
作者介绍
李华荣,网名小麦苗,长期专注Oracle数据库研究,具有交通、金融、政府、移动、医疗、电信等行业的运维经验。兴趣爱好广泛,热衷技术分享,对SQL语句优化、备份恢复、数据库巡检、数据库监控等有深入的钻研,熟悉DG、RAC,OGG及AIX,HP-UX,LINUX等主流操作系统平台。个人公众号:xiaomaimiaolhr。
前段时间工作上碰到了一个很奇怪的死锁问题,一般来说,由业务发出来的SQL是不太可能会产生死锁的,不过确确实实产生了,而且还是ITL死锁!于是借此机会,也把死锁可能出现的情况都分类总结了一下,分享给大家,欢迎探讨交流。
先看下大纲:
死锁的概念及其trace文件
死锁的分类
行级死锁的模拟
ITL的概念、ITL结构
ITL引发的死锁处理
ITL死锁的模拟
1什么是死锁?
所谓死锁,是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。Oracle对于“死锁”是要做处理的,而不是不闻不问。


2死锁的trace文件
Oracle中产生死锁的时候会在alert告警日志文件中记录死锁的相关信息,无论单机还是RAC环境都有Deadlock这个关键词,而且当发生死锁时都会生成一个trace文件,这个文件名在alert文件中都有记载。由于在RAC环境中,是由LMD(Lock Manager Daemon)进程统一管理各个节点之间的锁资源的,所以,RAC环境中trace文件是由LMD进程来生成的。
在RAC环境中,告警日志的形式如下所示:

在单机环境中,告警日志的形式如下所示:

通常来讲,对于单机环境,当有死锁发生后,在trace文件中会看到如下的日志信息:
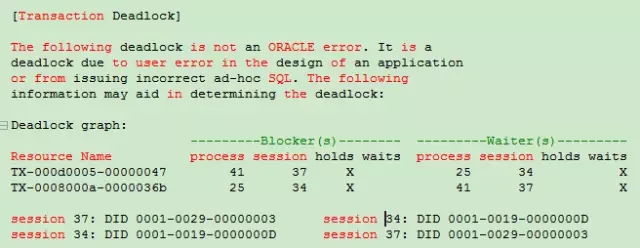
图 2-1 单机环境下的死锁
当看到trace文件时,需要确认一下产生锁的类型,是两行还是一行,是TX还是TM,如果只有一行那么说明是同一个SESSION,可能是自治事务引起的死锁。
对于RAC环境,当有死锁发生后,在trace文件中会看到如下的日志信息:
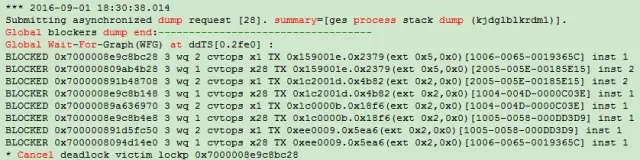
图 2-2 RAC环境下的死锁
3死锁的检测时间
死锁的监测时间是由隐含参数_lm_dd_interval来控制的,在Oracle 11g中,隐含参数_lm_dd_interval的值默认为10,而在Oracle 10g中该参数默认为60,单位为秒。
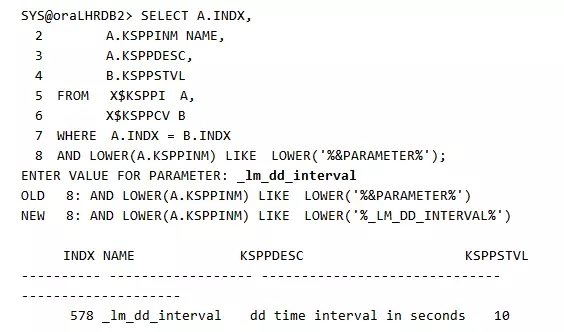
可以看到该隐含参数的值为10。
有人的地方就有江湖,有资源阻塞的地方就可能有死锁。Oralce中最常见的死锁分为:行级死锁(Row-Level Deadlock)和块级死锁(Block-Level Deadlock),其中,行级死锁分为①主键、唯一索引的死锁(会话交叉插入相同的主键值),②外键未加索引,③表上的位图索引遭到并发更新,④常见事务引发的死锁(例如,两个表之间不同顺序相互更新操作引起的死锁;同一张表删除和更新之间引起的死锁),⑤自治事务引发的死锁。块级死锁主要指的是ITL(Interested Transaction List)死锁。
死锁分类图如下所示:
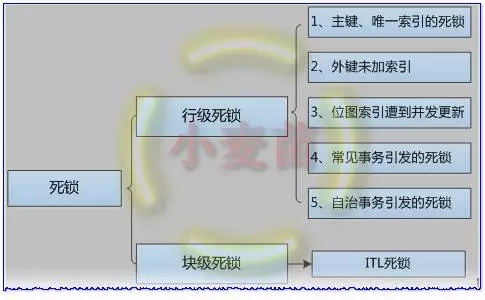
图 2-3 死锁的分类图
1行级死锁
行级锁的死锁一般是由于应用逻辑设计的问题造成的,其解决方法是通过分析trace文件定位出造成死锁的SQL语句、被互相锁住资源的对象及其记录等信息,提供给应用开发人员进行分析,并修改特定或一系列表的更新(UPDATE)顺序。
以下模拟各种行级死锁的产生过程,版本都是11.2.0.4。
主键、唯一索引的死锁(会话交叉插入相同的主键值)
主键的死锁其本质是唯一索引引起的死锁,这个很容易模拟出来的,新建一张表,设置主键(或创建唯一索引)后插入一个值,然后不要COMMIT,另一个会话插入另一个值,也不要COMMIT,然后再把这两个插入的值互相交换一下,在两个会话中分别插入,死锁就会产生。
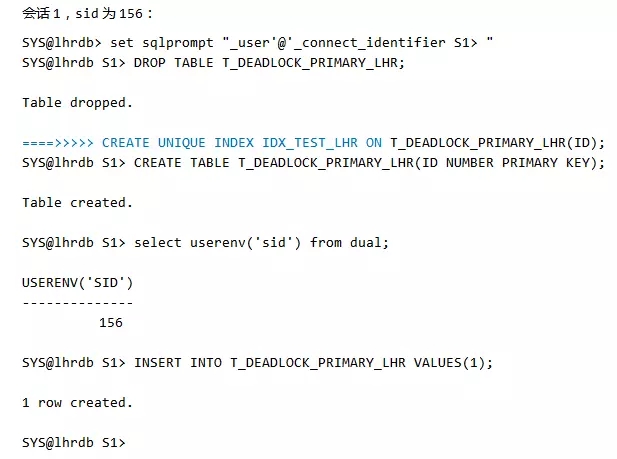
会话2,sid为156:


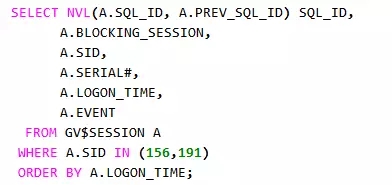

156阻塞了191会话,即会话1阻塞了会话2。
会话1再次插入数据:
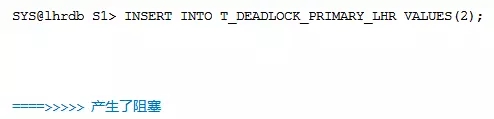
此时,去会话2看的时候,已经报出了死锁的错误:
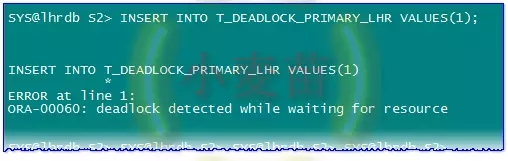
此时的阻塞已经发生了变化:

告警日志:

其内容可以看到很经典的一段:
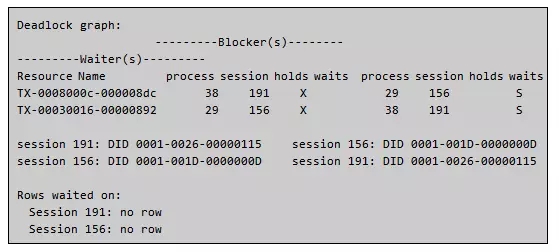
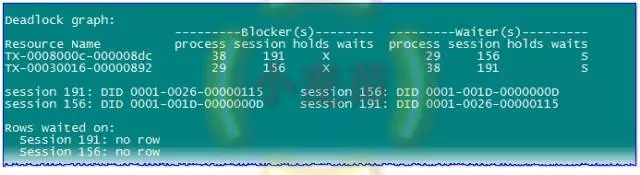
这就是主键的死锁,模拟完毕。
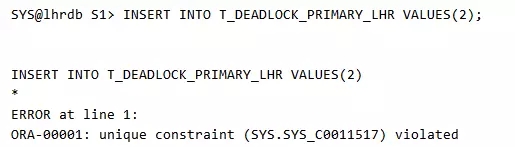
此时,若是会话2执行提交后,会话1就会报错,违反唯一约束:
外键的死锁(外键未加索引)
外键未加索引很容易导致死锁。在以下两种情况下,Oracle在修改父表后会对子表加一个全表锁:
如果更新了父表的主键,由于外键上没有索引,所以子表会被锁住。
如果删除了父表中的一行,由于外键上没有索引,整个子表也会被锁住。
总之,就是更新或者删除父表的主键,都会导致对其子表加一个全表锁。
如果父表存在删除记录或者更改外键列的情形,那么就需要在子表上为外键列创建索引。
外键的死锁可以这样通俗的理解:有两个表A和B:A是父表,B是子表。如果没有在B表中的外键加上索引,那么A表在更新或者删除主键时,都会在表B上加一个全表锁。这是为什么呢?因为我们没有给外键加索引,在更新或者删除A表主键的时候,需要查看子表B中是否有对应的记录,以判断是否可以更新删除。那如何查找呢?当然只能在子表B中一条一条找了,因为我们没有加索引吗。既然要在子表B中一条一条地找,那就得把整个子表B都锁定了。由此就会导致以上一系列问题。
实验过程:
会话1:首先建立子表和父表

会话1执行一个删除操作,这时候在子表和父表上都加了一个Row-X(SX)锁。
查询会话1的锁信息:


BLOCK为0表示没有阻塞其它的锁。
会话2:执行另一个删除操作,发现这时候第二个删除语句等待
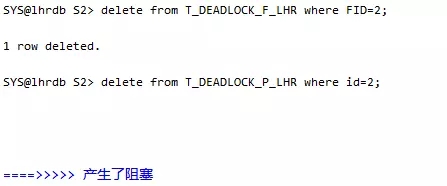
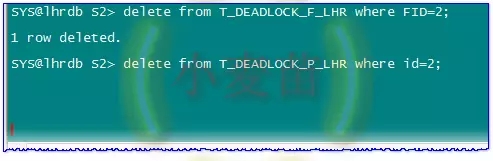

BLOCK为1表示阻塞了其它的锁。
会话1执行删除语句,死锁发生。
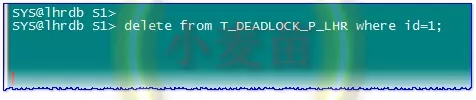
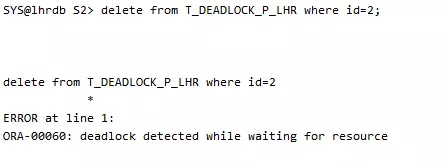

