

(点击底部获取贺春旸演讲完整PPT)
讲师介绍
贺春旸,《MySQL 管理之道:性能调优、高可用与监控》第一、二版一书作者,从事数据库管理工作多年,曾经任职于中国移动飞信,安卓机锋网,凡普金科(爱钱进),致力于MariaDB、MongoDB等开源技术的研究,主要负责数据库性能调优、监控和架构设计。
大家好,我是2015年7月份入职凡普金科(原普惠金融)爱钱进,公司核心数据库在我入职第二周,从最原始的MySQL 5.5.30社区版全部升级到MariaDB 10.0.21企业版,随后面的机房迁移,版本再次升级为MariaDB 10.0.30企业版。
为什么选择了MariaDB?
1、 业务上子查询SQL过多,需要大量改写为join关联查询语句,开发需要更改代码
在MariaDB 5.3版本里,就已经对子查询进行了优化,并采用semi join半连接方式将SQL改写为了表关联join,从而提高了查询速度。
通常情况下,我们希望由内到外,即先完成内表里的查询结果,然后驱动外查询的表,完成最终查询,但是MySQL 5.5会先扫描外表中的所有数据,每条数据将会传到内表中与之关联,如果外表很大的话,那么性能上将会很差。

案例:MySQL 5.5的子查询执行计划,是将in重写为exists
我们看一下这两个执行计划,当外表比较大时,第一行会扫描5000071行,改为exists写法,它的执行计划和in是完全一样的。如果你外表比较大的话,查询性能会是非常差的。

案例:MariaDB 10.0的子查询执行计划,是将in/exists重写为join
MariaDB 10.0相当于MySQL5.6版本,这里In和exists,它会直接重写为join关联查询,这里有三个不同的写法,执行计划是完全一样的。改写join以后是由小表关联大表,可以看下扫描的行数为10行,执行效率就是非常快的。
2、由于数据量上TB,直接升级MySQL5.6,不能平滑升级,需要进行一次mysqldump再导入,耗费过多的时间。
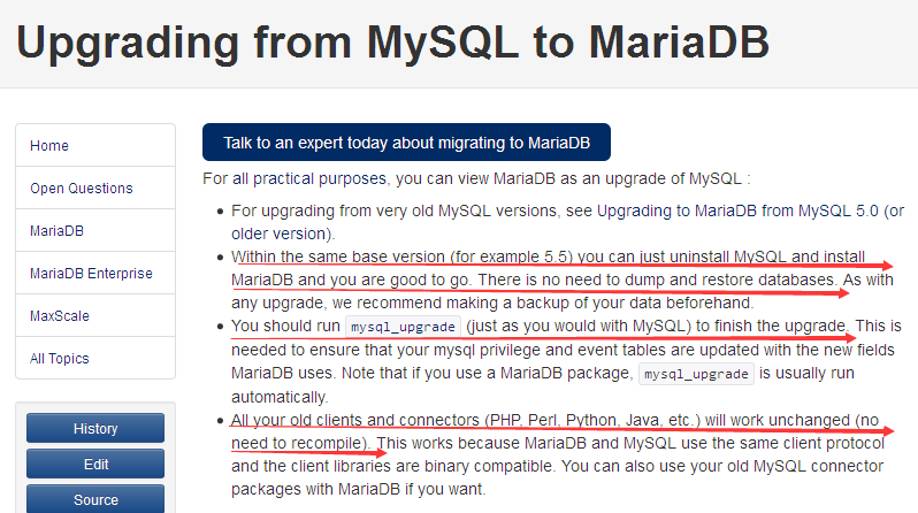
以MySQL5.5版本为例,若要升级到MySQL5.6,需要进行一次全库mysqldump导出再导入,当数据库很大时,比如100GB,升级起来会非常困难。但如果升级为MariaDB10,会非常轻松,按照官方文档阐述,只需把MySQL卸载掉,并用MariaDB启动,然后通过mysql_upgrade命令升级即可完成。
MariaDB跟MySQL在绝大多数方面是兼容的,对于前端应用(比如PHP、Perl、Python、Java、.NET、MyODBC、Ruby、MySQL C connector)来说,几乎感觉不到任何不同。

在处理内部的临时表,MariaDB 5.5/10.0用Aria引擎代替了MyISAM引擎,这将使某些GROUP BY和DISTINCT请求速度更快,因为Aria有比MyISAM更好的缓存机制。如果你的临时表很多的话,要增加aria_pagecache_buffer_size参数的值(缓存数据和索引),默认是128MB( 而不是tmp_table_size 参数)。如果你没有MyISAM表的话,建议把key_buffer_size调低,例如64KB,仅仅提供给MySQL库里面的系统表使用。
官方推荐使用jemalloc内存管理器获取更好的性能。
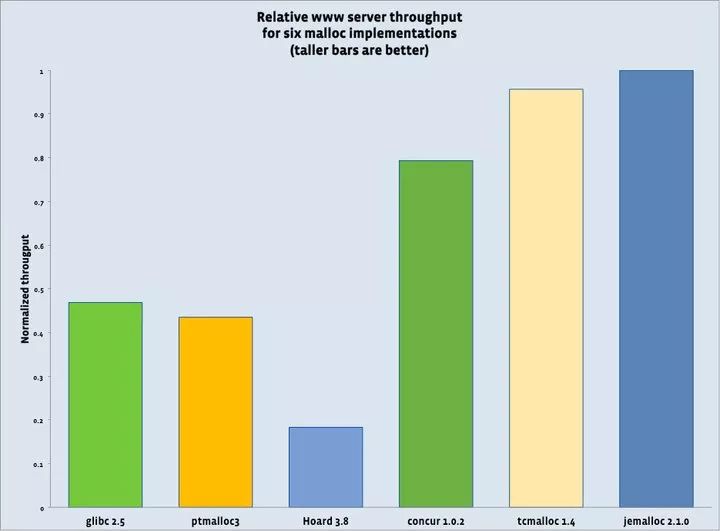
Jemalloc内存管理器性能
上图是官方的压力测试报告,可以看出Jemalloc内存管理器的性能是最好的。
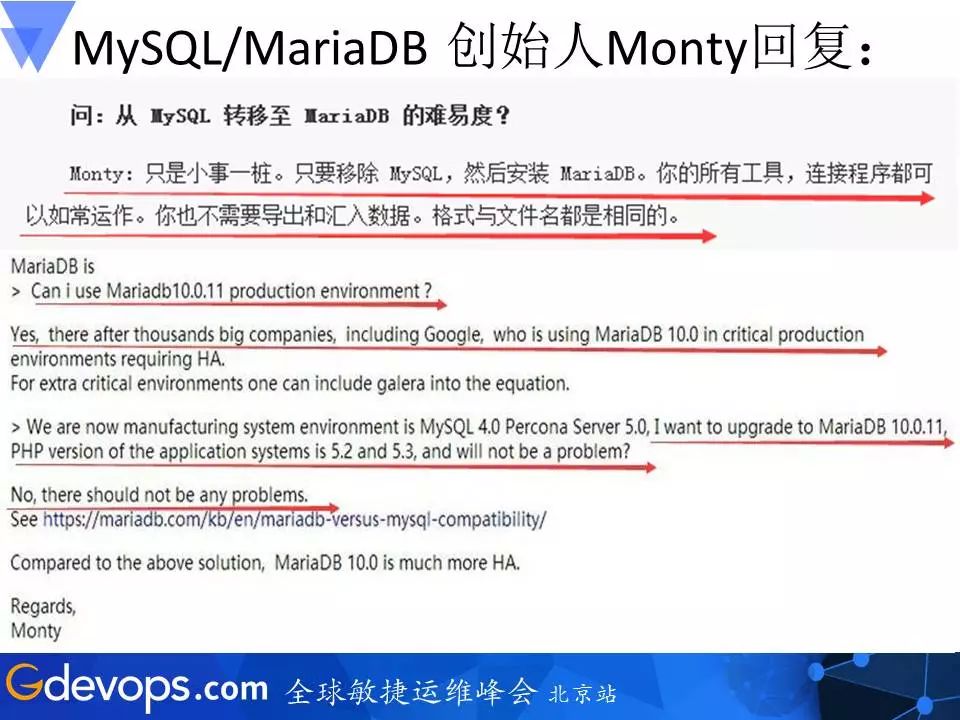
这是之前我给MariaDB作者写的一封信,他回答,升级到MariaDB是没有问题的,现在很多大公司都用MariaDB,例如Google、Wikipedia。主要原因我总结如下:
在Oracle控制下的MySQL有两个问题:
MySQL核心开发团队是封闭的,完全没有Oracle之外的成员参加。很多高手即使有心做贡献,也没办法做到。
MySQL新版本的发布速度,在Oracle收购Sun之后大为减缓。
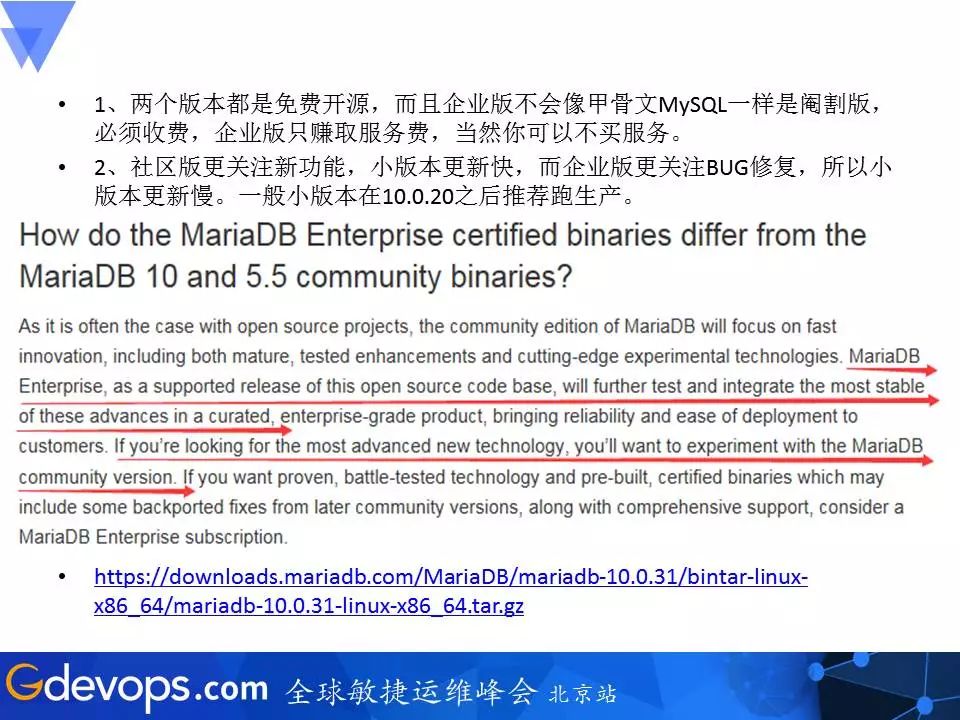
这里再说一下MariaDB企业版和社区版的区别:
企业版更注重bug的修复,社区版则对新功能更新比较快。MariaDB社区版和企业版的源代码都是开源的,并且所有功能都是免费开放,不用担心功能上有阉割,但甲骨文MySQL企业版延伸套件采取封闭源代码且需要付费。
此外,MariaDB相比MySQL拥有更多的功能、更快、更稳定、BUG修复更快。
3、解决复制延迟,开启多线程并行复制(MariaDB 10.0.X基于表)
金融公司对数据一致性要求较高,主从同步延迟问题是不能接受的。MySQL5.6由于是基于库级别的并行复制,在实际生产中用处并不大,而只有5.7才支持基于表的并行复制。MariaDB的并行复制有两种实现模式:
第一种:Conservative mode of in-order parallel replication(保守模式的顺序并行复制)
MariaDB 10 通过基于表的多线程并行复制技术,如果主库上1秒内有10个事务,那么合并一个IO提交一次,并在binlog里增加一个cid = XX 标记,当cid的值是一样的话,Slave就可以进行并行复制,通过设置多个sql_thread线程实现。
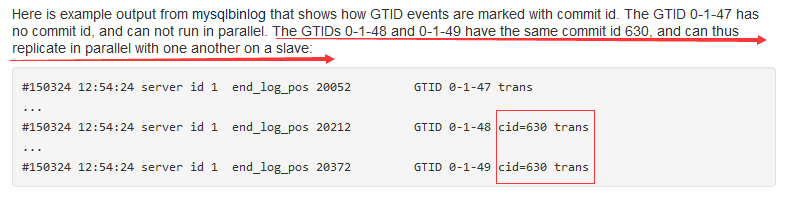
上述cid为630的事务有2个,表示组提交时提交了2个事务,假如设置slave_parallel_threads =24(并行复制线程数,根据CPU核数设置),那么这2个事务在slave从库上通过24个sql_thread线程进行并行恢复。只有那些被自动确认为不会引起冲突的事务才会被并行执行,以确保从库上事务提交和主库上事务提交顺序一致。这些操作完全是透明的,无须DBA干涉。
如果想控制binlog组提交数量,可以通过下图两个参数设置。

