

(点击“此处”可获取余军演讲完整PPT)
讲师介绍
余军,PingCAP金融行业首席架构师,20年企业级开源软件架构经验。前富麦科技CTO,前Red Hat中国区解决方案业务总监,前惠普分布式计算高级技术专家,长期服务金融行业开源架构和专家服务。重点服务于包括:商业银行、证券期货交易所及券商、大型保险行业等。长期专注于企业级分布式系统高可用架构设计及开源IT战略规划咨询。
一、背景
大家都了解,整个关系型数据库技术的发展经历了漫长岁月,这些数据库大家都非常熟悉,包括交易型数据处理技术和数据分析型领域的很多产品和技术。
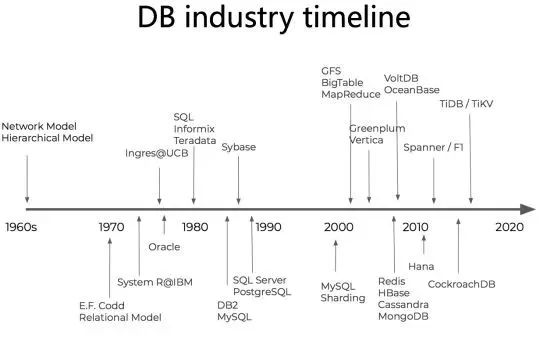
可能大家也关注到了一种规律,在整个数据库技术的发展历程中,总会有一些关键时间节点事件,这些关键节点事件发生后会显著地推动技术变革。图中这根线是数据库技术发展的脉络线,很明显看出从以中心化的技术架构方式向分布式架构发展的脉络。可以看到在谷歌著名的三篇数据处理论文发表以后,业界掀起了以分布式架构为主旋律的大数据技术演进和变革。

2012、2013年的时候,谷歌发表了一篇重要的论文,不知道大家听说过没有,谷歌的核心数据库叫Spanner/F1,它是个计算和存储分层的数据库架构,支撑谷歌的核心业务(广告业务,应用商店和金融支付相关业务等)。
在2015年左右,我们PingCAP的创始团队在谷歌的这套Spanner/F1论文的启发下,抓住了这个最新的数据库发展变革节点,启动了名叫TiDB的开源分布式数据库软件项目和相关产品研发。
整个项目从第一天开始就是以开源项目而存在的,无论是用户还是数据库方面的开发者,都可以在我们GitHub项目主页上,看到我们产品的所有代码的变化和快速迭代演进。同时,我们已经和国内外分布式数据处理技术的领先技术团队在研发合作层面建立了丰富的合作互动关系,也积极参与到全球云原生应用基金会CNCF的生态中,该基金会作为Linux基金会的分支机构,在未来5年的云计算领域将扮演极其重要的角色。
二、分布式数据库TiDB

底下的TiKV层,是我们分布式数据库存储引擎层,不只是用来存取和管理数据,同时也负责执行对数据的并行运算,在TiKV之上有TiDB分布式SQL引擎层,处理最核心的一个关系数据库需要做的诸如连接会话管理、权限控制、SQL解析、优化器优化、执行器等核心功能。此外我们在架构中还有一个承担集群大脑角色的集中调度器,叫做PD,同时在我们发布版本里面,还提供了运维的完善的工具,包括部署、变更、监控等。
