
本文根据张小虎老师在2017年12月3日【DBAplus数据库年终盘点大会】现场演讲内容整理而成。点击文末链接即可下载PPT~

今天我将和大家分享中国电信集团下属支付公司这一两年里做过的事情,讲一些我们实现的思路及过程,以及一些好玩的例子。
分享大纲:
上云之前需要做什么?
上云的最终决战八小时
上云之后还能再做什么?
一、上云之前需要做什么?
1、上云前夕-集团支付平台两地三中心整体规划
本人目前供职于甜橙金融信息技术部,从事运维及数据库工作有近7年的时间,在甜橙金融上云的过程中,除了机房设计外,我们在数据库层面上采用了一些业内比较有意思的技术。
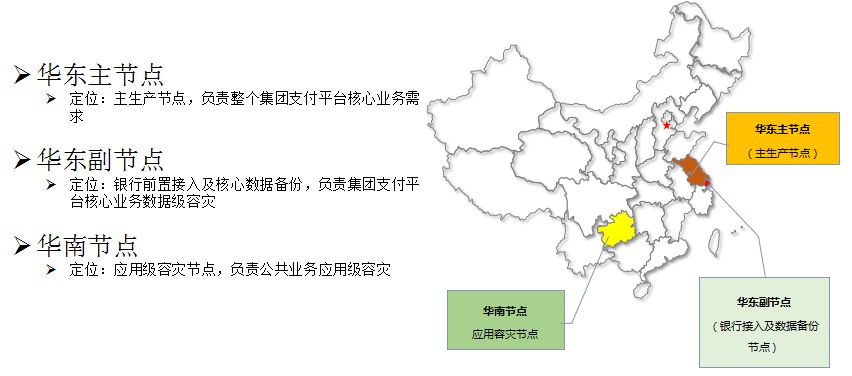
这是我们当前集团支付平台的IDC机房区域架构。如图所示,华东主节点定位为所有生产应用的主节点,这个节点当前承载了所有的生产业务量。华东副节点的定位主要是做数据级容灾。最后是今年正在建设的华南节点,用于公共业务应用级容灾。这样,在建设全部完成后,甜橙金融将形成两地三中心的机房布局。在应用容灾、数据容灾上都可以满足央行对我们的各项监管要求。
2、上云前夕-我们存在的问题
在此之前,给大家说说上云之前,作为一个有传统行业背景的新晋互联网金融公司所需要面对的问题。
在支付公司发展的6年时间里,遇到的问题有:
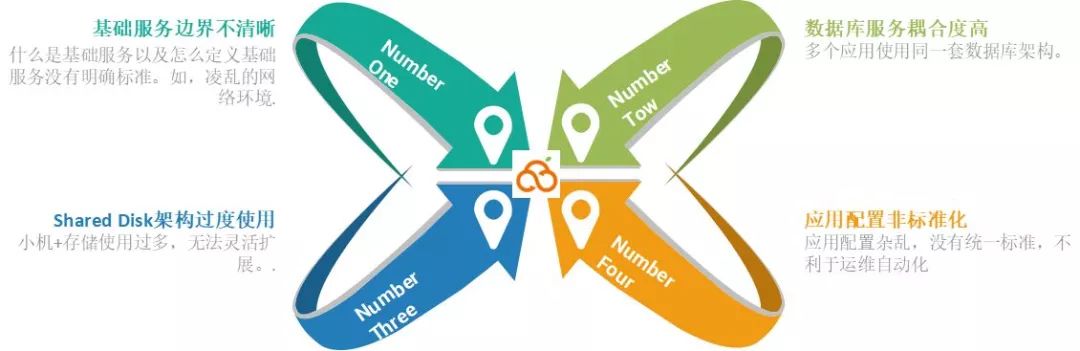
(1)基础服务边界不清晰
业内定义的基础服务没有统一标准,就我的理解来说,所有的网络、系统、服务器、硬件设施层面都可以盘点为基础服务。
在上云之前,支付公司的基础服务是非常零乱的。因为在业务发展初期,由于资源分配等原因,导致了数据系统资源在华东和华南均有分布,且基于这些数据系统资源的公司各业务系统也相对独立。由于缺乏标准化和规范化的设计,在业务快速发展过程中,出现了由基础服务边界不清晰、数据库服务耦合度高、传统数据架构无法灵活扩展等引起的各种问题,给我们的日常运维工作及新增业务需求等带来了极大的困难和阻力。
因此,基础环境的边界不清晰是在上云前最急需解决的问题。
(2)数据库服务耦合度太高
一个公司从小做到大一定会有架构上的变化,对于架构上的变化,我们要主动拥抱,这不仅体现了一个公司技术上的演进,也体现了公司业务上的发展程度。
