
第一天的keynote,拉里提出了自治管理的数据库,我也写了一篇文章 DBA 3.0时代来了!做了一些简单分析,国内国外的很多朋友对这个事情引发了不少讨论,这里建议大家不要只看到一些字眼就下结论,有时间去琢磨更多的技术内容来得更实在些。很多DBA今天还知道微软最新一代数据库 SQL Server 2017 正式发布,Windows、Linux和Docker版本已经GA,数据库行业现在发展飞速,不进步就是退步。
OOW的第二天同样精彩,我也特意梳理了几块亮点内容与大家分享。今天的内容主要是两部分:Oracle和MySQL。Oracle主要选择了新一代数据库(18c)的主题,比如在高可用方面的特性;MySQL则是选择MySQL 8.0的相关的主题内容。
说起高可用方案MAA,Oracle经历了16年的考研和探索,从9i的方案到现今的架构变迁,无论是在硬件和软件层面都在发力,看起来简单的架构图后面的实现大不同。

所以立足根本,无论自治数据库如何炫酷,功能丰富,还是要依赖MAA。

我是带着问题来听这个主题的,所以就会侧重去关注一些点,比如大家对sharding非常关心,这个特性对于业务场景是需要的,但是技术上来说还是有一定的复杂度,里面提到的一个重点案例是中国电信的尝试,从预研到上线用了3个多月的时间。
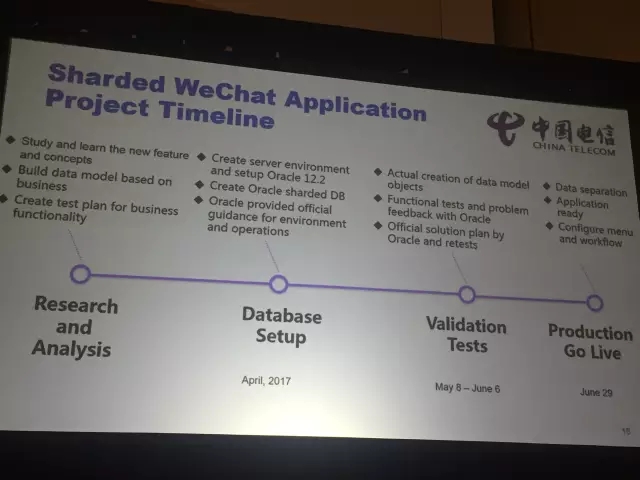
分享里面着重提到了sharding 2.0的概念,也就是18c里面的亮点特性,原来的sharding方案基于hash算法,在功能上使用还是受限,而且关键问题是RAC共享集成式架构,sharding本质是分布式架构,两者结合起来,左右手互搏有些难。Oracle在sharding 2.0里面做了很多的改进,期望解决一些当前碰到的问题。

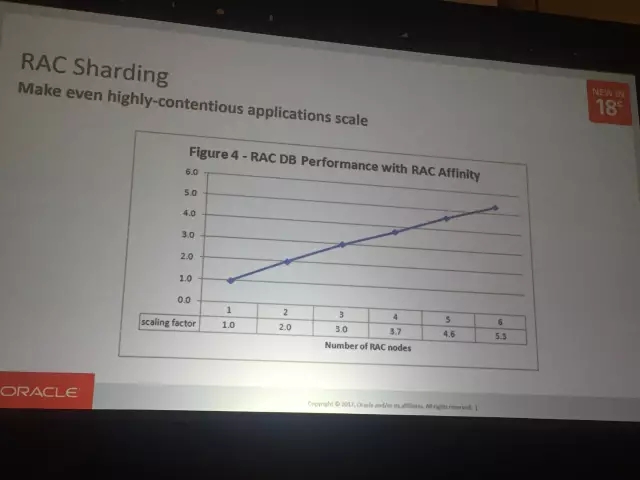
这是RAC Sharding,可以看到Oracle巧妙的解决了架构层面的冗余和冲突问题。每个实例节点可以是sharding的一个单元。

在性能上如何呢?通过这种方式能够快速扩展,可以看到随着节点的增加,性能不降反升。
还有地理复制的sharding功能,如果有全球的多个数据中心或者节点,也可以通过这种方式来做到分片的需求。还有分区方式也支持更加丰富的sharding策略。

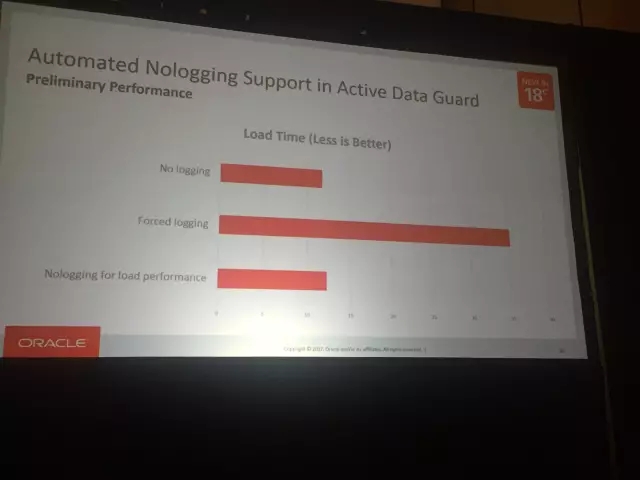
剩下的部分提到了灾备和计划内维护的一些功能点。比如Active Data Guard中在18c里面有了nologging的功能点,如果有数据库加载的场景,启用nologging是一个很好的补充,在保证性能的同时还需要保证高可用。