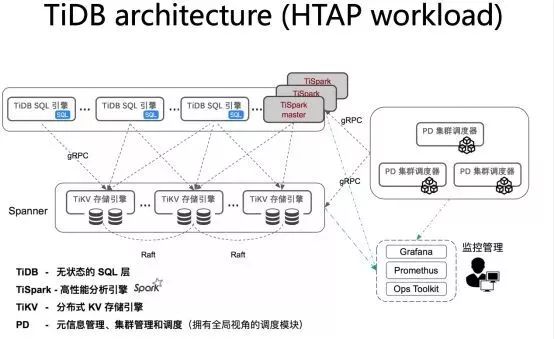
TiDB除了能够支撑海量大并发和强分布式事务这类联机交易处理OLTP负载的架构之外,在现在整个数据库的应用场景当中,还很好地支持了一类快速崛起的业务场景,就是数据中台类的HTAP混合负载计算业务场景。在金融行业有诸如实时风控、多源数据聚合与分析、实时数仓等。
我们有专门的研发团队负责设计和研发我们的高性能分析引擎,叫TiSpark,也就是上图的灰色部分。我们和Spark上游社区保持了紧密的沟通和互动并且与Spark领域全球知名厂商Databricks建立了深度的合作关系。TiSpark引擎的开发团队通过对Spark里面两个API的拦截,捕获用户的SQL请求;通过TiSpark对计算请求和计划的改写和优化,产生能够下推到TiKV层的各种计算执行指令。TiDB/TiSpark这样的架构,可以完成对海量数据计算的实时要求比较高的的业务负载需求和业务逻辑以及非常复杂的SQL业务逻辑分析要求,典型的比如:交易监控、风控等,待会儿我会提一些案例讲。
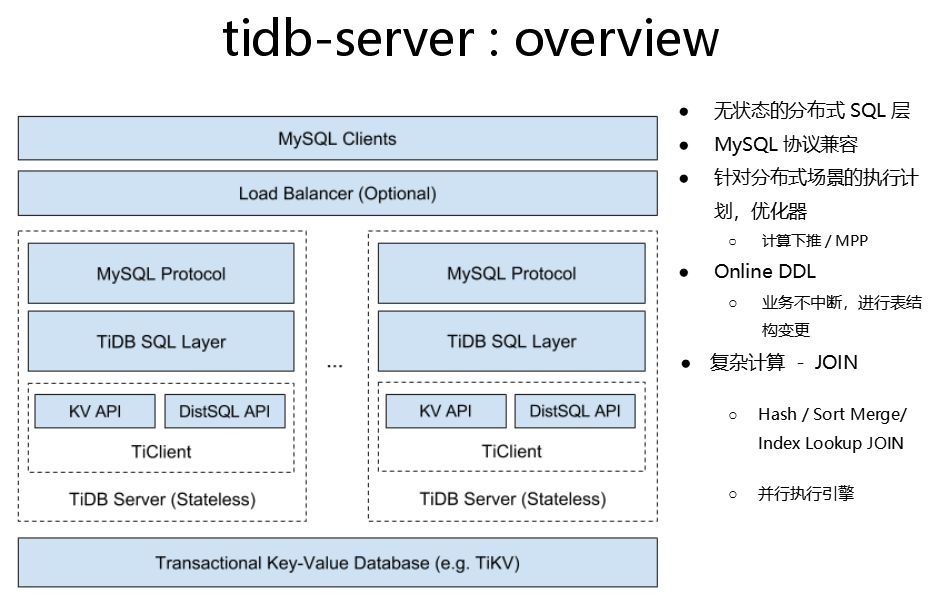
这是一个无状态的组件。完全不同于前几代基于MySQL/Postgres分库分表中间件Proxy架构的运行机制,TiDB SQL引擎是一个完整的SQL引擎,它除了完成SQL解析和控制之外,内部有完整的自己的SQL优化器和执行引擎,它跟下层的 TiKV分布式数据库存储引擎层通过两个引擎之间内部的gRPC机制执行引擎内的高并发通讯,对用户来说TiDB和TiKV构成一个横向可以弹性扩展的强大的数据库引擎体系,完全不再需要依赖任何的所谓的“数据库中间件”,业务应用在操作一个 TiDB进行数据存取的时候,有着和操作单机数据库一样的便利性和透明度,同时获得强大的性能/容量的横向扩展能力。
大家都知道数据库系统会有一个前向的连接通讯协议,我们TiDB采用兼容MySQL的协议的思路,同时我们在数据库内部的DDL/DML上也尽可能兼容MySQL,这样能够大大方便使用MySQL的用户非常简单直接的迁移应用到TiDB,而无需在协议层和业务逻辑上做代码或者框架上的转换,这个也是我们最早开始做这个产品的初衷之一,做一个能够弹性扩展,高可用,更加智能好用且拥抱MySQL生态的数据库产品。