支付公司在前几年的发展过程中处于人力资源比较粗放的发展,那时为了扩展业务,提高自身品牌的知名度,需要尽快推动产品发布。因此,过度的资源开销是必然的。每一个应用系统都着急上线,每一个应用系统对应着一套数据库,或者是若干个应用系统对应着一套数据库。甚至还有多套应用系统使用同一个用户,这种已经超限的数据库服务设计也给我们后续的迁移造成了一定困难。
不过,发展过程中的技术欠债是必须要还的,这也是这次上云的主要目的之一。
(3)Shared Disk架构过度使用
我们小机加存储的数据库架构特别多。这种数据库架构在早期的优点确实很明显,比如部署迅速、统一规划等。但在业务发展中后期,它的缺点就开始逐渐显现了,如成本高昂、扩展困难、人力迭代等,都不适合互联网金融业务中快速迭代的发展特点。
这种Shared Disk架构的过度使用,使得一些非核心业务逐渐成为核心业务的累赘。如果一套高端存储设备的价格在400万左右,那么连同小机在内的硬件设备上的开销就要将近千万。这对于一些只是存放日志信息的边缘应用来说无疑成本巨大。
Shared Disk架构还存在设计及布线繁琐等弊病。所以我的小机和存储之间还要架设光交,这样额外引入的一台网络设备会给整个数据库架构中增加额外的故障点。
(4)应用配置的非标准化
按照我的理解,上云就应该是一次标准化和规范化的过程。那么非标应用会带来什么影响呢?A应用和B应用使用的都可能是同一套数据存储,但应用底层的数据库连接池,一个采用了JDBC,另一个采用了c3p0。再比如服务的调用上,在改造Dubbo之前,我们甚至有应用是直接通过F5来做服务转发。这都是不可想象的。所以,为所有的应用在配置、服务调用等层面进行标准化改造,是我们在后续上云时需要着手解决的另一个问题。
3、上云前夕-准备工作
明确上述的4个问题后,我们用了近8个月的时间着手去解决它们:
(1)明确基础服务边界
在这个过程中,我们在集团内部、支付公司内部通过内部讨论,还和行业大牛做过交流,最终生成一套自己的基础服务边界规范。除了刚刚提到的,系统、网络、数据库、连接池的资源也被我定义为基础服务。我们通过各种域划分、资源划分,在底层形成了相对统一且相互隔离的基础服务环境。
