
作者介绍
蒋健,云趣网络科技联合创始人,11g OCM,多年Oracle设计、管理及实施经验,精通数据库优化,Oracle CBO及并行原理,曾为多个行业的客户的 Oracle 系统实施小型机到 X86跨平台迁移和数据库优化服务。云趣鹰眼监控核心设计和开发者,资深Python Web开发者。(文章审校:杨建荣)
关于本文
随着每个版本的演进,Oracle默认统计信息搜集策略更加智能和成熟。从11g 开始, Oracle 建议使用DBMS_STATS.AUTO_SAMPLE_SIZE,不需要手工使用estimate_percent设置每个表的采样比例。
有些新的特性比如分区表的增量统计信息,12c 的 hybrid 柱状图都依赖于DBMS_STATS.AUTO_SAMPLE_SIZE。绝大部分的情况,默认DBMS_STATS.AUTO_SAMPLE_SIZE性能和统计信息非常理想,但是在数据极端倾斜时,DBMS_STATS.AUTO_SAMPLE_SIZE的采样比例过低,可能导致柱状图信息中缺乏非热门数据的统计。当查询非热门数据时,优化器的估算可能不准确,从而选择次优的执行计划。本文就是这样一个例子。
案例背景
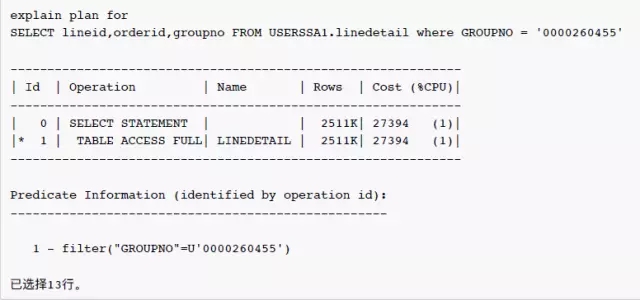
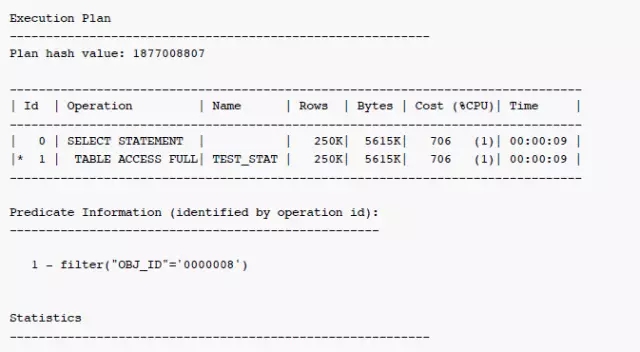
客户反映在表USERSSA1.linedetail的列GROUPNO上建了索引,但是优化器还是选择了全表扫描,以下为执行计划,数据库的版本为:11.2.0.2.0
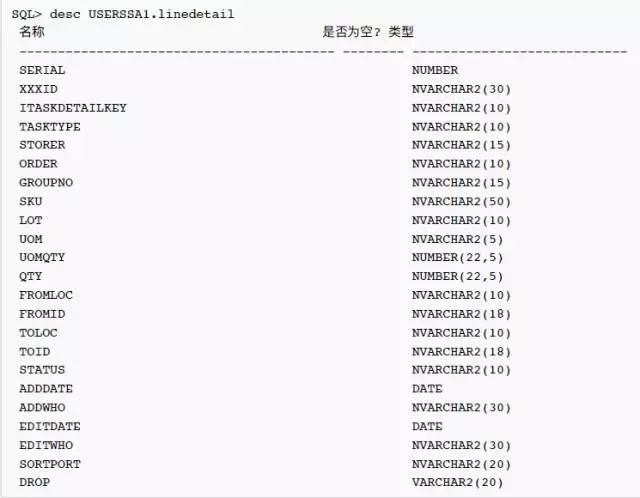
表结构如下:
统计信息分析
可以看到,优化器对于条件GROUPNO = '0000260455'估算行数为2511K 行记录。全表扫描是成本更低的访问路径,看起来是一个合理的选择。但是过滤条件GROUPNO = '0000260455'的估算值是否正确?我们看看这个表的统计信息:
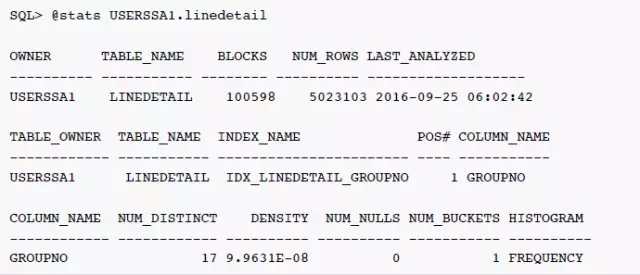
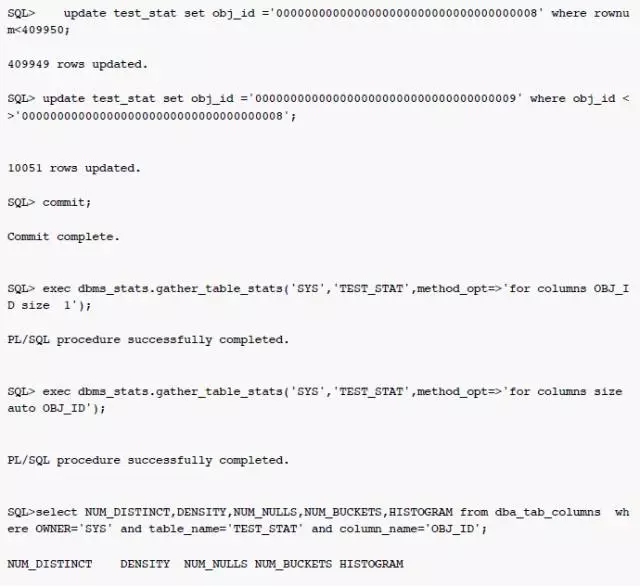
表LINEDETAIL的统计信息是今天早上6点钟搜集的,列 groupno 上确实有索引。groupno 列上的统计信息很奇怪,唯一值数量为17,柱状图类型为 Frequency,但是NUM_BUCKETS为1。如果唯一值数量为17,那么 Frequency 柱状图的柱状图数量为什么只1,而不是17?而且'0000260455'这个值是否为热门的数据呢?继续看看这个列上实际的数据分布:
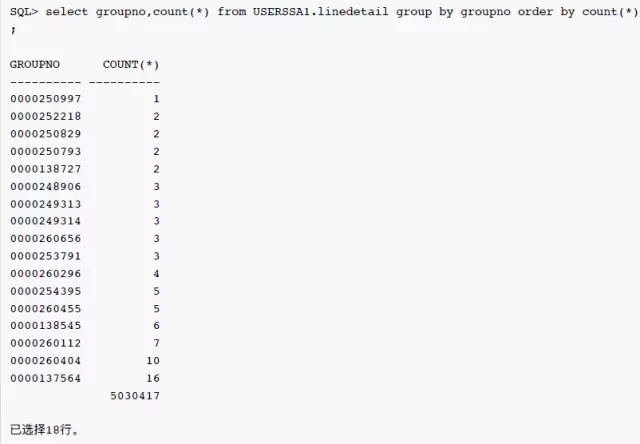
可以看到绝大部分的值为空值,'0000260455'实际只有5行数据,为什么优化器的估计是2511K,相差50万倍呢?继续查看10053事件跟踪中的信息:
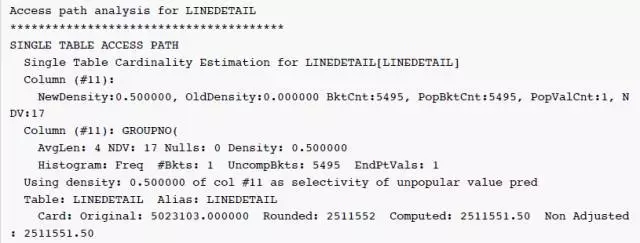
因为 NewDensity=0.5,只有一个 bucket 记录热门值(null)的数量,所以对于优化器,'0000260455'为非热门值(unpopular value),优化器使用 NewDensity 作为非热门值(unpopular value)的选择性因子。估算值 = num_rows * NewDensity = 5023103.000000 * 0.5 = 2511551.50
NewDensity 和 OldDensity
10053跟踪中有两个密度系数,NewDensity 和 OldDensity。OldDensity的计算公式如下:

对于Frenquency 柱状图的非热门值算值 = numrows * OldDensity = numrows * (0.5 / num_rows) = 0.5。对于没有记录在 Frequency 柱状图中的非热门值,估算值会固定为0.5, 执行计划中会显示为1。
NewDensity 是 10.2.0.4 之后优化器通过Bug 5483301 - QUERY WITH PREDICATE VALUE NON-EXISTENT IN FREQUENCY HISTOGRAM RUNS SLOW引入的新算法,对于没有记录在 Frequency 柱状图中的非热门值,估算值为最不热门值的估算值的一半,而不是固定为0.5。使用 NewDensity 算法,即使统计信息没有及时更新,非热门值的估算值也不会被简单粗暴的设置为1,这是优化器的一种折中,NewDensity的计算公式如下:
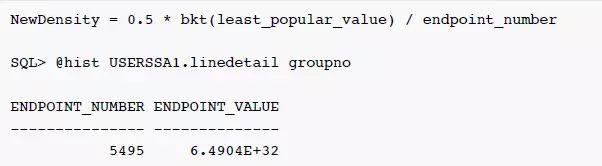
因为只有一个 bucket,least_popular_value = PopBktCnt = 5495,ENDPOINT_NUMBER为5495,NewDensity 而计算步骤为 **NewDensity = 0.5 * bkt(least_popular_value) / endpoint_number = 0.5 * 5495 / 5495 = 0.5**。导致对于所有非热门值,估算值为总行数的一半,完全违背了NewDensity算法的设计初衷。
关于 NewDensity 更为详细的讨论,比如针对 height-balance 柱状图的计算公式,可以参见 Alberto Dell’Era 的系列文章。(http://www.adellera.it/blog/2009/10/23/cbo-newdensity-for-frequency-histograms11g-10204-densities-part-iv/)
DBMS_STATS.AUTO_SAMPLE_SIZE 的缺陷
优化器默认的采样比例为DBMS_STATS.AUTO_SAMPLE_SIZE,但是针对重复值非常高的列,采样的比例非常底,比如 groupno 这个列,采样的比例只有0.1%。虽然优化器使用了APPROXIMATE_NDV算法(这个算法在12c 中通过函数APPROX_COUNT_DISTINCT提供给用户使用),可以准确地估算 groupno 列唯一值的数量为18,但是柱状图的 bucket 数量只为1,并不准确。