同时我们会按照MySQL兼容路子去做类似的权限认证的体系,包括函数等等我们都会做它的兼容。目的就是为了让应用从MySQL到TiDB这个数据库切入过去是无缝的过程。另外我们借鉴了谷歌同样在 2013 年发表的一篇论文,实现了可以在线执行的无阻塞DDL变更。

上面这个图是整个SQL引擎的结构,只要能够连上MySQL的客户端,驱动也好、框架也好,都可以直接连上TiDB。
客户端进来以后也是有监听器做监听,SQL解析生成 AST抽象语法树和后继的验证和类型推到等处理。然后TiDB SQL优化器通过基于规则的RBO和基于成本的CBO优化器机制产生逻辑执行计划和物理执行计划,并通过本地执行器和分布式执行器,将能够下推到TiKV层的数据计算和操作指令通过TiDB SQL引擎和TiKV存储引擎之间的gRPC通讯下发下去。
我们在SQL引擎这块做了大量优化,现在已经进入到 2.0 的版本系列。TiDB的SQL引擎整个优化会先过一个RBO,过完以后根据统计信息,通过这个信息通过我前面说的调度器提供给它的下面的信息,当中过了CBO这样一个优化的逻辑。

我们做了很多优化的点,大家可以看一下。各种各样的下推、函数,这些东西都可以打包往下走。走下去以后这个请求就会走到分布式的TiKV存储引擎,我们做SQL引擎跟计算引擎分离的话,有很多好处:横向扩展变得非常灵活,运维方面比较简单。因为TiDB是个开源项目,所以上下层的API接口也是开放给社区的,你可以有很多其它的玩法。在开源社区里已经有小伙伴根据我们的API接口,嫁接了Redis协议过来,形成了一个新的有趣的开源项目。

这个是我们TiKV存储引擎的架构,它里面的逻辑功能结构就是图上这样一个主要的组成。
TiKV作为存储引擎,最基本的需求就是要把数据库的数据安全可靠高性能的落下来。
我们早期的时候认识到这个问题的重要性,所以比较早跟Facebook合作,采用了Facebook的RocksDB开源项目作为单机持久化引擎,并用它主要来做三件事情:
快速安全的把存储层的数据做持久化。
因为我们是关系数据库,实现了完整分布式事务,不需要侵入。我们的事务模型采用了谷歌的Percolator模型,一个去中心化的的两阶段事务递交方案。在这块我们利用到了RocksDB里面一个高级特性Column Family,来配合事务层完成分布事务。
