
本文根据潘安群老师在2017年12月3日【DBAplus数据库年终盘点大会】现场演讲内容整理而成。点击此处下载PPT~
今天在座的大部分嘉宾都是Oracle的专家,在Oracle的高可用、数据安全性等方面有着非常深厚的经验,而我所在的腾讯公司,在关系型数据库的使用场景下,基本还是以MySQL这套开源产品为主。
而MySQL这套开源产品,与Oracle这类成熟的商业产品在使用上或者说理念上有着很大的不同,所以我在这里会分享一下我所负责的分布式数据库产品TDSQL的十年研发运营之路,希望能给大家带来不一样的思路。
分享大纲:
腾讯十年数据库技术发展之路
TDSQL核心特性
分布式水平扩展
腾讯内部及部分客户的部署实践
腾讯数据库技术发展之路
我来自腾讯TEG计费平台部,一开始负责公司整个计费体系的存储系统研发,现在主要负责TDSQL数据库的研发。这是我们产品的几个发展阶段:

我是2007年进入公司的,在此之前公司业务是一个野蛮生长阶段,所以腾讯在数据库的高可用、安全性方面考虑不多,到了2007年左右,业务经历了第二次腾飞之前的一个平稳阶段。
趁这个时机,团队启动了一个7*24高可用服务项目,目标就是保证计费等公司级别敏感业务高可用、核心数据的零流失、核心交易的零错账。这也是TDSQL的前身。
当时提出的解决方案更多还是在应用层解决,两个DB之间数据如果不同步,则会在业务层锁定,在出现故障时做主备切换,并让没有同步完数据的用户交易不可用,其它用户正常交易。按照CAP原理来理解就是:当故障(P)出现时,我们牺牲少数用户的可用性(A),来保证100%的数据一致性(C)。
在业务层做有一个非常大的好处——能够知道锁什么样的数据,但如果当时在数据库层面做的话,必须考虑到业务会涉及到很多张表的数据,非常不好做。
这里面最大的弊端就是——对应用层来说耦合度太高了,包括数据层的容灾,比方说主DB异常了要去切换到备机时,什么时候检测故障?什么时候是真的故障了?什么时候切换?怎么做切换逻辑?这个逻辑是业务开发人员控制的,所以落地时间周期很长。因为一个系统完成改造,并通过多次现网演练最终到达稳定且符合预期,需要非常长的时间才能搞定,而我们系统又非常多,是一个非常艰难的过程。
到了2009年,考虑到这样的高一致性解决方案易用性并不好,我们基于类似思路做了一套KeyValue系统,这比研发一套SQL系统要简单很多,但依然有一个问题,KV系统不像SQL是标准化的东西,而且功能没有SQL丰富,所以业务系统从SQL迁移到KV存储,相当于存储架构都改了。而我们线上业务是7*24服务的,所以改造及迁移工作量也比较大,推广时间周期依然长。