第二种模式:Out-of-order parallel replication(无序并行复制)

设置SET SESSION gtid_domain_id=99具有不同gtid_domain_id域识别符可并行复制,生产使用场景通常是用在增加索引、增加字段上。

实现无序并行复制,需要把GTID开启才可以实现,执行上图所示的命令。
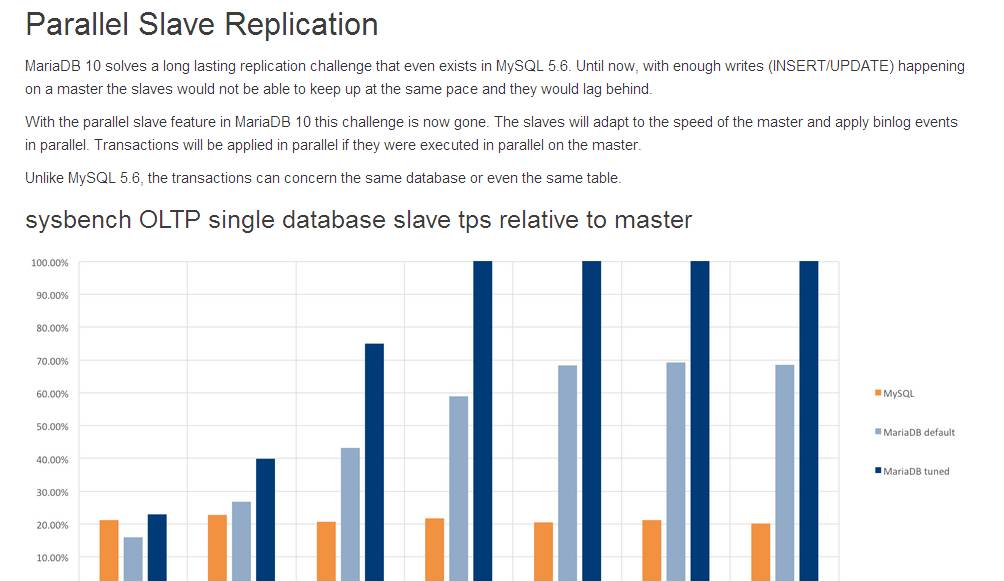
多线程并行复制---压力测试
我们可以看到,随着并行复制线程的增加,slave从库的TPS每秒写入速度接近主库。
4、前期公司大数据部门刚起步,未成熟,需要借助多源复制技术(汇总前面多个业务库),提供给BI部门、产品PO、金融分析师BA/MA进行分析。
(注:这个功能只有MySQL5.7才有,2015年7月未GA)
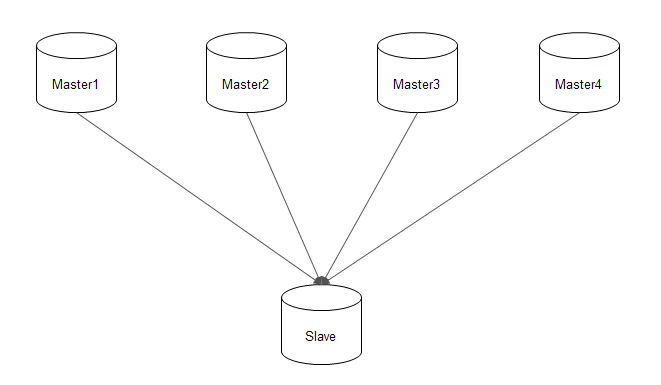
适用场景:实现数据分析部门的需求,将多个系统的数据汇聚到一台服务器上进行OLAP分析计算。
MariaDB10多源复制的搭建方法如下。
https://mariadb.com/kb/en/mariadb/multi-source-replication/
① 创建通道
SET @@default_master_connection = ${connect_name};
② 建立同步复制
CHANGE MASTER ${connect_name} TO
MASTER_HOST='192.168.1.10',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_PORT=3306,MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=4,MASTER_CONNECT_RETRY=10;
③ 启动
START SLAVE ${connect_name};
START ALL SLAVES;
④ 停止
STOP SLAVE ${connect_name};
STOP ALL SLAVES;
⑤ 查看状态
SHOW SLAVE ${connect_name} STATUS;
SHOW ALL SLAVES STATUS;
⑥ 清空同步信息和日志
RESET SLAVE ${connect_name} ALL;
⑦ 刷新Relay logs
FLUSH RELAY LOGS ${connect_name};
5、MariaDB ColumnStore(InfiniDB 4.6.2)数据仓库,用于大数据离线分析计算
第五个原因就是数据量逐日增长,在InnoDB里进行复杂SQL查询分析是一件非常痛苦的事情,后来我选择了MariaDB ColumnStore数据仓库,专为分布式大规模并行处理Massively Parallel Processing(MPP)设计的列式存储引擎,用它做大数据离线分析OLAP系统,借助ETL工具canal,实现抽取binlog并解析为原生态SQL文件入库到Columnstore里。
Columnstore技术特性
标准SQL协议
支持Navicat/SQLyog/WebSQL等客户端工具
数据分布式存储(本地化)
Shard Nothing架构
分布式并行计算
任务并行执行
横向扩展
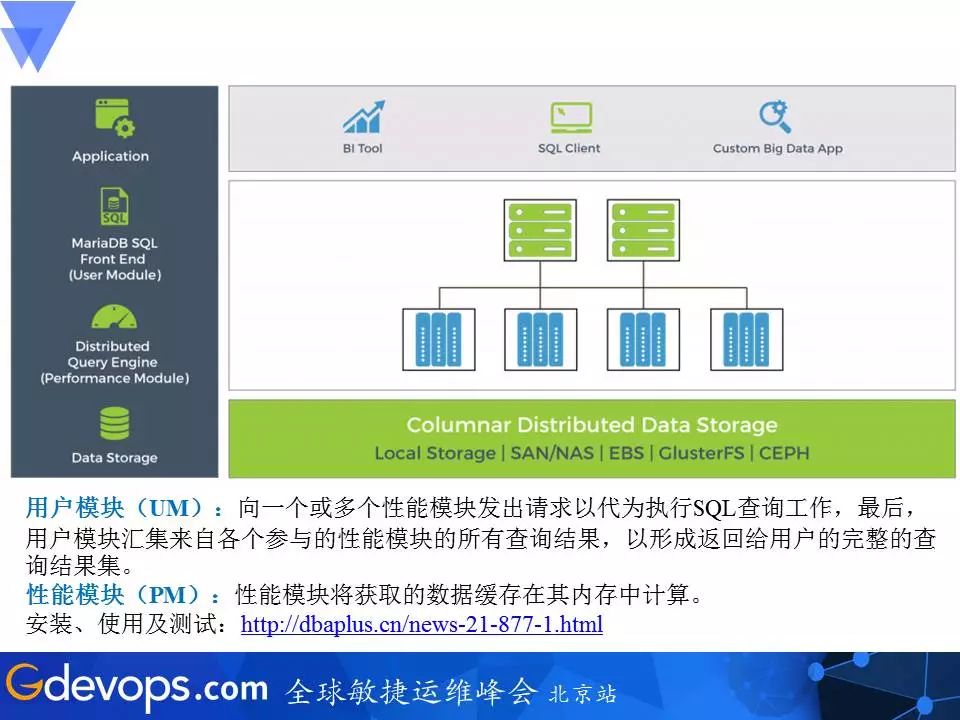
Columnstore技术架构
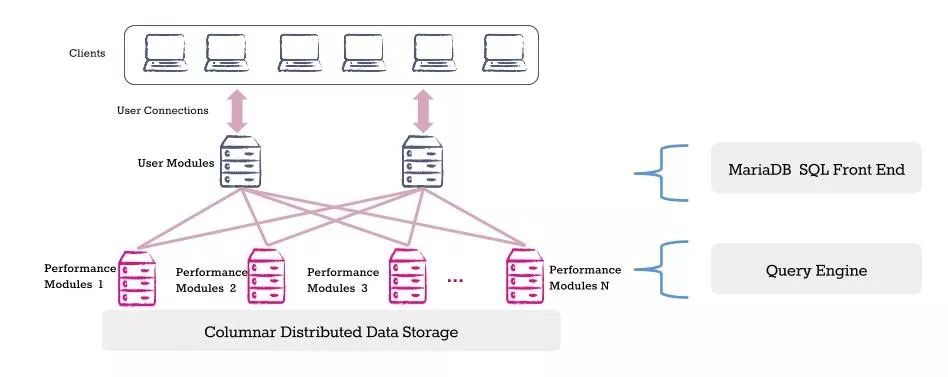
UM模块:SQL协议接口,接收客户端连接访问,推送SQL请求给PM性能模块代为执行,最后收集性能模块的处理结果做数据汇总,并返回给客户端最终查询结果。
PM模块:负责数据的列式存储,处理查询请求,将数据提取到内存中计算。
安装、使用及测试请参考我之前写的文章:《MariaDB ColumnStore初探:安装、使用及测试》
6、审计日志Audit Log
互联网金融公司对数据很敏感,业务从库提供给开发等人员使用。DBA通过审计日志记录他们操作的结果。
安装审计Audit Plugin插件:

MariaDB审计日志参数:
server_audit_events = 'CONNECT,QUERY,TABLE'
server_audit_logging = ON
server_audit_incl_users = 'hechunyang'
server_audit_excl_users = 'sys_pmm,nagios'
server_audit_file_rotate_size = 10G
server_audit_file_rotations = 500
server_audit_file_path = /data/audit/server_audit.log
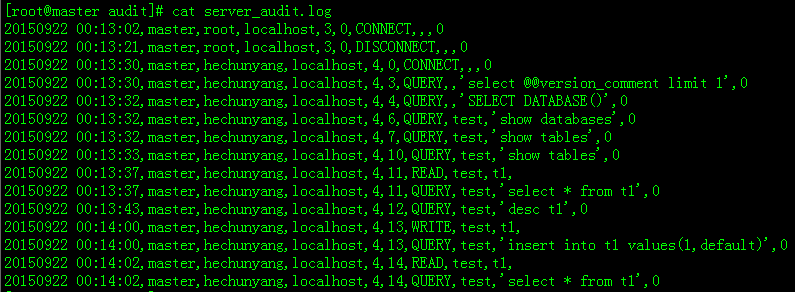
将审计日志抽到表里,用PHP展示出来分析。
由于MySQL功能上迭代速度太慢,移步MariaDB后,撑过了业务发展高峰期2015-2016年。
借助《高性能三》一书的原话:

MariaDB和Percona有什么不同?

高可用架构当时选型有两个方案,一个是MHA,一个是PXC,为什么没有选择PXC呢?有以下几个不可抗力因素:
(1)网络抖动或者机房被ARP攻击,导致NODE节点失联,出现了脑裂,怎么处理?最悲剧的是三份节点都同时写,而且还没复制过来,到底以哪份数据为准?
(2)硬盘坏了一块,导致RAID10性能下降,会导致集群限流,限流的参数是wsrep_provider_options=gcs.fc_limit:待执行队列长度超过该值时,flow control被触发,默认是16。此时正处于促销活动情形,由于PXC的性能取决于最弱的一个NODE节点,数据库连接数很容易被打满,直接挂了。
(3)业务如果有大事务,超过了wsrep_max_ws_rows、wsrep_max_ws_size这两个值,节点之间无法复制,造成数据不一致,怎么办?
由于集群是乐观锁并发控制,事务冲突的情况会在commit阶段发生。如果有两个事务在集群中不同的节点上对同一行写入并提交,失败的节点将回滚,应用端JAVA/PHP返回报错,直接影响用户体验。
可参考Percona之前分享的PPT——巨大的潜力在PXC架构,貌似解决了一致性的问题,但距离成熟还有一段距离。

下图是Group Replication以及Galera Cluster集群触发限流后,性能影响甚大。

在没有流量控制的情况下,Writer会在有限的时间内处理大量行(来自8个客户端,8个线程,50个并发批量插入)。随着流量控制,情况急剧变化。Writer需要很长时间才能处理明显更小的行数/秒。总之,性能显著下降。
https://www.percona.com/blog/2017/08/01/group-replication-sweet-sour/
(4)最主要的因素——性能问题
由于PXC/MariaDB Galera Cluster自身不支持VIP功能,MariaDB的解决方案是用MaxScale做七层负载均衡Proxy,由于本身性能就不如主从复制,再过一层代理,性能就更差。可参考下图官方的解决方案。
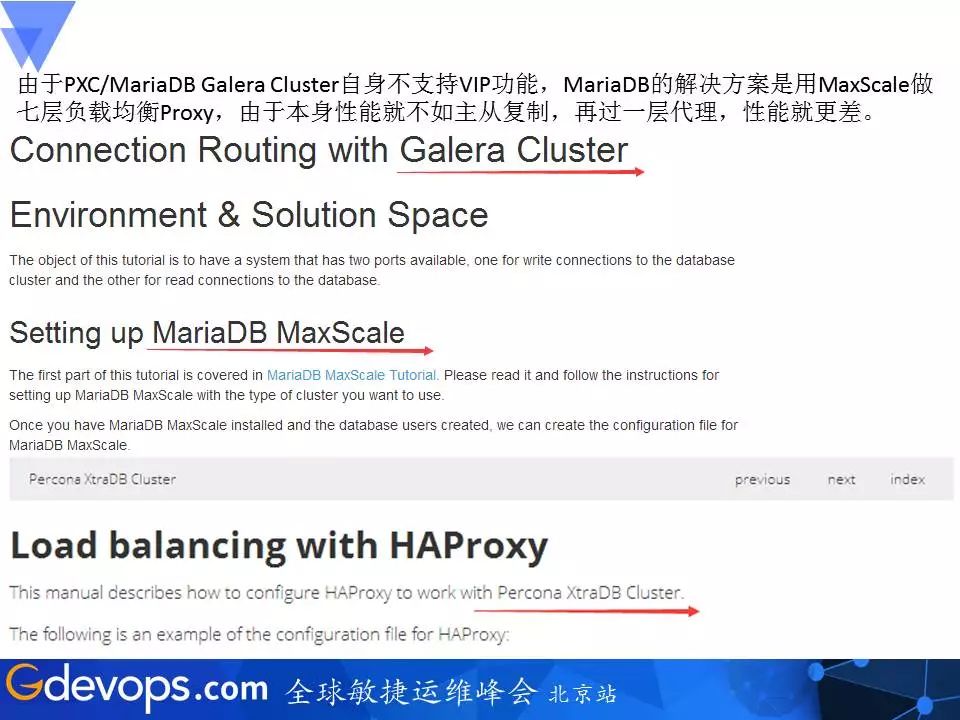
Galera Cluster整体架构图如下:

信任Percona专业团队的选择

生产数据库HA架构

MHA管理多组集群(多实例)
我们公司目前为一主带三从(其中一个从库是做的延迟复制12小时,用pt-slave-delay工具实现),高可用架构采用开源MHA+半同步复制semi replication。
延迟复制的目的怕万一开发手抖,或者代码写了一个BUG,或者把一个表给删了,通过延迟还能回来。
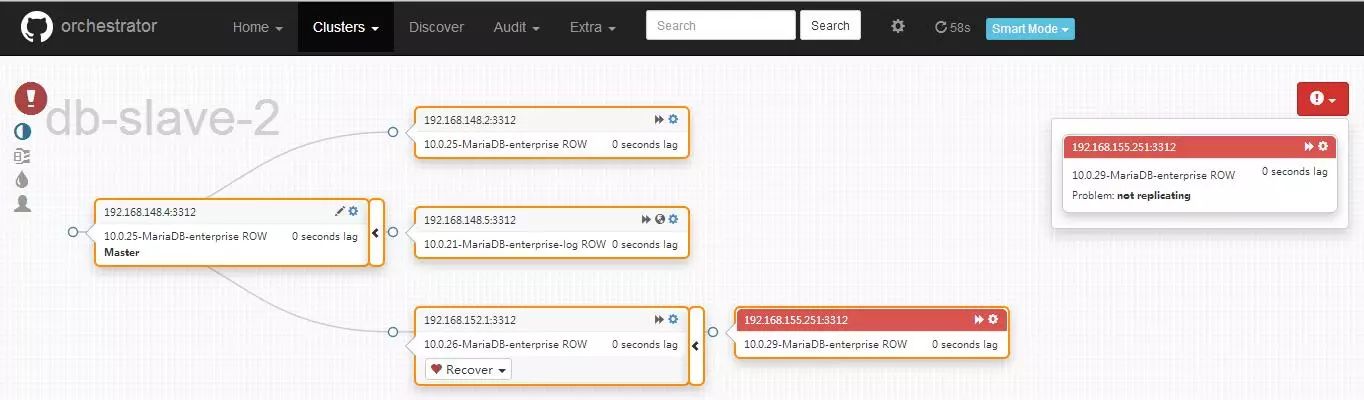
上面是一个监控图,报错的就是延时复制从库。
生产库MariaDB开启的参数
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1
innodb_support_xa = 1 (事务的两阶段提交)
MHA架构和MMM架构有什么区别呢?最大的区别在于:MHA会把丢失的数据,在每个Slave节点上补齐。下面通过一幅图来了解它的工作原理。
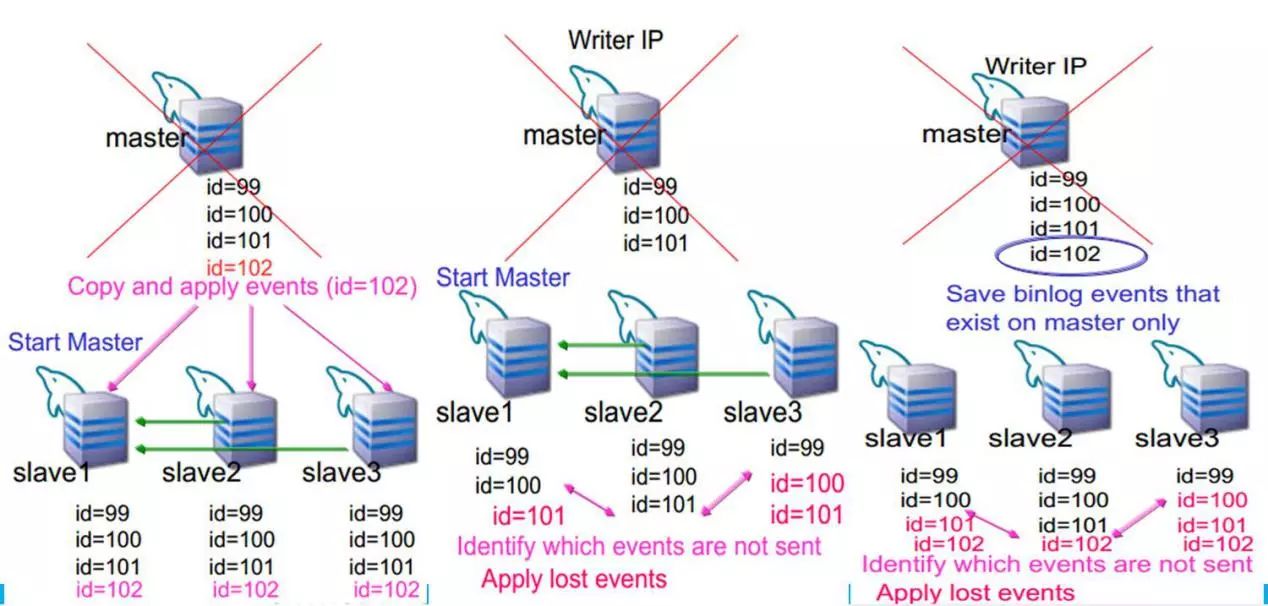
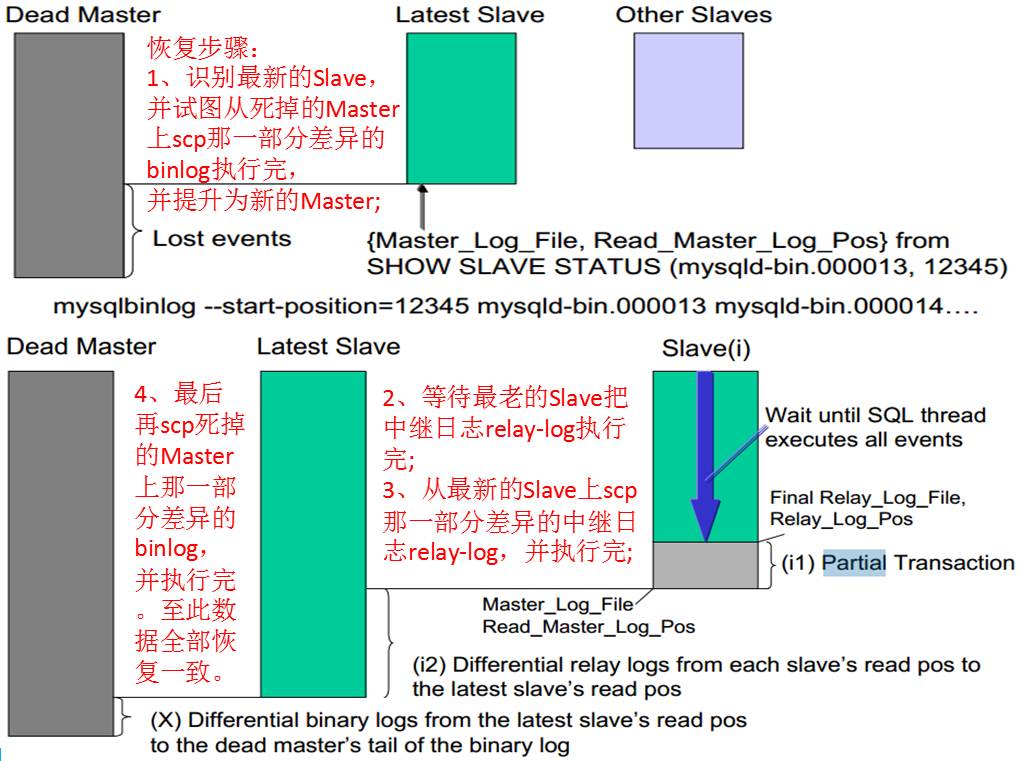
我们可以看到,当master宕机时,MHA管理机会试图scp丢失的那一部分binlog,然后把该binlog拷贝到最新的slave机器上,补齐差异的binlog并应用。当最新的slave补齐数据后,把它的relay-log拷贝到其他的slave上,识别差异并应用。至此,整个恢复过程结束,从而保证切换后的数据是一致的。
再通过下图,可以更容易去理解整个恢复过程。
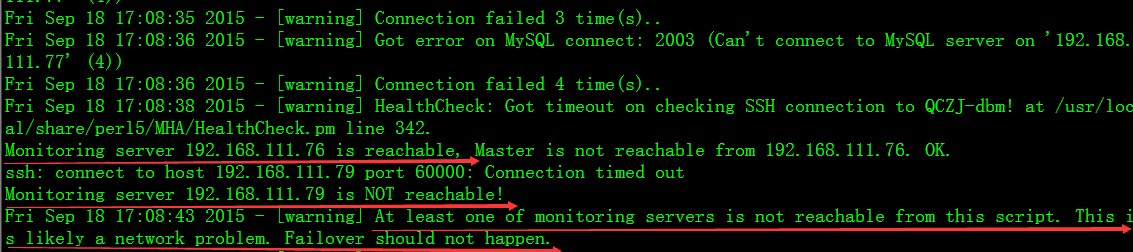
1、防止网络抖动误切换,造成数据不一致
其实现原理为:投票机制,当监控管理机无法ping通和无法连接MySQL主库,会试图从监控备机上去ping和连接MySQL主库,只有双方都连接失败,才认定MySQL主库宕机。假如有一方可以连接MySQL主库,都不会切换。
参数:
secondary_check_script=/usr/local/bin/masterha_secondary_check
-s 192.168.111.76 -s 192.168.111.79 --user=root
--master_host=QCZJ-dbm
--master_ip=192.168.111.77 --master_port=3306
从切换日志里看,它先试图用从库111.76和111.79,去同时ping 111.77主库,两个都ping不通的话,才认定主库宕机,此时才可以进行故障切换。如果有一个从库能ping通主库都不会进行故障切换。
需要留意的地方:由于masterha_secondary_check脚本写死了端口,所以要手工修改ssh端口
$ssh_user = "root" unless ($ssh_user);
$ssh_port = 62222 unless ($ssh_port);
$master_port = 3306 unless ($master_port);
2、VIP没有采用keepalived,就是怕网络抖动问题。
这里我修改了以下两个脚本,自带VIP,大家可以下载试用。
master_ip_failover_script=/usr/local/bin/master_ip_failover
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
红色的部分是修改的地方。
-------------------------------------------------------------------------------# Hardcode stuff now until the next MHA release passes SSH info in here
MHA::ManagerUtil::exec_ssh_cmd( $new_master_ip, '62222', "ip addr add 192.168.111.83/32 dev em2;arping -q -c 2 -U -I em2 192.168.111.83", undef );
-------------------------------------------------------------------------------


数据库架构演进
随着网站壮大,数据库架构一般会经历如下演进:

为什么要分库分表?(性能+存储扩容)
单个库数据容量太大,单个DB存储空间不够
单个库表太多,查询的时候,打开表操作也消耗系统资源
单个表容量太大,查询的时候,扫描行数过多,磁盘IO大,查询缓慢
单个库能承载的访问量有限,再高的访问量只能通过分库分表实现
针对爬虫业务,并发读写频率很高且对事务要求性不高,没有联表关联查询,那么就不需要考虑放入MySQL里,直接存入NOSQL——MongoDB里更适合。
利用MongoDB自身的Auto-Sharding分片技术实现,通过这种技术可以使我们非常方便的扩展数据,从而不用让开发更改一行代码即可轻松实现数据拆分。
我们这里做了分布式,集群总共是9台机器分两组Shard,两个Shard组来做的。通过这个自动分片,解决了开发不用改变原代码了,减少日常工作。
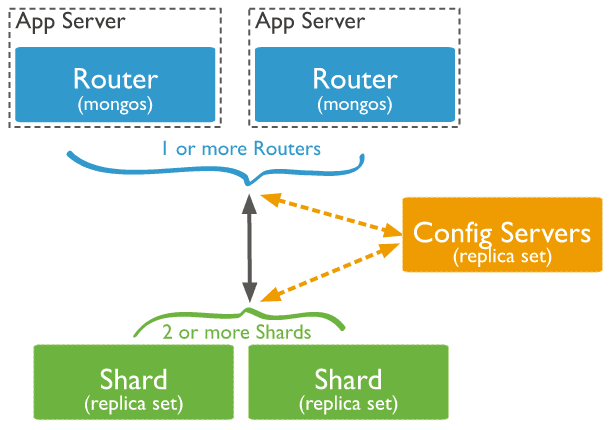
片键的选择