实现Snapshot快照,动态扩容过程中通过对TiDBRegion数据区的数据进行快照来快速扩展集群的新节点,配合下面讲的Raft机制完成后台的透明数据平衡。
Raft层
再往下这层是整个TiKV当中最核心的层,就是Raft层。大家都知道Raft层是保证数据一致性的。我们在不同的节点之间,在这个过程当中引擎发过来所有的请求,到达了TiKV以后,先过事务层(因为是个关系数据库,也是有版本的,你对这个数据做操作时候会产生新的版本),事务层过了、到达Raft层以后,在不同的TiKV事务之间,通过Raft做一个复制。多数派到达了这个递交点以后,开始各自往下走持久化,底层引擎的机制是这样一个机制。
在每个公司上面的话,我们是这样从关系模型到底层的存储模型做一个转换。我们会把一个关系表,按照一定的规则进行数据模型上的切分,将每一行的记录值构造成一个Value,然后引擎会为这个Value构造一个Key,这些Key在逻辑空间上是全局有序的。这些动作都是在数据库引擎内部自动且透明的完成的,所以用户不需要做数据表的人为切分。还是像单机数据库一样,创建库、创建表,该建索引的地方建索引,该设计主键的建主键。
TiDB为了高效率管理数据,根据连续的Key按照一段范围内数据的大小作为边界,设定了一个叫做Region的管理概念,也就是一堆Key连续的数据(记录及索引) 的集合。默认一个Region的大小是96MB,用户是可以根据工作负载不同的性能和管理需求调整这个设定。
所以在一个TiDB典型的海量数据处理生产环境里面,你可能有几千万的Region在里面,甚至更大都是有可能的。这种数据组织和管理方式,也是TiDB能够在单表数据没有限制,可以存放几十亿,几百亿行数据的原因。
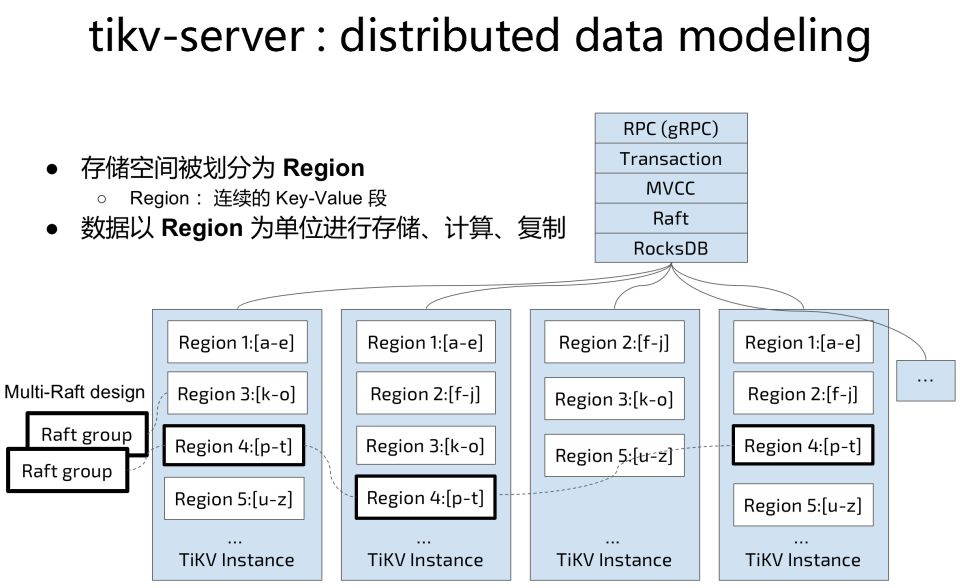
不同的Region之间是打乱调度在不同的机器上面,这样的话我们就通过这样的管理模式,实现了一个对数据库表最小颗粒的切分。
有了这样一个结构以后,配合上Raft的机制,在不同的Region、不同的实例之间建立副本。
当上面的SQL引擎的改查到达这个引擎层的时候,比如说你一个表有一亿行,Region可能切了五个,那么这时候每一个都会有副本在不同的节点上,它一个单个的Region就是一个Raft的组,我们在一个集群里面会有多个Region。
