
关于如何实现MySQL主库高可用,是一个老生常谈的问题了,目前开源方案主要有MHA和MMM,各有优缺吧。笔者比较推崇的一个原则是“引入尽可能少的东西来满足需求”,所以先想到了“经典”的双主+keepalived架构。关于这个架构,网络上的资料基本都仅停留在对server和MySQL进程层面的监控来决定keepalived是否切换vip,其实这样做是远远不足以保证主库可用性及双主数据一致性的。
举例来说:很多时候主库不可用是由于负载过高或者是达到最大连接数等因素导致的,而server和MySQL进程层面却是正常的;另一方面,在keepalived切换过程中若没有严格的监测当时从库是否有延迟、主库上是否还有耗时的写操作等细节,就无法避免双主数据分列的产生。
因此,笔者在“双主+keepalived”架构的基础上,通过shell脚本主要从以下三个方面进行了改进:
如何有效地判断主库可用性(通过具体的查询语句来判定);
如何“优雅”地执行vip切换动作;
主库修复后,如何安全地将vip切回主库。
目前,这套系统在笔者的线上环境使用,数据库日查询量9000w以上,期间经历过几次切换,未出现数据不一致等异常。
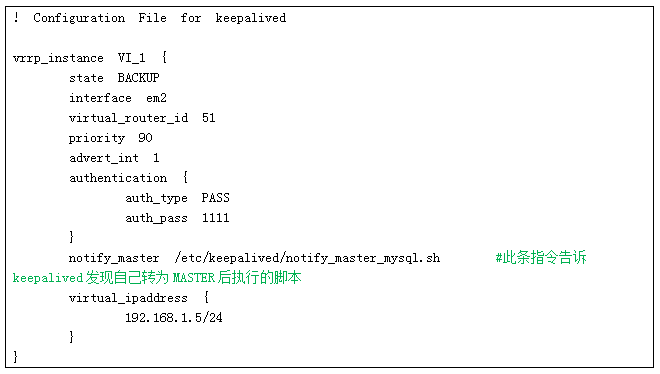
将DB1和DB2做成主动被动模式的双主结构:DB1主动、DB2被动,通过keepalived的VIP对外,将VIP设置成原DB1的IP,保证改造过程对代码透明。
三个前提:
两台MySQL的配置文件里需要加上“log_slave_updates = 1”;
并且“备用机”通过“read_only”参数实现除root用户之外的只读特性;
分别在两个数据库创建test.test表,插入几条数据,供检测脚本使用。
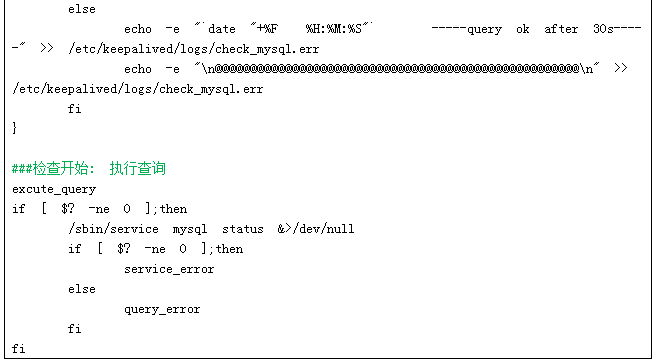
正常时,VIP在DB1,通过keepalived调用脚本定期检查mysql服务可用性(通过一个低权限用户连接mysql服务器并执行一个简单查询,根据返回结果来判定mysql是否可用)。
若无法执行查询:
1. 第一次检测失败后,检查服务状态:
若服务异常,则执行切换:关闭DB1的keepalived,使VIP漂移至DB2,通过DB2上keepalived的notify_master机制,触发脚本将DB2的mysql从被动状态(只读)切换到主动状态(可读写),并发送通知邮件。
若服务正常(则可能是一些临时性因素导致的监测失败),等待30s做第二次检查,这30s是对瞬时/短时因素造成检查失败的容忍时间,本着“能不切则不切”的原则。若第二次检查仍然失败
2. 开始执行系列切换动作
将DB1的MySQL设置为 read_only模式 (阻止写请继续求进入)
在DB1上kill掉当前客户端的线程。原来担心kill掉线程会对数据执行造成影响,后来查看了官方文档“mysql shutdown process”,发现mysql正常关闭过程也有一步是如此操作,所以这里可以放心了。然后 sleep 2,给kill命令一些时间(关于kill命令的机制,参考官方解释)
关闭DB1的keepalived,使DB2接管VIP。通过DB2上keepalived的notify_master机制,触发脚本将DB2的mysql从被动状态(只读)切换到主动状态(可读写),并发送通知邮件。
3. 管理员修复DB1后,通过脚本“change_to_backup.sh”将主库切换回DB1。脚本思路如下:
(注:涉及到切换主备,就会有中断时间,所以推荐此步骤在业务低谷期执行)
将DB2的read_only属性置为1
kill掉DB2上的client线程,并重启DB2的keepalived使VIP漂移至DB1
确定DB1跟上了DB2的更新,并将DB1上的read_only属性移除
关于“数据一致性”和“切换时间”:
连续两次失败以后,通过对主MySQL设置read_only属性,同时kill掉用户线程来保证在DB2接管服务之前,DB1上已经没有写操作,避免主从数据不一致。并且切换时间基本上是可确定的:
keepalived检测间隔笔者设置为30s(可调整)
若server或MySQL进程级故障,则马上切换,切换时间 < 2s(keepalived切换时间)
若其他原因,则切换时间 < 30s(shell脚本里尽量避免切换而等待30s,可调整)+2s(给kill 主库sql的时间)+2s(keepalived切换时间)
以上是大致思路,具体实现看过下面的脚本,就会一目了然了。
DB1上keepalived配置

/etc/keepalived/check_mysql.sh脚本内容如下(主要的判断逻辑都在这里)


DB2上keepalived配置:
/etc/keepalived/notify_master_mysql.sh脚本内容:

DB2上手动切换回DB1的脚本change_to_backup.sh:


日志截图:
DB1 mysql服务故障:

DB1 mysql服务正常,查询失败:

DB2 一次切换过程:

DB2 执行脚本手动切回DB1:

此方案解决了主从中master节点的单点问题;同时,在此基础上,可以再增加从库和中间件实现读写分离等架构。
作者介绍 李建凯
6年Linux运维经验,现混迹动漫行业,任职动漫之家运维经理。
经历过五六台server的“小作坊”,也见识过日pv近亿的“大考验“。多年的一线工作积累了丰富的trouble shooting经验。
擅长应用运维,对数据库感兴趣并对MySQL有些研究。
经作者同意授权转载
作者:李建凯
博客:奋进的K
原文链接:http://kaifly.blog.51cto.com/3209616/1665729
老规矩,在本文评论区留下足以引起共鸣的真知灼见,并在本文发布后24小时之内成为点赞数最多的前2名,可获得以下书籍一本哦~

特别鸣谢博文视点(www.broadview.com.cn)为本次活动提供图书赞助。
全球敏捷运维峰会【北京站】
2016年6月11日,DBA+社群联合运维帮、Linux中国开启全球敏捷运维峰会第二站:北京站!峰会力邀来自百度、新浪、58到家、小米、搜狐畅游、浙江移动、新炬网络、日志易等互联网与传统企业的资深大咖,汇聚500+行业精英!原价169元的门票限时免费,原价599元的VIP票,限时199元(优惠码:dbavip)!快扫码抢座吧~









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721