
作者介绍
傅宇,阿里巴巴分布式数据库(DRDS)团队高级开发工程师,专注大数据与分布式系统。个人博客 https://ericfu.me/
列式存储(Column-oriented Storage)并不是一项新技术,最早可以追溯到 1983 年的论文 Cantor。然而,受限于早期的硬件条件和使用场景,主流的事务型数据库(OLTP)大多采用行式存储,直到近几年分析型数据库(OLAP)的兴起,列式存储这一概念又变得流行。
总的来说,列式存储的优势一方面体现在存储上能节约空间、减少 IO,另一方面依靠列式数据结构做了计算上的优化。本文将着重介绍列式存储的数据组织方式,包括数据的布局、编码、压缩等。
一、什么是列式存储
传统 OLTP 数据库通常采用行式存储。以下图为例,所有的列依次排列构成一行,以行为单位存储,再配合以 B+ 树或 SS-Table 作为索引,就能快速通过主键找到相应的行数据:
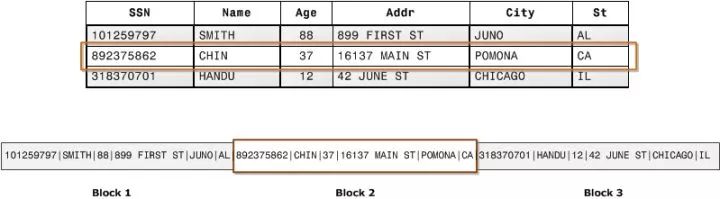
行式存储对于 OLTP 场景是很自然的:大多数操作都以实体(Entity)为单位,即大多为增删改查一整行记录,显然把一行数据存在物理上相邻的位置是个很好的选择。
然而,对于 OLAP 场景,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,这样一来按行存储的优势就不复存在了。更糟糕的是,分析型 SQL 常常不会用到所有的列,而仅仅对其中某些感兴趣的列做运算,那一行中无关的列也不得不参与扫描。
列式存储就是为这样的需求设计的。如下图所示,同一列的数据被一个接一个紧挨着存放在一起,表的每列构成一个长数组:
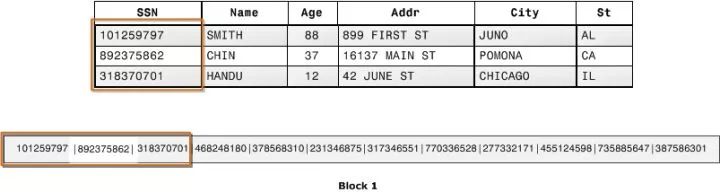
显然,列式存储对于 OLTP 不友好,一行数据的写入需要同时修改多个列。但对 OLAP 场景有着很大的优势:
当查询语句只涉及部分列时,只需要扫描相关的列
每一列的数据都是相同类型的,彼此间相关性更大,对列数据压缩的效率较高
小贴士:
BigTable(HBase)是列式存储吗?
很多文章将 BigTable 归为列式存储。但严格地说,BigTable 并非列式存储,虽然论文中提到借鉴了 C-Store 等列式存储的某些设计,但 BigTable 本身按 Key-Value Pair 存储数据,和列式存储并无关系。
有一点迷惑的是 BigTable 的列簇(Column Family)概念,列簇可以被指定给某个 Locality Group,决定了该列簇数据的物理位置,从而可以让同一主键的各个列簇分别存放在最优的物理节点上。由于 Column Family 内的数据通常具有相似性,对它做压缩要比对整个表压缩效果更好。
另外,值得强调的一点是:列式数据库可以是关系型、也可以是 NoSQL,这和是否是列式并无关系。本文中讨论的 C-Store 就采用了关系模型。
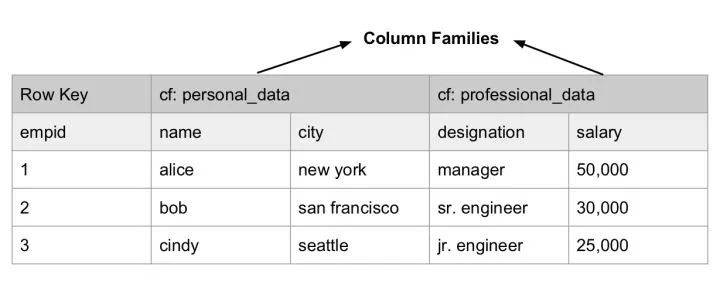
Column Families in BigTable
二、起源:DSM 分页模式
我们知道,由于机械磁盘受限于磁头寻址过程,读写通常都以一块(Block)为单位,故在操作系统中被抽象为块设备,与流设备相对。这能帮助上层应用更好地管理储存空间、增加读写效率等。
这一特性直接影响了数据库储存格式的设计:数据库的 Page 对应一个或几个物理扇区,让数据库的 Page 和扇区对齐,提升读写效率。
那如何将数据存放到页上呢?