所以很自然地,在2012年左右,我们就想做一套基于SQL的分布式数据库,取名TDSQL,目标就是让数据库来解决高可用、数据一致性、水平伸缩这些问题,而让业务系统只需要关注业务逻辑。
2014年腾讯投资了微众银行筹备,它的定位是要做一家互联网金融科技银行,所以一开始确定架构是基于互联网架构去做的。在对比了很多公司内外多个数据库产品方案后发现,TDSQL刚好跟他们的场景是比较符合的,在高可用、数据一致性方面比较切合金融行业的需求,所以整个微众银行的核心交易系统所有的数据库全部都是基于TDSQL,在银行核心交易系统里用这样的架构在无论在当时还是现在来看,都还是开创性的。
在微众成功落地投产后,我们希望我们的产品能为更多金融机构提供服务,所以在15年在腾讯云上也发布该产品,现在我们提供公有云PaaS服务,也提供私有云产品。
以上就是腾讯十年的数据库技术发展之路,接下来是今天分享的重点,我会先从TDSQL核心特性开始,然后讲讲分布式水平扩展,最后分享在腾讯内部以及在部分客户的部署实践。
一、核心特性
开源MySQL的玩法跟Oracle的确实有很大的差距,Oracle看起来就是一个高富帅,而MySQL看起来怎么也是一个经济适用男。例如我们支撑的业务以及客户,清一色的X86服务器,网络也是普通的专线网络,还是很经济实惠的。
所以有些传统企业的客户跟我们交流,问如果一台机器挂了怎么办?夸张一点来说,就是这台服务器咱就不要了,但这在Oracle生态下是不可能发生的事情。所以基于机器坏了就不要了的理念,在容灾方面上的设计就很不一样了。
此外,Oracle的功能确实非常强大,所以很多传统的运营商、银行客户过于依赖数据库,把大部分的逻辑都放在数据库层面,让数据库搞定,但MySQL很多时候搞不定这样的事情,所以互联网对数据库的依赖没有那么重,很多功能还是在业务层面做。
那像开源体系比较突出的一个问题是什么?就是坑特别多,在规模小的时候,可能问题不突出,一旦规模上去了,各种问题就蜂拥而至。官方团队对问题或Bug的响应是比较慢的,所以很多问题得需要自己去解决;而Oracle作为一家商业公司,相对来说就要好很多,基本上客户出了什么问题,都能比较快速的响应并协助解决。
所以这也是我们为什么将TDSQL在腾讯云上开发出来的一个目的,就是希望TDSQL在近十年在腾讯海量数据运营下走过的弯路、以及解决的问题,在其它团队不要再走一遍。
刚开始我们是定位金融这一块,这当中有几个问题必须要解决,一是高可用问题,二是数据可靠性、零丢失的问题。因为之前在行业内做分布式数据库的人认为,MySQL体系做不到数据零丢失或者是主备之间数据的一致性,但其实这个东西是没什么问题的,是完全可以做到的,看看我们是怎么做这个点的。
