
作者介绍
曹林华,现任沪江技术中心资深架构师,主要负责中间件产品设计与架构建设,承担了搜索平台、日志平台、分布式跟踪平台、实验平台等架构设计。曾任职百度高级工程师,主要负责大规模、高并发的消息推送技术研发工作。目前致力于解决分布式、高并发,大数据量等技术难题,持续优化公司基础架构产品。
高可用设计是互联网系统架构的基础之一,以天猫双十二交易数据为例,支付宝峰值支付次数超过 8 万笔。大家设想一下,如果这个时候系统出现不可用的情况,那后果将不可想象。而解决这个问题的根本,就是服务层的高可用。
众所周知,服务层主要用来处理网站业务逻辑,是大型业务网站的核心。比如下面三个业务系统就是典型的服务层,提供基础服务功能的聚合。
用户中心:主要负责用户注册、登录、获取用户信息功能;
交易中心:主要包括正向订单生成、逆向订单、查询、金额计算等功能;
支付中心:主要包括订单支付、收银台、对账等功能。

业务发展初期主要以业务为导向,一般采用 「ALL IN ONE」的架构方式来开发产品,这个阶段用一句话概括就是 「糙猛快」。当发展起来之后就会遇到下面这些问题
文件大:一个代码文件出现超过 2000 行以上;
耦合性严重:不相关业务都直接堆积在 Serivce 层中;
维护代价高:人员离职后,根本没有人了解里面的业务逻辑;
牵一发动全身:改动少量业务逻辑,需要重新把所有依赖包打包并发布。
遇到这些问题,主要还是通过「拆」来解决。
具体拆的方式,主要根据业务领域划分单元,进行垂直拆分。拆分开来的好处很明显,主要有以下这些:
每个业务一个独立的业务模块;
业务间完全解耦;
业务间互不影响;
业务模块独立;
单独开发、上线、运维;
效率高。
对于业务逻辑服务层,一般会设计成无状态化的服务,无状态化也就是服务模块只处理业务逻辑,而无需关心业务请求的上下文信息,所以无状态化的服务器之间是相互平等且独立的。
只有服务变为无状态的时候,故障转移才会变得很轻松。通常故障转移就是在某一个应用服务器不能服务用户请求的时候,通过负责均衡的方式,转移用户请求到其他应用服务器上来进行业务逻辑处理。
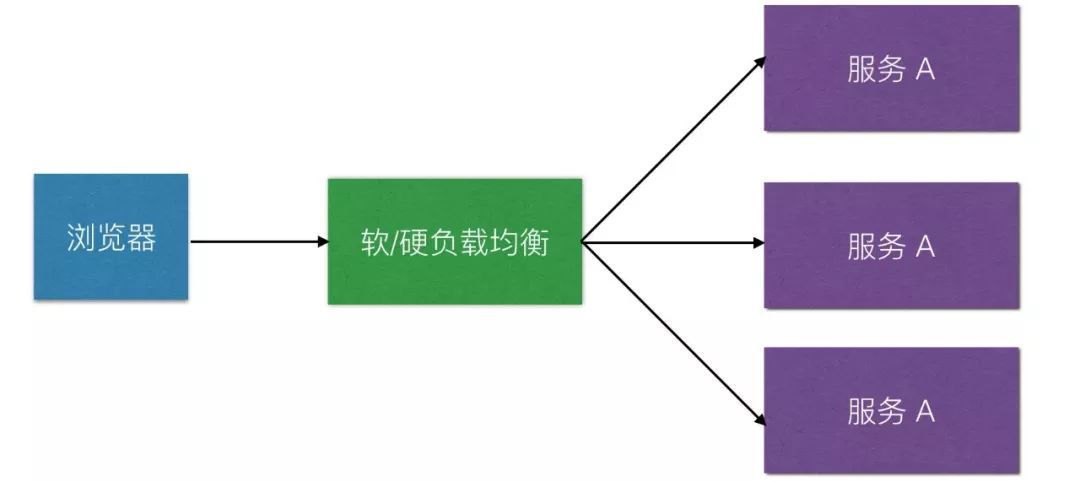
一般网站服务都会有主调服务和被调服务之分。超时设置就是主调服务在调用被调服务的时候,设置一个超时等待时间 Timeout。主调服务发现超时后,就进入超时处理流程。

主调服务 A 调用被调服务 B 时,设置超时等待时间为 3 秒,可能由于 B 服务宕机、网络情况不好或程序 BUG 之类,导致 B 服务不能及时响应 A 服务的调用;
此时 A 服务在等待 3 秒后,将触发超时逻辑而不再关心 B 服务的回复情况;
A 服务的超时逻辑可以依据情况而定,比如可以采取重试,对另一个对等的 B 服务去请求,或直接放弃结束这个请求调用。
超时设置的好处在于当某个服务不可用时,不至于整个系统发生雪崩反应。
一般请求调用分为同步与异步两种。同步请求就像打电话,需要实时响应,而异步请求就像发送邮件一样,不需要马上回复。
这两种调用各有优劣,主要看面对哪种业务场景。比如在面对并发性能要求比较高的场景,异步调用就比同步调用有比较大的优势,这就好比一个人不能同时打多个电话,但是可以发送很多邮件。
那我们什么时候该采用异步调用?