大多数服务于在线查询的 DBMS 采用 NSM (N-ary Storage Model),即按行存储的方式,将完整的行(即关系 relation)从 Header 开始依次存放。页的最后有一个索引,存放了页内各行的起始偏移量。由于每行长度不一定是固定的,索引可以帮助我们快速找到需要的行,而无需逐个扫描。
NSM 的缺点在于:如果每次查询只涉及很小的一部分列,那多余的列依然要占用掉宝贵的内存以及 CPU Cache,从而导致更多的 IO。为了避免这一问题,很多分析型数据库采用 DSM(Decomposition Storage Model),即按列分页:将 Relation 按列拆分成多个 Sub-relation。类似的,页的尾部存放了一个索引:
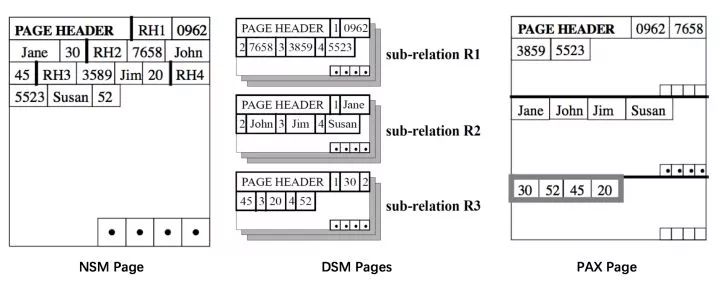
顺便一提,2001 年 Ailamaki 等人提出 PAX (Partition Attributes Cross) 格式,尝试将 DSM 的一些优点引入 NSM,将两者的优点相结合。
具体来说,NSM 能更快速地取出一行记录,这是因为一行的数据相邻,保存在同一页;DSM 能更好地利用 CPU Cache 以及使用更紧凑的压缩。PAX 的做法是将一个页划分成多个 Minipage,Minipage 内按列存储,而一页中的各个 Minipage 能组合成完整的若干 Relation。
如今,随着分布式文件系统的普及和磁盘性能的提高,很多先进的 DBMS 已经抛弃了按页存储的模式。但是其中的某些思想,例如数据分区、分区内索引、行列混合等,仍然处处可见于这些现代的系统中。
分布式储存系统虽然不再有页的概念,但是仍然会将文件切割成分块进行储存,但分块的粒度要远远大于一般扇区的大小(如 HDFS 的 Block Size 一般是128MB)。更大的读写粒度是为了适应网络 IO 更低的带宽以获得更大的吞吐量,但另一方面也牺牲了细粒度随机读写。
三、列数据的编码与压缩
无论对于磁盘还是内存数据库,IO 相对于 CPU 通常都是系统的性能瓶颈,合理的压缩手段不仅能节省空间,也能减少 IO 、提高读取性能。列式存储在数据编码和压缩上具有天然的优势。
以下介绍的是 C-Store 中的数据编码方式,具有一定的代表性。
根据:数据本身是否按顺序排列(Self-Order)以及数据有多少不同的取值(Distinct Values),我们分成以下 4 种情况讨论:
有序且Distinct值不多。使用一系列的三元组(v,f,n)对列数据编码,表示数值v从第f行出现,一共有n个(即f到f+n−1行)。例如:数值4出现在12-18行,则编码为 (4,12,7)。
无序且Distinct值不多。对于每个取值v构造一个二进制串b,表示v所在位置的Bitmap。例如:如果一列的数据是0,0,1,1,2,1,0,2,1,则编码为(0,110000100)、(1,001101001)和(2,000010010)。由于Bitmap是稀疏的,可以对其再进行行程编码。
有序且Distinct值多。对于这种情况,把每个数值表示为前一个数值加上一个变化量(Delta),当然第一个数值除外。例如,对于一列数据1,4,7,7,8,12,可以表示为序列1,3,3,0,1,4。显然编码后的数据更容易被Dense Pack,且压缩比更高。
无序且Distinct值多。对于这种情况没有很好的编码方式。
编码之后,还可以对数据进行压缩。由于一列的数据本身具有相似性,即使不做特殊编码,也能取得相对较好的压缩效果。通常采用 Snappy 等支持流式处理、吞吐量高的压缩算法。
