
作者介绍
蒋健,云趣网络科技联合创始人,11g OCM,多年Oracle设计、管理及实施经验,精通数据库优化,Oracle CBO及并行原理,曾为多个行业的客户的 Oracle 系统实施小型机到 X86跨平台迁移和数据库优化服务。云趣鹰眼监控核心设计和开发者,资深Python Web开发者。
故障现场
某客户核心 CRM 数据库(版本11.2.0.2,两个节点的 RAC),某个节点CPU利用率75%左右,过去几个月, 最严重时可达100%。客户DBA 通过ASH、AWR多次分析过后,依然没定位到问题根源,只能频繁重启。通过出现故障时段的顶级活动,可看到故障出现时,数据库出现严重 CPU 活动会话和共享池cursor: mutex S 等待,而且平均43个活动会话的SQL_ID是空的。这是一个奇怪的现象,如果 SQL 执行时间长的话,活动会话应该是有 SQL_ID 的。
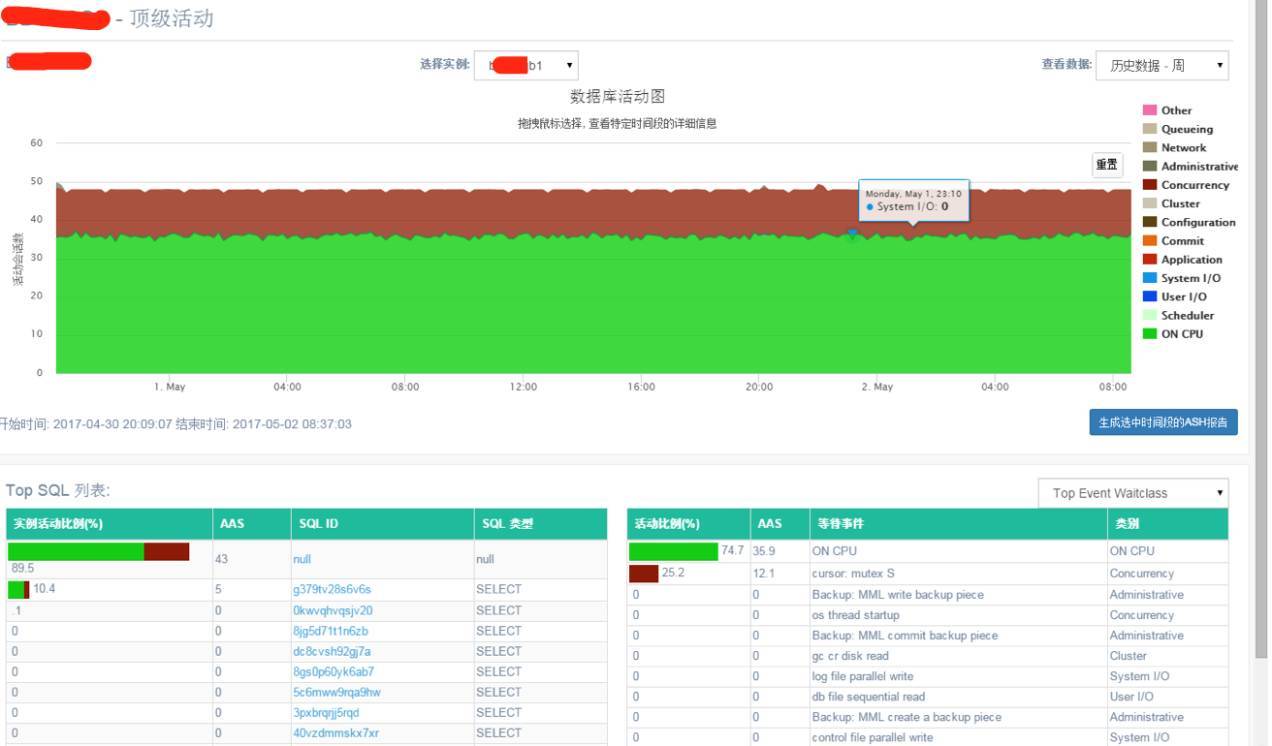
故障时间段AWR分析
数据库AAS 48,CPU 超线程后 64。CPU 资源已经过载,DBA 因为数据库主机 hang 住,通过重启数据库主机方式临时解决问题。

