
作者介绍
杨彪,蚂蚁金服技术专家,《分布式服务架构:原理、设计与实战》和《可伸缩服务架构:框架与中间件》作者。近10年互联网和游戏行业工作经验,曾在酷我音乐盒、人人游戏和掌趣科技等上市公司担任核心研发职位,做过日活跃用户量达千万的项目,也做过多款月流水千万以上的游戏。
本文节选自即将出版的《可伸缩服务架构:框架与中间件》一书,作者:李艳鹏、杨彪、李海亮、贾博岩、刘淏
如今,市面上的缓存解决方案已经逐步成熟了,今天我将选取其中一些代表性的方案包括Redis、Memcached和Tair进行对比,帮助大家在生产实践中更好地进行技术选型。
一、常用的分布式缓存的对比
常用的分布式缓存包括Redis、Memcached和阿里巴巴的Tair(见下表),因为Redis提供的数据结构比较丰富且简单易用,所以Redis的使用广泛。
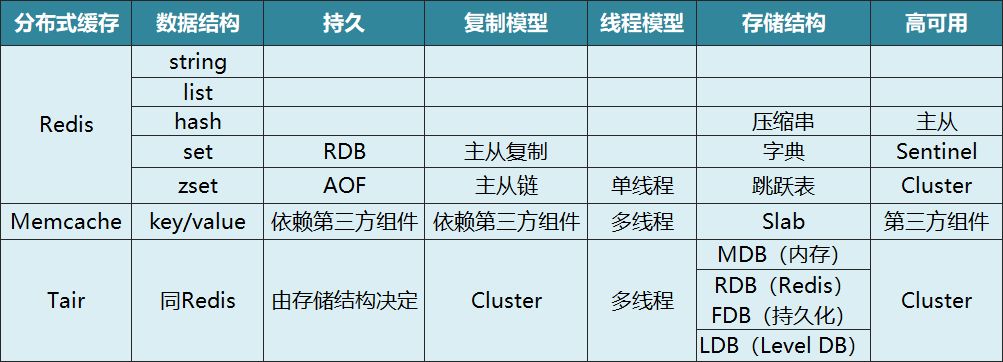
下面我们从9个大方面来对比最常用的Redis和Memcached。
Redis一共支持5种数据类型,每种数据类型对应不同的数据结构,有简单的String类型、压缩串、字典、跳跃表等。跳跃表是比较新型的数据结构,常用于高性能的查找,可以达到log2N的查询速度,而且跳跃表相对于红黑树,在更新时变更的节点较少,更易于实现并发操作。
Memcache只支持对键值对的存储,并不支持其它数据结构。
Redis使用单线程实现,Memcache等使用多线程实现,因此我们不推荐在Redis中存储太大的内容,否则会阻塞其它请求。
因为缓存操作都是内存操作,只有很少的计算操作,所以在单线程下性能很好。Redis实现的单线程的非阻塞网络I/O模型,适合快速地操作逻辑,有复杂的长逻辑时会影响性能。对于长逻辑应该配置多个实例来提高多核CPU的利用率,也就是说,可以使用单机器多端口来配置多个实例,官方的推荐是一台机器使用8个实例。
它实现的非阻塞I/O模型基于Libevent库中关于Epoll的两个文件加上自己简单实现的事件通知模型,简单小巧,作者的思想就是保持实现简单、减少依赖。由于在服务器中只有一个线程,因此提供了管道来合并请求和批量执行,缩短了通信消耗的时间。
Memcache也使用了非阻塞I/O模型,但是使用了多线程,可以应用于多种场景,请求的逻辑可大可小、可长可短,不会出现一个逻辑复杂的请求阻塞对其它请求的响应的场景。它直接依赖Libevent库实现,依赖比较复杂,损失了在一些特定环境下的高性能。
Redis提供了两种持久机制,包括RDB和AOF,前者是定时的持久机制,但在出现宕机时可能会出现数据丢失,后者是基于操作日志的持久机制。
Memcahe并不提供持久机制,因为Memache的设计理念就是设计一个单纯的缓存,缓存的数据都是临时的,不应该是持久的,也不应该是一个大数据的数据库,缓存未命中时回源查询数据库是天经地义的,但可以通过第三方库MemcacheDB来支持它的持久性。
常见的Redis Java客户端Jedis使用阻塞I/O,但可以配置连接池,并提供了一致性哈希分片的逻辑,也可以使用开源的客户端分片框架Redic。
Memecache的客户端包括Memcache Java Client、Spy Client、XMemcache等,Memcache Java Client使用阻塞I/O,而Spy Client/XMemcache使用非阻塞I/O。
我们知道,阻塞I/O不需要额外的线程,非阻塞I/O会开启额外的请求线程(在Boss线程池里)监听端口,一个请求在处理后就释放工作者线程(在Worker线程池中),请求线程在监听到有返回结果时,一旦有I/O返回结果就被唤醒,然后开始处理响应数据并写回网络Socket连接,所以从理论上来讲,非阻塞I/O的吞吐量和响应能力会更高。
Redis支持主从节点复制配置,从节点可使用RDB和缓存的AOF命令进行同步和恢复。Redis还支持Sentinel和Cluster(从3.0版本开始)等高可用集群方案。
Memecache不支持高可用模型,可使用第三方Megagent代理,当一个实例宕机时,可以连接另外一个实例来实现。
Redis本身支持lpush/brpop、publish/subscribe/psubscribe等队列和订阅模式。
Memcache不支持队列,可通过第三方MemcachQ来实现。