(2)数据库服务资源解耦
这个阶段,我们先把所有的IP直连方式、DBLINK等全部干掉,设置内部DNS Server,改由域名进行数据库服务连接。之后,针对所有业务系统做了全面梳理,开始在业务层面进行垂直拆分,根据垂直拆分的结果,最终把业务所属的数据库环境解耦掉。让不同的业务只能访问自己的库,只能使用自己的用户。
(3)“部分”去存储
不管怎样,Shared Disk架构还是有优点的,只是看用在什么地方。所谓技术方案的制定一定要针对相应的业务。因此像价格比较昂贵、性能优异、数据一致性要求高的核心业务可以继续使用高端存储;而像产品层的各种非核心业务则从shared disk架构中剥离,转而改造为其它的开源解决方案。
(4)标准化改造
这个改造过程是对应用、中间件、系统、数据库进行的全盘改造。包括Dubbo在内的多种技术方案形成了属于我们自己的标准,这为上云后的DBaaS方案奠定基础。
4、上云前夕-面临的困难
(1)南京机房的网络布局
上云的整个过程中,最基础的莫过于风火水电的机房建设以及机房网络设计。机房的网络就形如人类的骨架,一个好的网络设计可以为后续的服务搭建打好基础。如果说整个运维系统、网络、数据库最开始建设的永远是网络,没有好的网络环境,或者是网络环境不够清晰,就相当于人的骨骼出现了偏移,人长得再健壮也没用,可能我一脚就把你踹倒在地上了。
在整个机房建设的过程中,为了机房选址问题,我们的团队几乎走遍了半个中国。在机房网络架构设计中,经过多方调研,我们开始和思科进行了比较深度的合作。现在,我们是全球第三个大规模采用了思科ACI网络技术的公司。我们成功实施的案例也已经被思科收入到服务案例当中。
(2)跨千公里数据同步
其次需要解决的是跨千公里数据中心之间的数据同步。这里的数据同步我们采用了两种方式:第一种方式是针对所有的核心业务系统,我们设计并实现了基于Oracle ADG技术的四层数据同步架构,这种架构在我们的切换演练中可以做到数据零丢失,并且切换速度非常快。第二种方式是对非核心的产品层业务,这里采用的是MongoDB+MySQL的方式,通过我们自己开发的数据同步工具进行同步。
(3)“部分”去存储后的技术选型