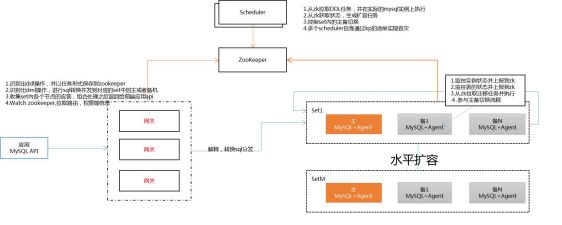
图:TDSQL核心架构
这是TDSQL的架构,现在分布式架构一般分为三个核心模块,第一模块是数据节点(上图右下角),通常是一主两备的方式。上面的两个模块组成调度系统,暂时是用ZooKeeper来做元数据管理。第三模块是接入计算层,当发生故障时主备切换和对路由的更新都在网关层面上做。上面的调度系统还包括负责监测故障、故障切换的操作,以及分布式场景下的扩缩容任务管理等,此外包括一些复杂SQL的重新以及计算工作。这是大体的核心架构。
我们再从右下角的Set讲起,通常是一主两备的方式。现在MySQL是两种复制模式,一种是异步复制,一种是半同步复制。但我们实测时会发现问题,当主备之间同步超时时,半同步复制会由超时时间退化为异步,这在金融场景下风险是比较大的。
按照CAP的原理,宁愿牺牲一定的可用性也不愿意把数据丢失,假设备机异常了,退化为异步了,主机继续交易。
如果此时主机再发生故障,数据库层面很可能出现数据丢失,一旦数据库层面出现数据丢失,事后要去修复是非常困难的,所以这种时候我们是不让它退化,继续强同步(可能交易失败),当然在具体实现时会做调整,根据业务特性去做配置设定是否退化异步。两个备机里只一个备机成功出现故障的概率会低很多,但不是说完全不会出现故障,但概率会低很多。
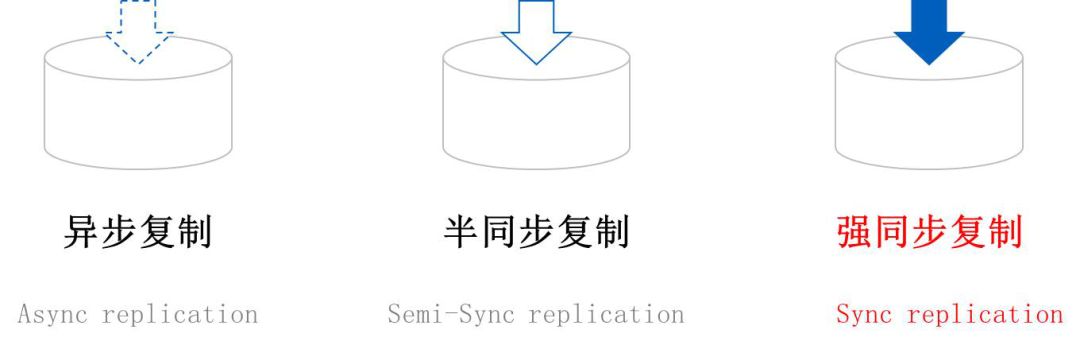
此外,在实际测试时做同城跨数据中心,这时的性能损耗会非常大,在MySQL 5.6版本性能损耗要降到原来的十分之一左右。现在5.7版本,在同步这里官方做了一些异步化处理,性能下降问题已经好很多了,但依然会有性能损耗。所以在复制这块,我们主要是去解决这两个问题。刚才讲的一主两备,两个备机是都做强同步复制的。

这是我们自己实测的结果,TPS下降非常快,所以我们做了两个异步化处理。
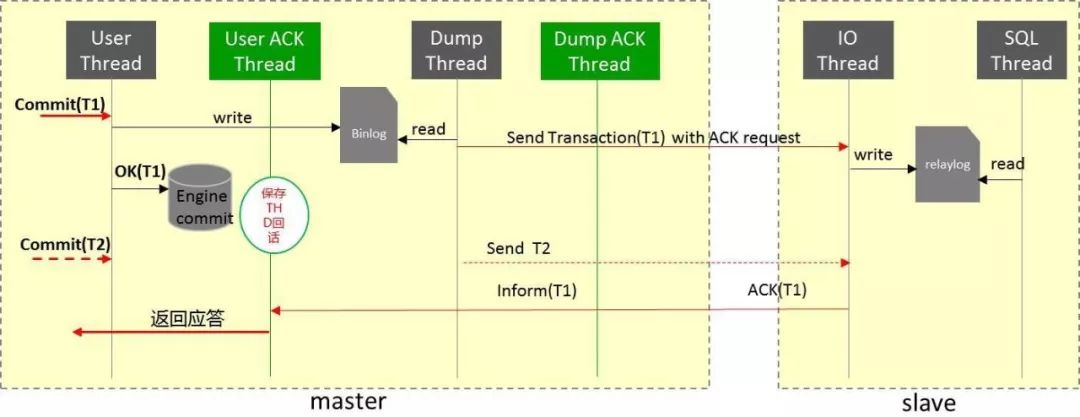
经过这些异步化改造,在性能方面我们目前可以做到同城跨数据中心,5毫秒以内的延迟的情况下,能够保证数据强同步和异步之间TPS不会下降,网络单笔时耗可能会增加,但增加网络延迟这是很正常的一种情况。也正是因为有了强同步TPS不会下降的问题,所以我们也敢在业务大规模推行同城三中心架构,这个架构我在下面会再具体展开讲。

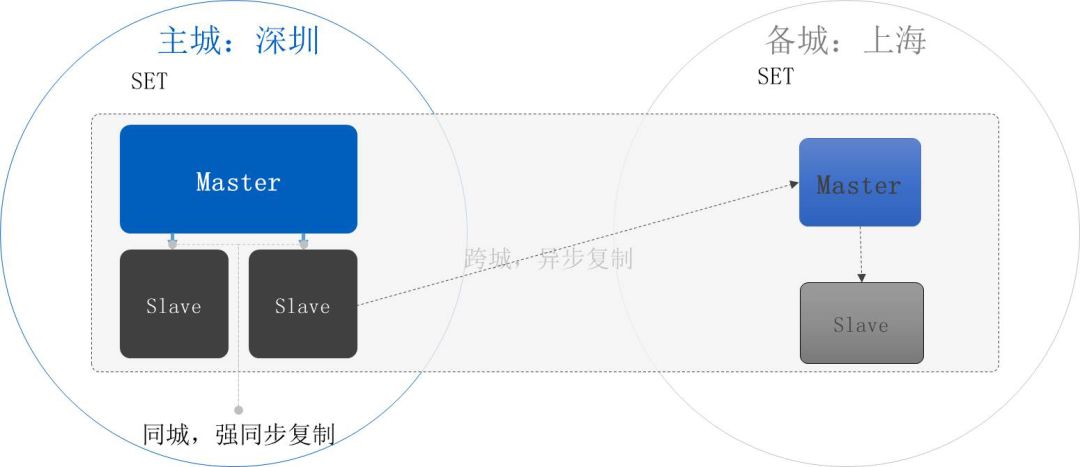
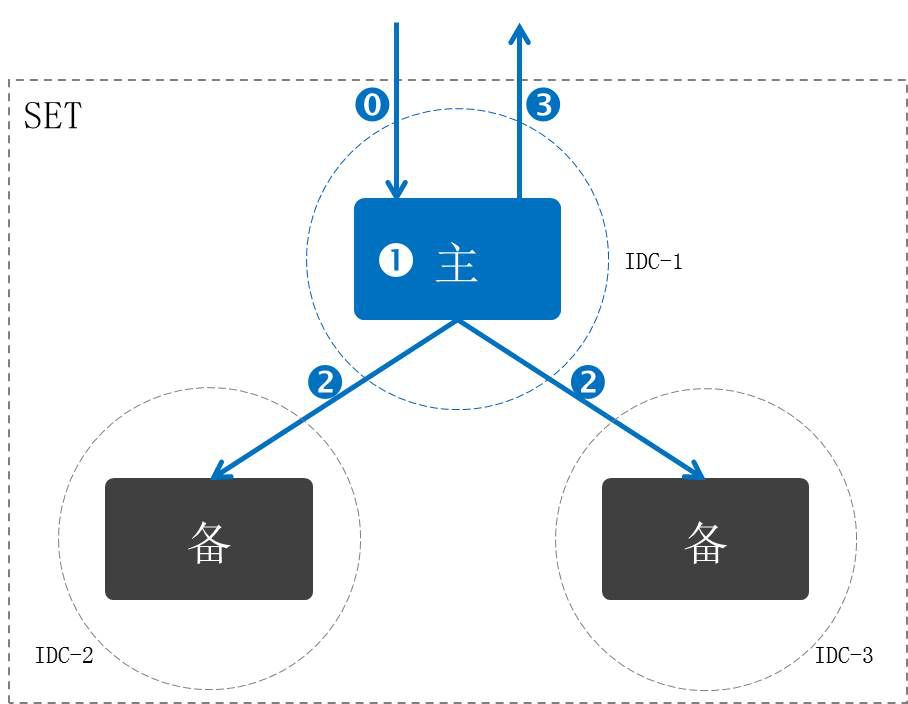