Redis提供了一些在一定程度上支持线程安全和事务的命令,例如:multi/exec、watch、inc等。由于Redis服务器是单线程的,任何单一请求的服务器操作命令都是原子的,但跨客户端的操作并不保证原子性,所以对于同一个连接的多个操作序列也不保证事务。
Memcached的单个命令也是线程安全的,单个连接的多个命令序列不是线程安全的,它也提供了inc等线程安全的自加命令,并提供了gets/cas保证线程安全。
Redis提供了丰富的淘汰策略,包括maxmemory、maxmemory-policy、volatile-lru、allkeys-lru、volatile-random、allkeys-random、volatile-ttl、noeviction(return error)等。
Memecache在容量达到指定值后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。在某些情况下LRU机制反倒会带来麻烦,会将不期待的数据从内存中清除,在这种情况下启动Memcache时,可以通过“M”参数禁止LRU算法。
Redis为了屏蔽不同平台之间的差异及统计内存占用量等,对内存分配函数进行了一层封装,在程序中统一使用zmalloc、zfree系列函数,这些函数位于zmalloc.h/zmalloc.c文件中。封装就是为了屏蔽底层平台的差异,同时方便自己实现相关的统计函数。具体的实现方式如下:
若系统中存在Google的TC_MALLOC库,则使用tc_malloc一族的函数代替原本的malloc一族的函数。
若当前系统是Mac系统,则使用系统的内存分配函数。
对于其它情况,在每一段分配好的空间前面同时多分配一个定长的字段,用来记录分配的空间大小,通过这种方式来实现简单有效的内存分配。
Memcache采用slab table的方式分配内存,首先把可得的内存按照不同的大小来分类,在使用时根据需求找到最接近于需求大小的块分配,来减少内存碎片,但是这需要进行合理配置才能达到效果。
从上面的对比可以看到,Redis在实现和使用上更简单,但是功能更强大,效率更高,应用也更广泛。下面将对Redis进行初步介绍,给初学者一个初体验式的学习引导。
二、Redis初体验
Redis是一个能够存储多种数据对象的开源Key-Value存储系统,使用ANSI C语言编写,可以仅仅当作内存数据库使用,也可以作为以日志为存储方式的数据库系统,并提供多种语言的API。
我们通常把Redis当作一个非本地缓存来使用,很少用到它的一些高级功能。在使用中最容易出问题的是用Redis来保存JSON数据,因为Redis不像Elasticsearch或者PostgreSQL那样可以很好地支持JSON数据。所以我们经常把JSON当作一个大的String直接放到Redis中,但现在的JSON数据都是连环嵌套的,每次更新时都要先获取整个JSON,然后更改其中一个字段再放上去。
一个常见的JSON数据的Java对象定义如下:
public class Commodity {
private long price;
private String title;
……
}
在海量请求的前提下,在Redis中每次更新一个字段,比如销量字段,都会产生较大的流量。在实际情况下,JSON字符串往往非常复杂,体积达到数百KB都是有可能的,导致在频繁更新数据时使网络I/O跑满,甚至导致系统超时、崩溃。
因此,Redis官方推荐采用哈希来保存对象,比如有3个商品对象,ID分别是123、124和12345,我们通过哈希把它们保存在Redis中,在更新其中的字段时可以这样做:
HSET commodity:123 price 100
HSET commodity:124 price 101
HSET commodity:12345 price 101
HSET commodity:123 title banana
HSET commodity:124 title apple
HSET commodity:12345 title orange
也就是说,用商品的类型名和ID组成一个Redis哈希对象的KEY。在获取某一属性时只需这样做就可以获取单独的属性:HGET commodity: 12345。
