
作者介绍
张秀云,网名飞鸿无痕,现任职于腾讯,负责腾讯金融数据库的运维和优化工作。2007年开始从事运维方面的工作,经历过网络管理员、Linux运维工程师、DBA、分布式存储运维等多个IT职位。对Linux运维、MySQL数据库、分布式存储有丰富的经验。简书地址:
https://www.jianshu.com/u/9346dc2e9d3e
作为一名DBA,我们在工作中会经常遇到一些MySQL主从同步延迟的问题,这些同步慢的问题,其实原因非常多:可能是主从的网络问题导致的,可能是网络带宽问题导致的,可能是大事务导致的,也可能是单线程复制导致的延迟。
近期笔者遇到了一个很典型的同步延迟问题,在此将分析过程写出来,希望能够为广大DBA在排查同步延迟问题时提供比较系统的方法论。
一、背景
最近有一组DB出现比较大的延迟,这组DB是专门用来存储监控数据的,每分钟会使用Load Data的方式导入大量的数据。为了节省空间,将原来使用压缩表的InnoDB引擎转换成了TokuDB引擎,使用的版本和引擎如下:
MySQL Version: 5.7
Storage Engine: TokuDB
转换后,发现主从延迟逐渐增大,基本每天落后主机大概50个binlog左右,大概延迟7.5个小时左右的数据,主机每天大概产生160个binlog,binlog列表如下图所示:
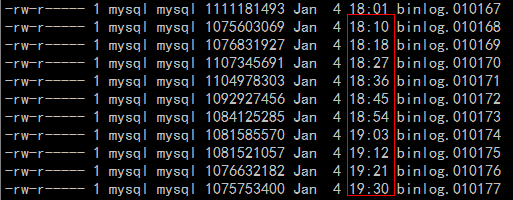
由于对该业务非常熟悉,因此很快就定位到造成主从同步延迟的原因,并很快就解决了延迟的问题。这里不直接说解决办法,而是想描述一套完整的解决主从延迟问题的思考方式,和大家一起来系统的做一些思考。
带着问题去思考延迟的根本原因和解决办法,这也许会更有意义。授人以鱼,不如授人以渔。接下来我们就一起开脑洞吧。
二、思考
首先,既然产生了主从延迟,就说明在从机上的消费速度赶不上主机binlog产生的速度。我们先来思考一下可能的原因,并根据现场的蛛丝马迹去验证猜想的正确性。其实所谓的问题排查,就是提出可能问题猜想,然后不断去证明的过程。不同的是,每个人的经验不同,排查的质量也不尽头相同,仅此而已。
网络可能导致主从延迟的问题,比如主机或者从机的带宽打满、主从之间网络延迟很大,有可能会导致主上的binlog没有全量传输到从机,造成延迟。
笔者的那组DB的IO线程已经将对应的binlog近乎实时地拉取到了从机DB上,基本排除网络导致的延迟,还可以结合网络质量相关监控来进一步确认是网络的问题。
从机使用了烂机器?
之前有遇到过有的业务从机使用了很烂的机器,导致的主从延迟。比如主机使用SSD,而从机还是使用的SATA。从机用烂机器的观念需要改改,随着DB自动切换的需求越来越高,尤其是笔者所在的金融行业,从机至少不要比主机配置差。
从机高负载?
有很多业务会在从机上做统计,把从机服务器搞成高负载,从而造成从机延迟很大的情况,这种使用top命令即可快速发现。
从机磁盘有问题?