一般在同城三个数据中心之间一主两备,这三个数据节点放在三个数据中心。在这种情况下,做强同步任何一个数据中心异常都能够自动地切换过去,切换到另外的数据中心。所以这种可用度是非常高的。现在能够承诺的是同城做强同步的话可以到RTO 40秒,RPO为0。
在跨城通常还是做异步的同步,这里如果需要强行切换到跨城异地的备份中心,会有数据丢失的风险。当然这也是概率的问题,我们认为只有像在整个深圳三个数据中心全都挂掉了,或地震级别的灾难才会出现到这种情况,所以如果真要做跨城切换的情况下,有少量的数据丢失是可以接受的。
当然我们跟上海也可以做强同步,但有两方面的因素:
第一是做了强同步以后单笔请求的网络延迟就太大了,原来在同城做强同步可能只需要2-3毫秒的请求访问,但跨城的话至少要30-40毫秒。而且一笔交易往往涉及上百次数据库操作,这将是指数级的放大,会对前端业务系统的资源消耗非常严重,所以没有必要为了这样非常小概率的事情让平时的资源有这么大浪费。
第二是跨城网络稳定性会差很多,在腾讯同城内部数据中心是环形的专线网络,三个数据中心当中任何一条专线断了基本上不会有影响,所以同城的网络稳定性非常高,但跨城的网络稳定性就要差一些,而且经常有波动,所以我们也没有必要为了小概率事件做这样的操作,所以跨城做异步,依然是成本与系统可用性之间的一个平衡。
刚才我们在同城跨数据中心切换承诺的是40秒,为什么说是40秒呢?我们是分成了两部分,第一部分20秒是故障检测阶段,第二部分是服务恢复阶段,服务恢复阶段主要是根据Raft协议选主、等待数据回放完成等工作,我们保守一点承诺是20秒完成,不过在我们实际运营环境中,通常3-4秒就可以完成这些工作。相对来说,服务恢复阶段在业界是比较成熟的,理论也比较完备。
在这里我想重点要提一下故障检测阶段。其实故障检测是非常难的事情,首先我们都是基于X86的服务器,虽然现在服务器硬件一年比一年往上翻,性能越来越好,但实际上依然会有很多业务在上线时设计得不合理,每个用户来的时候都会做全表扫描,有时你根本防不胜防,如果稍微没注意放过去了就一下子把系统给冲垮了,整个数据库节点表现就是不可用了。
那么,在资源被消耗光的情况下要不要做切换?在业务看来,数据库基本上是不可用的,理论上是需要切换的,但是你切换后,发现没啥用,SQL请求里面又把新主机压垮了。
此外,我们现在普遍使用的SSD盘,SSD有一个问题是寿命的问题,坏也不是一下子突然坏了,这中间有一条曲线,IOPS和磁盘响应时间有一个逐渐变差的过程。那这种情况下怎么切,在什么时间点切换呢?