最后在“部分”去存储后的技术选型,我们把自己开发或者是二次开发的开源软件全部标准化后投入生产系统。比如我们在账单的应用上部署MongoDB,在风控规则中使用Redis Cluster等。通过不同的应用场景,使用不同的数据库技术解决方案。而不再无脑地采用小机加存储的结构。
5、上云前夕-跨千公里数据同步方案设计
在我们的南京大二层网络架构搭建时,在设计整个网络架构当中充分考虑到了可能会出现域划分不清晰的问题,所以我们在最初设计时,人为地拆成了三层,从最底层的数据网、向上的管理网及业务层网。在建设完成后,在网络环境上已经达到了多租户隔离效果,我们把各类资源通过EPG域划分结合在一起,这样就从网络物理层面上完成了资源隔离。

这是当时四层ADG数据同步的拓扑图,原华南和华东的数据中心通过ADG技术将压缩后的日志通过专线把生产数据从B层向南京节点进行转发。这一过程是持续的。除了原始数据的处理可能需要大量时间外,已经进入同步状态后,异地机房中的数据近乎完全同步。这一状态也是整个割接前夕的标准状态。
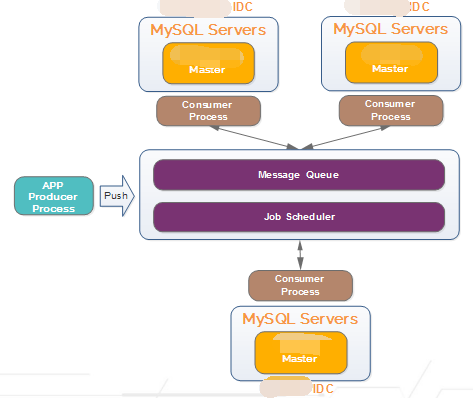
我们的MySQL同步采用如上方式实现。所有的前端应用作为生产者将数据变更写入消息队列中,各IDC机房中的消费者来负责生产数据的最终持久化。这套工具完全由我们自行研发。
6、上云前夕-合理去O,引入更多开源解决方案
上云之后所拥抱的开源解决方案:

首先MySQL生态圈中,除了各类开源解决方案外,在异地数据同步处理中我们也使用了一些阿里的开源技术,比如Canal。不过我们针对Canal有一些二次开发的工作,以令其适应我们自身的环境。
在NoSQL技术中,我们除了通过自动化运维平台管理200多套Redis哨兵架构外,还在几个重点项目里,采用不同大小的Redis Cluster集群。比如我们在风控系统里,就采用了9实机27个节点的大集群,其平均负载基本上维持在50%以上,机器使用率也较之前有大幅提高。
另外,我们还引入了MongoDB的新技术栈。用来处理一些非结构化的数据展示,如账单。同时,我们还自研了集群管理模块,实现在自动化运维平台上对Redis集群、MongoDB集群进行一键平滑扩缩容。
在数据分片中间件上,当前的MyCAT使用比较重,这可能是我们后面要着重解决的问题之一。我们修复了MyCAT的一些Bug,删除了一些我们认为无用的功能,比如当多个MyCAT同时进行DDL时会出现信号量超时问题等。