通过Top 5等待事件,除了DB CPU,共享池相关的等待cursor:mutex S占比25%。
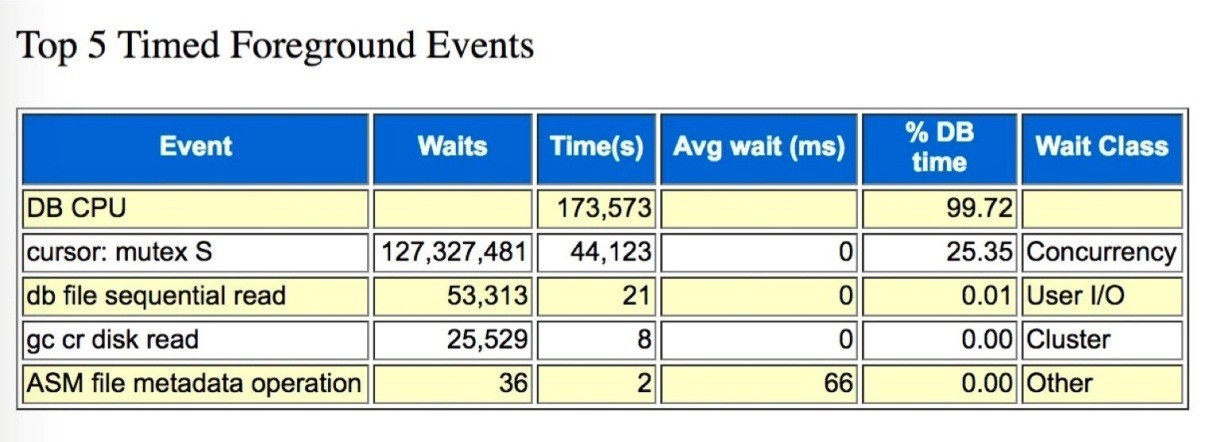
继续往下,时间模型的统计信息时,诡异的地方就出现了。解析时间占比99.81%,然而hard parse elapsed time 与failed parse elapsed time 时间占比几乎为零。

V$SESS_TIME_MODEL视图的官方网文档中,解析时间包含硬解析和软解析时间。到底发生了什么,占用整个数据库98%时间的解析难道是软解析? 但是应用并不复杂,从 AWR 的 SQL 列表中可以确定应用使用了绑定变量。这显然也不对,那数据库解析的时间到底是用在哪里了呢?

继续查看解析相关的实例统计信息,搜索parse count关键字,硬解析parse count (hard)一小时只有52次,奇怪的是存在25次的失败解析。是什么原因触发了错误的解析?是DBA连上数据库操作的执行SQL有错误?还是应用代码发送错误的SQL到数据库?

Bug 定位
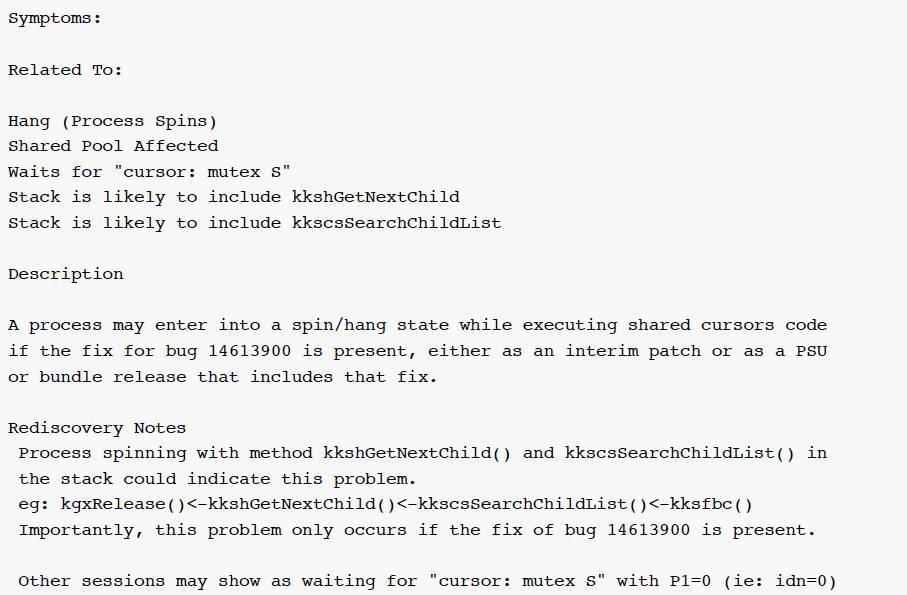
因为存在持续的稳定40多个进程一直 ON CPU,伴随着 mutex 等待,下一步我们重点查看 AWR中 mutex 的信息。Mutex Sleep 的 localtion 都集中为kkshGetNextChild[KKSHBKLOC1],根据我们的经验猜测可能由于mutex自旋引起。使用关键字kkshGetNextChild 去 MOS 搜索一番,定位到Bug 16175381 - Process spin in kkscsSearchChildList() -> kkshGetNextChild() with fix for bug 14613900 present (文档 ID 16175381.8). 是什么原因触发了进程在解析阶段进入进程自旋?会不会是失败的解析导致进程进入自旋?