在故障检测这个点上,目前来看很难有统一的一个理论说怎么发现故障、怎么去切换,这是非常难的事情,更多还是经验方面的积累,我们秉承的原则还是:切换后,如果系统可用性能提升,才切,否则免切。这确实可以避免很多没有意义的切换。
故障检测时间是可以配置的,我们配置3秒钟一次监测,大概要连续6次出现异常情况才会去触发切换,而且连续6次的情况下还要匹配到自己内部的逻辑——是不是切换过去就能够解决问题,如果像刚才那种因为业务使用不当导致了系统数据库不用的话切过去也没什么用,在这种情况下不会做无谓的切换。
如果有时候系统出了问题可能会引发连续的切换,连续切换对系统也没什么好处,比如说我们切换了一次后,配置在未来的一段时间不会做切换,用这样的逻辑做判断。
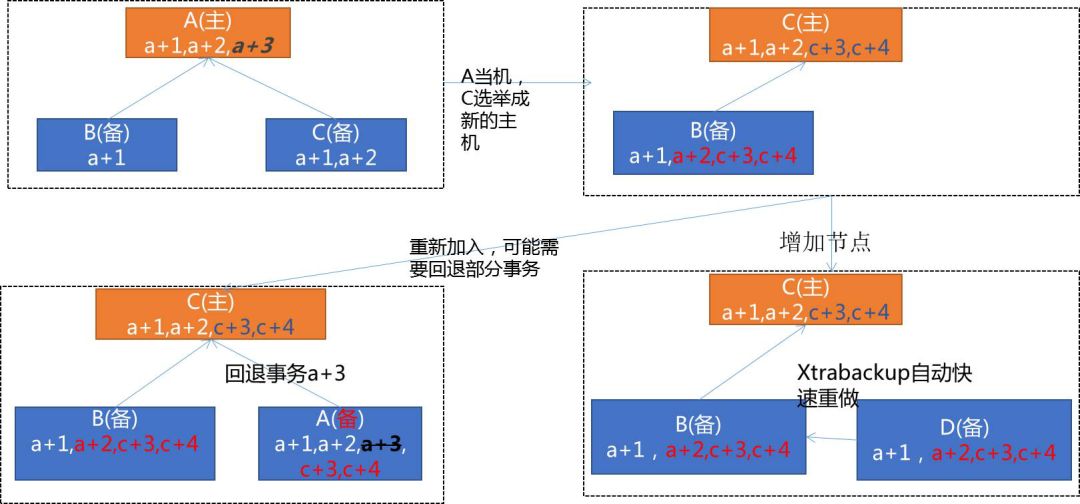
这里是我们在服务恢复阶段的示例演示。刚开始A是主机,B、C作为备机,而且B稍微延迟一些,C备机数据更新一点,此时a+3这个事务,依旧是未提交成功的,此时如果A主机故障了,那么调度系统会选择C作为新主机,B作为C的备机,组成一主一备的Set。
此时,我们会优先考虑,A节点是否能快速恢复(如MySQL bug,或者网络闪断等),如果能,则对a+3事务Rollback后,作为备机,继续提供服务;如果A节点不能快速恢复(如磁盘故障,服务器故障),则需要重新找一台服务器,通过物理备份+追Binlog的方式,快速构建一个新备机,尽可能地快速恢复为一主两备的三节点Set提供服务。
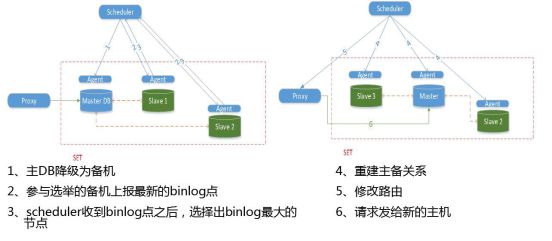
整个切换流程是一个严谨的操作,每个操作是有顺序的,否则可能会出现双写的情况,这都是靠切换流程来保障。
通常同城三中心架构,每个数据中心都是对等平等的。一旦因为故障,导致主备发生切换,除非再次发生故障,我们不会主动切换回来,这是同城三中心高度对等架构的好处。
任何一个中心的节点都可以提供主服务,这种更加标准化的部署,运维可以做到自动化操作,对运维管理的复杂程度要稍微低些。

这是冷备系统,每天会做全量的镜像,并实时做Binlog的增量备份,这些都会经过压缩后存储在分布式文件系统上,以便客户可以恢复到历史某一个时刻的数据点。目前我们在公有云上默认提供30天的任意时间点回档。
为什么需要每天做镜像呢?还是为了恢复的速度问题。比如说游戏出现了重大Bug需要快速回档,第二是DBA误操作删除数据了,这些情况都需要从冷备恢复。当然,每天一个镜像在一些情况下恢复时间也会比较长,假设每天凌晨4点钟做备份,但刚好在备份前一两个小时数据被删掉了,那这种恢复就需要用前一天凌晨4点的镜像数据,外加追一天的Binlog日志恢复,这个时间是比较长的。