单一的一个Raft组内,在Region副本成员中会选出一个Leader,不同的Raft组各自选出自己的Leader Region。然后TiDB的调度系统会将不同Raft group的Leader region调度在不同的服务器节点上,TiDB SQL引擎发过下来的读写请求,都只会去不同Raft group中被选举成Leader的那个Region去处理读写。所以在TiKV存储引擎的架构上面,我们并不是以机器为单位作为主从,我们是一个全对等全活的结构。TiKV集群中的每台服务器都同时在提供数据读写服务。这也是TiDB数据库扩展能力优异的主要原因之一。
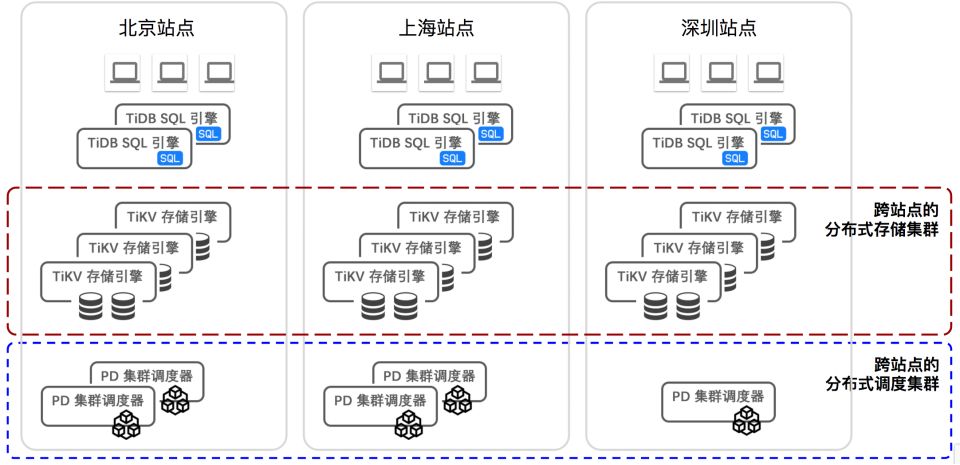
基于这样一个架构还能做一件事情。就是将一套数据库跨多中心部署和运行,一套数据库在几个站点当中,它TiKV的节点,下面这个节点都可以跨中心来做。我们今年完成了国内某头部城商行的一个跨两地三中心的核心交易系统的生产投产工作。
典型的跨中心架构见下图:
除了上述核心数据库引擎的组件之外,我们有个性能优异的OLAP分析引擎——TiSpark引擎。
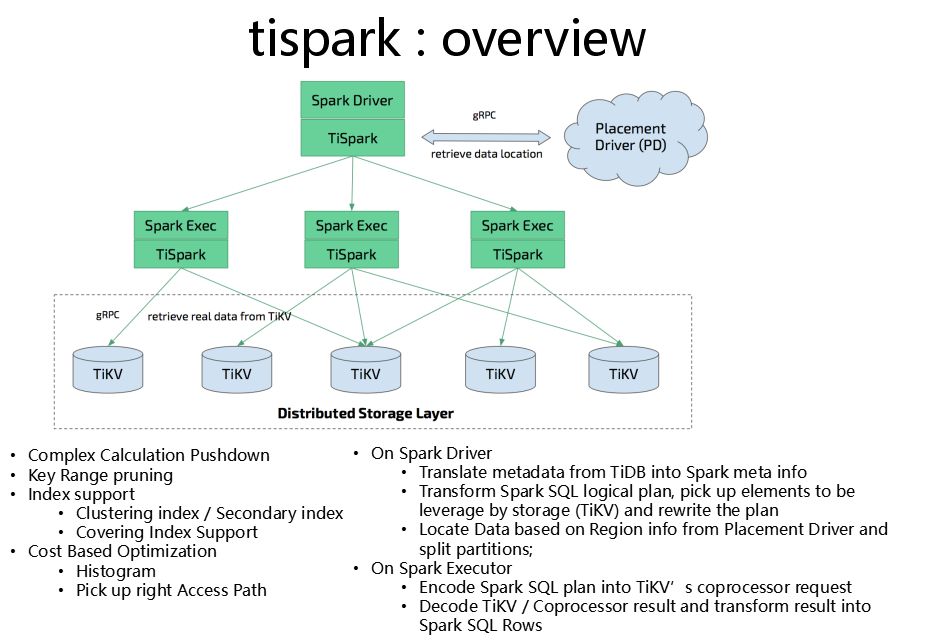
以上是Tispark的架构,TiSpark用来处理复杂的SQL计算的。大家知道原生Spark速度非常快,我们想让它更快和能够处理更加复杂的业务场景,我们又做了TiSpark组件,不需要依赖于大数据平台环境,把这个TiSpark集群部署上去以后,请求到达Spark,TiSpark会通过Spark内的API接口拦截,利用现有集群的meta信息,改写计算的plan,也可以直接利用当前集群数据中的索引信息,TiSpark和集群调度器PD协同,获得集群的各种关键信息。
TiSpark可以实现复杂计算的下推,利用现在的集群的统计信息实现CBO基于成本的代价模型的优化等性能优化手段;因此TiSpark可以做非常复杂的准实时分析业务。被金融行业广泛用于实时征信计算、实时风控、实时数仓、海量数据的实时查询分析等业务场景。
TiDB除了上述介绍的核心引擎和分析引擎之外,我们还为用户设计和实现了完整的配套工具,尤其是针对商业用户提供了完整的配套工具侧解决方案。

比如前面是MySQL的表,可以把这个数据持续同步到TiDB里面来。然后已经做完分表的数据库,我们在同步的工具里面有一个正则引擎,可以根据规则自动做同步。所以到TiDB 里面的话,你看到的还是一个库一个大表,因为在TiDB里面其实表大表小无所谓了。我们现在用户单个表的话十几亿很正常的,我们也有很多用户也是用TiDB + TiSpark的结构做数据的ODS和实时数仓。在里面加工完了以后,再给前面的消费网关。