告警日志:

查看内容:
回滚会话建立外键列上的索引:

重复上面的步骤会话1删除子表记录:
---会话1:
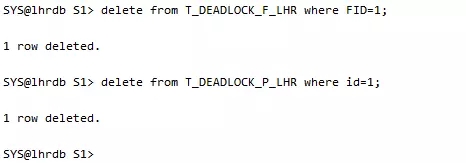
---会话2:

所有的删除操作都可以成功执行,也没有阻塞的生成,重点就是在外键列上建立索引。


位图(BITMAP)索引死锁
表上的位图索引遭到并发更新也很容易产生死锁。在有位图索引存在的表上面,其实很容易就引发阻塞与死锁。这个阻塞不是发生在表上面,而是发生在索引上。因为位图索引锁定的范围远远比普通的b-tree索引锁定的范围大。
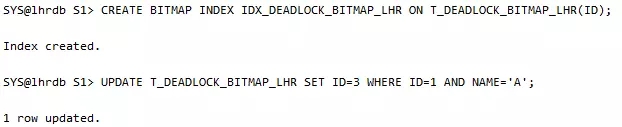
那么在ID列上建bitmap index的话,所有ID=1的会放到一个位图中,所有ID=2的是另外一个位图,而在执行DML操作的时候,锁定的将是整个位图中的所有行,而不仅仅是DML涉及到的行。由于锁定的粒度变粗,bitmap index更容易导致死锁的发生。
会话1:此时所有ID=1的行都被锁定

会话2:此时所有ID=2的行都被锁定
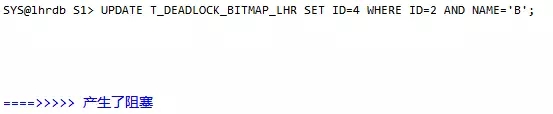
会话1:此时会话被阻塞


会话2:会话被阻塞

再回到SESSION 1,发现系统检测到了死锁的发生

告警日志:
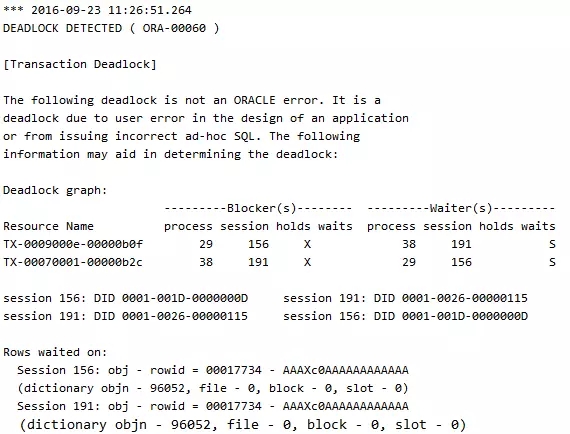
内容:
死锁发生的根本原因是对于资源的排他锁定顺序不一致。上面的试验中,session1对于bitmap index中的2个位图是先锁定ID=1的位图,然后请求ID=2的位图,而在此之前ID=2的位图已经被session2锁定。session2则先锁定ID=2的位图,然后请求ID=2的位图,而此前ID=1的位图已经被session1锁定。于是,session1等待session2释放ID=2的位图上的锁,session2等待session1释放ID=1的位图上的锁,死锁就发生了。而如果我们创建的是普通的B*Tree index,重复上面的试验则不会出现任何的阻塞和死锁,这是因为锁定的只是DML操作涉及到的行,而不是所有ID相同的行。
常见事务引发的死锁
如果你有两个会话,每个会话都持有另一个会话想要的资源,此时就会出现死锁(deadlock)。例如,如果我的数据库中有两个表A和B,每个表中都只有一行,就可以很容易地展示什么是死锁。我要做的只是打开两个会话(例如,两个SQL*Plus会话)。在会话A中更新表A,并在会话B中更新表B。现在,如果我想在会话B中更新表A,就会阻塞。会话A已经锁定了这一行。这不是死锁;只是阻塞而已。因为会话A还有机会提交或回滚,这样会话B就能继续。如果我再回到会话A,试图更新表B,这就会导致一个死锁。要在这两个会话中选择一个作为“牺牲品”,让它的语句回滚。想要更新表B的会话A还阻塞着,Oracle不会回滚整个事务。只会回滚与死锁有关的某条语句。会话B仍然锁定着表B中的行,而会话A还在耐心地等待这一行可用。收到死锁消息后,会话B必须决定将表B上未执行的工作提交还是回滚,或者继续走另一条路,以后再提交。一旦这个会话执行提交或回滚,另一个阻塞的会话就会继续,好像什么也没有发生过一样。
模拟一:两个表之间不同顺序相互更新操作引起的死锁
1、创建两个简单的表A和B,每个表中仅仅包含一个字段id。

2、每张表中仅初始化一条数据

3、在第一个会话session1中更新表A中的记录“1”为“10000”,不提交;在第二个会话session2中更新表B中的记录“2”为“20000”,不提交
session1的情况:


session2的情况:
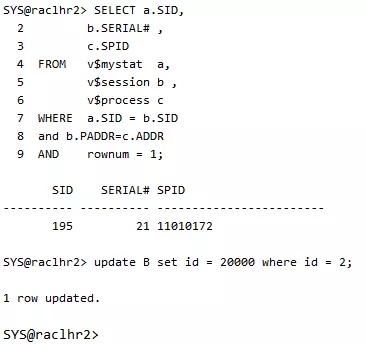
此时,没有任何问题发生。OK,现在注意一下下面的现象,我们再回到会话session1中,更新表B的记录,此时出现了会话阻塞,更新hang住不能继续。

