
刘世勇,曾就职于华为、网易,2015年初加入链家网,负责链家网数据库的运维、数据库架构设计、DB自动化运维平台的构建等工作。
在MySQL中,通过slow log,我们可以发现线上的慢查询,并且结合监控和pt-toolkit,我们能够比较快速地发现慢查询,并且根据总响应时间、执行次数、平均响应时间等多个维度去分析和统计慢查询。可是如果我们的DB是经过了大量的SQL和业务优化,在当前的配置下,slow log中几乎已经没有慢查询了,可是整个库的负载还是非常高,或者是某些项目刚上线,经常会因为缓存策略不合理导致大量的请求穿透到DB,可是这些请求又不是慢查,很难排查这种抖动的问题。这个时候怎么办呢?我们能够以什么为切入点更深一步地做一些调优呢?
一种方法就是将slow log的阈值尽可能的减小,或者打开general log,可是这样对性能的影响是非常大的,因为会新增很多的IO操作。当然可以间歇性地调整,可是这样运维成本和复杂度就高了,一两个集群还勉强,集群多了之后,问题就会凸显出来了。而且从另一方面来讲,这种计划性的调整很难应对线上一些偶发性的问题。
还有没有别的办法呢?此时我忍不住怀念起Oracle的AWR。使用过Oracle的同学都知道,Oracle是一个功能强大的性能分析工具,看懂AWR报告也是Oracle DBA的基本功之一。在AWR里面,有个SQL stat的功能,实际上就是对某段时间内,整个DB执行过的SQL统计和分析报告。区别于MySQL slow log的是,这种统计报告是全量的,而slow log仅仅只是慢查,遇到一些高频的、快速的查询,slow log就没有了参考价值。有前辈高人参考Oracle的AWR写过一个myawr(https://github.com/noodba/myawr),但是这个工具也仅仅支持了slow log的统计结果。那有没有办法能够像Oracle AWR一样,能够统计和分析全量的SQL执行情况呢?有,那就是perfomance schema。当然仅仅是perfomance schema还不够,还需要将其中的SQL执行的统计数据拿出来作分析和展示。分析数据和展示数据都是借助myawr来做的。
本文内容主要分析如何开启PS来获得SQL执行的统计信息、怎么将全量的SQL统计信息录入myawr、怎么分析和展示SQL执行的统计数据。
在使用perfomance schema之前,必须先开启它。开始PS其实比较简单,只要在配置文件中添加下面一行配置就可以:
但是,仅仅打开PS还不够,因为默认PS开启的功能比较少。因为我们需要做全量的SQL统计,所以需要依赖PS中events_statements_summary_by_digest这个表的数据。这就需要在PS的setup_consumers中,将name和statements相关的值设置为YES:
update performance_schema.setup_consumers
set ENABLED = 'YES'
where NAME like 'events_statements%';
同时,还需要将setup_instruments表中,name和statements相关的值设置为YES:
update performance_schema.setup_instruments
set ENABLED = 'YES', TIMED = 'YES'
where NAME like 'statement%';
打开之后,接下来就需要将SQL统计数据接入myawr中。由于myawr最初没有对PS的支持,所以我们需要从头开始改造myawr。
第一步是创建表,用于存储统计数据。设计表的时候,为了和myawr原有的表的表结构保持一致,前三个字段还是分别为id、snap_id和host_id,snap_id是快照ID,和一个具体的snapshot对应,这个在生成最后的myawr报告时,非常有用,host_id是MySQL实例的ID。剩下的字段,都是从performance_schema.events_statements_summary_by_digest这个表中,根据实际的需求摘取出来的。
我们先看看这个表的结构:
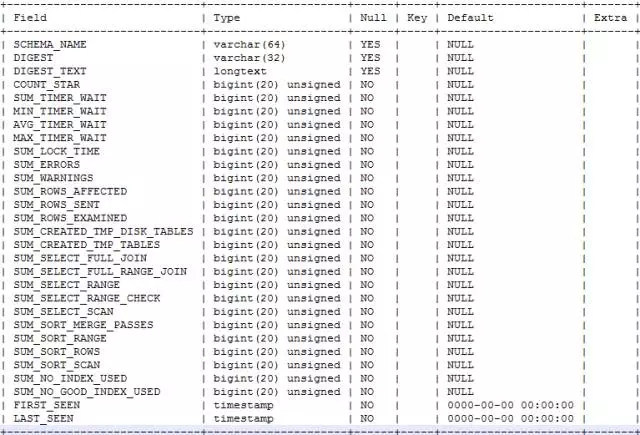
SCHEMA_NAME
SQL执行时的default database
DIGEST
一个hash值,代表结构相同的一类SQL
DIGEST_TEXT
通过正则过滤后的SQL文本,没有具体参数值,代表结构相同的一类SQL
COUNT_STAR
代表这一类SQL一共执行了多少次,这是一个累积值,只有实例重启才会重置
SUM_TIMER_WAIT ~ SUM_NO_GOOD_INDEX_USED
这一系列的字段,都是从不同维度对SQL进行的统计,可以根据自己关注的侧重点,按需查询
FIRST_SEEN
SQL第一次执行的时间
LAST_SEEN
SQL最近一次执行的时间,这个字段在收集SQL统计数据和最终生成myawr报告时都会用到
为了设计上的简单,我把performance_schema.events_statements_summary_by_digest所有的字段都包含进去,命名为myawr_snapshot_events_statements_summary_by_digest,最终的myawr中的表结构如下:

创建好表之后,接下来就是将PS的数据录入这个表。录入时,需要做一些简单的筛选,因为可能有一些SQL很长时间都没有被执行过了,这样的SQL的统计数据就不用重复的接入到myawr的数据库中。这时候过滤就需要用上上面说的LAST_SEEN这个字段,我们目前的设计是只录入最近24小时被执行过的SQL的统计信息,具体数据查询的SQL为select * from performance_schema.events_statements_summary_by_digest where LAST_SEEN > date_sub(now(), interval 24 hour)。确定数据采集方式之后,只需要在myawr的数据采集脚本中,将这部分功能逻辑添加进去即可。
一个需要注意的地方是数据量,因为SQL执行的全量统计信息是非常大的。一方面需要考虑表的设计,在建表时就将表按照时间分区,避免后面数据写入成为瓶颈。另外,可以在部署数据采集任务时,适当地调整采样周期,这直接决定了数据写入的频率。
数据录入到myawr的数据库之后,接下来的工作就是分析和展示了。实际上就是从各个不同的维度去出分析报告,最终在报告里面展示的数据是一样的,只是不同的分析维度的排序规则不一样。下面,从总执行时间、总执行次数、总扫描记录数、总返回记录数、总排序记录数5个维度去分析如何生成myawr报告。分析维度的选取,是根据日常运维的需求而定的,大家可以根据自己的实际需求,从myawr_snapshot_events_statements_summary_by_digest中选取其他的一些维度。
总执行时间是在整个DB性能分析时非常有用的信息,可以据此分析出当前整个DB的资源消耗的分布情况。总执行时间对应myawr_snapshot_events_statements_summary_by_digest这个表的SUM_TIMER_WAIT字段,生成报告的查询SQL如下:

$tid
host_id,即对哪个MySQL实例生成myawr报告
$start_snap_id
为myawr报告的起始快照ID
$start_snap_time
为$start_snap_id对应的时间点
$end_snap_id
为myawr报告的终止快照ID
$end_snap_time
为$end_snap_id对应的时间点
最终在myawr报告中展示为:
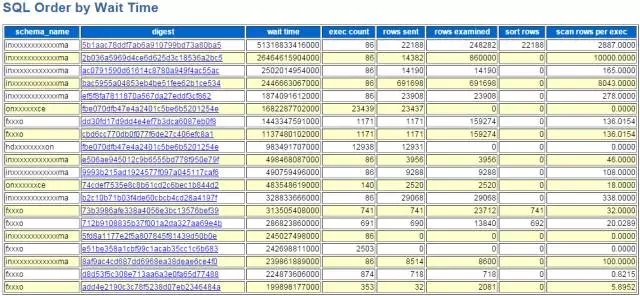
总执行次数在分析某一固定时间段的故障时比较有参考价值。总执行次数对应myawr_snapshot_events_statements_summary_by_digest这个表的COUNT_STAR字段,生成报告的查询SQL如下:

最终在myawr报告中展示为:
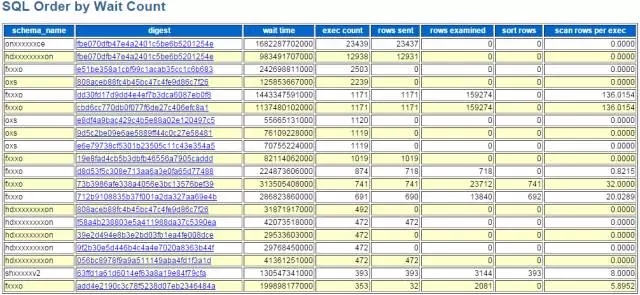
总扫描记录数,以及后面的总返回记录数、总排序次数,都是在分析某一固定时间段的某一类问题故障时比较有参考价值。总扫描记录数对应myawr_snapshot_events_statements_summary_by_digest这个表的SUM_ROWS_EXAMINED字段,生成报告的查询SQL如下:

最终在myawr报告中展示为:

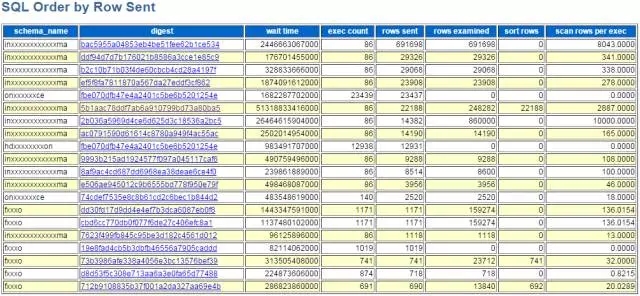
总返回记录数,实际上是指返回给客户端的记录数,也就是最终结果集的大小。如果你发现网卡流量突增,可以从这个角度去分析一下。总返回记录数对应myawr_snapshot_events_statements_summary_by_digest这个表的SUM_ROWS_SENT字段,生成报告的查询SQL如下:

最终在myawr报告中展示为:
总排序记录数,对应myawr_snapshot_events_statements_summary_by_digest这个表的SUM_ROWS_SENT字段,生成报告的查询SQL如下:

最终在myawr报告中展示为:
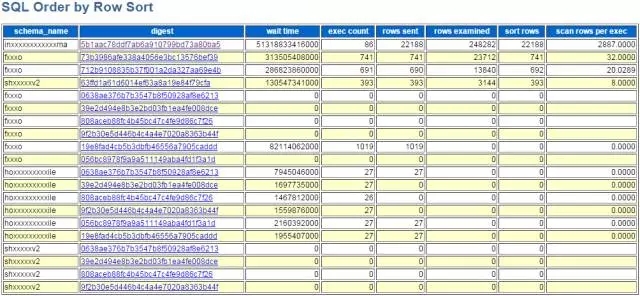
通过将performance schema中的SQL执行统计数据,录入到myawr,扩展了myawr的功能,实现了全量SQL执行情况统计分析,填补了slow log功能上的空白,为解决和分析线上问题提供了更多的参考依据。
除了SQL统计信息,其实在perfomance schema中还有很多有用的信息,比如类似Oracle AWR的等待事件、文件IO统计、连接统计等,这些能为DBA的日常故障排查、性能调优提供非常多的帮助,所以perfomance schema是非常值得尝试的一个特性。这些信息我们实际上也已经添加到myawr中,成为日常运维工作的一个很重要的工具。当然有得必有失,开启perfomance schema会对性能有一些影响,也会消耗额外的内存。不过,只要前期经过严谨的测试,这些影响都是可以控制的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721