
作者介绍 杨奇龙
前阿里数据库团队资深DBA,主要负责淘宝业务线,经历多次双十一,有海量业务访问DB架构设计经验。
目前就职于有赞科技,负责数据库运维工作,熟悉MySQL性能优化,故障诊断,性能压测。
前面写了一篇文章介绍innodb的特性,囿于相关知识点比较多 ,本文继续介绍5.7版本的innodb新特性。
1、 innodb buffer dump 功能增强
MySQL 5.7.5 版本新增innodb_buffer_pool_dump_pct参数,用于控制转储每个innodb buffer pool instance中innodb buffer pages的比例。之前的版本中该参数的默认值是100%。当触发转储的时候 会全量dump innodb buffer pool中的pages。如果启用新的参数比如40 ,每个innodb buffer pool instance中有100个 ,每次转储每个innodb buffer 实例中的40个pages。
注意:当innodb发现系统后台io资源紧张时,会主动降低该参数设置的比例。
2、支持多线程刷脏页
MySQL 5.6.2版本中,MySQL将刷脏页的线程从master线程独立出来,5.7.4版本之后,MySQL系统支持多线程刷脏页,线程的数量由innodb_page_cleaners参数控制,该参数不能动态修改,最小值为1 ,最大值支持64,5.7.7以及之前默认值是1 ,5.7.8版本之后修改默认参数为4。
当启用多线程刷脏时,系统将刷新innodb buffer instance脏页的任务分配给各个空闲的刷脏页的线程,如果设置的innodb_page_cleaners>innodb_buffer_pool_instances,系统会自动重置为innodb_buffer_pool_instances大小。
3、动态调整innodb buffer size
从5.7.5版本,MySQL支持在不重启系统的情况下动态调整innodb_buffer_pool_size。resize的过程是以chunk(每个chunk的大小默认为128M)的为单位迁移pages到新的内存空间,迁移进度可以通过Innodb_buffer_pool_resize_status 查看。记住整个resize的大小是以chunk为单位的。
innodb_buffer_pool_chunk_size的大小,计算公式是innodb_buffer_pool_size / innodb_buffer_pool_instances,新调整的值必须是 innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的整数倍。如果不是整数倍,则系统则会调整值为大于两者乘积的最大值。
例子
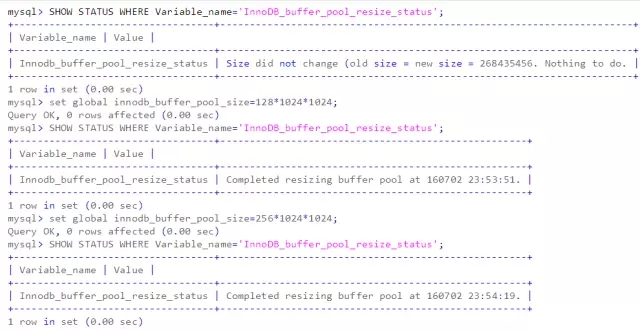
online调整bp size的log记录大致过程:
计算要调整的bpsize
禁止AHI,清理所有的索引缓存
Withdrawing block是遍历freelist 确定可以使用的空闲block
锁住整个buffer pool
迁移重新分配chunk/删除可以释放的chunk
设置innodb_buffer_pool_size为新的值
重新开启AHI

