
作者介绍
杨志洪,DBAplus社群联合发起人,新炬网络首席布道师。Oracle ACE、OCM、《Oracle核心技术》译者。数据管理专家,拥有十余年电信、银行、保险等大型行业核心系统Oracle数据库运维支持经验,掌握ITIL运维体系,擅长端到端性能优化、复杂问题处理。现主要从事数据架构、高可用及容灾咨询服务。
好吧,标题显然目前还只是个噱头,但负责MySQL Server Tuning的研发总监表示在接下来的版本会考虑放进去,应该不是8.0,可能是9.0。
10月18日晚上,MySQL 8.0优化器新特性交流会如期举办,DBAplus社群从众多报名者中精选了15人,在会上与MySQL研发总监Manyi Lu进行了面对面的深度交流。除了Manyi之外,到场嘉宾还包括:MySQL台湾技术顾问Ivan Tu、太平洋保险研发副总陆进、海通证券数据库专家王朝阳、携程DBA何根华、绿芯产品经理高峰.......还有一些互联网公司的兄弟就不一一列出了,大家围坐一个长方桌近距离交流,气氛和效果都非常好,达成了一次真正意义上的技术交流,而不像一般的培训只是以听为主。
关注“dbaplus”订阅号,回复“8.0”或点击本文末【阅读原文】即可下载本次交流会Manyi分享的PPT!
先上2张照片:

MySQL研发总监Manyi Lu

方桌会议
作为一位MySQL吃瓜群众,我主要记录了一些我感兴趣的内容,主干是Manyi的分享,少部分是现场嘉宾的交流速记。
为什么新版本叫MySQL 8.0?
其实Manyi在演讲的时候不时还会说成5.8,之所以叫8.0,有两个原因:
之前其实研发过一个6.0的版本,但没公布;
当前有些组件,比如MySQL Cluster已经发布过了7.4。
所以为了统一所有组件的版本,减少用户歧义,直接“升级”到了8.0版本,以后的大版本就会是8.0,9.0,10.0,当然,也会出一些小版本,比如8.0.1、8.0.2之类的。
MySQL企业版和社区版的主要区别在哪里?
目前来说,企业版和社区版的主要区别在四个方面(企业版有,而社区版没有,短时间内也不会有):
备份/恢复效率
Enterprise Monitoring
Thread Pool(对大规模并发的互联网应用来说非常重要,MySQL研发也希望开源,不过policy不允许)
安全控制(类似于TDE/audit等)
MySQL企业版已经是个盈利部门,研发人员在近两年内从100多人扩张到300人左右,所以企业版功能要更完善、更安全(至少是意愿上)是合理的。对那些不想支付庞大的Oracle license,又想使用相对完善功能来说,是一个合理的选择。比如我们前期与某互联网金融公司交流,对方就明确一定是全部系统使用MySQL,而且是企业版本,而不是社区版(相对Oracle来说,license费用确实低了太多)。当然,社区版仍然会有许多拥趸,毕竟在license上是零成本。
选用MySQL有哪些注意事项?
最最最重要的说明,我认为是字符集。Manyi建议大家选择UTF8mb4 Collation500,现场大部分企业用的是mb3。
8.0以后,默认的存储引擎就变为InnoDB了,对一些以前使用MyISAM的用户来说,可能:
select count(*)可能会觉得性能下降;
大批量的insert会慢一些。
InnoDB的团队已经在着手优化了,成效要拭目以待。
参会嘉宾提了哪些期望的新特性
好吧,噱头的标题源于这里。其实是在交流会之前,我跟Manyi交流的时候提的,Manyi表示,这次来大陆,支持Hash Join是被问得最多的特性,后续版本一定会支持,不过应该不在8.0这个版本中,因为她觉得还有更重要的功能要解决。
其他嘉宾的期望呢?
太保的陆老师期望更加智能、更加强大。目前虽然企业版有Enterprise Monitoring,但是仍然不够,期望可以类似Oracle的AWR、ADDM功能。这个期望被重点认可;
微软的兄弟提出希望人工提示的加强,动态显示的加强。关于Hint,这个也是跟Oracle学的,每个版本都在增加更多的Hint,MySQL一直在努力;
绿芯半导体的兄弟提出,希望对PCIE闪存卡兼容性更强些。这个暂时还没法智能判断,因为Server层不知道哪些表的数据是在磁盘上,还是在SSD上,还是在内存里,可以通过hint来解决;
携程的兄弟希望支持多线程并发完成一个任务;
Oracle的一名SC提出希望内存加速和一致性。这个已经有了,大概10%左右的加速提升;
MySQL的哪个版本最稳定?作为MySQL研发来说,只能告诉你最新版本就是最好的版本,要不咱干嘛发布出来呢?
海通的朝阳兄弟提了个需求,什么时候可以支持flashback?MySQL官方没有研发计划,不过国内已经有开源团队在做这方面的研发了;
多名嘉宾提到Sharding,分布式数据访问。其实MySQL一直在努力,从MySQL Cluster,Febric(已经停止研发,该团队调去搞InnoDB了),到InnoDB Cluster,不断地在调整和优化。到底是要类似于MongoDB Sharding的傻瓜化呢,还是自由灵活些,要抉择的东西蛮多....
8.0要在1年以后才会GA,所以,如果你有什么新特性希望在8.0里出现,欢迎在本文留言区提出,社群会统一收集反馈给MySQL研发总监。
MySQL的对手是谁?
从研发的角度来说,显然是MongoDB无疑,JSON在5.7版本的支持,就是为了抢回被MongoDB掠夺过去的一些客户,在8.0上增加了更多的JSON函数。 对于LBS类应用来说,MongoDB支持的也不错,而在8.0中,GIS的增强也是一大亮点。
显然,Postgre暂时还没被列入其中。本月下旬PG在上海将有一次年度大会,使用者还是在逐渐增加的。
其实,SQL Server在年初已经支持Linux阵营,往后未必不是MySQL的一大对手。
MySQL为什么会有许多存储引擎?
MySQL公司最开始主要研发的是Server部分,而存储引擎则是由不同的公司开发,以插件的形式与Server结合使用,不同的存储引擎适合不同的应用场景。
不过,目前MySQL Server和InnoDB都已经被Oracle公司收为己有,所以后续会重点扶持InnoDB。虽然其他存储引擎仍然会以插件的形式存在,不过Oracle公司自然而然的会把MySQL Server和InnoDB视为一个整体,有些特性优化会下方到InnoDB层,而不是在Server层进行:比如Foreign key,Partition等。
中间有个比较棘手的问题是Handler API,一部分问题的性能瓶颈在于此,而它要支持不同的存储引擎,而且至今没有version的概念,所以重构起来比较困难。
关于 MySQL的Hint
MySQL为什么要学Oracle提供Hint? 是Oracle优化器变得越来越烂,越来越不自信么?
当然是为客户的应用性能稳定性着想。数据库的优化器非常复杂,就算是远没有Oracle复杂的MySQL的成本模型也是一样,可能更新的成本模型将99.9%的功能和场景都性能提升了,而0.1%的场景性能会有下降/退化,那么Hint就派上用场了。
目前来说,下面一些场景是需要用到Hint的:
没有索引的列,MySQL是没有统计信息的,filter是大概多少完全没概念。比如性别,许多开发人员喜欢用int或者varchar的数据类型,而又不会建索引;
大量数据查询,开发者明确知道一定是从磁盘读,而不是从内存读取,而优化器是不知道的;
一些特定的join顺序。
关于Sharding
Sharding是个好东西,MySQL开源解决方案也很多,不过目前MySQL官方仍然还在改良中。

Oracle的Sharding
MySQL Cluster + ndb engine的Sharding其实不错,不过要求比较严格,因此应用范围比较窄。
Sharding实现有两种可选路径,一种是类似于MongoDB的Sharding方式,完全对应用透明;另一种是由开发人员来选择Sharding key,灵活度高,同时也意味着对开发人员的要求提高。
从性能上说,尽可能不做跨库访问,或者跨库事务。但对于金融业务来说,分布式事务似乎是必然的,所以分布式事务的优化也是接下来8.0的重点改进。
越来越向Oracle靠近的MySQL
尽管MySQL的研发可能没觉得,但8.0实现的大多功能确实是Oracle已经非常成熟的功能,比如:
invisible index,Oracle11g实现,对我们删除一些潜在冗余索引非常有用;
Descending index;
Common table expressions,Oracle9i实现,with语句;
Improved performance of scans,缓存;
JSON aggregation;
Hints。
还有一些将开发或者正在开发的特性:
成本模型改进:histogram;
SQL WINDOWING分析函数;
缓存执行计划;
sequence(当前的自增长类型,会发生宕机后出现重复数据)。
这些特性Oracle都有了,或者说是好的东西,大家都会相互借鉴吧。这样,Oracle DBA以后转MySQL会更加容易,或者说,MySQL DBA不久的将来会变得没这么值钱。
JSON是个什么鬼?
JSON的全称是JavaScript Object Notation,一种数据交换格式,跟XML类似,比XML小巧。JSON在MySQL的内部是以BLOB的形式存储的。
JSON其实就是KEY-VALUE存储数据,网上的示例:
var a ={"one":"一","two":"二","three":"三"}
MongoDB的文档数据结构叫BSON(Binary JSON)格式,示例:
db.COLLECTION_NAME.insert(document);
>db.col.insert({title: 'Name',
description: '周小平',
TItle: '权贵网红',
Wechart: '我是周小平'
})
哪些场景用JSON比较合适呢?比如通过接口去调用天气情况,提供的API返回的都是JSON数据集合:{Location:上海,Date:2016年10月20日,Time:AM 10:00,AirQuality:优,temperature:24}。 比如高德地图的周边应用。