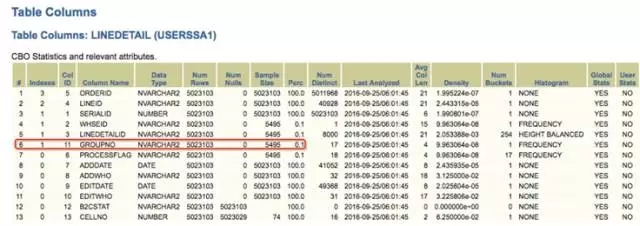
使用DBMS_STATS.AUTO_SAMPLE_SIZE,即使强制指定柱状图的 bucket 数据量为254,重新搜集统计信息之后buckets 的数量还是1,执行计划依然为全表扫描。

bucket的数目为什么会不准
原因主要有两种:
数据存在极度的倾斜,采样时非热门数据可能会被遗漏(参考测试1)
数据的前缀相同且长度超过32字节(假定编码为定长单字节编码),这样的数据会被误认为同一样本(参考测试2)
数据初始化:

测试1:数据存在极度倾斜
(数据存在极度倾斜,收集直方图信息时没有被采样到,最后的执行计划CBO估算行数远大于真实行数。注:前6位相同时显著提高采样时被忽略的概率 采用如00000开头,可能无法重现)