Hash based partitioning可以确保数据平均分布,但是这样会导致经过哈希处理的值在各个数据块和shard上随机分布,进而使制定的范围查询range query不能定位到某些shard而是在每个shard上进行遍历查询。鉴于业务的实际情况,没有范围查询,我们是以userId(查询最频繁的)字段做的Hash拆分。
再说说片键的注意事项。
第一,在对文档个别字段update时,如果query部分没有带上shard key,性能会很差,因为mongos需要把这条update语句派发给所有的shard 实例,跨多个网络性能就会下降。
第二,当update 的upsert参数为true时,query部分必须带上 shard key,否则语句执行出错。例:db.t1.update({},{cid:7,name:"D"},{upsert:1})
第三,shard key的值不能被更改。
最后再说一下数据均衡Balance注意事项。
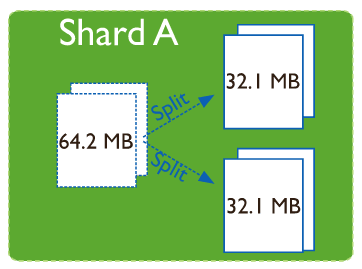
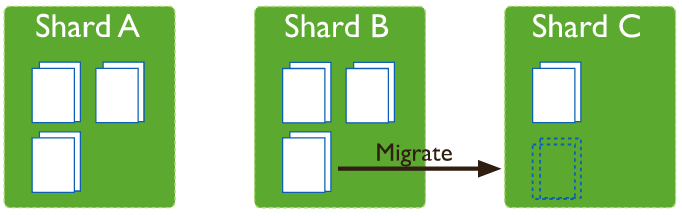
Balancer的稳定性&智能性问题,Sharing的迁移发生时间不确定,chunk(数据块)每到32M时内部分裂并自动balance,一旦发生数据迁移会造成整个系统的吞吐量急剧下降。为了应对Sharding迁移的不确定性,我们可以强制指定Sharding迁移的时间点,具体迁移时间点依据业务访问的低峰期。
我们的流量低峰期是在凌晨1点到6点,那么我们可以在这段时间内设置窗口期开启Sharding迁移功能,允许数据的迁移,其他的时间不进行数据的迁移,从而做到对Sharding迁移的完全掌控,避免掉未知时间Sharding迁移带来的一些风险。
设置窗口期命令:
use config
db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "1:00", stop : "6:00" } } }, true )
数据均衡Balance监控图--Percona PMM

观察getmore黄颜色曲线,1:00-6:00点时间段正是做数据迁移。
如果不设置窗口期,以我们7200转的sas硬盘,在早高峰做数据迁移,定将影响业务稳定。
参考我之前写的PMM监控搭建使用文章:《安利一款运维杀手锏,让监控部署不再尴尬!》
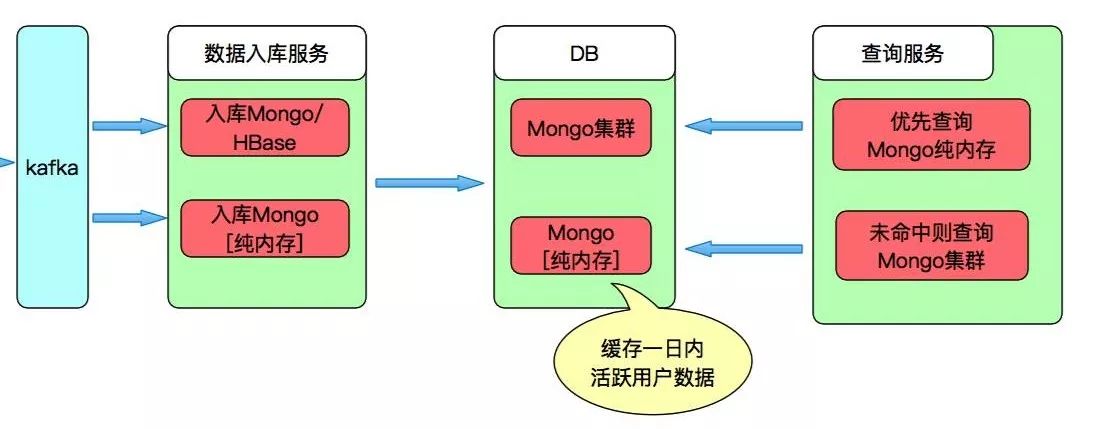
新增数据先写入数据库WiredTiger里,然后马上更新到In-Memory引擎(inMemorySizeGB = 180G),读取时优先在In-Memory内存中读取,如果数据不在则从后端WiredTiger里取数。In-Memory中的热数据失效时间为一天,等待下次读取时再加载。
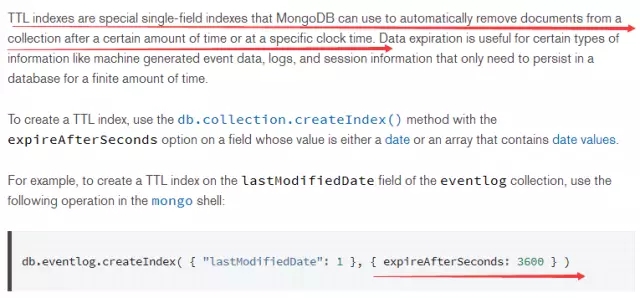
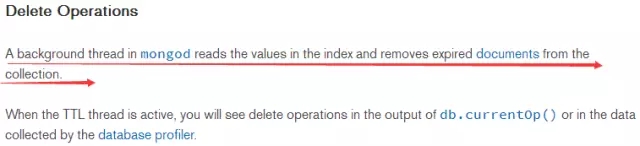
在创建索引时,需要指定过期时间,参考画红色线部分,过期后集合里的这个文档就会自动删除。这里有一个注意事项就是:字段必须是时间类型的。
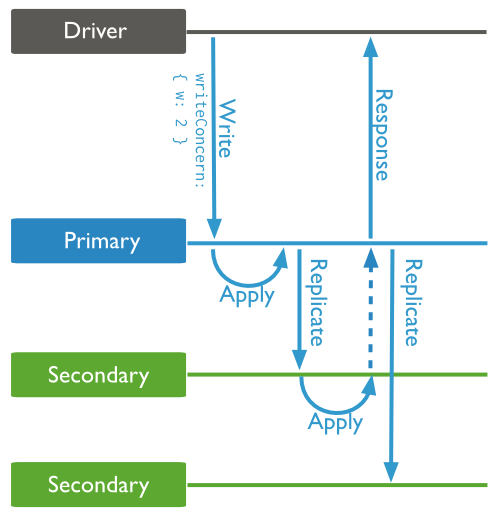
1、 MongoDB默认为异步复制,本地写完后即返回客户端请求。
2、可以通过驱动设置为:
// Setting w=majority for update:
$collection->update($someDoc, $someUpdates, array("w" =>
"majority","j" => true));
?>
意思为同步复制机制,主库数据写入内存后,还要确保Journal重做日志刷入磁盘,并保证已复制到从节点后,才会返回更新成功,将请求返回给客户端。

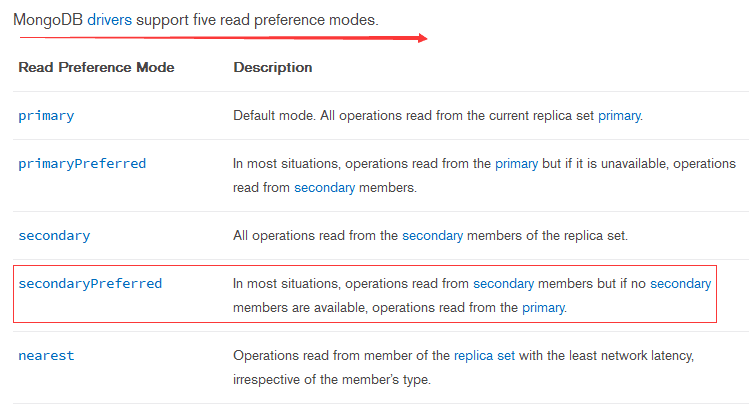
MongoDB的Java驱动,默认读写是在Primary主节点上,如果想读Secondary从节点,需要通过设置驱动实现。
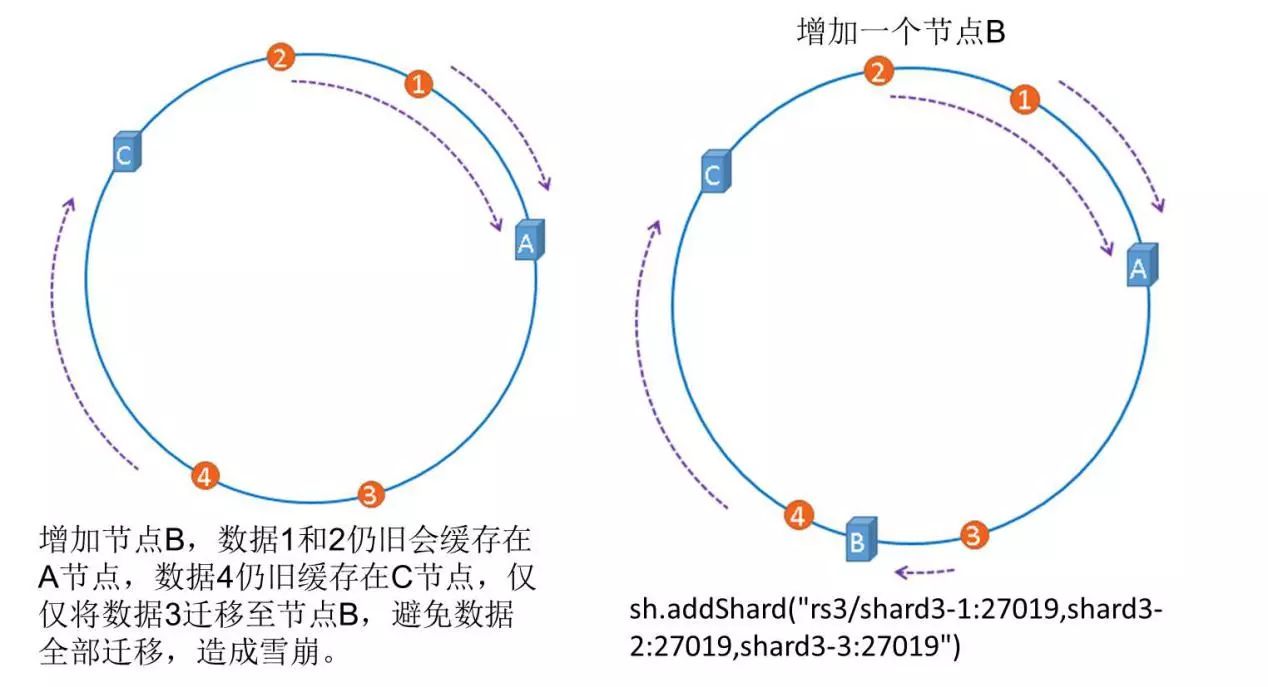
节点扩容过程为:数据1、2在节点A上,数据3、4在节点C上。如果增加一个节点B,数据1、2还在A上,只需要把数据3迁到B上,数据4仍在C上,所以只是部分数据迁移,并不是整体数据迁移,这样避免了雪崩的现象。
原因:
1、开发代码有BUG或DBA手抖,一瞬间让你的业务回到解放前
2、过TB数据备份恢复问题
MariaDB 10.2才支持延迟复制(MySQL5.6早已支持),固需要借助Percona PT工具实现
shell > perl /usr/local/bin/pt-slave-delay -S /tmp/mysql.sock --user root
--password 123456 --delay 43200 --log /root/delay.log --daemonize
注:单位秒,43200秒等于12小时
MongoDB 3.2延迟复制实现
Primary > rs.add( { host:
"qianzhan_delay.mongodb.dc.puhuifinance.com:27017", priority:0,hidden:1,slaveDelay:43200,votes:0 } )
注:
priority权重设置为0,永远不能切为Primary
hidden设置为隐藏节点
slaveDelay延迟时间,单位秒,43200秒等于12小时
votes取消投票资格