最后,编码和压缩不仅是节约空间的手段,更多时候也是组织数据的手段。在 PowerDrill、Dremel 等系统中,我们会看到很多编码本身也兼具了索引的功能,例如在扫描中跳过不需要的分区,甚至完全改表查询执行的方式。
四、列式存储与分布式文件系统
在现代的大数据架构中,GFS、HDFS 等分布式文件系统已经成为存放大规模数据集的主流方式。分布式文件系统相比单机上的磁盘,具备多副本高可用、容量大、成本低等诸多优势,但也带来了一些单机架构所没有的问题:
读写均要经过网络,吞吐量可以追平甚至超过硬盘,但是延迟却要比硬盘大得多,且受网络环境影响很大;
可以进行大吞吐量的顺序读写,但随机访问性能很差,大多不支持随机写入。为了抵消网络的 Overhead,通常写入都以几十MB为单位。
上述缺点对于重度依赖随机读写的 OLTP 场景来说是致命的。所以我们看到,很多定位于 OLAP 的列式存储选择放弃 OLTP 能力,从而能构建在分布式文件系统之上。
要想将分布式文件系统的性能发挥到极致,无非有几种方法:按块(分片)读取数据、流式读取、追加写入等。我们在后面会看到一些开源界流行的列式存储模型,将这些优化方法体现在存储格式的设计中。
五、列式存储系统案例
大多数 DBMS 都是为了写优化,而 C-Store 是第一个为了读优化的 OLTP 数据库系统,虽然从今天的视角看它应当算作 HTAP 。在 Ad-Hoc 的分析型查询、ORM 的在线查询等场景中,大多数操作都是查询而非写入,在这些场景中列式存储能取得更好的性能。像主流的 DBMS 一样,C-Store 支持标准的关系型模型。
就像本文开头即提到——列式存储不是新鲜事。C-Store 的主要贡献有以下几点:
通过精心设计的 Projection 同时实现列数据的多副本和多种索引方式;
用读写分层的方式兼顾了(少量)写入的性能;
此外,C-Store 可能是第一个现代的列式存储数据库实现,其设计启发了无数后来的商业或开源数据库,就比如 Vertica。
数据模型
C-Store 是关系型数据库,它的逻辑表和其他数据库中的并没有什么不同。但是在 C-Store 内部,逻辑表被纵向拆分成 Projections,每个 Projection 可以包含一个或多个列,甚至可以包含来自其他逻辑表的列(构成索引)。当然,每个列至少会存在于一个 Projection 上。
下图的例子中,EMP 表被存储为 3 个 Projections,DEPT 被存储为 1 个 Projection。每个 Projection 按照各自的 Sort key 排序,在图中用下划线表示 Sort key。
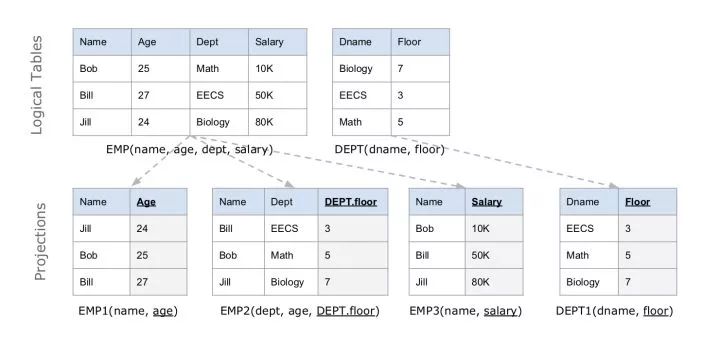
Projection 内是以列式存储的:里面的每个列分别用一个数据结构存放。为了避免列太长引起问题,也支持每个 Projection 以 Sort key 的值做横向切分。
查询时 C-Store 会先选择一组能覆盖结果中所有列的 Projections 集合作为 Covering set,然后进行 Join 计算重构出原来的行。为了能高效地进行 Projections 的 Join(即按照另一个 Key 重新排序),引入 Join Index 作为辅助,其中存储了 Proj1 到 Proj2 的下标映射关系。