测试2:相同数据前缀超长(大于32位)
这种场景下,直方图信息endpoint_actual_value显示样本标签不准确,执行计划估算数据也完全错误,与之前估算约一半的数据相比,这种情况会被认为是完全命中。只能通过手动hint写死执行路径解决。
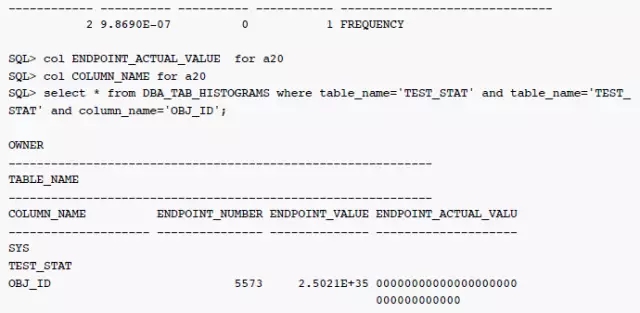
ENDPOINT_ACTUAL_VALUE这里信息明显已经不准确(00000000000000000000000000000000只去了前32位)
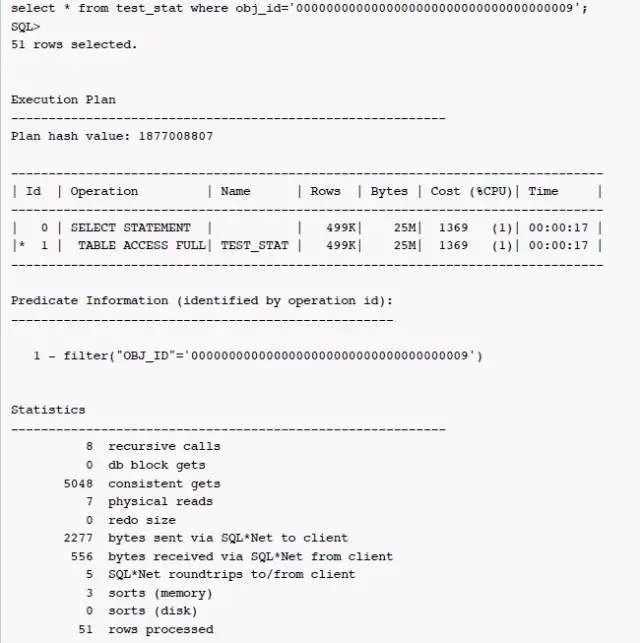
从执行计划的估算值可发现CBO其实完全估错,也验证了相同前缀超长时CBO估算会存在问题。
解决方案1:手动指定estimate_percent
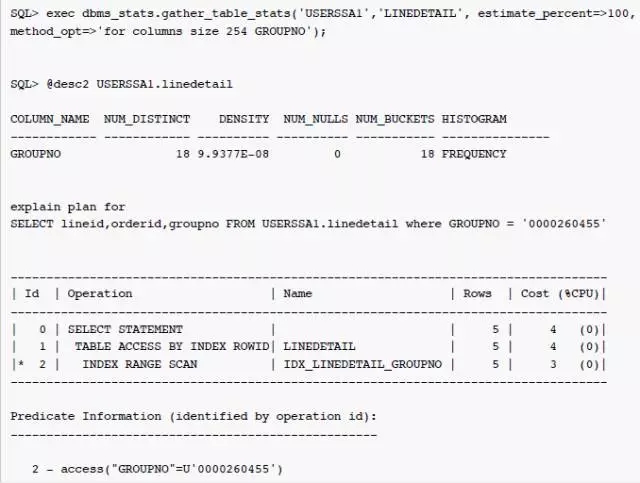
通过强制指定estimate_percent为100%,重新搜集统计信息之后, buckets 的数据量为18,重新解析之后,SQL 的执行计划发生改变,对于条件GROUPNO = '0000260455'的估算值为5,通过索引IDX_LINEDETAIL_GROUPNO访问数据。本案例中数据量仅百万级,采样使用了100%,数据量特别大的情况比例考虑降低些。
为了避免之后对表 LINEDETAIL 统计信息的搜集,继续使用DBMS_STATS.AUTO_SAMPLE_SIZE,可以使用DBMS_STATS.SET_TABLE_PREFS对表 LINEDETAIL 定制 estimate_percent的偏好,如下:

解决方案2:使用 OldDensity 算法
可以通过_fix_control关闭 NewDensity,使用 OldDensity 算法。使用 alter system 可以在系统全局关闭改算法。
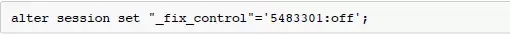
预防
文中描述的极度倾斜的情况虽然并不多见,但在生产中也可能遇见。通过查询dba_tab_histograms中NUM_BUCKETS为1的项目,可以找出这种潜在的危险(NUM_BUCKETS为2等也有可能,相对可能性比较小)。
总结
虽然 Oracle 优化器的算法和默认统计信息的收集策略越来越智能,现实世界还是有一些极端情况,比如数据极端倾斜时,需要 DBA 进行手工处理,以保证统计信息的合理准确。幸运的是,DBMS_STATS 提供了丰富的功能,使 DBA 可以在默认统计信息搜集策略的基础上,进行灵活的定制。







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721