Percona MongoDB3.2版本默认支持WiredTiger引擎的在线热备份,解决了官方版只能通过mongodump逻辑备份这一缺陷。恢复很简单,把备份目录里的数据文件直接拷贝到你的dbpath下,然后启动MongoDB即可。
参考文献:
https://www.percona.com/doc/percona-server-for-mongodb/LATEST/hot-backup.html#hot-backup
注:Percona server Mongodb 3.2.10有一个bug
directoryperdb = true
wiredTigerDirectoryForIndexes = true
这两个参数必须注销掉,否则备份失败。
这是我提交的bug地址,https://jira.percona.com/browse/PSMDB-123
Percona采纳了该bug,并在3.2.12版本里修复。
https://www.percona.com/doc/percona-server-for-mongodb/3.2/release_notes/3.2.12-3.2.html

Percona MongoDB3.2 HotBackup Perl Scripts
使用说明:请在本地admin数据库,以管理员身份运行createBackup命令,并指定备份目录。
自动备份脚本
# perl -MCPAN -e “install MongoDB”
|
#!/usr/bin/perl use MongoDB; use File::Path; use POSIX qw(strftime); my $mc = MongoDB::MongoClient->new( host => "mongodb://localhost:37019/", username => "admin", password => "123456", ); my $db = $mc->get_database("admin"); $year = strftime "%Y",localtime; $month = strftime "%m",localtime; $time = strftime "%Y-%m-%d-%H-%M-%S", localtime; $BAKDB = "yourdb"; $BAKDIR = "/data/bak/hcy/$year/$month/$BAKDB_$time"; my $user = getpwnam "mongodb" or die "bad user"; my $group = getgrnam "mongodb" or die "bad group"; mkpath($BAKDIR) or die "目录已存在. $!"; chown $user, $group, $BAKDIR; my $cmd = [ createBackup => 1, backupDir => $BAKDIR ]; $db->run_command($cmd); if($! == 0){ print "backup is success."; }else{ print "backup is failure."; } |
MongoDB 慢查询邮件报警并自动KILL Perl Scripts

通过查看当前操作db.currentOp(),大于指定执行时间,发邮件报警,并通过db.killOp(opid)杀掉进程。

默认剩余空间的5%
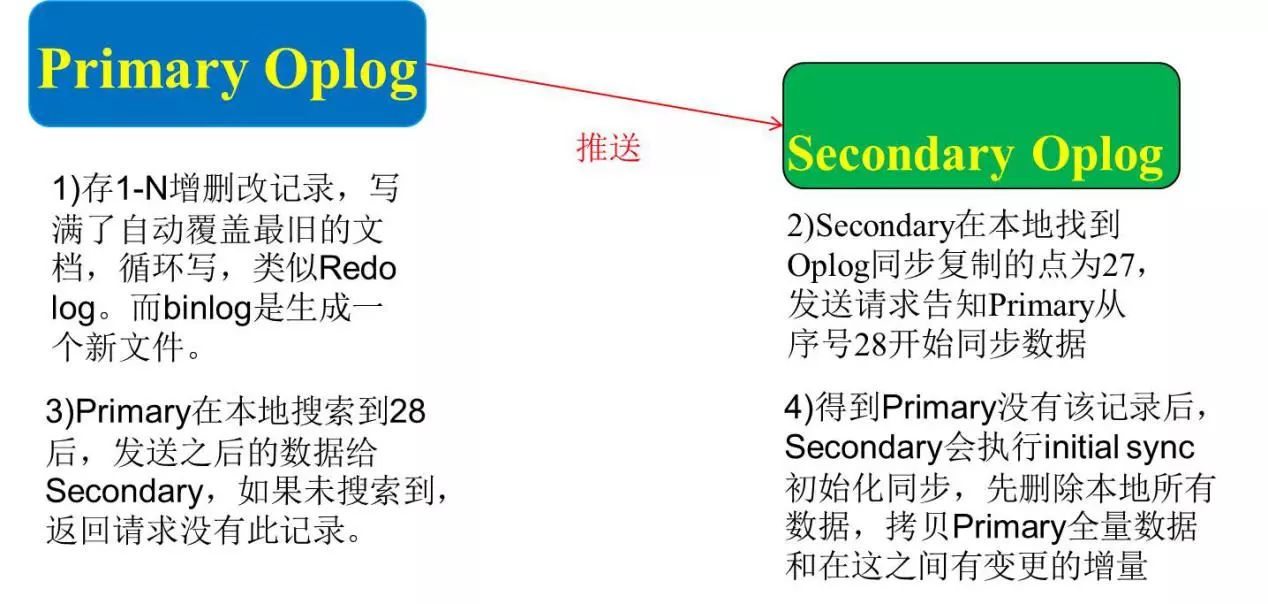
当你搭建副本集的时候,一定要把Oplog设置得比较大,默认是剩余磁盘空间的5%,我们线上设置为100G。Oplog跟binlog存储方式不太一样,binlog是写满一个文件会再生成一个新的文件继续写,而Oplog则是覆盖写。我们看上图,从库挂掉以后再次加入集群时,它会先发送一个位置点给主库,比如现在发送一个位置点是27,主库有的话会把27之后的数据推过来。如主库没有会告知从库我这里没有找到,从库会把本地数据全部删除,从主库上全量抽数据,学名为initial sync。
神器!MongoDB语法在线生成器
http://www.querymongo.com/
可以将SQL语法转换成MongoDB语法,例子:

MySQL 分库分表中间件选择
MariaDB Spider分库分表存储引擎
https://mariadb.com/kb/en/mariadb/spider-storage-engine-overview/
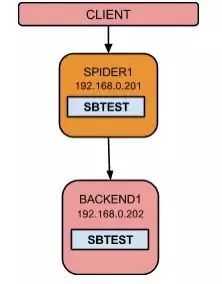
Spider是MariaDB内置的一个可插拔用于MariaDB/MySQL数据库分片的存储引擎,充当应用服务器和远程后端DB之间的代理(中间件),它可以轻松实现MySQL的横向和纵向扩展,突破单台MySQL的限制,支持范围分区、列表分区、哈希分区,支持XA分布式事务,支持跨库join。通过Spider,您可以跨多个数据库后端有效访问数据,让您的应用程序一行代码不改,即可轻松实现分库分表!
开发无需调整代码,应用层跟访问单机MySQL一样。
DBA部署简单,由于MariaDB10 默认已经捆绑了Spider引擎,无需编译安装。
支持标准SQL语法,存储过程,函数,跨库Join,没有Atlas那么多的限制。
后端DB可以是任一版本,MySQL/MariaDB/Percona
无维护成本
生产成熟案例-腾讯公司
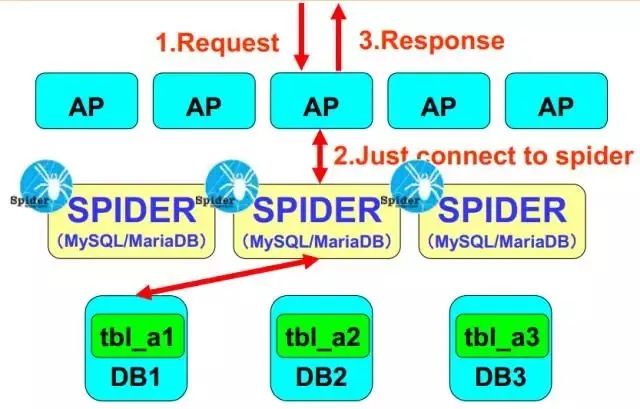
这个是它的整体的架构图, 应用程序连接Spider,Spider充当中间件代理,将客户端查询的请求,按照事先定义好的分片规则,分发给后端数据库,之后返回的数据汇总在Spider内存里做聚合,最终返回客户端请求,对于应用程序而言是透明的。
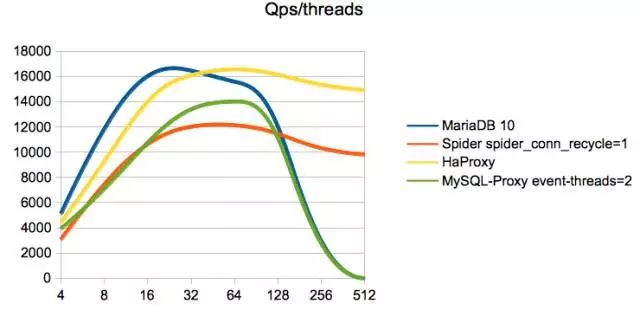
在我的压测结果上,分表的性能会降低70%,垂直拆分性能会降低40%,性能损耗的原因是在分布式场景下,要保证2PC一致性和可用性读写的表现就差,另外就是跨多个网络传输这两方面引起的。
在生产环境中,我通过Spider实现了表的垂直拆分,没有做分库分表。
(架构图)
1、交易流水表我是半年一切表,老表改名,再创新一张新表,然后通知开发手工改代码里的SQL,用union all的方式关联查询。如:select * from t1 where apply_no = 'XXXX' union all select * from t1_20170630 where apply_no = 'XXXX'
2、由于历史表没有写操作,只有用户的查询,且查询频率并不是很高,将历史表移到备份机,再通过spider做一个映射(软连接)实现表的垂直拆分,解决磁盘空间扩展问题。
3、实施这个方案,选择Spider引擎是有优势的:
SQL解析和查询优化是个非常复杂且很难做好的工作,其它替代产品都是自己实现,由于复杂性,这些产品都带来了一些限制,比如不支持存储过程、函数、视图等,给使用和实施带来了困难。而作为一个存储引擎,这些工作都由MariaDB自身完成了,可以方便地将大表做分布式拆分,它的好处是对业务方使用是透明的,SQL语法没有任何限制,在不改变现有DB架构的方案中,侵入性最小。
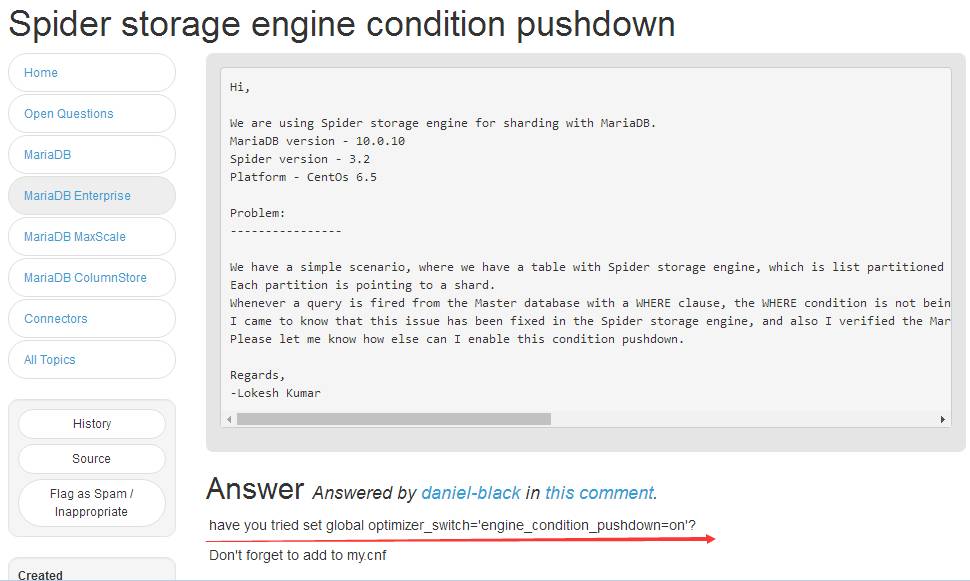
optimizer_switch= 'engine_condition_pushdown=on'
引擎下推,查询推送到后端数据库,将查询结果返回给Spider做聚合,类似Map-Reduce。早期的版本是从后端拉取所需的数据到本地临时表,然后再做处理。
注:涉及跨库join操作,同样是从后端拉取本地做关联查询。
shell > mysql -uroot -p < /usr/local/mysql/share/install_spider.sql
SELECT engine, support, transactions, xa FROM
information_schema.engines;