磁盘、Raid卡、调度策略有问题的情况下,有时会出现单个IO延迟很高的情况,比如Raid卡电池充放电时,在没有设置强行write back的情况下得会将write back模式修改为write through。
使用iostat命令查看DB数据盘的IO情况,是否是单个IO的执行时间很长、块大小和磁盘队列情况等,可以比较一下DB盘的IO调度规则以及块大小的设置等。
使用iostat查看IO运行情况:
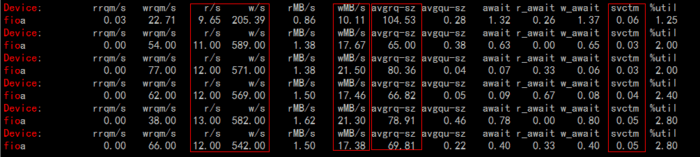
从IO情况看也没什么问题,单个IO延迟很小,IOPS很低,写带宽也不大。调度规则(cat /sys/block/fioa/queue/scheduler)和块大小等和主机设置是一样的,排除掉磁盘的问题。
从运行指标看,机器负载很低,机器性能也可以排除。
是否经常会有大事务?
这个可能DBA们会遇到比较多,比如在RBR模式下,执行带有大量的Delete操作,或者在MBR模式下删除时添加了不确定语句(类似limit)或一个表的Alter操作等,都会导致延迟情况的发生。
这种可通过查看Processlist相关信息,以及使用mysqlbinlog查看binlog中的SQL就能快速进行确认。这个设想也被排除。
锁冲突问题也可能导致从机的SQL线程执行慢,比如从机上有一些select .... for update的SQL,或者使用了MyISAM引擎等。此类问题,可以通过抓去Processlist以及查看information_schema下面和锁以及事务相关的表来查看。
经过排查也并未发现锁的问题。
参数部分使用如果是InnoDB引擎,可以根据自己的使用环境调整innodb_flush_log_at_trx_commit、sync_binlog参数来提升复制速度,那组DB使用的TokuDB,则可以优化tokudb_commit_sync、tokudb_fsync_log_period、sync_binlog等参数来做调整。这些参数调整后,复制的延迟情况会有一些作用。
备注:这种调整可能会影响数据的安全性,需要结合业务来考虑。
多线程问题可能是DBA们遇到最多的问题,之前在5.1和5.5版本,MySQL的单线程复制瓶颈就广受诟病。从5.6开始MySQL正式支持多线程复制。
很容易想到,如果是单线程同步的话,单个线程存在写入瓶颈,导致主从延迟。那就先调整为多线程试试效果。
可以通过Show Processlist查看是否有多个同步线程,也可以查看参数的方式查看是否使用多线程(show variables like '%slave_parallel%')
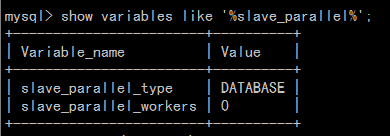
当你看到是上图这种结果时,恭喜你,你使用的是单线程。可使用下面那行命令改造成多线程复制:
STOP SLAVE SQL_THREAD;
SET GLOBAL
slave_parallel_type='LOGICAL_CLOCK';
SET GLOBAL
slave_parallel_workers=8;
START SLAVE SQL_THREAD;
改造后如下图所示:

我的环境如上图所示,本来就已经是多线程复制了,因此问题的根源也不在是否开启多线程复制上。但当我使用Show Processlist查看复制状态时,大多数情况下发现只有1个SQL线程在执行,如下图所示:
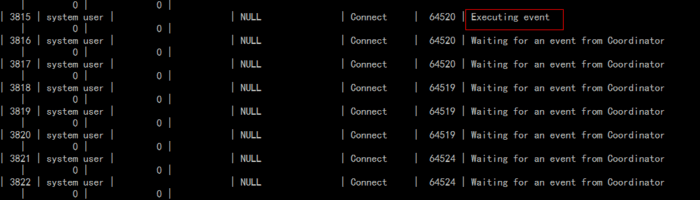
通过上面的图可发现,基本都是一个线程在执行,那么可初步判定是多线程的威力没有得到很好的发挥,为了更有力地说明问题,想办法统计出来每个同步线程使用的比率。统计方法如下:
1、将线上从机相关统计打开(出于性能考虑默认是关闭的),打开方法如下:
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE 'events_transactions%';
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'WHERE NAME = 'transaction';
2、创建一个查看各同步线程使用量的视图,代码如下:
USE test;
CREATE VIEW rep_thread_count AS SELECT a.THREAD_ID AS THREAD_ID,a.COUNT_STAR AS COUNT_STAR FROMperformance_schema.events_transactions_summary_by_thread_by_event_name a WHERE a.THREAD_ID in (SELECT b.THREAD_ID FROM performance_schema.replication_applier_status_by_worker b);
3、一段时间后统计各个同步线程使用比率,SQL如下:
SELECT SUM(COUNT_STAR) FROMrep_thread_count INTO @total;
SELECT 100*(COUNT_STAR/@total) AS thread_usage FROMrep_thread_count;
结果如下:
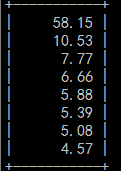
从上面的结果可以看出,绝大多数情况下,都是一个线程在跑,在监控这种存在大量数据导入的场景下肯定容易出现瓶颈。如果能提高各个线程并发执行的能力,也许能很好地改善同步延迟的情况,那如何解决呢?