这里出现了“锁等待”(“阻塞”)的现象,原因很简单,因为在session2中已经对这条数据执行过update操作没有提交表示已经对该行加了行级锁。

我们可以通过v$session视图看到,实例2的195阻塞了实例2的133会话,即本实验中的session2阻塞了session1。
6、接下来再执行一条SQL后死锁就会产生了:在session2中,更新表A的记录
SYS@raclhr2> update A set id = 10000 where id = 1;
这里还是长时间的等待,但是这里发生了死锁,这个时候我们去第一个会话session1中看一下,原先一直在等待的SQL语句报了如下的错误:
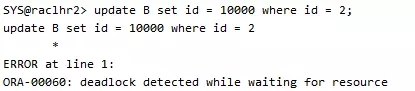
若此时查询v$session视图可以看到实例2的133阻塞了实例2的195会话,即本实验中的session1阻塞了session2,和刚刚的阻塞情况相反,说明oracle做了自动处理:
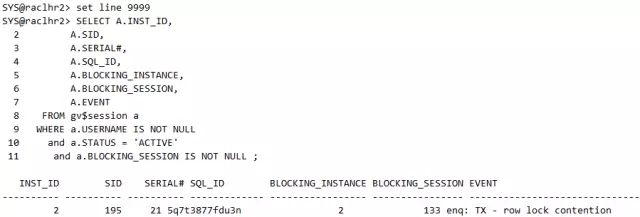
更进一步:查看一下alert警告日志文件发现有如下的记录:

若是单机环境,报警日志为:


可以看到该文件是由lmd进程生成的,为rac的特有进程,完成CacheFusion的作用,再进一步:看看系统自动生成的trace文件中记录了什么:

若是单机环境比较明显:
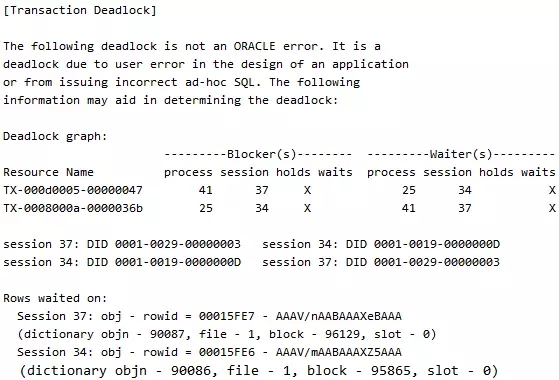
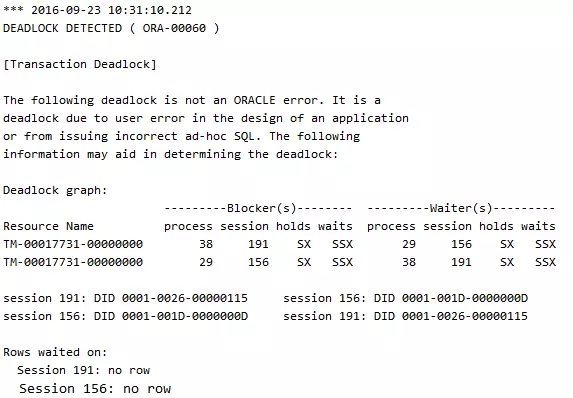
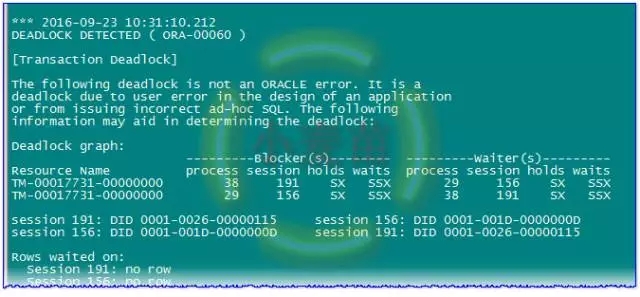
注意trace文件中的一行如下提示信息,说明一般情况下都是应用和人为的,和Oracle同学没有关系:
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL.
模拟二:同一张表删除和更新之间引起的死锁
造成死锁的原因就是多个线程或进程对同一个资源的争抢或相互依赖。这里列举一个对同一个资源的争抢造成死锁的实例。
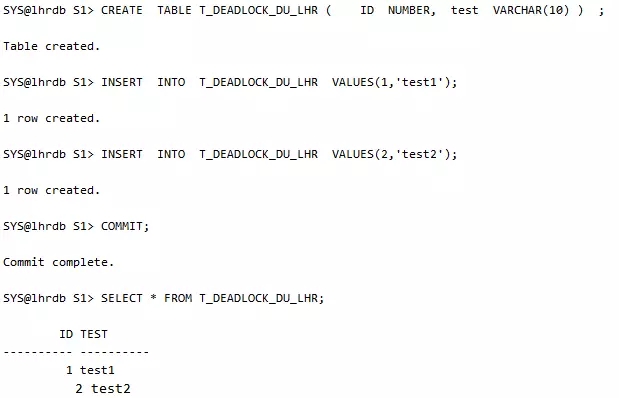
会话1更新第一条记录:

会话2删除第二条记录:

接下来会话1更新第二条记录,这是就产生了阻塞:
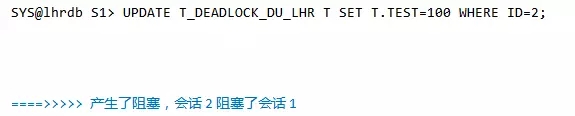

会话2删除第一条记录:

查看会话1:
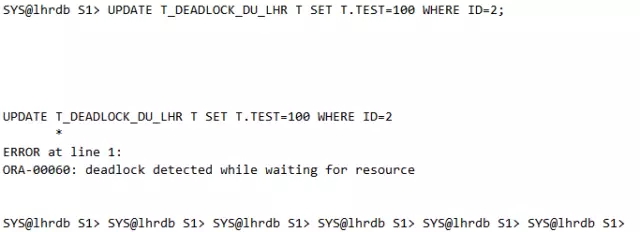
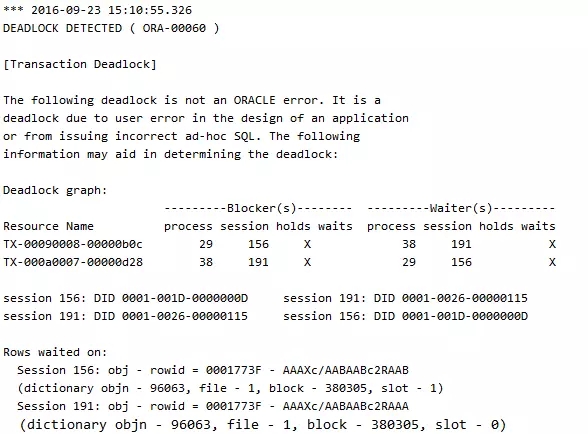
告警日志:

内容:

自治事务引发的死锁
一般来说构成死锁至少需要两个会话,而自治事务是一个会话可能引发死锁。
自治事务死锁情景:存储过程INSERT表A,然后INSERT表B;其中INSERT表A触发TRIGGER T,T也INSERT表B,T是自治事务(AT),AT试图获取对B的锁,结果B已经被主事务所HOLD,这里会报出来ORA-00060 – 等待资源时检查到死锁。
解决方法:去掉了T中的PRAGMA AUTONOMOUS_TRANSACTION声明,保持和存储过程事务一致。
模拟一:更新
在主事务中如果更新了部分记录,这时若自治事务更新同样的记录,就会造成死锁,下面通过一个简单的例子模拟了这个错误的产生:
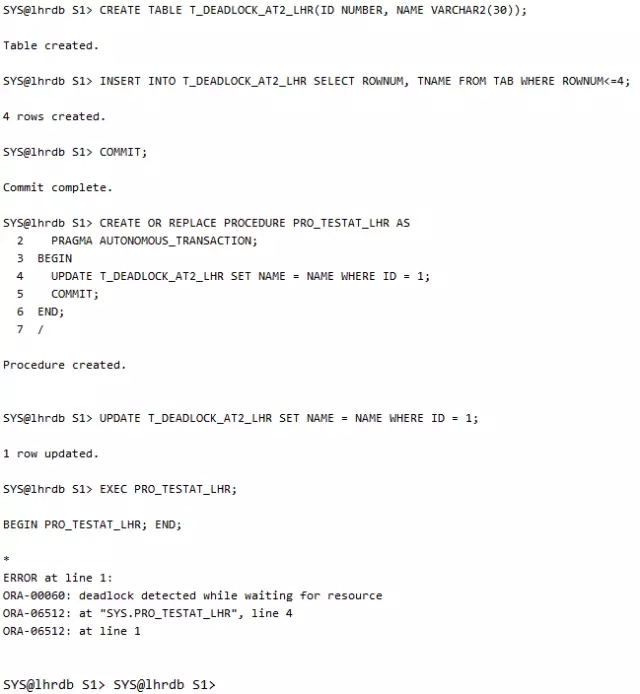
在使用自治事务的时候要避免当前事务锁定的记录和自治事务中锁定的记录相互冲突。
告警日志:

内容:
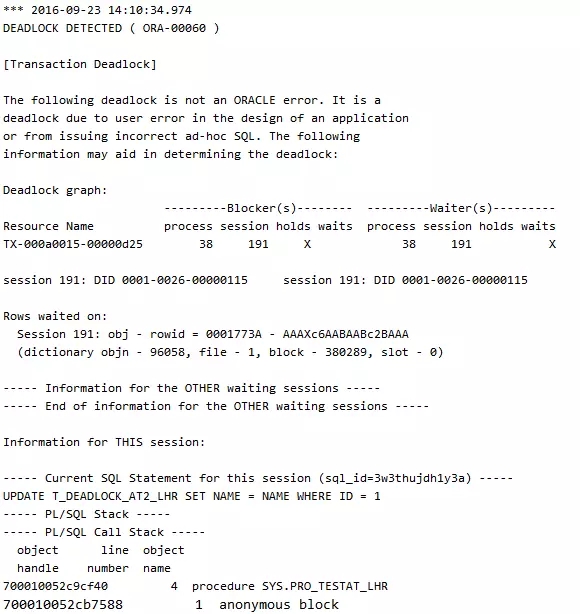
模拟二:插入
主事务和自治事务插入的是同一个主键值也会引起死锁。
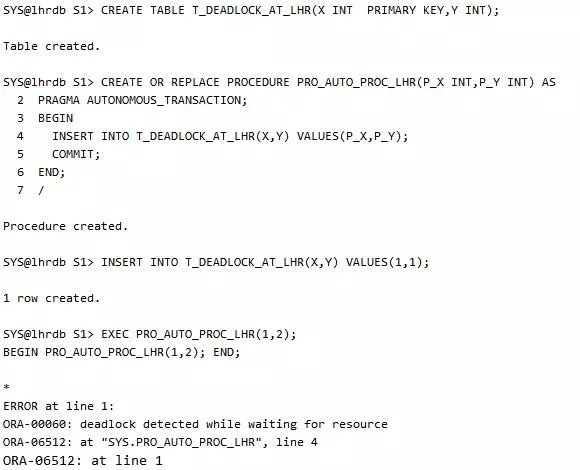
告警日志:

内容:
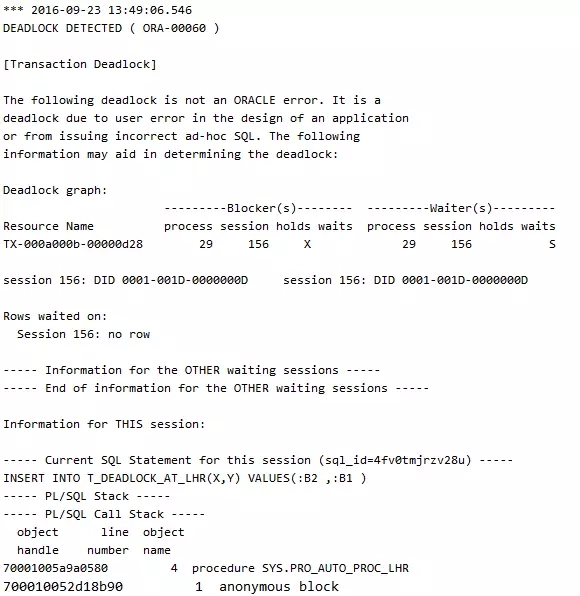
可以看到,等待的和持有锁的是同一个会话,根据trace信息记录的对象,发现问题是自治事务导致的。
2块级死锁
块级死锁其实指的就是ITL死锁。
ITL简介
ITL(Interested Transaction List)是Oracle数据块内部的一个组成部分,用来记录该块所有发生的事务,有的时候也叫ITL槽位。如果一个事务一直没有提交,那么,这个事务将一直占用一个ITL槽位,ITL里面记录了事务信息、回滚段的入口和事务类型等等。如果这个事务已经提交,那么,ITL槽位中还保存有这个事务提交时候的SCN号。ITL的个数受表的存储参数INITRANS控制,在一个块内部,默认分配了2个ITL的个数,如果这个块内还有空闲空间,那么Oracle是可以利用这些空闲空间再分配ITL。如果没有了空闲空间,那么,这个块因为不能分配新的ITL,所以,就可能发生ITL等待。如果在并发量特别大的系统中,那么最好分配足够的ITL个数,或者设置足够的PCTFREE,保证ITL能扩展,但是PCTFREE有可能是被行数据给消耗掉的,例如UPDATE,所以,也有可能导致块内部的空间不够而导致ITL等待,出现了ITL等待就可能导致ITL死锁。
ITL结构
如果DUMP一个块(命令:alter system dump datafile X block XXX;),那么在DUMP文件中就可以看到ITL信息:


1)Itl: ITL事务槽编号,ITL事务槽号的流水编号
2)Xid:代表对应的事务id(transac[X]tion identified),在回滚段事务表中有一条记录和这个事务对应。Xid由三列使用十六进制编码的数字列表示,分别是:Undo Segment Number +Transaction Table Slot Number+ Wrap,即由undo段号+undo槽号+undo槽号的覆盖次数三部分组成,即usn.slot.sqn,这里0x0008.002.000009e9转换为10进制为8.2.2537,从下边的查询出的结果是相对应的。

3)Uba:(Undo Block Address),该事务对应的回滚段地址,记录了最近一次的该记录的前镜像(修改前的值)。Uba组成:Undo块地址(undo文件号和数据块号)+回滚序列号+回滚记录号。多版本一致读是Oracle保证读操作不会被事务阻塞的重要特性。当Server Process需要查询一个正在被事务修改,但是尚未提交的数据时,就根据ITL上的uba定位到对应Undo前镜像数据位置。这里的Uba为:0x00c0108b.04ac.24,其中00c0108b(16进制)=0000 0000 1100 0000 0001 0000 1000 1011(2进制,共32位,前10位代表文件号,后22位代表数据块号)=文件号为3,块号为4235:(10进制);04ac(16进制)=1196(10进制);24(16进制)=36(10进制)。这个结果和v$transaction查询出来的结果一致。
SELECT UBAFIL 回滚段文件号,UBABLK 数据块号,UBASQN 回滚序列号,UBAREC 回滚记录号 FROM v$transaction ; --查看UBA
4)Flag:事务标志位,即当前事务槽的状态信息。这个标志位就记录了这个事务的操作状态,各个标志的含义分别是:
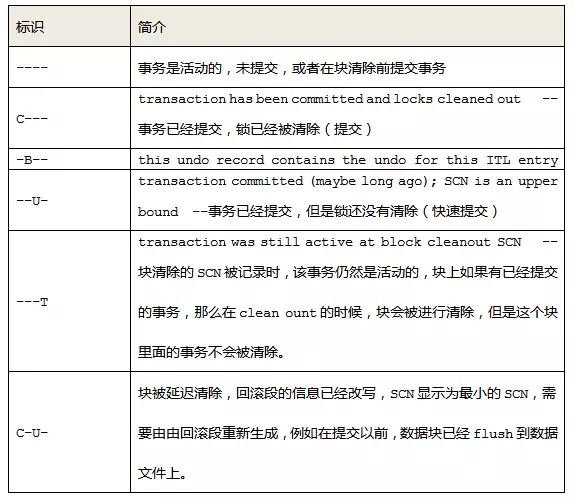
5)Lck:表示这个事务所影响的行数,锁住了几行数据,对应有几个行锁。我们看到01号事物槽Lck为3,因为该事物槽中的事物Flag为U,证明该事物已经提交,但是锁还没有清除。再比如对于下边这个ITL:

我们看到01号事物槽Lck为0,因为该事物槽中的事物Flag为C,证明该事物已经提交,锁也被清楚掉了,该事物槽可以被重用了。02号事物槽Lck为1,是因为我对第一行做了一个更新,并且没有提交,Flag为“----”说明该事物是活动的。
6)Scn/Fsc:Commit SCN或者快速提交(Fast Commit Fsc)的SCN。 Scn=SCN of commited TX; Fsc=Free space credit(bytes)每条记录中的行级锁对应Itl条目lb,对应于Itl列表中的序号,即那个事务在该记录上产生的锁。一个事物只有在提交之后才会在ITL事物槽中记录SCN。
ITL个数
ITL的个数,受参数INITRANS控制,最大ITL个数受MAXTRANS控制(11g已废弃MAXTRANS),在一个块内部,默认分配了2个ITL的个数。ITL是block级的概念,一个ITL占用块46B的空间,参数INITRANS意味着块中除去block header外一部分存储空间无法被记录使用(46B*INITRANS),当块中还有一定的FREE SPACE时,ORACLE可以使用FREE SPACE构建ITL供事务使用,如果这个块内还有空闲空间,那么Oracle是可以利用这些空闲空间并再分配ITL。如果没有了空闲空间(free space),那么,这个块因为不能分配新的ITL,所以就可能发生ITL等待,即enq: TX - allocate ITL entry等待事件。注意:10g以后MAXTRANS参数被废弃,默认最大支持255个并发。
如果在并发量特别大的系统中,最好分配足够的ITL个数,其实它并浪费不了太多的空间,或者,设置足够的PCTFREE,保证ITL能扩展,但是PCTFREE有可能是被行数据给消耗掉的,如UPDATE,所以,也有可能导致块内部的空间不够而导致ITL等待。
对于表(数据块)来说,INITRANS这个参数的默认值是1。对于索引(索引块)来说,这个参数默认值是2。
ITL等待表现出的等待事件为“TX - allocate ITL entry”,根据MOS(Troubleshooting waits for 'enq: TX - allocate ITL entry' (Doc ID 1472175.1)提供的解决办法,需要修改一些参数,SQL如下,这里假设用户名为TLHR,表名为TLHRBOKBAL,表上的索引名为PK_TLHRBOKBAL:

无MOS权限的朋友可以去http://blog.itpub.net/26736162/viewspace-2124531/阅读。
ITL引起的死锁案例处理
由ITL不足引发的块级死锁的一个处理案例可以参考我的BLOG:http://blog.itpub.net/26736162/viewspace-2124771/、http://blog.itpub.net/26736162/viewspace-2124735/。
ITL死锁的模拟
我们首先创建一张表T_ITL_LHR,这里指定PCTFREE为0,INITRANS为1,就是为了观察到ITL的真实等待情况,然后我们给这些块内插入数据,把块填满,让它不能有空间分配。
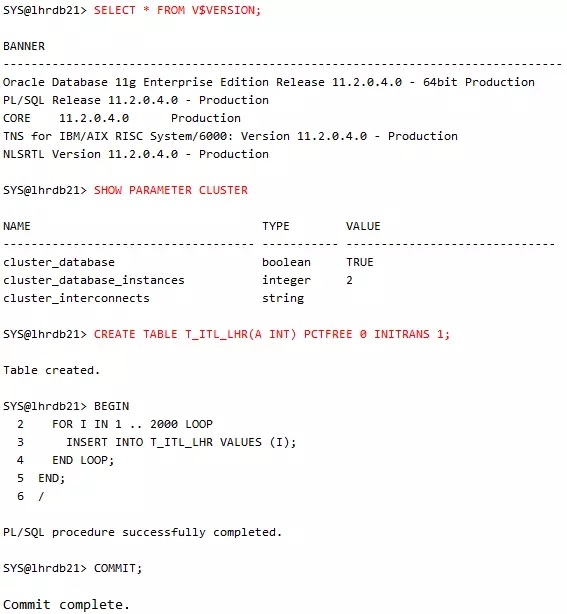
我们检查数据填充的情况:
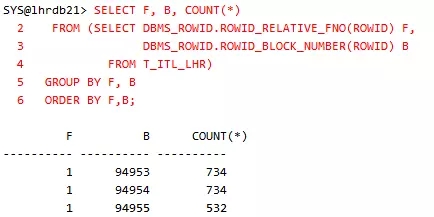
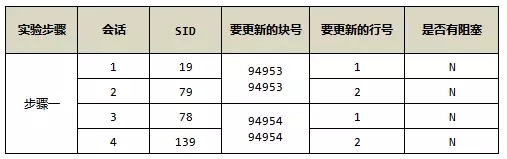
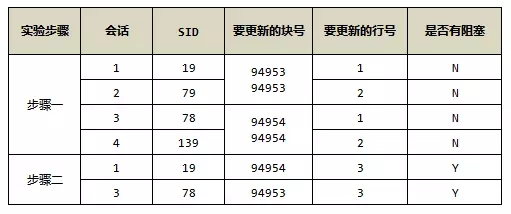
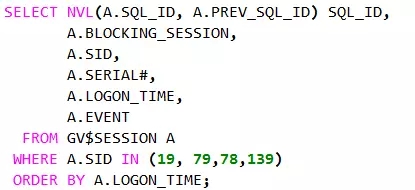
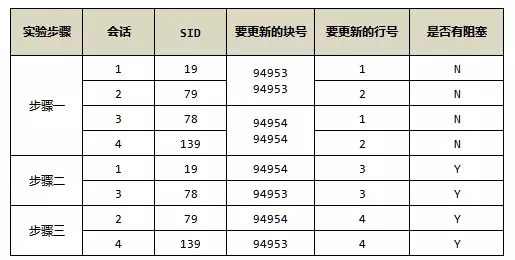
可以发现,这2000条数据分布在3个块内部,其中有2个块(94953和94954)填满了,一个块(94955)是半满的。因为有2个ITL槽位,我们需要拿2个满的数据块,4个进程来模拟ITL死锁:
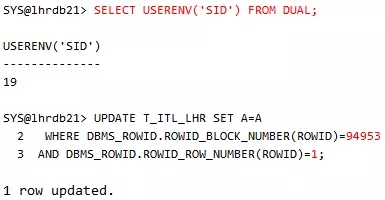
会话1:
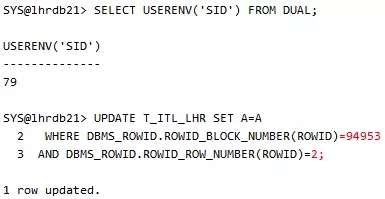
会话2:
会话3:
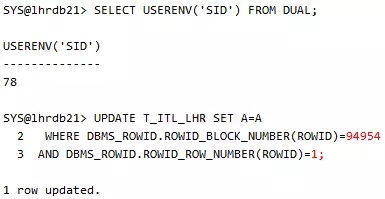
会话4:
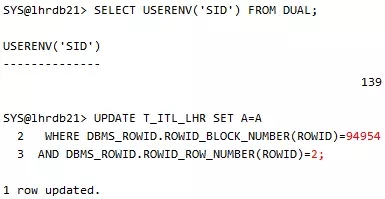
这个时候系统不存在阻塞,