Projection 是有冗余性的,常常 1 个列会出现在多个 Projections 中,但是它们的顺序也就是 Sort key 并不相同,因此 C-Store 在查询时可以选用最优的一组 Projections,使得查询执行的代价最小。
巧妙的是,C-Store 的 Projection 冗余性还用来实现 K-safe 高可用(容忍最多 K 台机器故障),当部分节点宕机时,只要 C-Store 还能找到某个 Covering set 就能执行查询,虽然不一定是最优的 Covering set 组合。
从另一个角度看,C-Store 的 Projection 可以看作是一种物化(Materialized)的查询结果,即查询结果在查询执行前已经被预先计算好。并且由于每个列至少出现在一个 Projection 当中,没有必要再保存原来的逻辑表。
为任意查询预先计算好结果显然不现实,但是如果物化某些经常用到的中间视图,就能在预计算代价和查询代价之间获得一个平衡。C-Store 物化的正是以某个 Sort key 排好序(甚至 JOIN 了其他表)的一组列数据,同时预计算的还有 Join Index。
Apache ORC 最初是为支持 Hive 上的 OLAP 查询开发的一种文件格式,如今在 Hadoop 生态系统中有广泛的应用。ORC 支持各种格式的字段,包括常见的 Int、String 等,也包括 Struct、List、Map 等组合字段,字段的 meta 信息就放在 ORC 文件的尾部(这被称为自描述的)。
数据结构及索引
为分区构造索引是一种常见的优化方案,ORC 的数据结构分成以下 3 个层级,在每个层级上都有索引信息来加速查询:
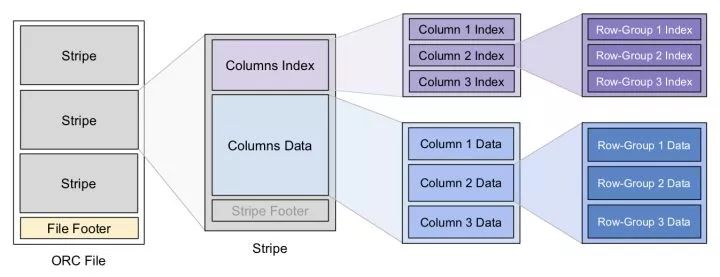
File Level:即一个 ORC 文件,Footer 中保存了数据的 meta 信息,还有文件数据的索引信息,例如各列数据的最大最小值(范围)、NULL 值分布、布隆过滤器等,这些信息可用来快速确定该文件是否包含要查询的数据。每个 ORC 文件中包含多个 Stripe。
Stripe Level:对应原表的一个范围分区,里面包含该分区内各列的值。每个 Stripe 也有自己的一个索引放在 Footer 里,和 File-Level 索引类似。
Row-Group Level :一列中的每 10000 行数据构成一个 Row-Group,每个 Row-Group 拥有自己的 Row-Level 索引,信息同上。
ORC 里的 Stripe 就像传统数据库的页,它是 ORC 文件批量读写的基本单位。这是由于分布式储存系统的读写延迟较大,一次 IO 操作只有批量读取一定量的数据才划算。这和按页读写磁盘的思路也有共通之处。
像其他很多储存格式一样,ORC 选择将统计数据和 Metadata 放在 File 和 Stripe 的尾部而不是头部。
但 ORC 在 Stripe 的读写上还有一点优化,那就是把分区粒度小于 Stripe 的结构(如 Column 和 Row-Group)的索引统一抽取出来放到 Stripe 的头部。这是因为在批处理计算中一般是把整个 Stripe 读入批量处理的,将这些索引抽取出来可以减少在批处理场景下需要的 IO(批处理读取可以跳过这一部分)。
ACID 支持
Apache ORC 提供有限的 ACID 事务支持。受限于分布式文件系统的特点,文件不能随机写,那如何把修改保存下来呢?