我们不妨从多线程同步的原理来思考,在5.7中,多线程复制的功能有很很大的改善,支持LOGICAL_CLOCK的方式,在这种方式下,并发执行的多个事务只要能在同一时刻commit,就说明线程之间没有锁冲突,那么Master就可以将这一组的事务标记并在slave机器上安全的进行并发执行。
因此,可以尽可能地使所有线程能在同一时刻提交,这样就能很大程度上提升从机的执行的并行度,从而减少从机的延迟。
有了这个猜想后,很自然想到了人为控制尽可能多地使所有线程在同一时刻提交,其实官方已经给我们提供了类似的参数,参数如下:
备注:这个参数会对延迟SQL的响应,对延迟非常敏感的环境需要特别注意,单位是微秒。
参数说明见:
https://dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html#sysvar_binlog_group_commit_sync_delay
备注:这个参数取到了一定的保护作用,在达到binlog_group_commit_sync_no_delay_count设定的值的时候,不管是否达到了binlog_group_commit_sync_delay设置定的阀值,都立即进行提交。
参数说明见:
https://dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html#sysvar_binlog_group_commit_sync_no_delay_count
由于是监控的DB,主要是load数据,然后进行展示,1秒左右的导入延迟对业务没什么影响,因此将两个参数调整为:
SET GLOBAL binlog_group_commit_sync_delay = 1000000;
SET GLOBAL binlog_group_commit_sync_no_delay_count = 20;
备注:这两个参数请根据业务特性进行调整,以免造成线上故障。
为了防止导入SQL堆积,设置SET GLOBAL binlog_group_commit_sync_no_delay_count为20,在达到20个事务时不管是否达到了1秒都进行提交,来减少对业务的影响。
设置完这两个参数后,发现并发复制瞬间提升了好多,很多时候8个线程都能跑满。于是将线程调整到16个。运行一段事件后,再次统计各个同步线程的使用比率,发现并发度提升了非常多,新的比率如下图所示:
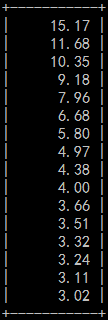
通过show slave status查看,发现从机延迟越来越小,目前已经完全追上,并稳定运行了一周。
三、总结
最后简单总结一下,在遇到主从延迟的问题时,可从以下几个地方开脑洞,寻找蛛丝马迹,找到问题的根源,对症下药才能药到病除,排查范围包括但不限于如下几方面:
网络方面
性能方面
配置方面(参数优化)
大事务
锁
多线程复制
组提交
通过上面对整个问题排查的梳理,希望能够帮助广大DBA在遇到类似复制延迟的问题时彻底终结问题。
https://dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html
https://www.percona.com/blog/2016/02/10/estimating-potential-for-mysql-5-7-parallel-replication/









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