这个特性是最令众多MySQL DBA期待的特性之一。以后线上动态扩容,缩容就无需做数据库切换了,间接增强了系统的稳定性和DBA的生活幸福感。
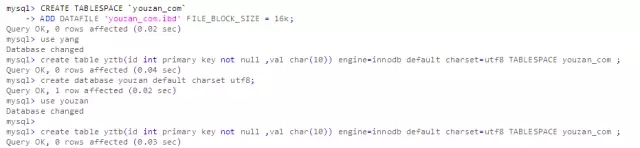
4、支持全局表空间
全局表空间可以被所有的数据库的表共享,而且相比于file-per-table tablespaces. 使用共享表空间可以节约元数据方面的内存。(需要更深入的了解共享表空间,主要是大小收缩问题)
5、行格式默认为DYNAMIC
从MySQL 5.7.9开始,行格式DYNAMIC取代COMPACT 成为innodb存储引擎默认的行格式,MySQL提供了新的参数innodb_default_row_format来控制Innodb 行格式,详细的信息请参考《Specifying the Row Format for a Table》。
6、支持原生的分区表
在MySQL 5.7.6之前的版本中,创建分区表时MySQL为每个分区创建一个ha_partition handler,自MySQL 5.7.6之后,MySQL支持原生的分区表并且只会为分区表创建一个partition-aware handler,这样的分区表功能增强节约分区表使用的内存。对于老版本创建的分区表在升级到新的版本之后怎么处理呢?莫慌,5.7.9之后,MySQL提供了如下升级方式解决这个问题:
ALTER TABLE ... UPGRADE PARTITIONING.
当然友情提示:从我个人的理解来看,在没有合适的自动化维护分区表系统的基础上,不推荐使用分区表。四年的工作经历已经数次在分区表上掉坑里了。
7、支持truncate undo logs
MySQL 5.7.5版本开始支持truncate undo 表空间中的undo log。启用该特性必须设置innodb_undo_log_truncate=[ON|1]。大致原理是系统必须设置至少两个undo 表空间(初始化的时候设置 innodb_undo_tablespaces=2 ) 用于清理undo logs的切换。该特性的好处是解决了 ibdata 文件一直增大的问题,减轻系统的空间使用。
1、支持JSON
从MySQL 5.7.8开始,MySQL支持原生的JSON格式,即有独立的json类型,用于存放JSON格式的数据。JSON格式的数据并不是以string格式存储于数据库而是以内部的binary格式,以便于快速的定位到JSON格式中值。
在插入和更新操作时MySQL会对JSON类型做校验,已检查数据是否符合JSON格式,如果不符合则报错。同时5.7.8版本提供了四种JSON相关的函数,从而不用遍历全部数据。

我们通过简单的例子来对JSON有一定的认识。
创建

初始化


修改

删除

查看JSON的key

其他函数的用法请感兴趣的读者朋友自行参考《官方文档》。
MySQL 5.7版本提供的JSON格式以及对应的操作函数极丰富了MySQL的存储格式,可以在一定程度上和Mongodb和PG竞争,对于经常使用MySQL varchar 存储JSON的业务是一个福音。同时再强调一下对于OLTP业务的表结构设计 尽可能的避免大字段存储。一来是减少不必要的查询带来的IO,带宽,内存方面的影响 二来是 避免因为表大小太大导致的ddl时间成本增加系统风险。
2、sys schema
MySQL 5.7版本新增了sys数据库,该库通过视图的形式把information_schema 和performance_schema结合起来,查询出更加令人容易理解的数据,帮助DBA快速获取数据库系统的各种纬度的元数据信息,帮助DBA和开发快速定位性能瓶颈。详细的信息请参考《官方文档》,这里给两个例子能直观的了解sys 功能的强大。

1、优化(工具方面)增强
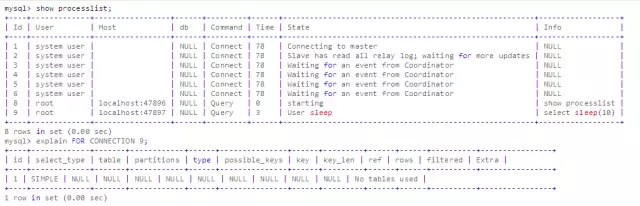
5.7版本中如果一个会话正在执行SQL,且该SQL是支持explain的,那么我们可以通过指定会话id,查看该SQL的执行计划。
EXPLAIN [options] FOR CONNECTION connection_id
该功能可以在一个会话里面查看另外一个会话中正在执行的长查询。
2、hint功能增强
相比于MySQL5.6版本的hint主要是index 级别的hint和控制表join顺序的hint,5.7.7之后,MySQL增加了优化器hint,来控制sql执行的方式,因为目前MySQL支持nest loop join,故暂时无hint来修改sql的join方式。熟悉Oracle的朋友是否会发现MySQL和Oracle在功能上越来越近了。话说回来5.7的hint (先别和 index hint 比较)的用法,和Oracle的类似:

优化器级别的hint分四种类型

其他更加详细的信息请参考《官方文档》。
3、触发器功能增强
5.7版本之前一个表对于每种action(INSERT,UPDATE, DELETE)和时机(BEFORE or AFTER) 只能支持一种类型的触发器。新版本可以针对同一个action支持多个触发器。
4、syslog功能
之前的版本,*nix系统上的MySQL支持将错误日志发送到syslog是通过mysqld_safe捕获错误输出然后传递到syslog来实现的。新的版本原生支持将错误日志输出到syslog,且适用于windows系统,只需要通过简单的参数(log_syslog等)配置即可。
MySQL支持–syslog选项,可将在交互式模式下执行过的命令输出到syslog中(*nix系统下一般是.mysql_history)。对于匹配“ignore”过滤规则(可通过 –histignore选项或者 MYSQL_HISTIGNORE环境变量进行设置)的语句不会被记入。
5、虚拟列
在MySQL 5.7中,支持两种Generated Column:
1)Virtual Generated Column :只将Generated Column保存在数据字典中表的元数据,每次读取该列时进行计算,并不会将这一列数据持久化到磁盘上;
注意:MySQL 5.7.8以前 虚拟列字段不支持创建索引。5.7.8之后Innodb支持在虚拟列创建辅助索引。
2)Stored Generated Column : 将Column持久化到存储,会占用一定的存储空间。与Virtual Column相比并没有明显的优势,因此,MySQL 5.7中,不指定Generated Column的类型,默认是Virtual Column。
创建虚拟列语法:

具体的例子
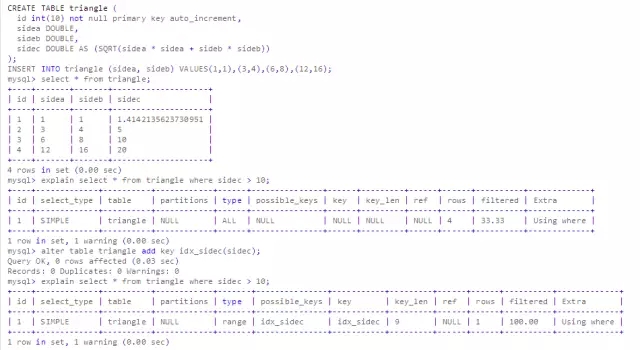
看到这个例子,熟悉oracle的朋友可能会和函数索引作比较,两者比较类似.使用虚拟列达到函数索引或者解决业务上的设计缺陷,但是个人不建议使用类似的功能,因为虚拟列在一定程度上也会给后期运维带来潜在的风险和复杂度。网络上的例子基本都是使用虚拟列解决业务逻辑上的问题,违背了数据库只存储数据的初衷,思考一下MVC框架的基本逻辑,业务逻辑要放到C层或者V层,M层只存放数据即可。
6、小结
本文算是对5.7版本innodb、对JSON格式的支持和功能类新特性做收尾,后面会介绍主从复制、GTID、InnoDB性能优化方面以及数据库升级相关的知识,这些特性更具有操作性,相对前面几篇文章会更难写。
另外学习5.7的过程中,我查看了很多MySQL的worklog,发现这里简直是一个MySQL资料宝库,很多功能的需求和原理讨论都可以在这里找到。想深入学习MySQL的朋友可以多钻研:http://dev.mysql.com/worklog
相关专题:
◆ 近期热文 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721