正常时间段AWR分析
对比查看正常时间段的 AWR 报告,Top 5等待事件的最后 SQL*Net break/reset to client,意味着应用客户端和数据库的正常交互过程中出现错误。
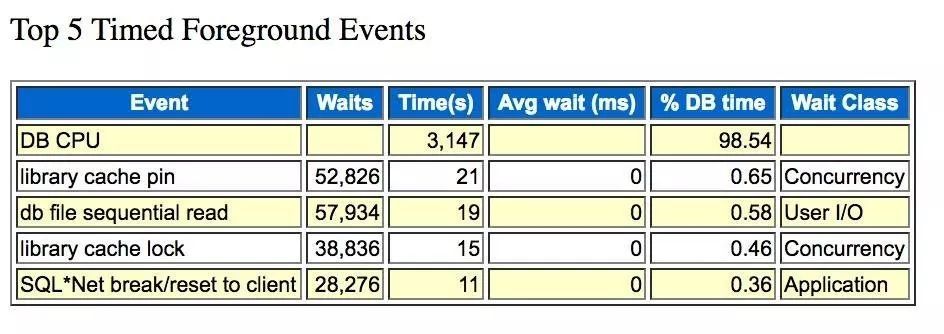
一个小时之内出现13148次错误的解析,定位每秒解析失败次数 3.6 次。这个频率有点高! 不可能是 DBA 手工执行 SQL 错误造成的。
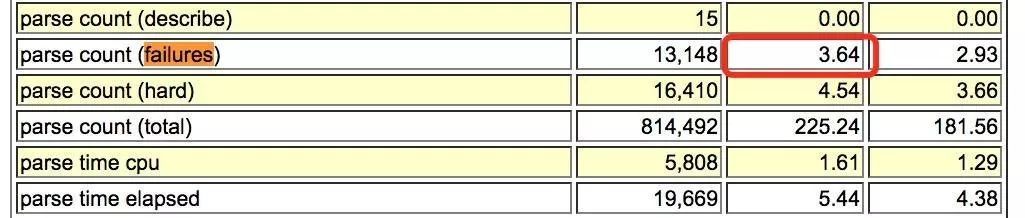
定位错误的 SQL 语句
通过事件 10035 事件定位错误的SQL,在生产环境短暂打开跟踪,参考文档How to Identify Hard Parse Failures (文档 ID 1353015.1) :
ALTER SYSTEM SET EVENTS '10035 trace name context forever, level 1';
ALTER SYSTEM SET EVENTS '10035 trace name context off';
跟踪文件中找到错误的 SQL 语句:
PARSE ERROR: ospid=12597, error=904 for statement:
select nvl(CantonCode,'0') as CantonCode from xxxx.yyyyy where recID = :1;
通过sqlplus可以验证错误的 SQL,表xxxx.yyyyy没有CantonCode字段,只有CANTONCODEEX字段。初步猜测是因为应用的数据库 schema 版本控制没有在生产上同步引起,客户与开发商确认后,最终解决问题。

