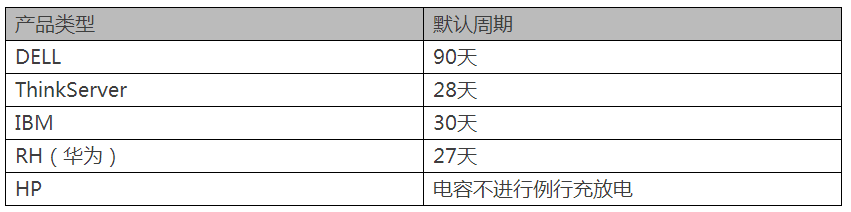
所以,Raid卡电池充放电阶段,会禁用WriteBack模式,以保证数据完整性,同时会造成性能的降低。
通过下面命令生成日志,可以查看充放电详细信息:

服务器硬件自检
除了Raid卡电池外,还有一个影响IO的重要因素那就是硬件自检。回到文章前面提到的监控图,同一业务的8台服务器于11月12日凌晨3:00开始IO开始升高,4:00左右达到最高峰IO利用率达70%左右,之后开始下降直至平稳正常。此系统已经平稳运行了很长时间,并没有做什么上线操作。
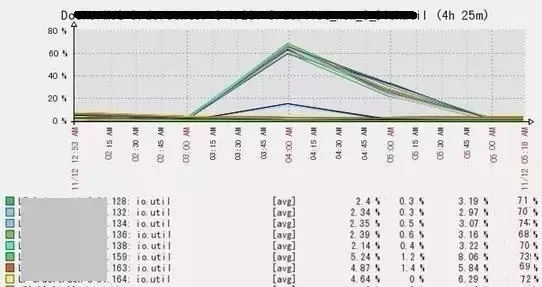
因为是凌晨3:00出现,而且备份正好是凌晨3:00开始,首先想到可能是备份导致的IO上升,但是登上服务器检查发现这几组机器并没有部署备份。
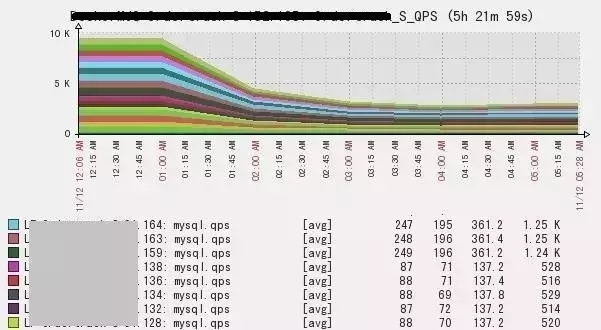
那么接下来可能会认为这段时间事物量较大,通过监控发现这个时间段并没有大量并发,而且此时间段为业务低峰期,相对访问操作较少。
开始着手分析硬件,怀疑为Raid卡电池导致,通过命令生成硬件自检及raid卡电池充放电日志1.log和2.log,部分日志内容如下:
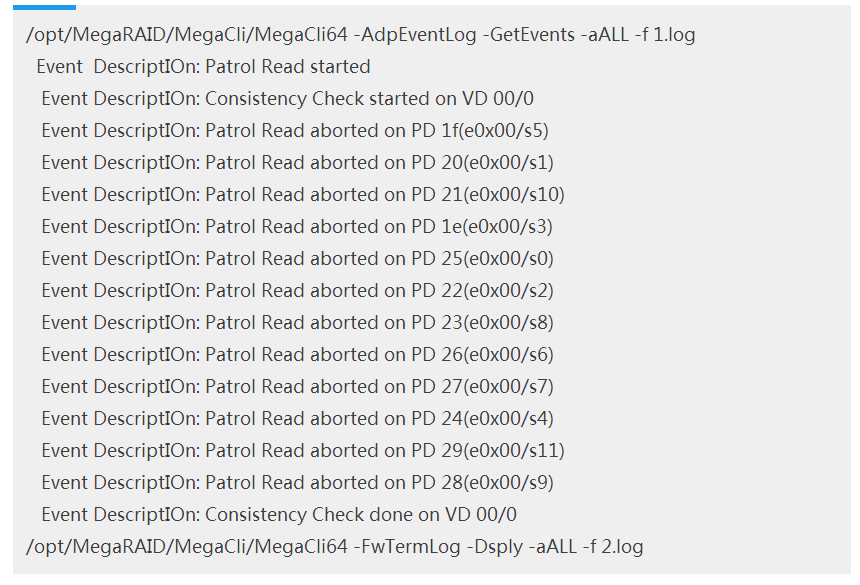
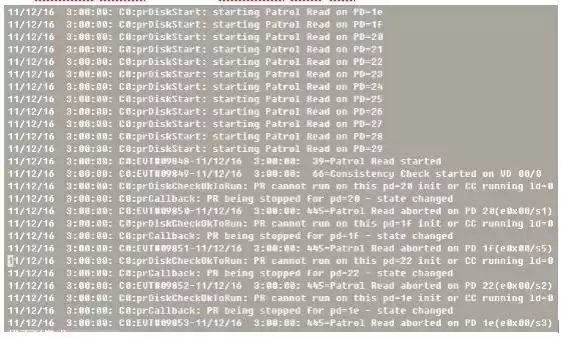
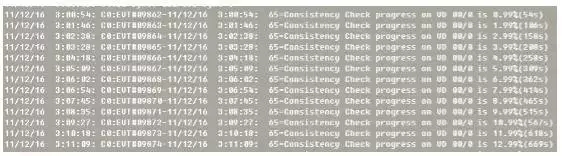
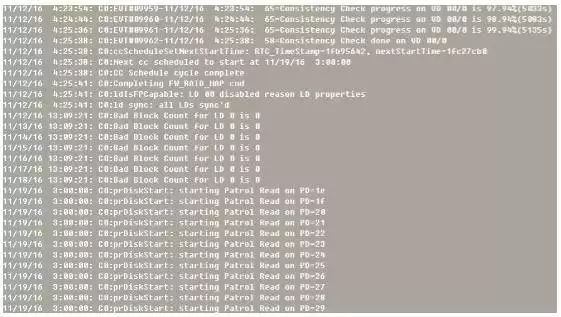
通过分析日志发现,此时Raid卡电池运行正常,也没有进行充放电。而是系统进行了硬件自检,时间是每周六凌晨3:00开始。而且这几台为同一批机器,再查看更久的监控,发现每周六凌晨3:00 都会出现IO较高现象。自检期间IO消耗比较大,如果期间有事物处理,会出现慢SQL、超时等现象,导致TP99报警。
问题原因找到了,该如何优化?