类似于 LSM-Tree 中的 MVCC 那样,Writer 并不是直接修改数据,而是为每个事务生成一个 Delta 文件,文件中的修改被叠加在原始数据之上。当 Delta 文件越来越多时,通过 Minor Compaction 把连续多个 Delta 文件合成一个;当 Delta 变得很大时,再执行 Major Compaction 将Delta 和原始数据合并。
这种保持基线数据不变、分层叠加 Delta 数据的优化方式在列式存储系统中十分常见,是一种通用的解决思路。
别忘了 ORC 的 Delta 文件也是写入到分布式储存中的,因此每个 Delta 文件的内容不宜过短。这也解释了 ORC 文件虽然支持事务,但主要是对批量写入的事务比较友好,不适合频繁且细小地写入事务的原因。
Dremel 是 Google 研发的用于大规模只读数据的查询系统,用于进行快速的 Ad-Hoc 查询,弥补 MapReduce 交互式查询能力的不足。为了避免对数据的二次拷贝,Dremel 的数据就放在原处,通常是 GFS 这样的分布式文件系统,为此需要设计一种通用的文件格式。
Dremel 的系统设计和大多 OLAP 的列式数据库相比,并无太多创新点,但是其精巧的存储格式却变得流行起来,Apache Parquet 就是它的开源复刻版。要注意的是,Parquet 和 ORC 一样都是一种存储格式,而非完整的系统。
嵌套数据模型
Google 内部大量使用 Protobuf 作为跨平台、跨语言的数据序列化格式,相比 JSON 要更紧凑并具有更强的表达能力。Protobuf 不仅允许用户定义必须(Required)和可选(Optinal)字段,还允许用户定义 Repeated 字段,意味着该字段可以出现 0~N 次,类似变长数组。
Dremel 格式的设计目的就是按列来存储 Protobuf 的数据。由于 Repeated 字段的存在,这要比按列存储关系型的数据困难一些。一般的思路可能是用终止符表示每个 Repeat 结束,但是考虑到数据可能很稀疏,Dremel 引入了一种更为紧凑的格式。
作为例子,下图左半边展示了数据的 Schema 和 2 个 Document 的实例,右半边是序列化之后的各个列:
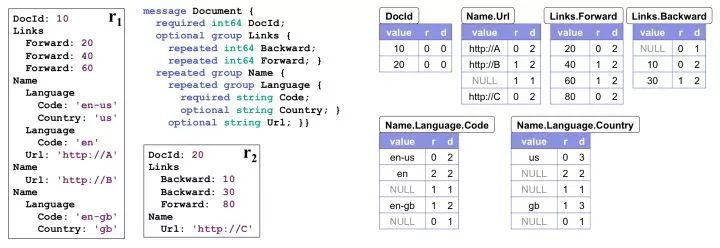
序列化之后的列多出了 R、D 两列,分别代表 Repetition Level 和 Definition Level,通过这两个值就能确保唯一地反序列化出原本的数据。
Repetition Level 表示当前值在哪一个级别上重复。对于非 Repeated 字段只要填上 Trivial 值 0 即可;否则,只要这个字段可能出现重复(无论本身是 Repeated 还是外层结构是 Repeated),应当为 R 填上当前值在哪一层上 Repeat。
举个例子说明,对于 Name.Language.Code 我们一共有三条非 NULL 的记录:
第一个是 en-us,出现在第一个 Name 的第一个 Lanuage 的第一个 Code 里面。在此之前,这三个元素是没有重复过的,都是第一次出现。所以其 R=0
第二个是 en,出现在下一个 Language 里面。也就是说 Language 是重复的元素。Name.Language.Code 中Language 排第二个,所以其 R=2
第三个是 en-gb,出现在下一个 Name 中,Name 是重复元素,排第一个,所以其 R=1
注意到 en-gb 是属于第3个 Name 的而非第2个Name,为了表达这个事实,我们在 en 和 en-gb中间放了一个 R=1 的 NULL。