测试的场景可以看到,如果启用了数据加载场景的nologging,性能相比force logging的提升是相当大的,而相比数据库层级的nologging几乎没有什么变化。
个人觉得下面的功能点很实用,在DG Broker里面使用validate能够干更多的事情,做到self-repair,这个也是自治管理的重点。

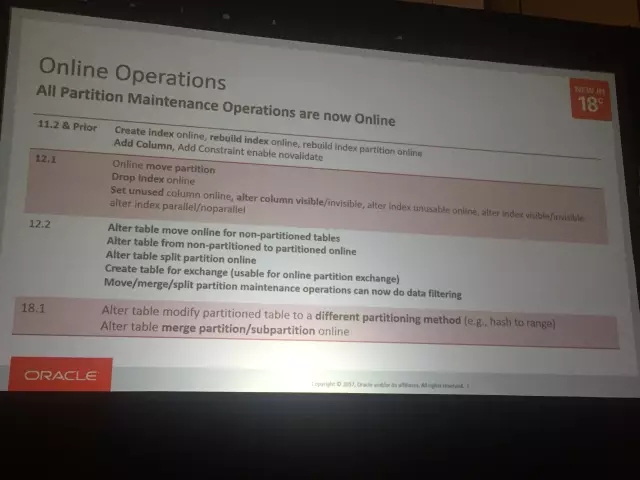
计划内维护大体就是升级,打补丁,还有online DDL了。升级补丁的部分如果能够做到自动化,做到可控,downtime尽可能短,无论是人工还是自动都是需要很深的沉淀。需要明确的是18c的自治数据库的前提是你购买了RAC + Multitenant + Active Data Guard全套组件的,要不怎么自动打补丁,出了事谁来背锅:)

而对于online DDL,在18c里面也做了更细力度的控制,分区,子分区级别都可以做到了。
所以说12c好,18c更好。

MySQL的场次比较集中,场地不是很大,但是基本都坐得满满当当。MySQL官方在做《MySQL Enterprise Edition Complete Guide》的分享,有不少是两个人或者3个人来做的 。

国内使用社区版的还是比较多,很多企业版的组件还没有用到,我也了解了一下。主题《Using MySQL Containers》里面演示了一个在MacOS上安装docker的小例子,讲得会笼统一些。因为开头的时候调研生产中使用Docker的场景,没有看到有人举手,所以内容就偏向于overview一些。
当然对于官方来说肯定是希望支持的,在5.7.20的企业版和社区版本都会体现。相反不开源的Oracle的主题可谓是如火如荼的进行,很多分享内容非常internal了。
Peter分享的主题是《Why we're Excited About MySQL 8》,他的风格和国内的风格比较搭,ppt是那种简洁明快的,一页上面字不多,但是点明观点之后,说得比较细。总体来说MySQL 8.0里面的受益他从Devops的角度来阐述。

当然正如他一贯的严谨,先声明下文档里说测试好了,和生产中马上投入大规模使用是有差距的。

他先选择了Ops方向,从稳定性,高可用,性能,安全,管理等几个层面来说。数据字典中不会再有MyISAM,MySQL在5.0中使用MyISAM作为默认存储引擎,在5.5中使用InnoDB作为默认存储引擎,在8.0里面直接抛弃了MyISAM,同时数据字典的性能也做了很大的优化。

优化程度如何呢,他们得到的一个测试结果,测试的表的量级有些大,5000张表和100万张表的数据字典信息查询效果,在5.7和8.0里面差距很明显,而且默认的数据字符集为utf8mb4。

在安全性上,MySQL也去除了以前做得不好或者不完善的地方,做了一些补充。比如role,其实就是权限的打包,使用role能够方便管理,简化操作。super权限也做了回收,还有--skip-grants的语句,明确告知这么用不安全,直接做了减法。

对于自增列的问题,这个是MySQL里面饱受诟病的老问题了。如果节点重启,会从数据列中按照max(id)+1的方式来处理,在多环境历史数据归档的情况下,如果主库重启,很可能会出现数据不一致的情况,记得在MySQL bug中很多人留言,说十多年前的老问题了,怎么还不解决。这些事情在8.0终于给出了答案。