以上4个进程把2个不同块的4个ITL槽位给消耗光了,现在的情况,就是让他们互相锁住,达成死锁条件,回到会话1,更新块94954,注意,以上4个操作,包括以下的操作,更新的根本不是同一行数据,主要是为了防止出现的是行锁等待。
会话1:

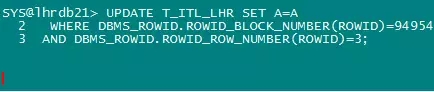
会话1出现了等待。
会话3:


会话3发现出现了等待。
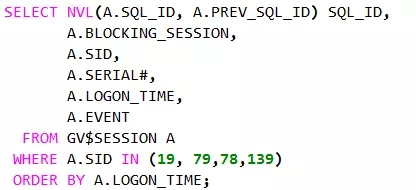
我们查询阻塞的具体情况:

可以看到,会话1被会话4阻塞了,会话3被会话2阻塞了。
注意,如果是9i,在这里就报死锁了,但是在10g里面,这个时候,死锁是不会发生的,因为这里的会话1还可以等待会话4释放资源,会话3还可以等待会话2释放资源,只要会话2与会话4释放了资源,整个环境又活了,那么我们需要把这两个进程也塞住。
出现的是行锁等待。
会话2,注意,我们也不是更新的同一行数据:


会话2出现了等待,具体阻塞情况:

我做了几次实验,会话2执行完SQL后,会话3到这里就报出了死锁,但有的时候并没有产生死锁,应该跟系统的阻塞顺序有关,若没有产生死锁,我们可以继续会话4的操作。
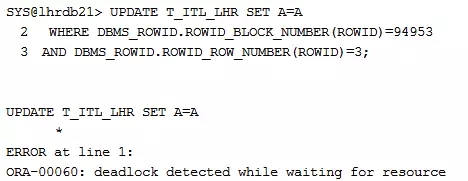
会话4,注意,我们也不是更新的同一行数据:


会话4发现出现了等待。

虽然,以上的每个更新语句,更新的都不是同一个数据行,但是,的确,所有的进程都被阻塞住了,那么,死锁的条件也达到了,等待一会(这个时间有个隐含参数来控制的:_lm_dd_interval),我们可以看到,会话2出现提示,死锁:
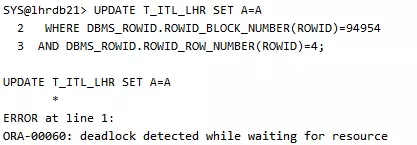
报出死锁之后的阻塞情况:

我们可以在会话2上继续执行步骤三中的SQL,依然会产生死锁。生成死锁后,在告警日志中有下边的语句:

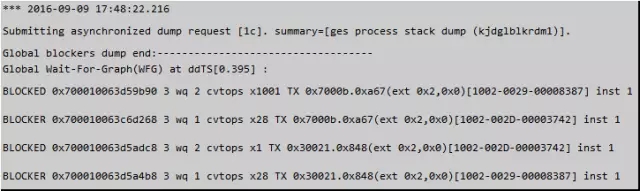
其中的内容有非常经典的一段Global Wait-For-Graph(WFG):
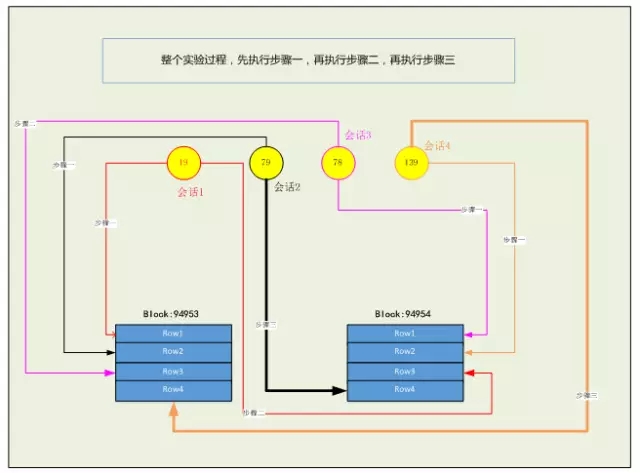
该实验过程可能有点复杂,我画个图来说明整个实验过程:









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