其实主要看业务场景,如果业务允许延迟处理,那就采用异步的方式处理。
那我们该怎么实现异步调用?
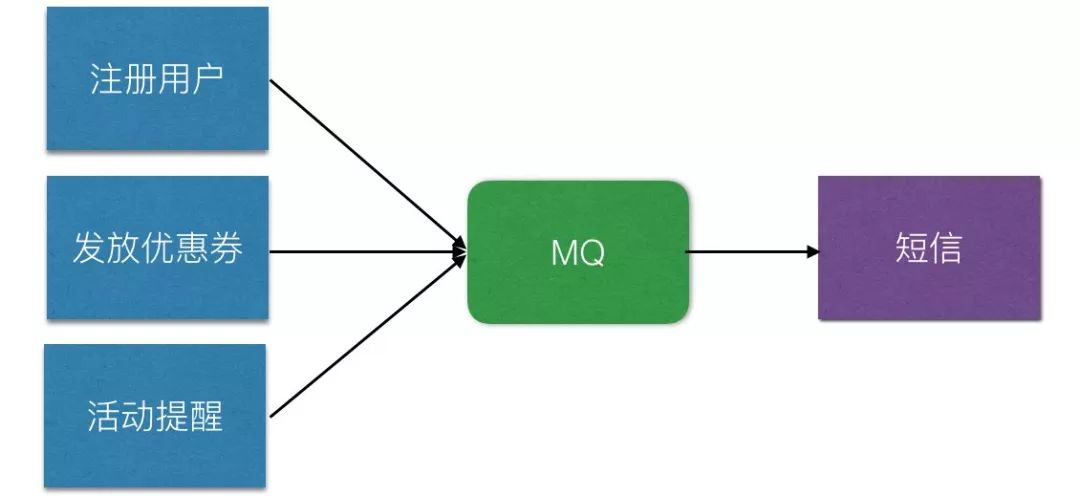
通常采用队列的方式来实现业务上的延迟处理,比如像订单中心调用配送中心,这种场景下面,业务是能接受延迟处理的。
消息队列主要有哪些功能?
异步处理 - 增加吞吐量;
削峰填谷 - 提高系统稳定性;
系统解耦 - 业务边界隔离;
数据同步 - 最终一致性保证。
到底有多少种队列?其实主要看处理业务的范围大小:
应用内部 - 采用线程池,比如 Java ThreadPool 中 BlockingQueue 来做任务级别的缓冲与处理;
应用外部 - 比如 RabbitMQ、ActiveMQ 就是做应用级别的队列,方便进行业务边界隔离与提高吞吐量。
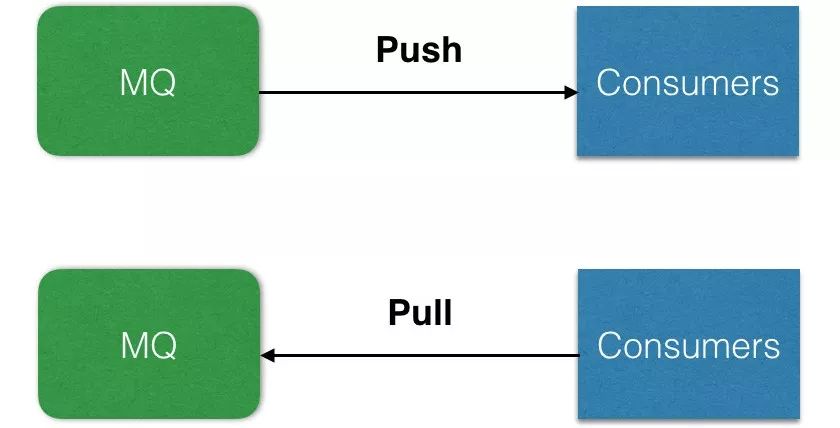
同时,技术上来讲,消息队列一般分为两种模型:Pull VS Push
Pull 模型:消费者主动请求消息队列,获取队列中的消息;
Push 模型:消息队列主动推送消息到消费者。
其中 Pull 模式可以控制消费速度,不必担心自己处理不了消息,只需要维护队列中偏移量 Offset。所以对于消费量有限并且推送到队列的生产者不均匀的情况下,采用 Pull 模式比较合适。
Push 比较适合实时性要求比较高的情况,只要生产者消息发送到消息队列中,队列就会主动 Push 消息到消费者。不过这种模式对消费者的能力要求就提高很多,如果出现队列给消费者推送一些不能处理的消息,消费者出现 Exception 情况下,就会再次入队列,造成消费堵塞的情况。
不过互联网业界比较成熟的队列主要以采用 Pull 模式为主,像 Kafka、RabbitMQ(两种方式都支持)、RocketMQ 等。
什么是幂等设计?