在上云迁移后,由于MyCAT相对于所有的运维人员来说确实太难维护,我们现在开始着手改造为Sharding-JDBC。所以在明年的计划里,我们会在Sharding-JDBC做比较多的二次开发。
最后是定制化的监控开发,我们知道面对云环境,当你对所有资源进行容器化时,你会发现监控系统如果不配合云环境进行改造的话会非常痛苦。如果每一个虚拟出来的容器都要手动添加监控的话,怎么对外宣称已经做到平滑扩缩容?
于是我们基于Zabbix已经做了非常多的二次开发。结合Zabbix的Discovery功能,我们已可以在虚机划分或各类服务推送完成后,就能识别所推送的服务类型并自动导入相应的监控模板。当前我们的监控系统承载的nvps非常大,所监控的实机大概在2000台左右,虚机的话我就不说了,我们实虚比大约在1:6。
二、上云的最终决战八小时
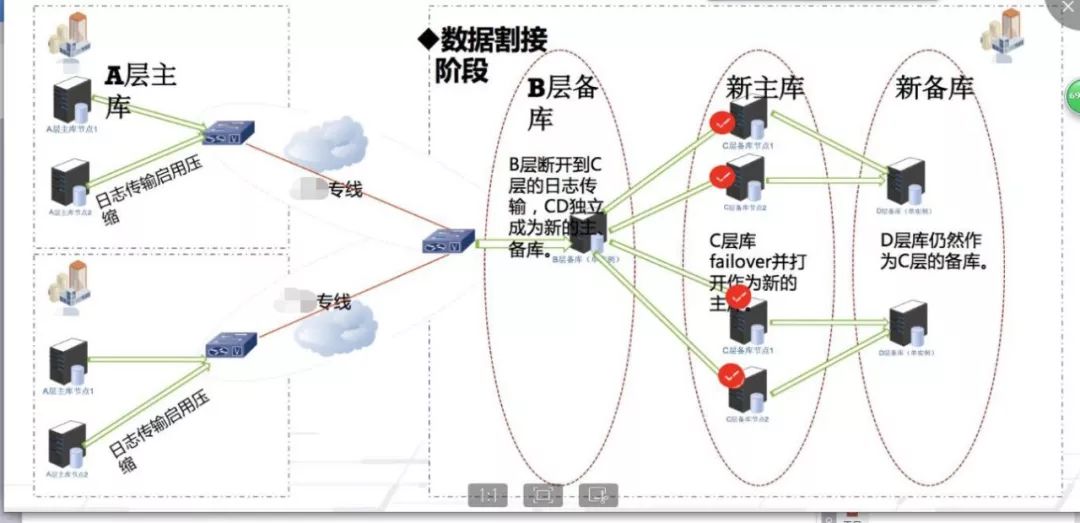
上图展示的是我们上云八小时决战。整个上云操作在和各省公司密切沟通过后,最终确认在2016年10月底进行。所有业务给出的真实割接时间只有两个半小时,完整数据量在150T左右。我们前期进行了4轮各种情况下的割接演练,做了这么多的工作就是为了在最后2.5小时里得瑟一下。
随着割接总指挥的一声令下,操作人员只是点了一下鼠标,就看着进度条一点一点往前推。
说实话,数据割接是我最有把握的。我们自动化平台里的实现逻辑经过了多次讨论订正,简单来说就是B层断开到C层。数据的比对是经过了一套非常严密的算法。而割接真正结束以后,所有的B层备库也会同时被斩断,斩断后的新C层主库才会启用。
整个割接,从开始到结束,我的内心深处并没有太大波澜,毕竟已准备8个多月了,但事后真正回想起来还是有些后怕。比如,我们当时遇到了一个比较紧急的情况,个人账户的核心主库在当晚割接时有一个节点拉不起来了,在紧急维护了半个小时后,才把它拉起来。在最后复盘时,发现是因为自动化平台里的Bug,把没有起来的节点文件推错了。所以,自动化有利有弊,但如果用得好确实是非常好的方式。