Definition Level 是为了说明 NULL 被定义在哪一层,也就宣告那一层的 Repeat 到此为止。对于非 NULL 字段只要填上 Trivial 值,即数据本身所在的 Level 即可。
同样举个例子,对于 Name.Language.Country 列:
us 非 NULL 值填上 Country 字段的 Level 即 D=3
NULL 在 R1 内部,表示当前 Name 之内、后续所有 Language 都不含有 Country 字段,所以D为2。
NULL 在 R1 内部,表示当前 Document 之内、后续所有 Name 都不含有 Country 字段,所以D为1。
gb 非 NULL 值填上 Country 字段的 Level 即 D=3
NULL 在 R2 内部,表示后续所有 Document 都不含有 Country 字段,所以D为0。
可以证明,结合 R、D 两个数值一定能唯一构建出原始数据。为了高效编解码,Dremel 在执行时首先构建出状态机,之后利用状态机处理列数据。不仅如此,状态机还会结合查询需求和数据的 Structure 直接跳过无关的数据。
状态机实现可以说是 Dremel 论文的最大贡献。但是受限于篇幅,有兴趣的同学请参考文末的“文章参考”。
六、总结
本文介绍了列式存储的存储结构设计。抛开种种繁复的细节,我们看到,以下这些思想或设计是具有共性的:
跳过无关的数据。从行存到列存,就是消除了无关列的扫描;ORC 中通过三层索引信息,能快速跳过无关的数据分片。
编码既是压缩,也是索引。Dremel 中用精巧的嵌套编码避免了大量 NULL 的出现;C-Store 对 Distinct 值的编码同时也是对 Distinct 值的索引;PowerDrill 则将字典编码用到了极致。
假设数据不可变。无论 C-Store、Dremel 还是 ORC,它们的编码和压缩方式都完全不考虑数据更新。如果一定要有更新,暂时写到别处、读时合并即可。
数据分片。处理大规模数据,既要纵向切分也要横向切分,不必多说。
关于这类内容更多的思考,也欢迎大家来留言区进行交流。
参考文章:
Distinguishing Two Major Types of Column-Stores - Daniel Abadi
Columnar Storage - Amazon Redshift
Weaving Relations for Cache Performance - A Ailamaki, DJ DeWitt, MD Hill, M Skounakis
C-Store and Google BigTable - Greg Linden
The Design and Implementation of Modern Column-Oriented Database Systems - D Abadi, P Boncz, S Harizopoulos…
C-store: a column-oriented DBMS - M Stonebraker, DJ Abadi, A Batkin, X Chen…
Apache ORC Docs
Dremel: Interactive Analysis of Web-Scale Datasets - S Melnik, A Gubarev, JJ Long, G Romer…









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