我认真查了一下这个bug的历史,最早竟然就是今天的演讲者Peter提的。

在优化上MySQL 8.0里面有一个特性是self-tuning,设定了一个参数,修改为auto-tune就可以使得几个参数联动。

而对于undo的处理,其实在MySQL5.6就开始了,5.6中可以配置但是无法调整大小,到了5.7中可以做收缩,到了8.0已经改进的算不错了。

索引优化,提出了不可见索引,使得对于索引敏感的操作有一个缓冲处理,Oracle里面有不可见索引,还有虚拟索引等等,其实还是蛮相通的。

临时表的部分改进,使用了内置临时表的方式,原来的临时表是MyISAM,8.0冷处理之后,把这个问题也一并做了解决。

还有就是备份锁的问题,在8.0里面新加了一个语句,lock instance for backup,使用unlock instance来解锁,这种在线备份时如果有DML是可以的,会有一个实例级备份锁,防止可能导致快照不一致的操作。

优化部分是增加了直方图的内容,粒度到了列级别,而不只是索引级,对于优化器解析处理会有更多的数据,使得细粒度的优化有据可依。
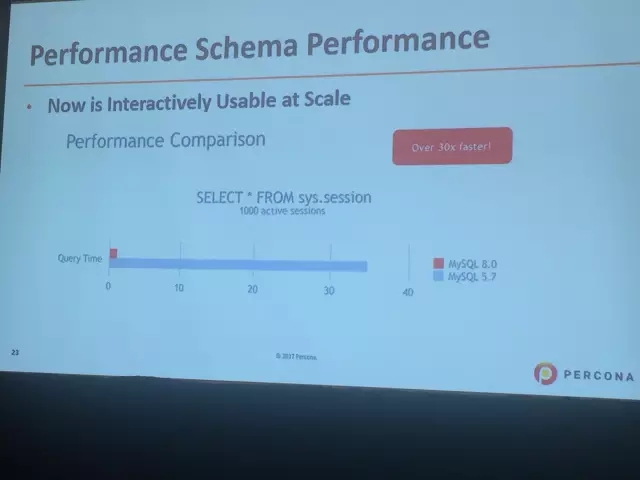
performance_schema的性能问题比较多,在5.7推出了sys的方式,集成整合简化了复杂度,在8.0里面又做了进一步的改进,比如1000个活跃会话,8.0相比5.7的查询响应时间有了极大的提高。
还有数据库中,我们经常会提到的最优的默认值,8.0里面的这几个参数都默认打开了,这确实是最优的默认值。

至于查询缓存这块,Peter说它带来的问题比解决的问题要多,所以直接就去除了,那么可以推荐使用ProxySQL或者其他方式,Peter不会上硬广,而是在建议中留有余地,和场下的MySQL原厂朋友也简单作了互动,说一个问题能够照顾到很多人的感受,还是很细心的。当然还是性能,8.0的性能在特定的场景下还是很有优势的。

MySQL引入了skip locked的方式,能够更好的处理热点问题。

在索引定义的时候可以使用更加丰富的定制功能,比如多字段的asc,desc等。

很多MySQL的主题都有JSON相关的说明,这里也不会落下,但是这个功能还属于实验阶段,使用还是要慎重。

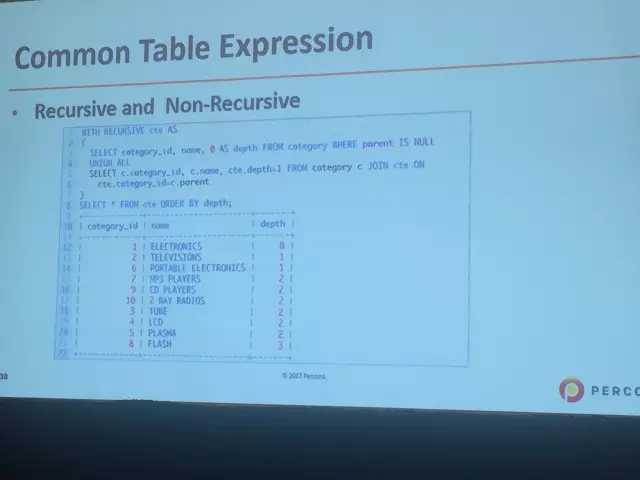
数据库中的CTE(公用表表达式)很多数据库都有相应的实现,8.0也支持了,对于递归查询还是很有帮助的。
窗口函数,这个严格来说属于OLAP的范畴,但是数据处理中有的话如虎添翼。

在GIS方面,MySQL支持的很不错,甚至说在一些场景里比PG的测试效果要好。8.0里面支持的范围更广了,Percona官方也做了一些测试,感兴趣可以看一下。

MySQL和PostgreSQL都是开源领域,所以很多人会去对比它们,Percona之前做了一次性能测试的对比,还是值得借鉴的。相关文章:每秒百万查询:MySQL与PG在苛刻负载下的和平之战。所以到了最后,至少目前来看,8.0做了很多让人欣喜的改进。
微信扫一扫
关注该公众号







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721