整体迁移所有的生产数据150T左右,大数据平台在2P左右,迁移数据库有94套,耗时时间是在2.5小时内。数据校验采用了自研的方法,完成了1300多套规范审查,整个过程平滑切换,没有数据丢失。在所有南京应用上云割接操作以后,我们彻彻底底地摆脱了传统企业技术上落后挨打的局面。
上云后的效果很快就体现出来了。在2015年上云之前,每年的525大促都是所有技术人员的一场噩梦。活动开始时第一小时很正常,第二小时很正常,到第三小时一定死,机器扩不上去,用户无法登录,各种妖孽问题频出。当时扩容的时间有多长呢?从机房搬机器到机架上线插电,基本按天算。是不是很落后?都已到了2014年、2015年,互联网IT技术飞速发展,那个时候我们还在采用这种方式来做,非常落后,所以落后就要挨打,“525”活动只能在最后一刻完成指标。经过这些年我们技术人员的成长,我们决定通过技术改变这种状况。在2016年上云改造后,硬件资源入池时间只有15分钟,镜像虚拟好后加入到资源池扩资源,也就是在三五分钟之内。
三、上云之后还能再做什么?
1、上云后-集团支付平台DBaaS体系架构规划
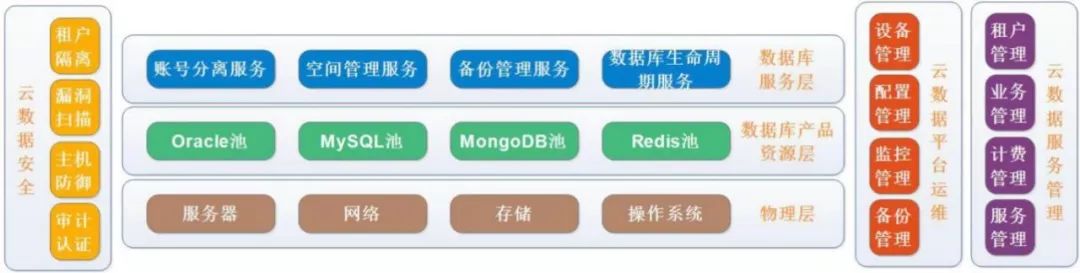
这是上云后我们规划的支付平台DBaaS架构图,最底层已经做好了IaaS的部分,数据库服务层是我们逐渐开始做的,我们计划把数据库服务包装虚拟化、容器化掉。云数据安全是和兄弟部门安全中心一起规划的,他们帮我们进行所有数据库层面上的隔离以及审批认证,这是最核心的两部分。
再看右边的云数据平台,已经成功上线大半年时间了,所有的机器管理、资产管理、自动化运维工作全部都在平台上得到有效的执行。
云数据服务是我们2018年的计划,主要还是根据支付公司系统内部来做,我们后面要对各划小事业群进行服务计费及流量管理。
2、上云后-集团支付平台DBaaS技术框架

这是现在的DBaaS技术架构图。最上面是门户界面,会访问所有DBaaS的Service,底层推送是在用Ansible。DBaaS Service会把资产管理一部分资产信息传递给当前资源池的API,如果说所有资源都合适的话就直接通过Ansible Server进行发送。
3、上云后-集团支付平台数据安全体系
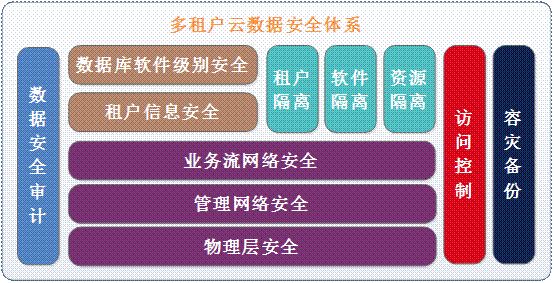