现在企业纷纷在评估和引入微服务架构,特别是在微服务架构中,上面是微服务架构支撑的业务应用层,下面我们可以通过数据服务网关。通过TiDB来为微服务应用层提供灵活的数据支撑。
三、应用

金融行业对于核心数据库的交易事务要求非常高,TiDB提供完整的分布事务支持、提供多维度数据入口处理,对业务没有侵入这种特性,在应用TiDB的时候和使用单机数据库几乎一样的体验。对于在线核心交易系统,TiDB提供了强有力的高可用保障和在线的弹性扩缩容,这些都是金融企业关注和重视TiDB的主要原因。另外在海量实时分析场景中,包括针对多源汇聚的场景,不同业务源的生产库同步到TiDB里来,在里面做一些实时的计算包括数仓、做数据加工等。当然金融行业比较喜欢真正做到一个多活的结构,可靠性也比较高。
现在TiDB量都比较大,一般都是在线做,对开发也比较友好,前面都是标准SQL,应用也不需要做太多。包括我们做的分布事务这些东西,都不是什么侵入性的,不需要做什么修改。当然有些分布式事务的数据量大小可能要做限制,这个可能要分批处理。我们也为用户提供了在TiDB上做应用开发方面的建议和规范文档可供参考。
因为我这边主要以金融行业为主,这两年里金融用户,证券、保险、银行、交易所、互联网金融公司等用得特别多,大概整理了一下,基本上都有了。我们今年三月份上线的就是一个核心的在线支付交易相关的场景。
在线交易类业务场景
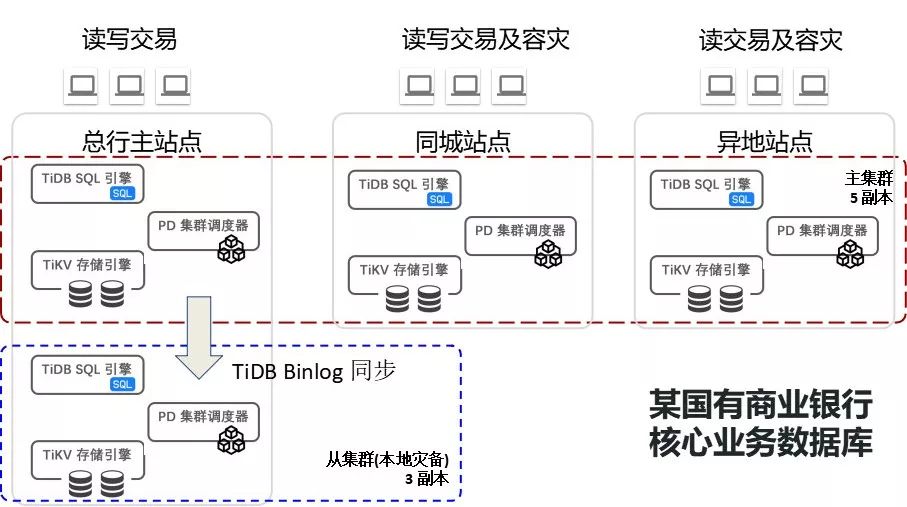
这是前面说的城商行一个具体案例,在线交易类的。目前整个城商行核心在线支付交易全部移到TiDB上面来了,同城有两个中心,还有一个异地的千公里以上的站点,它是一套数据库集群跨在了三个中心之上部署和运行。
金融产品营销类业务场景
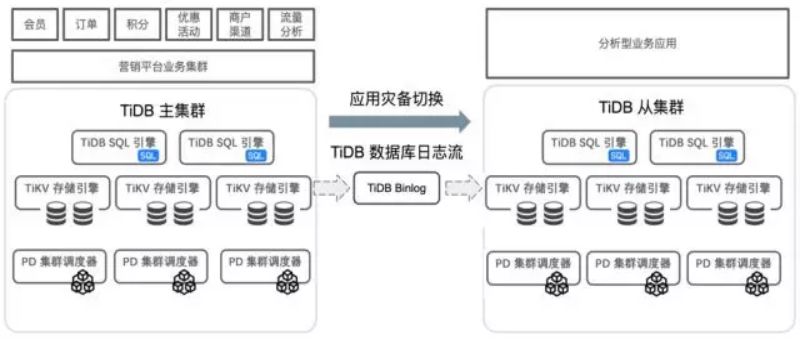
某大型互联网金融企业营销平台
这个是做营销平台,卖各种各样的理财产品等等。
金融实时风控类场景

某大型金融企业在线实时风控平台
这个是做风控,我们有的用户在旁边还会有数据库,做完以后会回写进TiDB。









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