
作者介绍
林伟壕,网络安全DevOps新司机,先后在中国电信和网易游戏从事数据网络、网络安全和游戏运维工作。对Linux运维、虚拟化和网络安全防护等研究颇多,目前专注于网络安全自动化检测、防御系统构建。
众所周知,Nginx是目前最流行的Web Server之一,也广泛应用于负载均衡、反向代理等服务,使用过程中可能因为对Nginx工作原理、变量含义、参数大小等问题的理解错误,导致Nginx工作异常。
因此,本文将从一个Nginx错误代码400引发的故障入手,谈谈如何分析和修复常见的Nginx异常。

故障简述
小明某天中午在线优化一个敏感服务的Nginx配置时,发现5分钟内Nginx errorlog里出现了大量400错误,于是迅速回滚了Nginx配置。
故障详情
原来的Nginx配置存在重复或者需废弃的内容,于是在多次diff了新旧两份配置内容后,小明认为最新配置是不影响业务的,因此在线推送更新配置后,直接reload了Nginx,出于double check原则,在线观察了5分钟Nginx日志:

发现出现大量类似下面的400错误:

400错误的产生,很可能影响服务端或客户端的后续业务逻辑判断,因此需要引起重视。
处理过程
 节点1
节点1
当时回滚配置后,小明先在搜索引擎查找了Nginx 400错误的可能原因和解决办法,初步确定有下面两种可能:1是空主机头,2是请求包头过大。
小明跟客户端同学确认了客户端请求方式,发现他们使用的是类似telnet的方式发起的http请求,类似下面的:

为了方便后续排查,小明参考线上环境临时搭建了一套Nginx测试环境,重现了故障:
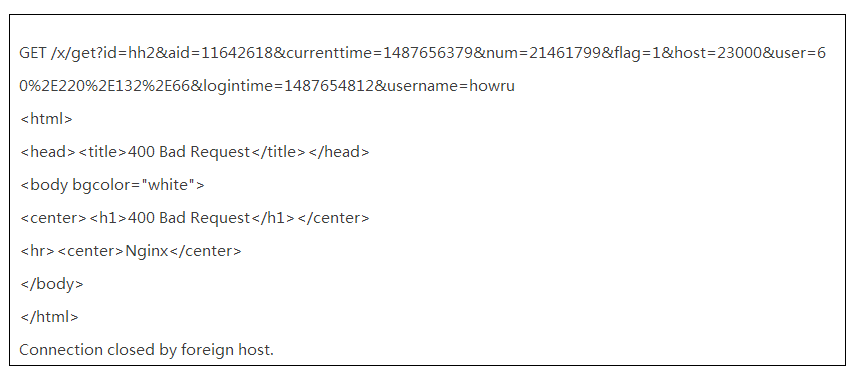
后来小明了解到原来客户端不是从代码的http库调用, 而是按照上面的方式走TCP/telnet传递http参数来调用服务端http接口。但是为什么一样的客户端请求方式,旧配置完全ok,新配置则会出现大量400错误?
节点2
至此,小明怀疑自己没有完全diff出新旧两份配置的差别,于是他使用vimdiff再次对比新旧两份配置。下面仅贴出关键配置:
旧配置:
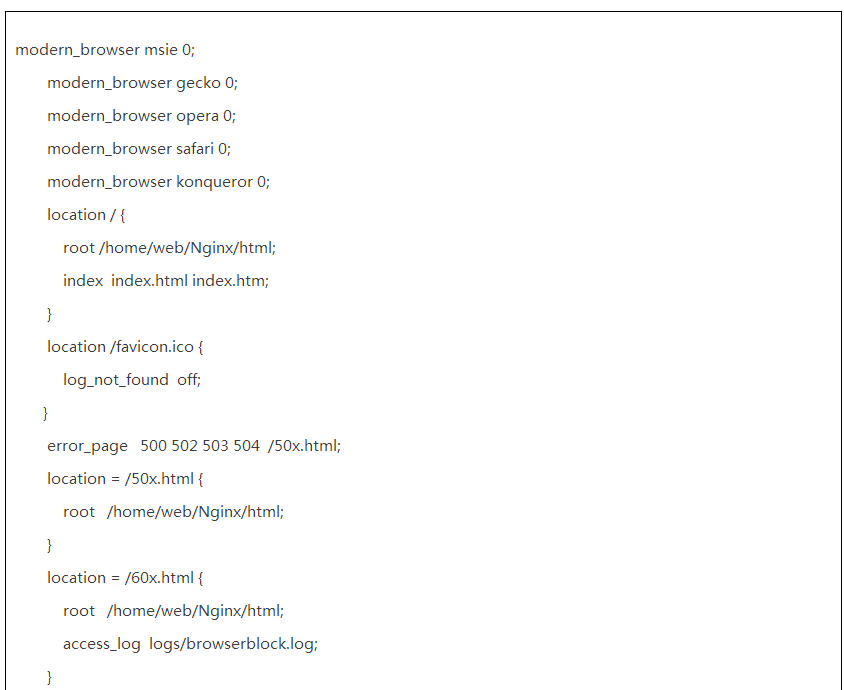