Redis官方推出了一个集群管理工具,叫作哨兵(Sentinel),负责在节点中选出主节点,按照分布式集群的管理办法来操作集群节点的上线、下线、监控、提醒、自动故障切换(主备切换),且实现了著名的RAFT选主协议,从而保证了系统选主的一致性。
这里给出一个哨兵的通用部署方案。哨兵节点一般至少要部署3份,可以和被监控的节点放在一个虚拟机中,常见的哨兵部署如图所示。
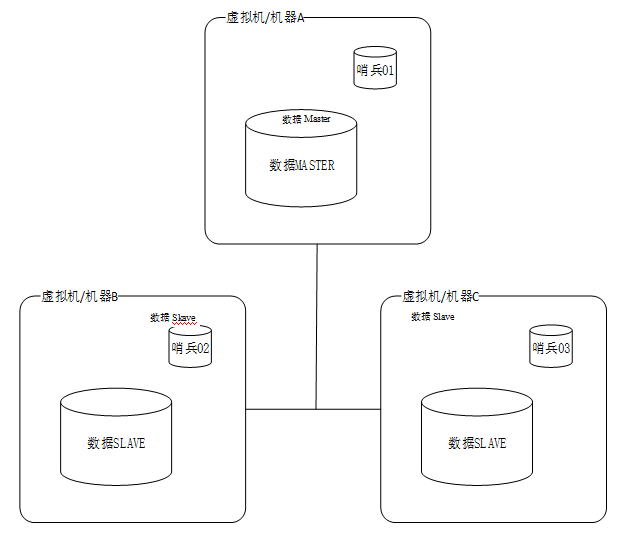
在这个系统中,初始状态下的机器A是主节点,机器B和机器C是从节点。
由于有3个哨兵节点,每个机器运行1个哨兵节点,所以这里设置quorum = 2,也就是在主节点无响应后,有至少两个哨兵无法与主节点通信,则认为主节点宕机,然后在从节点中选举新的主节点来使用。
在发生网络分区时,若机器A所在的主机网络不可用,则机器B和机器C上的两个Sentinel实例会启动failover并把机器B选举为主节点。
Sentinel集群的特性保证了机器B和机器C上的两个Sentinel实例得到了关于主节点的最新配置。但机器A上的Sentinel节点依然持有旧的配置,因为它与外界隔离了。
在网络恢复后,我们知道机器A上的Sentinel实例将会更新它的配置。但是,如果客户端所连接的主机节点也被网络隔离,则客户端将依然可以向机器A的Redis节点写数据,但在网络恢复后,机器A的Redis节点就会变成一个从节点,那么在网络隔离期间,客户端向机器A的Redis节点写入的数据将会丢失,这是不可避免的。
如果把Redis当作缓存来使用,那么我们也许能容忍这部分数据的丢失,但若把Redis当作一个存储系统来使用,就无法容忍这部分数据的丢失了,因为Redis采用的是异步复制,在这样的场景下无法避免数据的丢失。
在这里,我们可以通过以下配置来配置每个Redis实例,使得数据不会丢失:
min-slaves-to-write 1
min-slaves-max-lag 10
通过上面的配置,当一个Redis是主节点时,如果它不能向至少一个从节点写数据(上面的min-slaves-to-write指定了slave的数量),则它将会拒绝接收客户端的写请求。由于复制是异步的,所以主节点无法向从节点写数据就意味着从节点要么断开了连接,要么没在指定的时间内向主节点发送同步数据的请求。
所以,采用这样的配置可排除网络分区后主节点被孤立但仍然写入数据,从而导致数据丢失的场景。
Redis在3.0中也引入了集群的概念,用于解决一些大数据量和高可用的问题,但是,为了达到高性能的目的,集群不是强一致性的,使用的是异步复制,在数据到主节点后,主节点返回成功,数据被异步地复制给从节点。
首先,我们来学习Redis的集群分片机制。Redis使用CRC16(key) mod 16384进行分片,一共分16384个哈希槽,比如若集群有3个节点,则我们按照如下规则分配哈希槽:
A节点包含0-5500的哈希槽;
B节点包含5500-11000的哈希槽;
C节点包含11000-16384的哈希槽。
这里设置了3个主节点和3个从节点,集群分片如图所示。
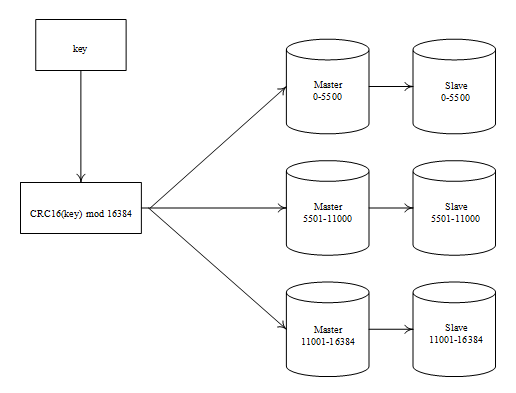
图中共有3个Redis主从服务器的复制节点,其中任意两个节点之间都是相互连通的,客户端可以与其中任意一个节点相连接,然后访问集群中的任意一个节点,对其进行存取和其他操作。
那Redis是怎么做到的呢?首先,在Redis的每个节点上都会存储哈希槽信息,我们可以将它理解为是一个可以存储两个数值的变量,这个变量的取值范围是0-16383。根据这些信息,我们就可以找到每个节点负责的哈希槽,进而找到数据所在的节点。
Redis集群实际上是一个集群管理的插件,当我们提供一个存取的关键字时,就会根据CRC16的算法得出一个结果,然后把结果除以16384求余数,这样每个关键字都会对应一个编号为0-16383的哈希槽,通过这个值找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。但是这些都是由集群的内部机制实现的,我们不需要手工实现。









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