在内部有类似事件的时候会有几个点从流程上优化:
第一点,一旦发现出现删数据的情况,无论是DBA误删还是因为系统内部Bug,一旦报了故障过来,立马申请新实例,并行开始恢复数据,不管最终会不会用上。
第二点,我们会有一个冷备验证环境,专门用于验证冷备系统及冷备数据的可用性。腾讯会有大量的数据库实例,每天随机挑选一些实例自动恢复,并跟现有生产环境去比对数据。我们要确保冷备备份出来的数据是可用的,我们通过这种随机抽查的冷备验证机制,确保整个冷备系统的可用性。
性能绝对数值本身没什么太大意义,不同的厂商可以用不同测试场景,发布对自己产品有利的数据。这里我想补充一点就是关于硬件。
硬件发展其实很快。大概两年前,我们自己内部用一个代号为Z3的服务器,大概1.3T SSD FusionIO卡。到了2017年年初,我们现在已经开始用上了TS85服务器,这种机型已经相当厉害了,是24个物理核,512G内存,4块1.8T NVME SSD卡,我们把它做成RAID 0,在数据库里很少有人说数据盘是用RAID 0的,但在我们架构里通常都是RAID 0。前提就是数据三副本,我们系统的可靠性及可用性不依赖单个副本,一个副本故障了就重新构建一个副本。

基于数据库账号的读写分离
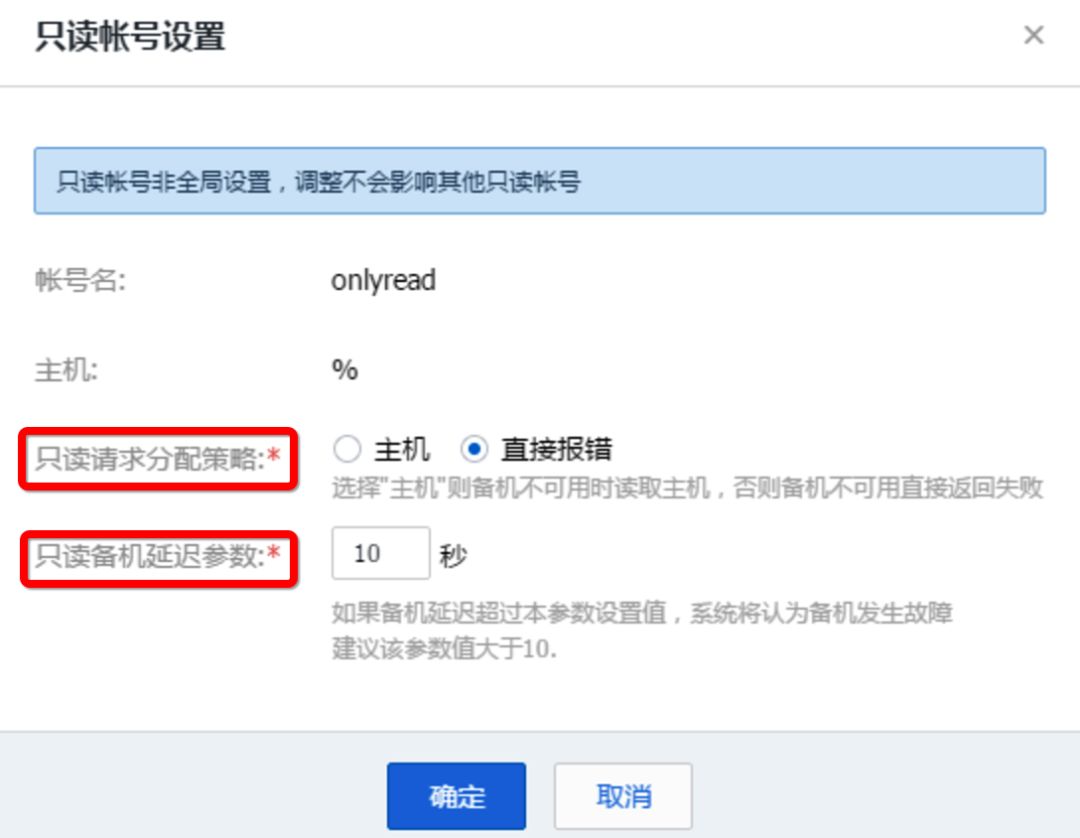
基于Hint的读写分离

二、分布式集群
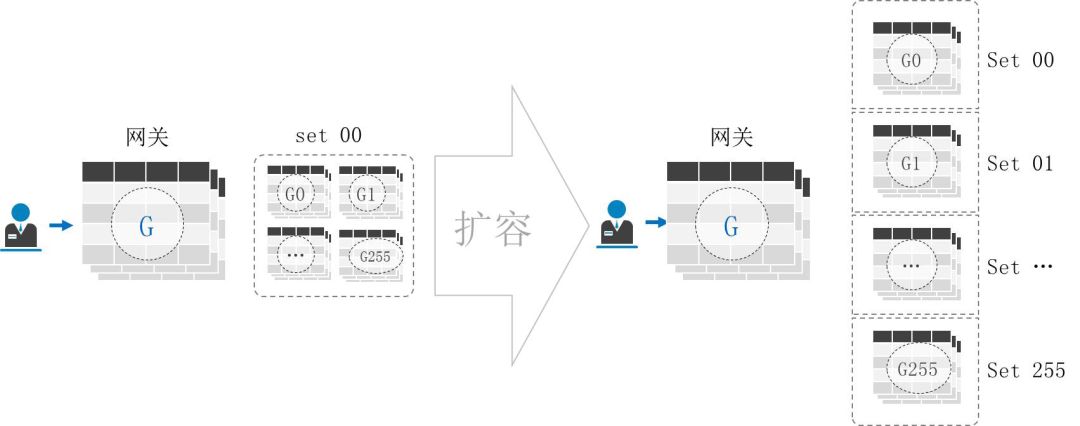
下面讲一下分布式实践。TDSQL一开始是定位在腾讯内部做计费、金融支付这类场景,是常见的OLTP场景。考虑到OLTP场景,一个系统的实时交易数据量并不会超级大,所以我们采用预分片的策略,一开始把数据帮你做好逻辑分片,例如设置为64个分片或者是128个分片,当然要做到1024个分片甚至更多都没什么问题,但通常来说用不了那么多分片。
你想想,单节点基于当前硬件可用是6T存储空间,如果达到128分片,就将近有大几百个T,对交易系统来说数据量是绝对够的。
为什么要做预分配呢?现在有很多数据库是自动扩容的,或者一开始做了哈希,但这类也会面临一个问题——数据大量地删除,如果仅仅删除一部分数据的话空间不一定会释放。所以一开始做好预分配在运营管理上会有非常大的方便,比如说你删除分区的话速度是非常快的,另外就是空间会立马得到释放,所以在运营层面会非常友好。
此外,有些表的数据没有必要做分布式,可能是配置表,所以会有广播小表或者是NoSharding表,这样做交易事务会非常方便。