如果调整的话需进入BIOs修改,因为服务器产品不同,修改方法可能不一样。
以DELL、ThinkServer为例:
通过ILO F1进入BIOS,首先需要把BIOS的Legacy修改成UEFI模式:
1.进入boot manage修改 boot mode为UEFI Only
2.进入Miscellaneous Boot Settings修改Storage OpROM Policy为UEFI Only
3.F10保存后重启再进入Boot manage里面可以看到Adapters and UEFI Drivers 选项
4.依次进入Controller Management—>Asvanced Controller Management—>Schedule Consistency Check即可看到一致性检查项:
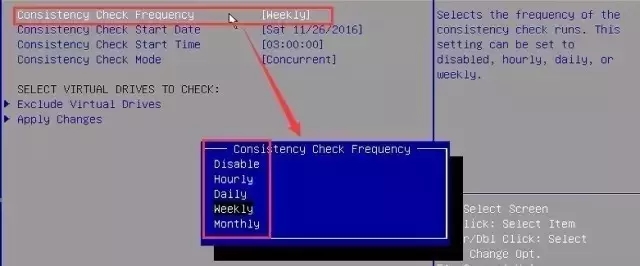
5.修改后,选择Apply Changes,务必执行这一步,选择应用生效
6.再把前面的UEFI修改回Legacy模式,否则无法进入操作系统,重启即可
7.调整后,结合监控和日志检查,没有再出现凌晨3:00 IO升高现象
8.这里的Monthly指的是30天,而不是正常月,所以日期还是不固定9) 调整观察一段时间后,每周六的IO升高现象不再出现,不建议关闭此功能
总结
杜绝以上问题,需要从服务器初始化就做好:
1.调整硬件一致性自检策略,由每周调整为每月,并根据业务情况修改日期。但有一点需要注意,这里的月指的是固定30天,即使调整日期以后还是会错乱。不知道服务器厂商以后是否会修改。
2.针对电商来说,618和双11是最大的两个大促,日期相对固定,所以在大促前最好计算一下,是否会赶上,提前做好调整,相对影响更小、更安全。
3.修改Raid卡缓存策略
WriteBack,ReadAdaptive,Direct,Write Cache if Bad BBU模式:
此模式下存在在BBU有问题时(如电池失效)期间,突然断电或者主板故障都会导致数据丢失风险。
WriteBack,ReadAdaptive,Direct,No Write Cache if Bad BBU模式:
在BBU有问题时, 不使用Write Cache。但是可能发生Write Cache策略变更的情况(由WriteBack变成WriteThrough),导致IO性能急剧下降。
所以,修改成哪种模式需要结合实际业务来定,建议无论是否有raid卡电池都改成WriteBack,ReadAdaptive,Direct,Write Cache if Bad BBU模式。
4.不建议关闭硬件自检,可以适当延长自检周期,通过自检可以及时发现硬件问题,监控更及时。
5.不建议关闭Raid卡电池Auto Learn模式,通过这个校准,能延长电池寿命,不作电池校准的Raid卡,电池寿命将从正常的2年降为8个月。
6.另外mysql innodb_flush_method建议设成O_DIRECT模式:数据文件的写入操作是直接从mysql innodb buffer到磁盘(raid卡缓存)的,并不用通过OS缓冲,而真正的完成也是在flush这步,日志还是要经过OS缓存。
innodb_flush_log_at_trx_commit、sync_binlog改成0模式也会提升IO性能,但数据安全性会大打折扣,所以不到万不得已建议不要调成双0。
HP官方工具集:
经平台同意授权转载
来源:IPCHAT 订阅号








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721