其实很简单,就是一次请求和多个请求的作用是一样的。用数学上的术语,即是 f(x) = f(f(x))。
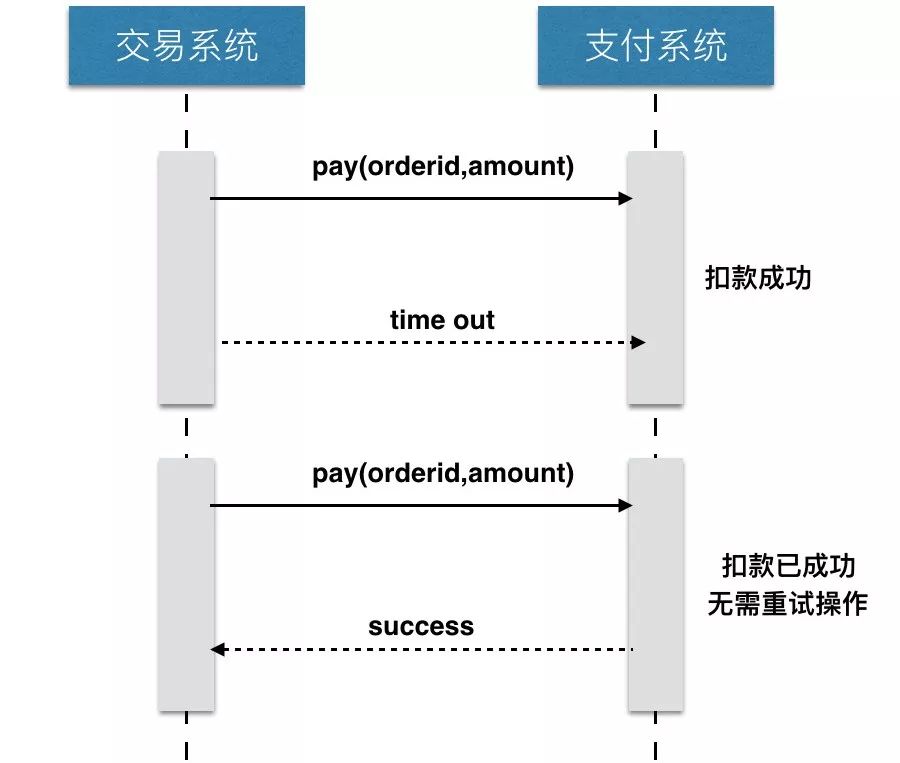
那我们为什么要做幂等性的设计呢?主要是因为现在的系统多是采用分布式的方式来设计,在分布式系统中调用一般分为 3 个状态:成功、失败、超时。
如果调用是成功或者失败都不要紧,因为状态是明确和清晰的,但如果出现超时的情况,就不知道请求是成功还是失败了。

如果出现这种情况,我们该怎么办?一般采取重试的操作,重新请求对应接口。如果请求接口是 Get 操作的话,那倒还好,因为请求多次的效果是一样的。但如果是 Post、Put 操作的话,就会造成数据不一致,甚至数据覆盖等问题。
举个例子:在支付收银台页面进行支付的时候,因为网络超时的问题导致支付失败,这时我们都会再进行一次支付操作,但是当支付成功后,如果发现你的账户余额被减了 2 次,心里肯定会很不爽。
造成这个问题的关键是:网络超时后,不知道支付是什么状态,是成功还是失败呢?所以说幂等性设计是必须的,尤其在电商、金融、银行等对数据要求比较高的行业中。
一般在这种场景下,我们该怎么解决?
请求方一般会生产一个唯一性 ID 标识,这个标识可以具有业务一样,比如订单号或者支付流水号,在发起请求时候带上唯一性 ID;
接收者在收到请求后,第一步通过获取唯一性 ID 来查询接收端是否有对应的记录。如果有的话,就直接将上次请求的结果返回;如果没有的话,就进行操作,并在操作完成后记录到对应的表里。
服务降级主要解决资源不足和访问量过大的问题,比如电商平台在 618、双十一等高峰时期采用部分服务不提供访问,减少对系统的影响。
降级的方式有哪些?