定义后端服务器和数据库名字

这个是定义后端服务器和数据库名字。这里后端服务器的名字为backend1,数据库名字为test,主机IP地址为192.168.143.205,用户名为user_readonly,密码为123456,端口为3306。
注:如配置错误,可直接DROP SERVER backend1; 重新创建即可。
垂直拆分(映射、软连接)
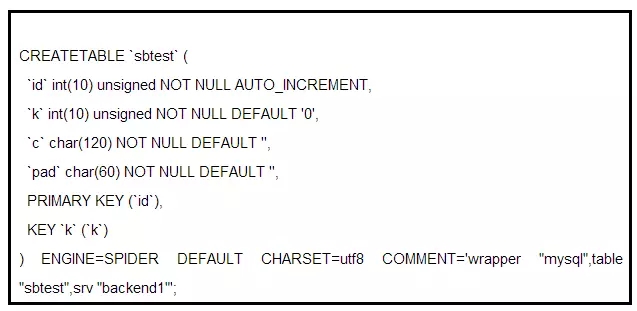
这个是定义垂直拆分,也就是映射和软连接,做一个超链接。Spider自身不保存数据,只保存路由信息。这里通过设置COMMENT注释来调用后端的表,然后你就可以查看sbtest表了,是不是很简单?
参考https://mariadb.org/embrace-community-fly-open-source-dream/
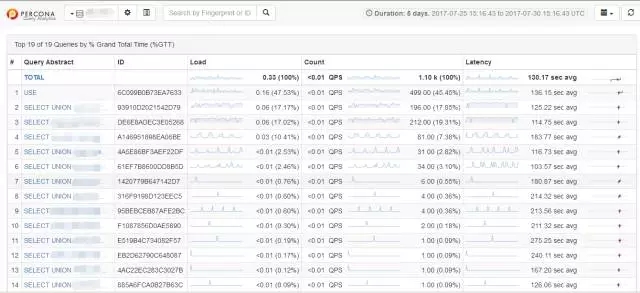
慢查询监控也是用的是Percona来做,这里是集成了可视化平台。
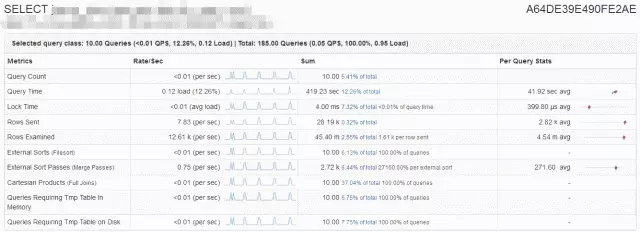

(Percona PT-kill精简版)
多增加发送kill掉后的慢SQL邮件报警功能
注:官方原版默认被kill掉的SQL不会发邮件出来,这会造成不能及时通知开发,对排查问题带来困惑。
下一代关系型数据库NewSQL

最后说一下下一代关系型数据库NewSQL:CockroachDB和TiDB。
CockroachDB是一个分布式SQL数据库。其主要设计目标是扩展性、强一致性和生存性(CockroachDB蟑螂数据库由此得名)。 CockroachDB的目标是容忍磁盘、机器、机架,甚至数据中心故障,在无需人工干预的情况下,最小化这些延迟中断的影响。 CockroachDB各节点是对等的,设计目标是同质化部署(一个二进制包),最小化配置,也不需要外部依赖项。CockroachDB集群中的每个节点都可以扮演一个客户端SQL网关角色,SQL网关将客户端SQL语句转换成KV操作,分发到所需的节点执行并返回结果给客户端。其设计灵感,来自谷歌Spanner和F1论文。
https://github.com/cockroachdb/cockroach
https://www.cockroachlabs.com/docs/stable/
TiDB的SQL解析协议是基于MySQL,而CockroachDB是基于PostgreSQL。
CockroachDB采用分层架构,其最高抽像层为SQL层,CockroachDB直接通过SQL层提供熟悉的关系概念, 如:模式schema、表table、列column和索引index, 接下来SQL层依赖于分布式KV存储,该存储管理range处理的细节以提供一个单一全局KV存储的抽象。分布式KV存储与任意数量的CockroachDB物理节点通信,每个物理节点包含一个或者多个存储。
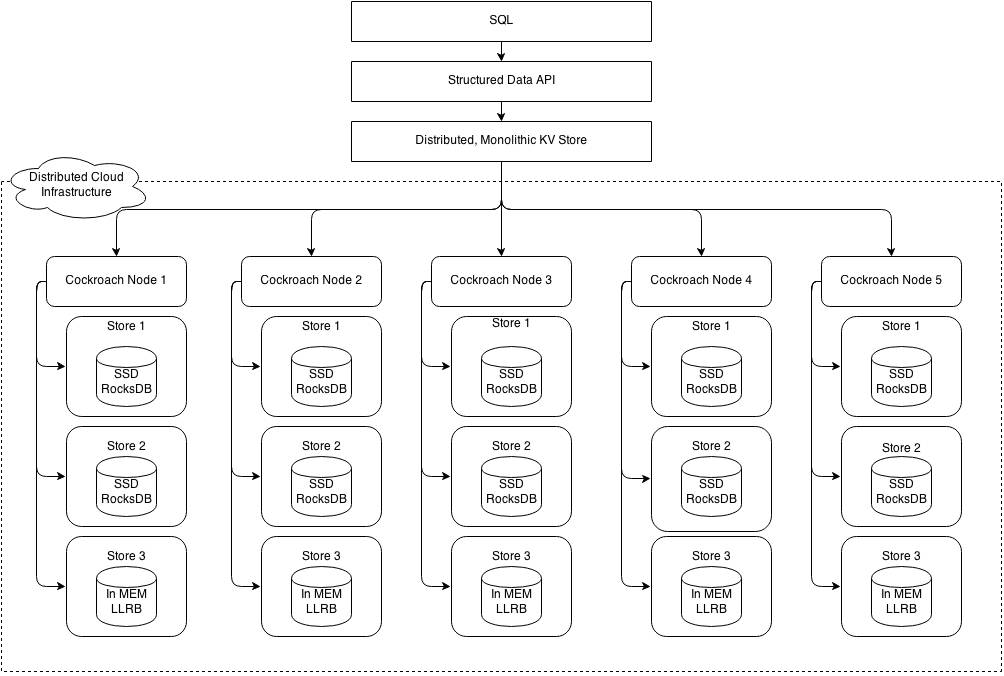
在原有NoSQL数据库(Facebook RocksDB)基础上,增加了分布式事务,解决了数据强一致性。
支持传统SQL语法,封装了一层PostgreSQL协议。
采用MongoDB的Raft协议做故障切换(大多数投票机制),默认3个节点挂1个节点不影响业务读写。
节点动态热扩容,节点间的数据自动迁移。
内部自动分裂数据块(达到64M),自动balance均衡(数据迁移)。
全同步机制(强一致性),数据写入必须至少2个副本(默认3个副本)落地,客户端才可以返回提交成功请求。
任意一个节点支持读写操作。

这个是Percona之前在这个文章里做的评测
https://www.percona.com/blog/2017/03/27/whats-next-for-sql-databases/
性能上,不及MySQL,生产环境主库替代MySQL为时尚早,其工业品质和MySQL尚有差距。