Oracle在5.7和8.0以及后续的版本中,都会大力加强JSON的支持,就是要夺回失地。5.7中有个亮眼的功能,通过虚拟列个JSON创建索引,类似Oracle里面的函数索引,避免查找数据的时候,到整改BLOB对象里去找。

MySQL研发的困惑
以往这种系统软件的研发,要比应用软件的研发远得多,细细交流下来,其实发现他们的困惑相差不大。
花了很长时间研发的一个核心功能/核心函数,居然不如一个很多时间研发的函数受欢迎!比如JSON Aggregation;
被追问到底哪个版本最稳定?当然是最新版本,一个版本的上线,不仅是研发人员,包括销售和服务支持者都有否决权;
为什么这么好的功能,比如Thread Pool不给大家免费使用?当然要看领导的决策了;
为什么这么多人盯着“没那么重要的”Hash Join?因为应用软件开发人员已经被Oracle惯得只会写烂SQL了,应用一致到MySQL就死了;
为什么日本使用者在呼吁开发日语collation的字符集,而中国的使用者不在乎?据现场的兄弟说因为通用字符集日本人无法比较出爹妈(片假名),而中文没有这个问题,而且中文顺序的敏感度低。
MySQL的高可用架构如何选择?
相信这是很多即将使用MySQL的新同学的问题。
这个问题,MySQL强烈推荐5.7已经发的innodb cluster,它包含三个部分:
MySQL Router(替代febric)
MySQL Shell
MySQL Group Replication
在9月份的旧金山OOW大会上,从MySQL3.2开始使用的开发者Frederic Descamps对其中的核心插件Group Replication做了分享(详细的PPT可以在这里看到:http://www.slideshare.net/lefred.descamps/mysql-innodb-cluster-group-replication):

有多好用还有待来自真实环境的反馈吧。除此之外,DBAplus社群分享过几个常用的高可用架构:
MySQL的市场份额在增大么?
目前还没有准确数据,但受欢迎程度MySQL基本上稳坐老二的位置,和老三SQL Server一起甩开MongoDB和Postgre几条街,他们和更后面的几位在稍稍的蚕食着Oracle的分值(不是市场占有率)。
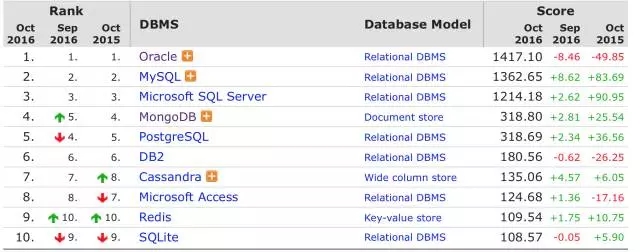
不过,据DB-engines 10月4日的文章,开源关系型数据库近半年来的受欢迎度在一个相对持平状态,不像之前一直处于上升的态势。

应该说,在MySQL越来越向Oracle靠近的过程中,传统行业的互联网业务(跟携程、微信、支付宝接口的业务、网上商城等)势必会越来越多的使用MySQL,而核心主营业务由于开发商的因素更换的可能性非常小。
MySQL对社区的支持力度会加大
类似于Oracle的很多新的特性是使用者通过CAB会议传达给研发部门,MySQL本身就是开源起家,社区的反馈会更加迅速。如果你有心仪的MySQL研发大咖,可以反馈给我们,DBAplus社群会邀请他们来参加线上或线下分享。







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721