分析总结
我们根据数据库high cpu,数据库top等待事件中cursor:mutex S占比非常高。定位到存在错误的 SQL,触发 Bug 16175381,导致进程自旋。 通过10053事件跟踪我们定位了错误的 SQL 语句并有开发商修复。
遗留问题
为什么故障发生时, time model failed parse elapsed time中错误解析的时间占比只有0%? 如果大部分的解析时间时间都计入failed parse elapsed time,那么我们第一时间就可以定位到错误解析的问题了。是不是 AWR time model 的数据,对于错误解析时可能出现偏差? 我们进行了几项测试,测试数据库版本为11.2.0.4。
测试1.非绑定变量SQL + cursor_sharing设置为exact
执行10W次sql update yyyy set n = n + 1; (yyyy表不存在),执行前后做上快照,生成awr报告。从时间模型可清楚发现 failed parse elapsed time 占比达68%。
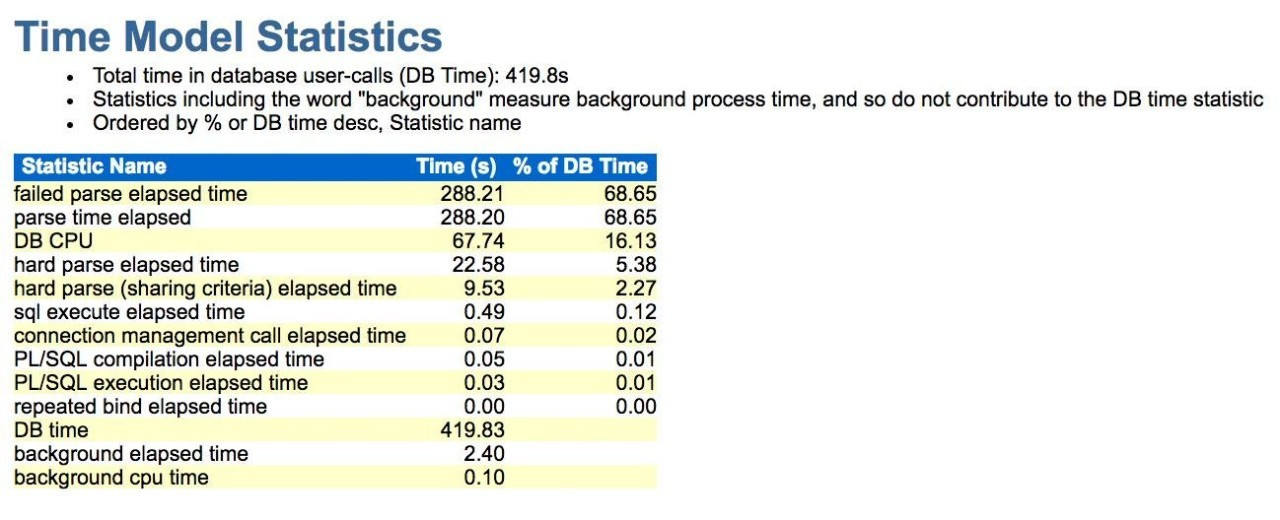
parse count (failures) 每秒3352次,这里可以马上定位问题为错误解析引起。
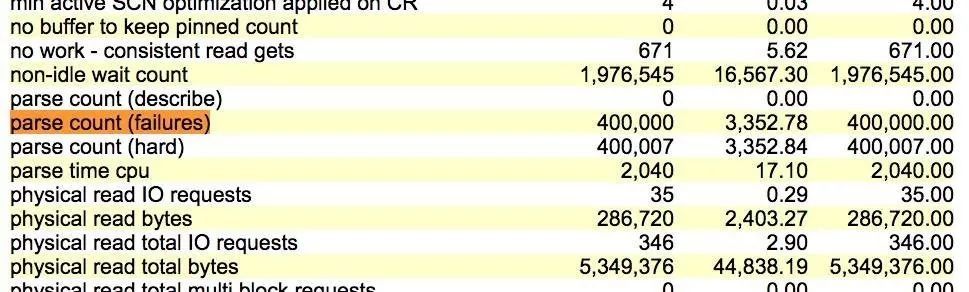
测试2.非绑定变量SQL + cursor_sharing设置为force
与测试1一样运行sql 10W次,生成的AWR报告部分时间模型中,解析失败占用比例下降至11%,为测试1的6分之1!