我们安全的同事说最好还是简单提一下云安全,因为如果真正对一个公司来讲,数据安全是无比重要的。安全同事从底层网络层的安全开始抓起,把所有的管理网段、业务网段进行了相应配置。
真正跟数据库相关的我认为主要还是租户隔离、软件隔离、资源隔离这部分,当然还包括备份。因为这些全部隔离好以后,数据服务才变成一个个独立的个体,你才能把这些服务下发给所有的想要使用的租户,而且租户和租户之间的信息不会有太大偏差。
4、上云后-集团支付平台数据平台运维
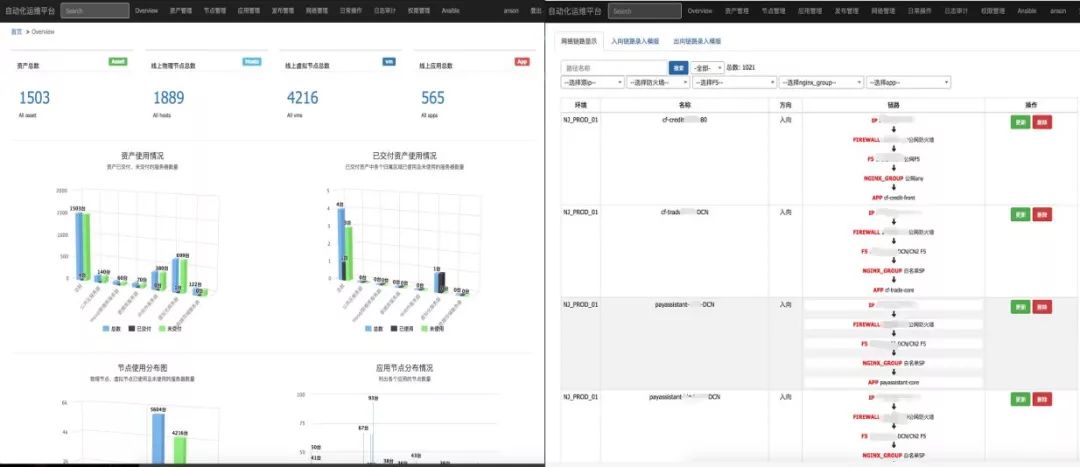
这是当前我们云平台的功能展示,我特别截了一下ACI网络的管理,已经可以达到完全自动化。比如现在我想把一台MongoDB的机器加入到新申请的节点,直接通过管理平台就可以把当前这一台MongoDB的机器划分到相应的EPG中。所有的虚机扩展包括划分应用都是采用类似的操作。
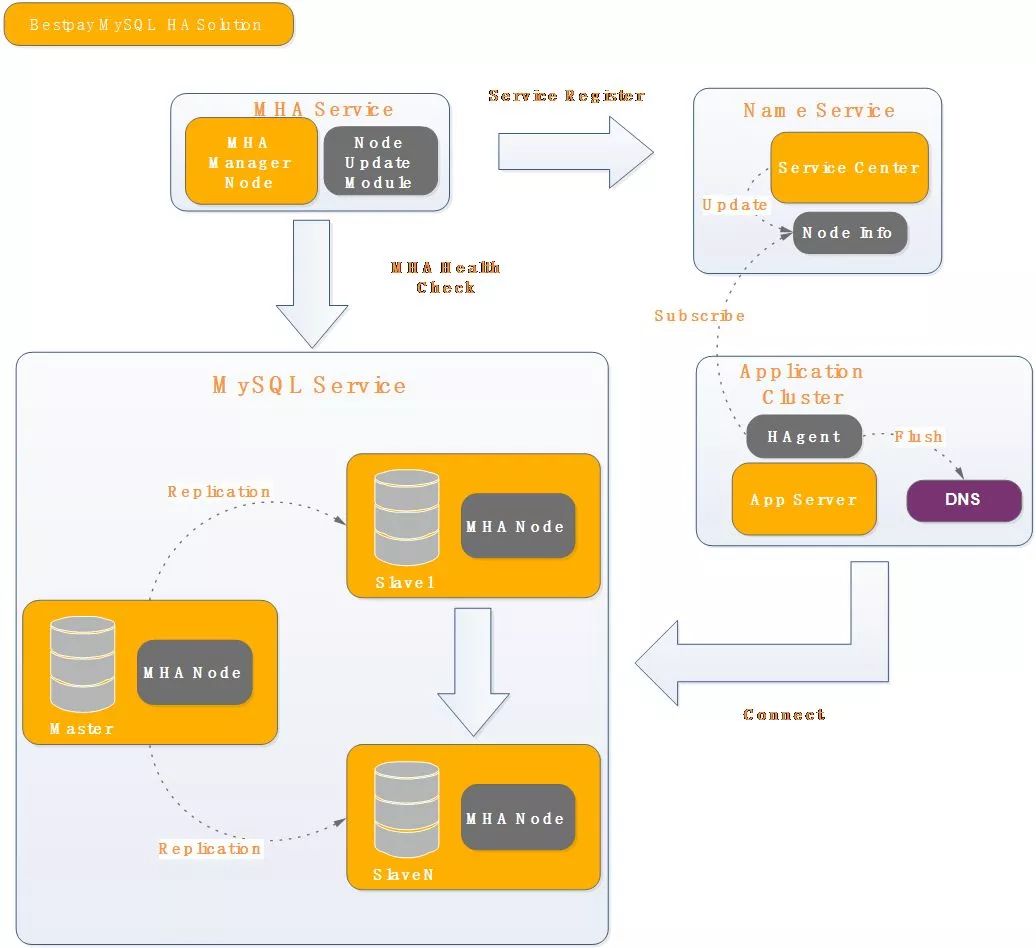
前段时间我在沙龙里介绍过我们对MHA的改造时,已经介绍过我们这块的工作。那时还只是刷新MHA自己的本地HOST文件。MHA还是有一点问题,比如说在真正切的时候还会出现日志追不上的情况。所以,我们现在把MHA服务化,增加一层DNS Service。ZK节点会把所有想要知道的域名信息推送给MHA,然后MHA所有底层的监控节点同步当前的信息就可以了。
5、上云后-服务高可用性-MySQL

这张图是现在列的的当前资源申请的流程图,所有管理员只负责资源入库,管理员是由工程部门来扮演的,工程部门把所有相应型号的数据库应用机器全部入池,会有类似的表格根据某一些表格的形式把机器入池。入池以后,会根据不同的业务需求推送成相应的服务,比如说有一些是需要部署Java,那就直接把Java给你推送出来。Redis和MongoDB也是一样的,如果紧急出现要预服务的话资源也能加的上去。
以前都是通过工单系统或者是纸质流程来完成资源的申请,现在是直接通过管理门户打给当前租户的领导,只要同意就直接把底层资源划掉。
今天的分享就到这里。若有疑问和探讨,欢迎留言交流。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721