MySQL本身在复杂SQL场景下处理会比Oracle差一些,尤其是在数据分析方面。但通常来说,标准的聚合函数都是没什么问题,我们现在也支持基于两阶段提交的分布式事务,但Join是有不同的。。
有很多场景下不让做Join,直接禁止一些复杂Join SQL。这里主要从系统可用性健壮性方面考虑,我们担心一旦放开限制,客户在自己测试环境测试,因为数据量小,所以性能啥都完全OK,但在实际生产环境中,数据量一旦上去了,数据库就扛不住,导致生产环境系统可用性降低,这是非常严重的问题。
如果后面万兆网卡普及的话,情况可能会有变化,但目前情况下,复杂关联查询SQL带来网络带宽消耗以及对中间节点存储内存消耗是需要去考虑的,绝对不能因为这些导致生产环境出现事故,所以我们前面限制非常严,存在风险的话都会限制住,让你在开发、测试的时候就能够发现、杜绝风险,避免承诺给你是可用的结果到最后发现不可用、线上容易出问题,否则对我们来说,承担的风险是非常大的。
所以我们更加偏向于保守一些,而且尽量地把错误在前面开发测试阶段发现,而不是到生产的时候才处理,当然我们也在逐步放开一些限制,在系统层面去做好控制、确保安全。

分布式事务最核心的点是异常处理。我们的分布式事务是基于两阶段提交的。做分布式系统最复杂的一个问题就是当出现网络故障、网络超时的情况时如何处理。
任何一笔网络请求可能有三种结果:正确、失败、超时。对于超时怎么处理是最关键的,所以我们有一套测试环境,专门随机模拟各种异常,包括网络、服务器各种情况下,用于验证我们分布式事务机制的健壮性。
第二点是分布式事务的死锁检测。我们在MySQL的锁信息里面增加上了分布式事务ID,在出现一定超时时间后,会主动去测试整个集群里面是否有多个事务之间占用的锁构成了环,也就是死锁,一旦出现死锁,我们会根据我们的策略,Kill掉某个事务,确保其它事务正常执行。
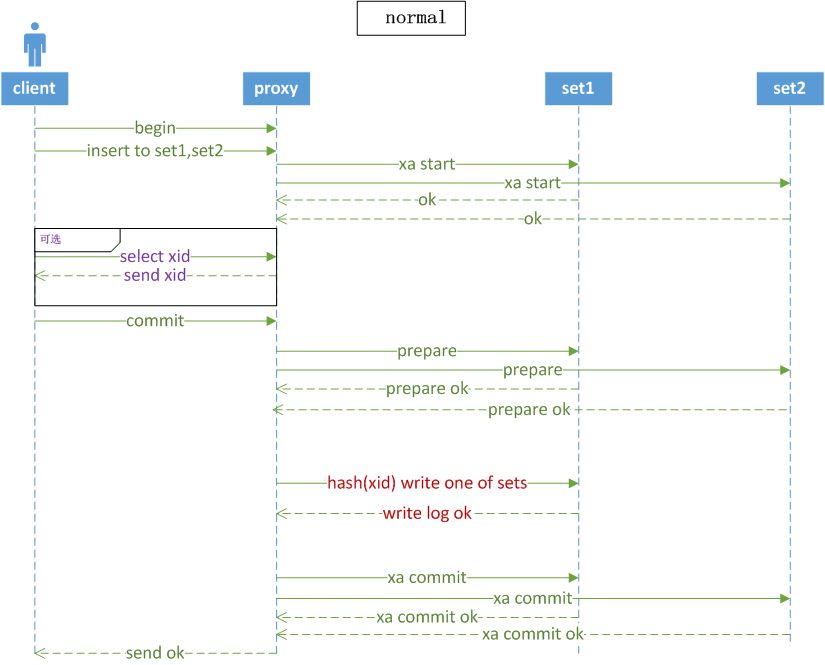

分布式事务不可避免是对性能的对比,目前我们的性能是损失大概是在30%左右,这是一个相当不错的性能了。而且TDSQL也是通过TPCC测试验证的。
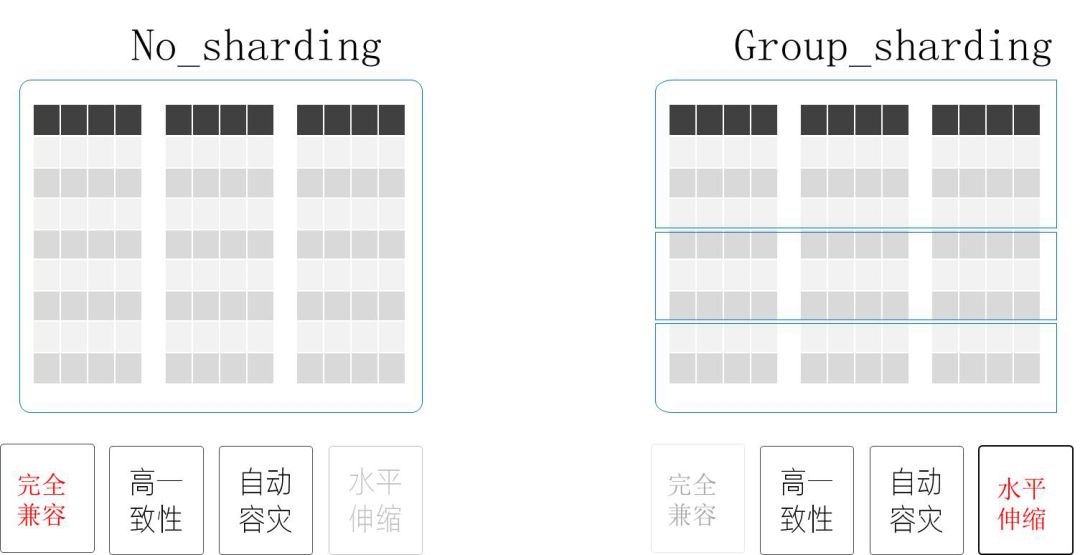
我们也提供了两个版本,一个是分布式版本,一个是No-sharding版本,如前面提到的在分布式版本里SQL会有一些限制,No-sharding提供的是完全SQL兼容的高可用方案。
前面也提到了MySQL和Oracle对比生态系统不够完善,Oracle的配套工具相当完善,此外就像Oracle有很多专家,客户出了什么问题,ITPUB发个帖子说有没有专家过来帮我解决问题,就会有很多专家过来解决,在MySQL体系下还没有这样的方法去处理。