延迟服务:比如春晚,微信发红包就出现抢到红包,但是账号余额并没有增加,要过几天才能加上去。其实这是微信内部采用延迟服务的方式来保证服务的稳定,通过队列实现记录流水账单;
功能降级:停止不重要的功能是非常有用的方式,把相对不重要的功能暂停掉,让系统释放更多的资源。比如关闭相关文章的推荐、用户的评论功能等等,等高峰过去之后,在把服务恢复回来;
降低数据一致性:在大促的时候,我们发现页面上不显示真实库存的数据,只显示到底有还是没有库存这两种状态。
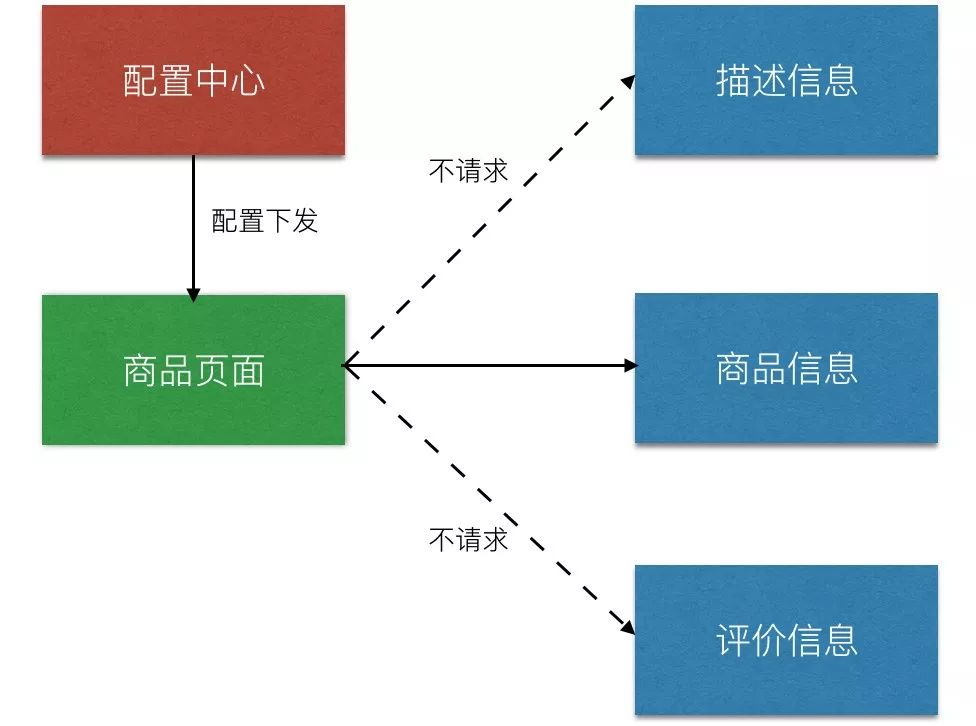
刚刚说了降级的方式,那操作降级时有哪些注意要点呢?
清晰定义降级级别: 比如出现吞吐量超过 X,单位时间内响应时间超过 Y 秒、失败次数超过 Z 次等,这些阈值需要在准备的时候,通过压测的方式来确定;
梳理业务级别:降级之前,首先需要确定哪些业务是必须有,哪些业务是可以有的,哪些业务是可有可无的;
降级开关:可以通过接入配置中心(比如携程 Apollo、百度 Disconf )的方式直接后台降级。但是如果公司没有配置中心的话,可以封装一个 API 接口来切分,不过该 API 接口要做成幂等的方式,同时需要做一些简单的签名,来保证其一定的安全性。
总结一下本文分享的主要内容:
整体架构:根据业务属性进行垂直拆分,减少项目依赖,单独开发、上线、运维;
无状态设计:应用服务中不能保存用户状态数据,如果有状态就会出现难以扩容、单点等问题;
超时设置:当某个服务不可用时,不至于整个系统发生连锁反应;
异步调用:同步调用改成异步调用,解决远程调用故障或调用超时对系统的影响;
服务降级:牺牲非核心业务,保证核心业务的高可用。
所有好的架构设计首要的原则并不是追求先进,而是合理性,要与公司的业务规模和发展趋势相匹配。任何一个公司,哪怕是现在看来规模非常大的公司,比如 BAT 之类,在一开始,其系统架构也应简单和清晰。









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