parse count (failures) 每秒3465次,这个指标值还是准确的。
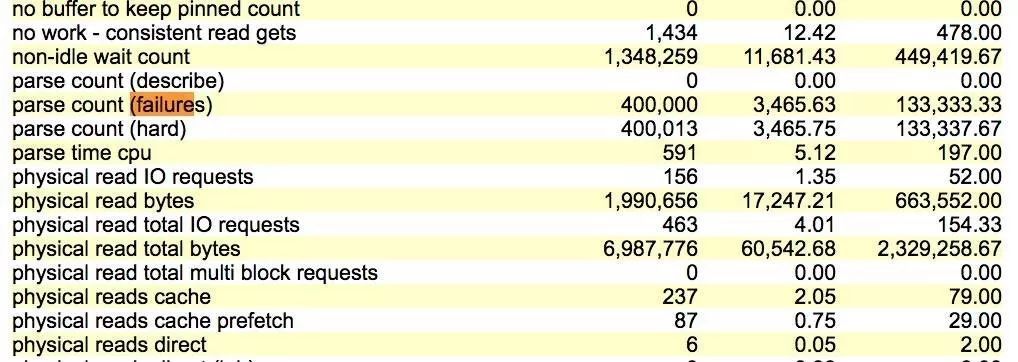
测试3.绑定变量SQL + cursor_sharing设置为exact
先执行语句 variable n number exec :n := 1 后,再执行10W次sql update yyyy set n = n + :n; 生成的awr报告部分时间模型中,解析失败占用比例下降至2.9%。

parse count (failures) 每秒3459次,这个指标值这里依然准确。
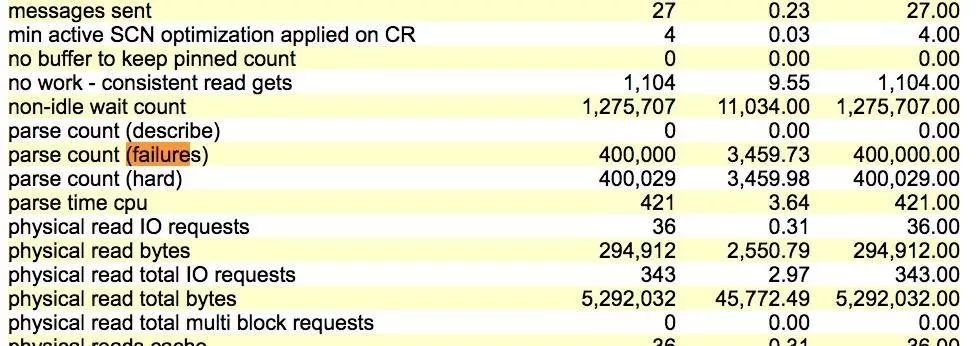
从上面的测试可以发现在11.2.0.4版本中,不使用绑定变量会则计入,Time Model 中有明显的failed parse elapsed time,可以快速的知道存在错误解析的问题;使用了绑定变量的SQL,或者使用cursor_sharing=force,解析出错时基本不计入failed parse elapsed time,这时的 Time model 数据具有误导性。
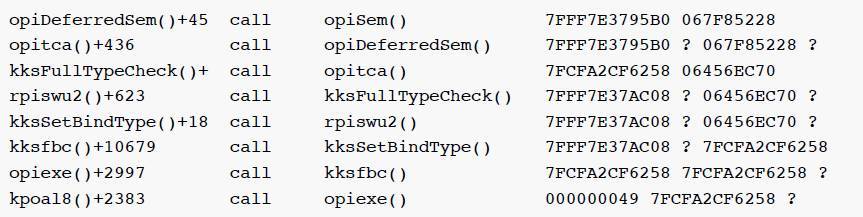
如果对比使用和不使用绑定变量时的堆栈调用,可以发现两者的调用栈有诸多不同,可以猜测 Oracle 在计量绑定变量执行时的错误解析时间是存在问题的.failed parse elapsed time 应该是在 kksLoadChild,opiosq0 and kksSetBindType这些调用中被记录的。
不使用绑定变量的call stack调用部分

使用绑定变量的call stack调用部分
参考文档
How to Identify Hard Parse Failures (文档 ID 1353015.1)
https://docs.oracle.com/cd/B19306_01/server.102/b14237/dynviews_2087.htm#REFRN30340







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721