译:不能用于严重部署(根据我的经验),我预计这两个项目将在2017年取得重大进展。
不能用于OLAP 和重度数据分析
JOIN关联查询性能较差
比较适合的场景,就是订单历史流水表,物流历史表,论坛帖子历史表这种,低并发简单SQL读写,通过CockroachDB自动扩容
我们公司现在把历史表导入到CockroachDB里面,配合大数据部门,让他们从这里直接抽数据。
性能差的原因

一个是全同步机制,强一致性,数据至少写入两个节点才可以。
第二就是默认序列化,事务只能一个一个执行,不能并行执行。
第三分布式事务提交,需要跨多个网络,网络IO开销大。
The long transactions (let's say changing 100000 or more rows) also will
be problematic. There is just too much network round-trips and
housekeeping work on each node, making long transactions an issue for
distributed systems.
https://www.percona.com/blog/2017/03/27/whats-next-for-sql-databases/
译:大事务(例如更改10万行或更多)也是有问题的。每个节点都有太多的网络往返,使得长时间的大事务成为分布式系统的一个瓶颈。
默认三个副本,每个节点都可以读写:
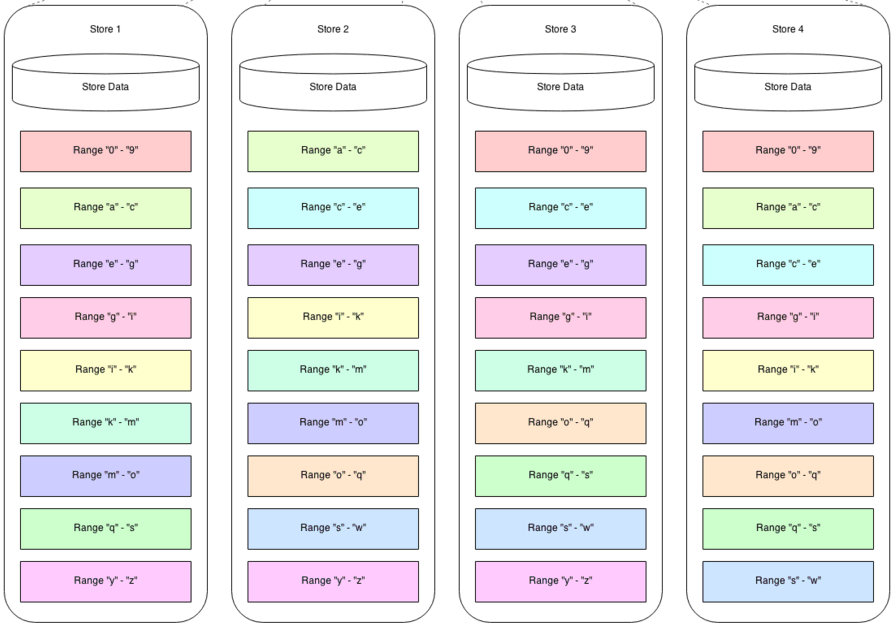

参数解释:
--cache为内存缓存的数据,通常为物理内存的70%
--join为加入群集节点
部署非常简单,只需要添加节点,数据会自动迁移扩容。
CockroachDB客户端 Postico for Mac

命令行工具
# psql -h 192.168.1.1 -U dev -p 26257 --password
自带监控 http://192.168.155.46:8080
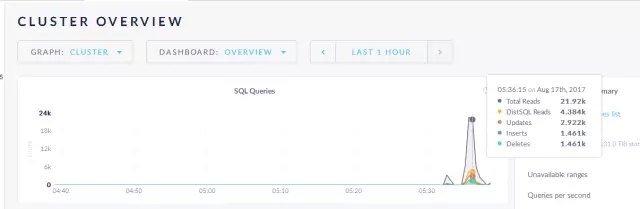

这个是自带的监控平台,可以看到运行情况。
由于采用PostgreSQL协议,MySQL表结构语法会报错,需要微调。
不支持COMMENT注释,需注销掉。
AUTO_INCREMENT PRIMARY KEY主键自增,需改成SERIAL
int(11)改为int,没有tinyint,用smallint代替
不支持double,用decimal代替
不支持`反引号,需注销掉
创建表结构时,不支持写二级索引,需要单独用命令创建
默认UTF-8字符集
timestamp默认UTC格林威治时间
更多请参考https://www.cockroachlabs.com/docs/stable/data-types.html
1、导出MySQL表结构
# mysqldump --xml --compact test t1 > t1_schema.sql
2、转成PostgreSQL表结构
# php convertor.php -i t1_schema.sql -o t1_schema.sql.pg
https://github.com/mihailShumilov/mysql2postgresql
3、导出MySQL数据
# mysqldump --single-transaction --compact
--default-character-set=utf8 --set-charset -c -t -q --extended-insert
-uroot -p123456 --compatible=postgresql test t1 > t1.sql
4、如果SQL文件里有转义符,需要进行一次格式化,PostgreSQL在反斜杠转义符之前需要添加'E'前缀。
# sed -i "s/,'/,e'/g" t1.sql
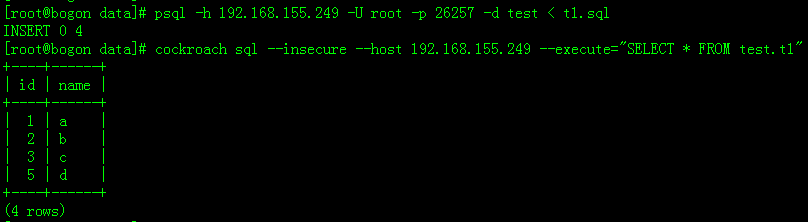
导入到CockroachDB里
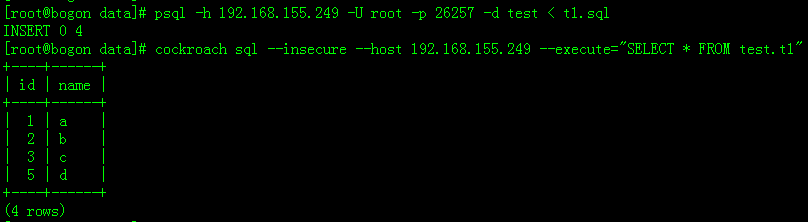
# psql -h 192.168.155.249 -U root -p 26257 -d test < t1.sql
# 定义慢SQL执行时间
> SET CLUSTER SETTING sql.trace.txn.enable_threshold = '1s';
# 开启慢日志记录
> SET CLUSTER SETTING sql.trace.log_statement_execute = true;
效果如下:

1、支持查看SQL运行状态,类似MySQL show processlist命令
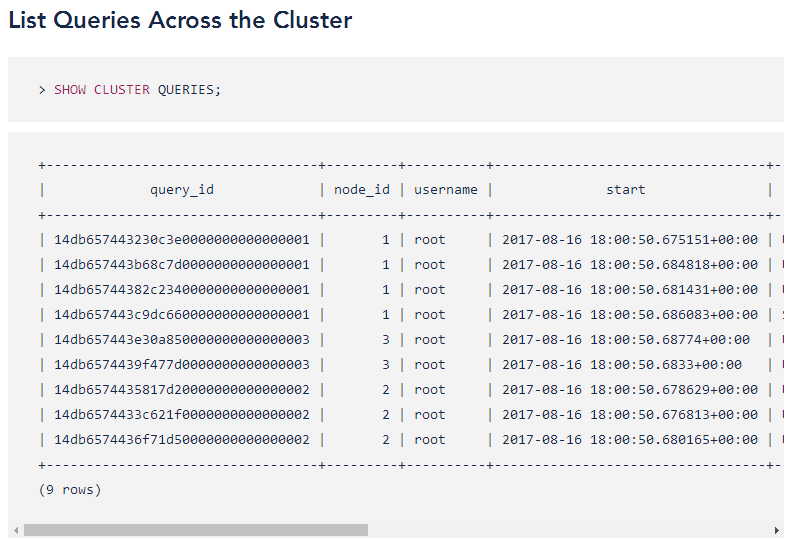
2、支持kill 慢SQL线程id,类似MySQL kill thread_id
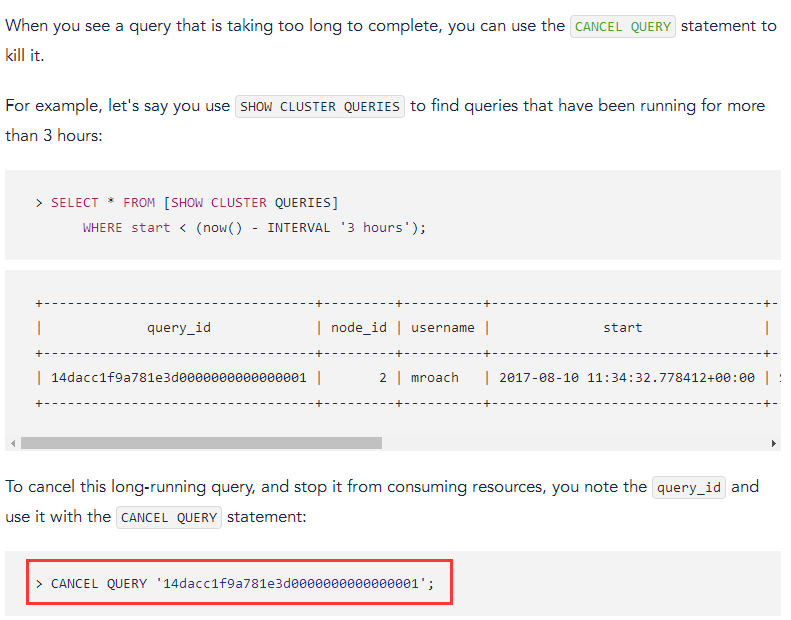
执行时间超过10秒的select查询全部干掉
> CANCEL QUERY (SELECT query_id FROM [SHOW CLUSTER QUERIES] WHERE start < (now() - INTERVAL '10 seconds') AND query ~* 'select');
1、下载PostgrepSQL驱动
https://jdbc.postgresql.org/
2、连接CockroachDB范例For JDBC

这就是我今天讲的三个数据库,谢谢大家!
干货PPT与脚本下载链接:https://pan.baidu.com/s/1gfcpQwj#list/path=%2F







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721