
分布式查询语句对于远程对象的查询在远程库执行,在远程库可以执行的SQL语句会通过优化器的查询转换,执行的是转换后的语句,然后结果集返回到本地,再与本地表运算。当然,本地操作还是远程操作是相对的,我们可以通过driving_site hint改变主查询计划的执行位置,但是对DML,driving_site是失效的,另外对远程表也可以使用其他hint来控制执行计划。
分布式查询语句中可能有不同远程库的表,优化分布式查询要达到3点目标:
1. 访问同一个远程库的次数要尽量少,也就是同一远程库的对象应该尽量转为一条SQL运算,一次运算,运算后将结果返回给本地库。
2.从远程库上返回到本地库的结果集要尽量小,只访问远程对象需要的字段,从而减少网络传输。
3.远程库上执行的语句的执行计划、远程库返回的结果与本地联合查询的计划应该比较高效。
如果能够达到以上3点,一般情况下,分布式查询的效率较高。
优化分布式查询需要从以上3个方面着手。下面的local_tab 7万多条,remote_big_tab百万条,remote_small_tab 7万多条。
1、使用Collocated内联视图
也就是说,SQL要引用不同远程库的表,需要组织好语句结构。将相同库的表放一起组成内联视图,这样ORACLE就很容易知道这个内联视图里的表是在同一远程库作完查询,然后再返回给本地库。这样减少了本地库与远程库的交互次数、传输结果集的数量和次数,从而提高效率。比如查询:

可以看出,在远程库remote上执行的语句是两个远程表关联后,并经过查询转换(全转为大写,自己取了别名A1,A2,ORACLE内部自己构造查询语句SELECT DISTINCT…,之后远程查询结果返回给本地,可以去远程库里查询实际的计划,走的是HASH JOIN。通过以上案例看出,对于一些复杂的查询,对象来源于不同远程库,能够通过SQL改写将相同远程库的表先做JOIN,可以提高效率。
2、了解CBO优化器对分布式查询的处理
CBO对分布式查询的处理,也是尽量转为Collocated内联视图,CBO会做如下动作:
1) 所有可mergeable的视图会merge。
2) CBO会测试Collocated内联视图的query BLOCK。
3) 如果可以将相同库的表组合成SQL一起查询,那么就会一起执行。
当然,CBO对分布式查询的处理,可能是不高效的,这时候得用其他的方法,比如使用HINT,改造SQL,改造分布式查询的方法(远程库用视图)等。特别当分布式查询包含下列情况,CBO可能是不高效的:
1)有分组运算
2)有子查询
3)SQL很复杂
比如下面语句含有子查询:

通过计划可以看到REMOTE有两个,两张远程表无法做Collocated inline VIEW运算。
再比如下面的语句,有分组运算:
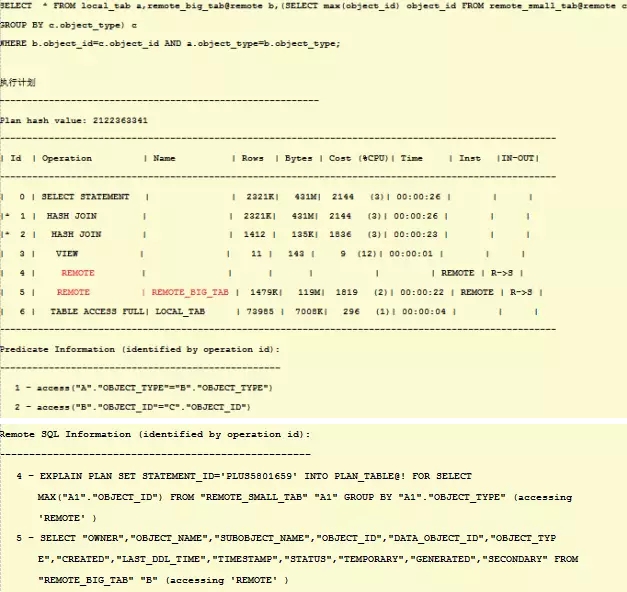
通过计划看出,将远程表进行分组运算后,传输给本地库,然后大表传输给本地库,之后做HASH JOIN,这是不高效的。运行时间:已用时间: 00: 02: 12.22
可以改造分布式查询,手动组织Collocated inline VIEW,在远程库建立view:
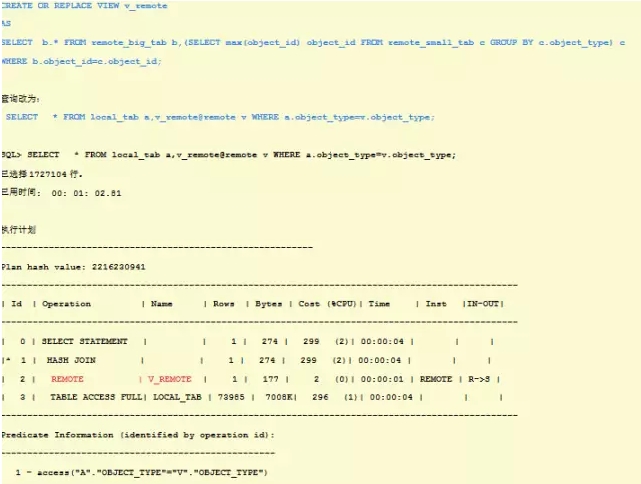
通过计划可以看出,现在是远程表做整体操作之后才返回到本地了。
3、使用HINT,特别是driving_site HINT
对远程表可以使用hint,比如parallel,use_nl,use_hash,FULL等。
driving_site hint能够指定执行计划在远程还是本地做,比如下面使用driving_site(b),那么SQL就是放到远程去执行,也就是原来的远程表就相当于本地表,本地表要传输给remote库,主计划在remote库上执行