确实周边配套、内部监控的处理包括本身的优化没有提供很好的工具,所以在这方面我们也投入了很大的精力。如果做产品化的话,这是非常重要的过程,无论是公有云还是私有云,目前提供给腾讯内部的其它业务也是云方式,整个这一套东西部署进去就能实现DBaaS服务,你可以直接购买TDSQL的实例应用。

三、部署实践
最后讲一下我们经常用的部署实践。
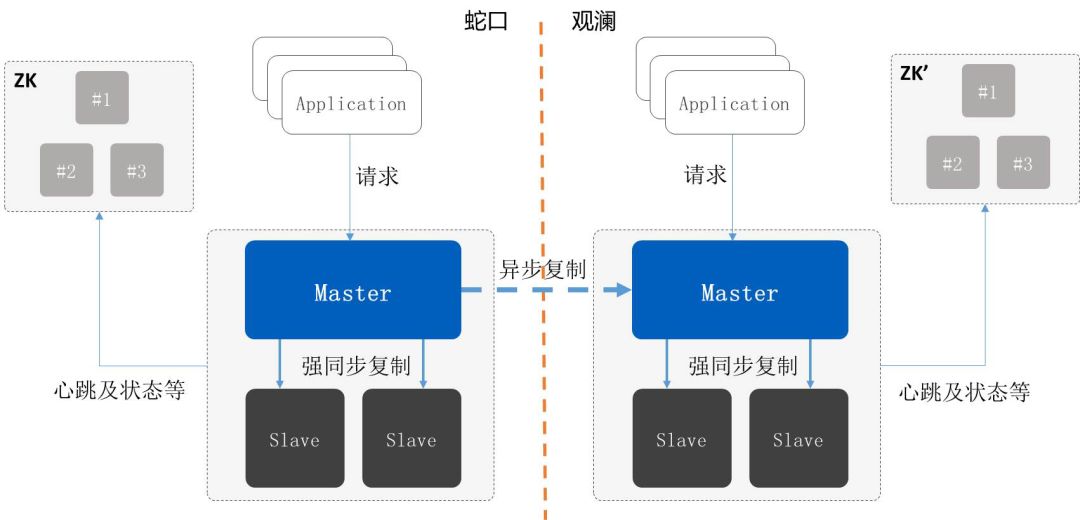
同城双中心没有什么很大的借鉴,这是微众银行最开始的架构。微众银行是全国第一家互联网新筹民营银行,所以是从零开始建构的,最开始的时候同城只有两个数据中心,最大的问题是出了故障时彼此都不知道到底是谁出了故障。
比如说网络数据中心的网络断了不知道谁出现了故障,所以同城不能自动切换,系统不知道谁出了问题,就需要人工去判断的。
但同一个数据中心内是可以做到切换的,像微众银行每个季度会做演练,因为两边都有数据中心、应用程序,所以每季度会跟监管机构申请窗口时间,比如说5分钟把业务停掉,等到数据全部传输到备中心以后验证是不是完整可用的。通过演练的方式确保备中心是可用的。
但今年微众银行已经彻底换成同城三中心架构,任一中心都可以切换,数据的架构看起来比较简单,可用性会好很多。这确实对成本的要求比较高,建设一个符合监管规范的金融级数据中心成本相当高,所以很多客户不愿意为了你再去搞多一个数据中心,只有微众是做类似金融科技才会搞三中心的架构。
微众当时评估成本,当它的账户量达到2000万以上时,单用户成本能够达到原来传统IOE架构的十分之一左右,越到后面用户量越增加就越划得来。
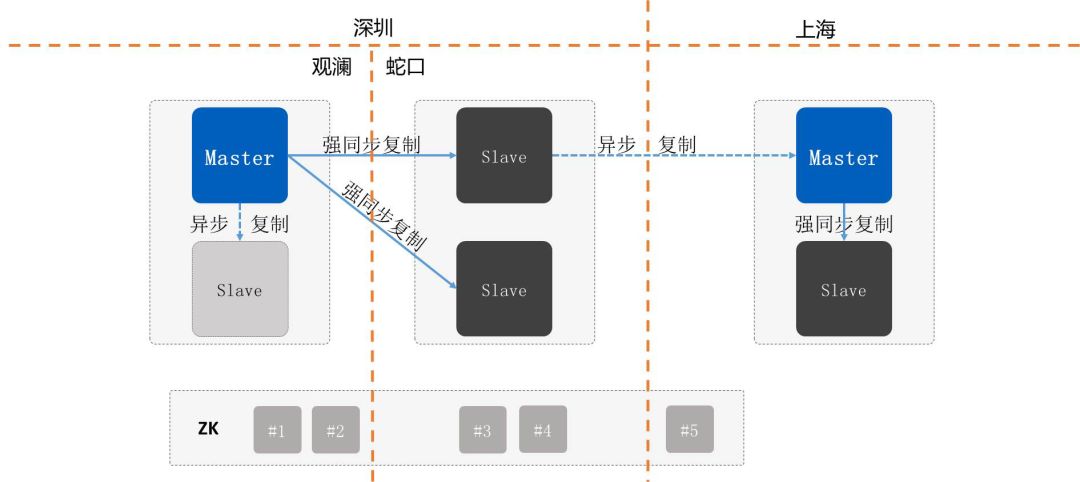
考虑到客户当前的数据中心及成本情况,更多的是客户会做两地三中心的架构,比如说深圳两个中心一主两备,通常在主数据中心会加一个备机,这个备机是为了做异步复制。
因为异步复制跟强同步复制本身上来说没有区别,所以异步大部分情况下数据也是最新的,如果真的主机出现故障要切换时会去优先选择本地备机,避免跨数据中心切换,如果数据确实跟其它的强同步节点最新的数据是一致的,当然没有异步节点也是没有什么问题的。

在腾讯内部通常就是这种部署架构,基本上能够满足大部分客户的需求。同城三个数据中心对等,任何数据中心及故障都能40秒内切换,数据零丢失,性能也稳定可靠,所以对业务来说是非常友好的。
今天和大家简单交流这些,若有疑问欢迎留言探讨,谢谢大家!









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