新配置:

本次排查中,小明考虑的重点是新配置里遗漏了某些配置,于是他把location ~ (.*)的相关逻辑加上,发现问题依旧:

节点3
既然前面往缺失配置的思路走不通,下面就按照新增配置的思路排查,结果发现新配置增加了一些包头信息,小明怀疑是请求包过大,于是优先排查了Nginx针对包头大小的设置,其中有这么几个配置:
client_header_buffer_size:默认是1k,所以header小于1k的话是不会出现问题的。
large_client_header_buffers:该命令用于设置客户端请求的Header头缓冲区的大小,默认值为4KB。
客户端请求行不能超过large_client_header_buffers指令设置的值,客户端请求的Header头信息不能大于large_client_header_buffers指令设置的缓冲区大小,否则会报“Request URL too large”(414)或者“Bad-request”(400)错误,如果客户端Cookie信息较大,则须增加缓冲区大小。于是小明将client_header_buffer_size和large_client_header_buffers都设置为128k。结果问题也重现了。
接下来,小明发现新配置中多了“proxy_set_header Host $http_host;”查找了Nginx官方文档发现跟$http_host类似功能的还有$server_name和$host等变量,在他将$http_host更换成$host后,问题修复了。
原因分析
根据Nginx官方文档介绍,400状态码含义如下:

上面是http1.1的rfc关于host部分的解释,从上面我们了解到如果一个http1.1的请求没有host域,那么server应该给client段发送400的状态码,表明这个请求server不能处理。而对于Nginx server来说,也遵循这样的方式,说明client发送了一个无效的请求,Nginx server无法处理,于是返回了400的状态码。
另外,关于$host和$http_host这两个变量的区别如下:

本次故障中,客户端的调用方式没有使用host 参数,传递了空的Host头给服务端,一旦Nginx设置了proxy_set_header Host $http_host,空Host头就传给了后端。然而,在http 1.1的规范中,Host只要出现空,就会返回400,所以出现了这个故障。而对于需要在Host字段里带上端口信息的,则仍需要配置proxy_set_header Host $http_host。
最后,需要注意的是,400错误不一样会影响业务,需要看具体的业务处理逻辑,比如使用nagios的check_tcp插件对Nginx server端口做检测或者使用keepalived的tcp_check功能对后端Nginx端口的存活做检测,这两种情况都会在Nginx errorlog中产生400的请求。
原因也很简单,就是一般tcp check的方式,就是建立tcp连接,但是没有发送任何数据,当然也没有Host头,然后再reset或者四次挥手断开连接。
经验教训
运维规范
细心的同学会发现本次配置更新是在大中午操作,而且也没有在测试环境测试通过,这在流程上是不严谨的。虽然Nginx等web服务的配置更新基本上通过热更就可以了,但没有灰度测试或者在测试环境测试,一是无法提前发现问题,二是无法控制业务影响。所以,在运维规范上看,即使是热更也应当在测试环境测试正常后再同步到线上,其他的更新则应在业务低谷时操作。
技术学习方法
本次故障的产生,很大程度上就是运维同学不理解Nginx变量的定义和区别,直接从搜索引擎上找了些配置,检查觉得正确就推到了线上。这里仍需要重申的是,以官方文档为准!互联网上很多知识或者配置有各种各样的问题,随时都有暗坑在里边,只有啃过官方文档才能避免误读。
Web日志分析
针对这里的Nginx错误日志查看,我们看到小明是用在线命令查看的,其实现在有很多web日志分析工具或系统,比如ELK(ElacticSearch+LogStash+Kibana),只需要配置好grok正则,是可以通过可视化界面实时监控web服务质量的。
引申
上面介绍了Nginx 400错误的可能原因和解决办法,但实际工作中,我们遇到的可不止这么一点。于是,由此引申出去的是,针对那些Nginx常见错误如何去排查和解决。
403错误
403是很常见的错误代码,一般就是未授权被禁止访问的意思。
可能的原因有两种:
Nginx程序用户无权限访问web目录文件
Nginx需要访问目录,但是autoindex选项被关闭
修复方法:
授予Nginx程序用户权限读取web目录文件
设置autoindex目录为on

413错误
在上传时Nginx返回了413错误:“413 Request Entity Too Large”,这一般就是上传文件大小超过Nginx配置引起。
修复方法:
在Nginx.conf增加client_max_body_size的设置,这个值默认是1M,可以增加到8M以提高文件大小限制;
如果运行的是php,那么还要检查php.ini,这个大小client_max_body_size要和php.ini中的如下值的最大值一致或者稍大,这样就不会因为提交数据大小不一致出现的错误。
post_max_size = 8M
upload_max_filesize = 2M
502错误
Nginx 502 Bad Gateway的含义是请求的PHP-CGI已经执行,但是由于某种原因(一般是读取资源的问题)没有执行完毕而导致PHP-CGI进程终止。一般来说Nginx 502 Bad Gateway和php-fpm.conf的设置有关。
修复方法:
1、查看FastCGI进程是否已经启动
ps -aux | grep php-cgi
2、检查系统Fastcgi进程运行情况
除了第一种情况,fastcgi进程数不够用、php执行时间长、或者是php-cgi进程死掉也可能造成Nginx的502错误。
运行以下命令判断是否接近FastCGI进程,如果fastcgi进程数接近配置文件中设置的数值,表明worker进程数设置太少。
netstat -anpo | grep "php-cgi" | wc -l
3、FastCGI执行时间过长
根据实际情况调高以下参数值
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
504错误
Nginx 504 Gateway Time-out的含义是所请求的网关没有请求到,简单来说就是没有请求到可以执行的PHP-CGI。
Nginx 504 Gateway Time-out一般与Nginx.conf的设置有关。
头部太大这种情况可能是由于Nginx默认的fastcgi进程响应的缓冲区太小造成的, 这将导致fastcgi进程被挂起,如果你的fastcgi服务对这个挂起处理的不好,那么最后就极有可能导致504 Gateway Time-out。
默认的fastcgi进程响应的缓冲区是8K,可以调大以下参数:
fastcgi_buffer_size 128k;
fastcgi_buffers 8 128k;
fastcgi_busy_buffers_size 由 128K 改为 256K;
fastcgi_temp_file_write_size 由 128K 改为 256K。
此外,也可能是php-cgi的问题,需要修改php.ini的配置:
将max_children由之前的10改为30,这样操作是为了保证有充足的php-cgi进程可以被使用。
将request_terminate_timeout由之前的0秒改成60秒,这样使php-cgi进程处理脚本的超时时间提高到60秒,可以防止进程被挂起以提高利用效率。

参考资料
Nginx 400状态码排查
http://www.68idc.cn/help/jiabenmake/qita/20140707115201.html
Nginx变量大全
https://openresty.org/download/agentzh-Nginx-tutorials-en.html
Nginx报502、504、400、413错误







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721