当然,如果是driving_site(a)那么就是本地驱动的,默认的是本地驱动的。
使用driving_site,特别是本地小结果集,远程大结果集的时候,总体结果集较小,希望计划在远程驱动,这样远程执行完毕,将结果集传输到本地,这样避免大结果集的传输。
例1:
小表9998条,大表3169376条记录,远程大表sub_id,acc_id上联合索引
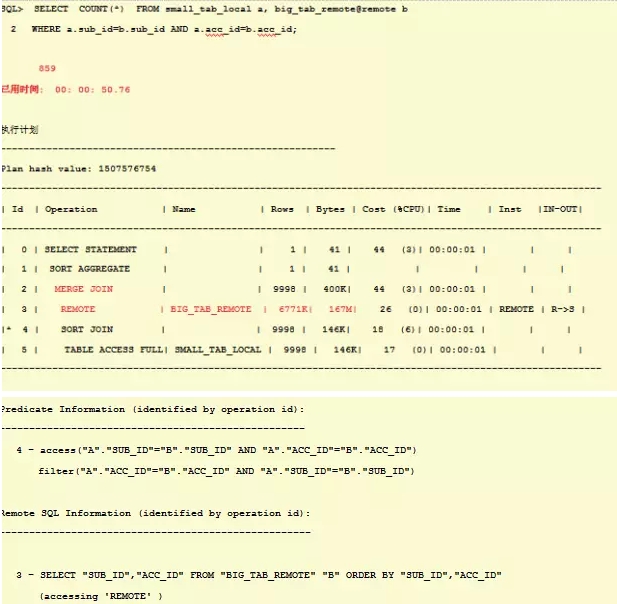
查询876条数据,耗时50s,显然将大结果集拉到本地做运算是不好的,因为本地表很小,远程大表有索引,如果能在远端执行,并走nl,那么显然效率非常好。使用driving_site hint改造查询如下:

现在主计划是在远端remote上执行的,本地表small_tab_local变成了远程表,ORACLE会将small_tab_local结果集送到远端,只查询了sub_id,acc_id,然后作为驱动表,与远端表做NESTED LOOPS运算,计划里可以看到远端表走索引了,最后将远端执行结果返回给本地。
driving_site hint注意点
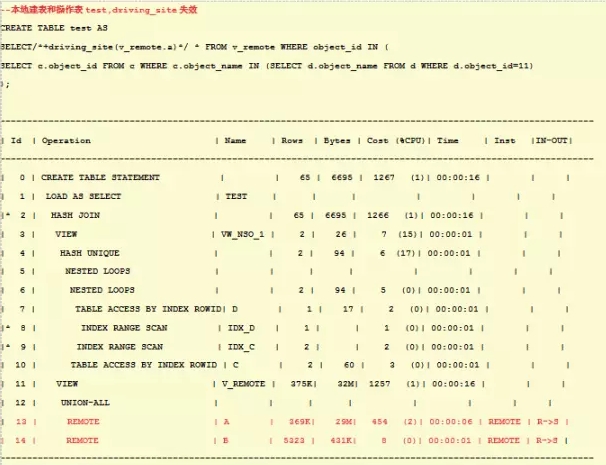
driving_site对dml无效,dml以目标表所在库驱动SQL计划。比如下面的driving_site失效,后面的hint还是有效的。
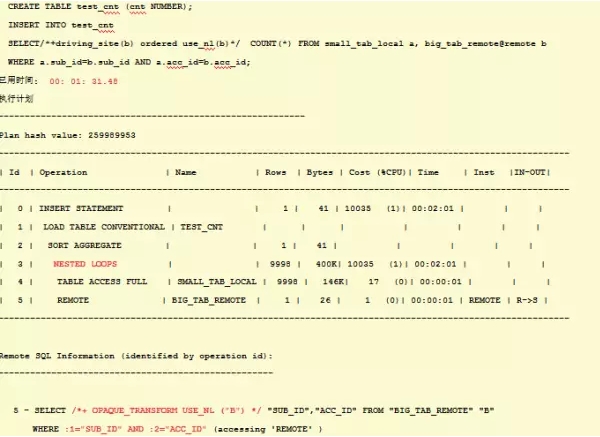
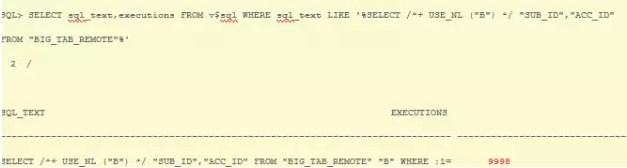
语句执行1分31s,driving_site hint失效,但是后面的NL没有失效,可以从计划中看出类似绑定变量的参数,这实际上是对于每个small_tab_local的结果集的行,将sub_id,acc_id传给远端表big_tab_remote,也就是变量:1,:2,这样本地的表筛选出多少行,远程语句SELECT /*+ OPAQUE_TRANSFORM USE_NL ("B") */ "SUB_ID","ACC_ID" FROM "BIG_TAB_REMOTE" "B" WHERE :1="SUB_ID" AND :2="ACC_ID" 就执行多少次。
这里本地表9998条,无过滤条件,因此远程表语句运行了9998次,虽然远程查询也是走索引的,但是SQL被执行了9998次,是非常影响性能的。可以去远程库查询下:
这里driving_site失效,但是后面的nl还有效,远程表执行的次数是small_tab_local表的数量(因为这里没有谓词过滤small_tab_local),可以使用其他hint,比如。
INSERT INTO test_cnt
SELECT/*+ordered use_hash(b)*/ COUNT(*) FROM small_tab_local a, big_tab_remote@remote b
WHERE a.sub_id=b.sub_id AND a.acc_id=b.acc_id;
当然效率不一定很好,因为这里由远程驱动效率最好,为了不想driving_site失效,可以使用PL/SQL(这里是只查询数量,如果查询结果集可以使用PL/SQL批处理插入)。

例2:
查询语句:
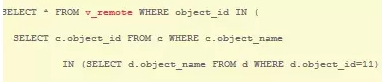
比较慢,返回32行,需要10来秒。其中v_remote是个视图,此视图连接到远程表,其中远程的两张表的object_id都有索引:

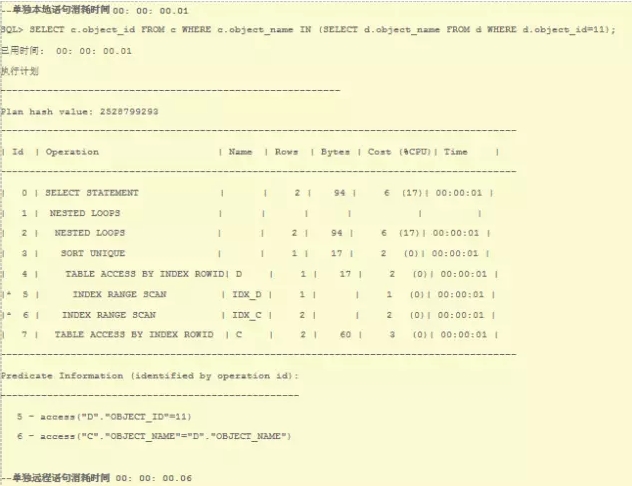
c和d是本地表,d.object_id以及c.object_name有索引。单独查询很快,<1s就会返回:

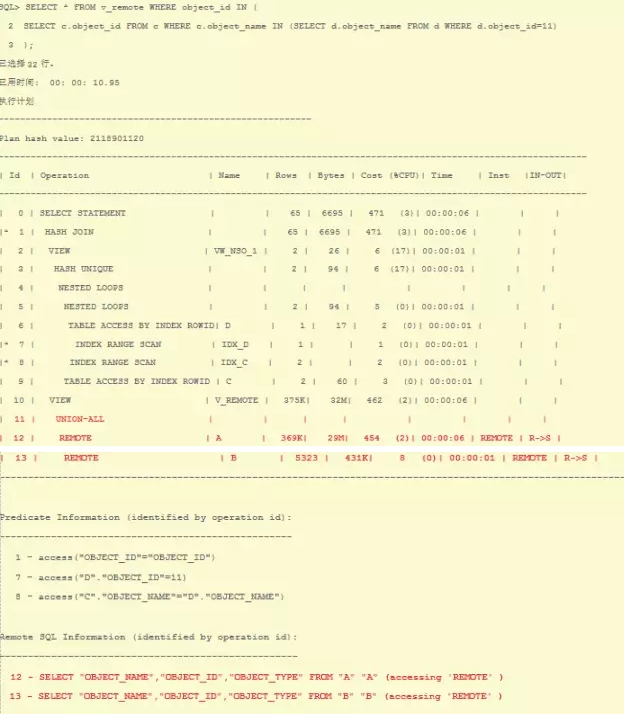
单独查询很快,为什么联合查询就慢了呢?原因在于:

因此,优化此混合查询的语句有多种办法:可以使用PL/SQL拆分本地与远程查询,或者可以使用driving_site hint,将主计划推到远程库去执行,本地的结果集少,推到远程,远程视图走索引,效率高。如下:
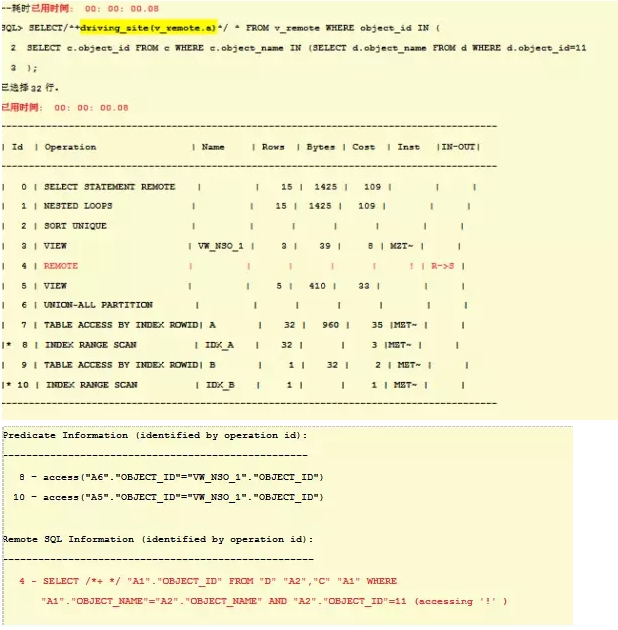
现在效率很高,从计划中可以看出,现在计划在远程库上执行,本地的查询查询一行object_id=11传输给远程,并驱动视图查询,视图走索引,然后再将结果返回给本地。另外注意hint 视图的用法是hint(视图名.表名)。
再次说说driving_site失效的情况:
DML,DDL让driving_site失效,driving_site hint会自动被oracle忽略掉,因为此时以目标表所在的库为主计划驱动,相当于driving_site(目标表库)
1)DML,DDL如果是对本地表操作,主计划是在本地做的,远程数据拉到本地,driving_site(remote)失效。
2)DML如果是对远程表DML,主计划是在远程做的,本地数据送到远程,相当于自动driving_site(remote)


含有dblink的SQL语句,特别是DML SQL,优化是很复杂的,特别是远程表与本地表结果集都很大,或含有多个不同的远程对象,这时更加复杂。很多含有dblink的SQL语句可以通过Collocated inline view,定义视图,driving_site hint,PL/SQL程序等进行优化。当然,在业务允许的情况下也可以通过MV等技术,减少dblink使用,可以在一定程度上优化含有DBLINK的分布式操作语句。
作者介绍:丁俊
【DBA+社群】联合发起人,新炬网络专家团成员。
性能优化专家,Oracle ACEA,ITPUB开发版资深版主、ITPUB 2010-2013连续4届最佳精华获得者、2011-2014连续4届最佳版主。
十年电信行业从业经验,从事过系统开发与维护、业务架构和数据分析、系统优化等工作。
电子工业出版社终身荣誉作者,《剑破冰山-Oracle开发艺术》副主编。
往期作品:
【重磅干货】看了此文,Oracle SQL优化文章不必再看!
全球敏捷运维峰会【杭州站】

2016 年4月16日,与你相约杭州,来一场敏捷与运维的美丽邂逅!DBA+社群联合三墩IT人开启全球敏捷运维峰会第一站:杭州站!峰会力邀来自互联网与传统企 业的资深专家,各路大咖齐聚,汇聚500+行业精英,聚焦架构、敏捷、运维三大主线,开启一场专属于IT人的年度之约!
专家阵容:或行业资深派、或著书力作派、或传统转型派、或一线实战派,总有一款是你喜欢!
绝对干货:聚焦架构、敏捷、运维三大主线,共讨传统企业在技术转型过程中的实践与困境、互联网企业在前沿技术方面的应用与心得、技术服务型企业在新老技术之间如何切换与落地,拒绝无营养的广告,绝对干货,精彩不容错过!
连接联动:汇聚社群数百顶级专家人脉,携数万社群成员声势,联合数十家媒体单位,共同打造一场连接敏捷与运维圈子的年度之约!
门票:免费!(限时限额)
VIP票:199元(限3月18日前)







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721