
作者介绍
梁敬彬,福富研究院副理事长、公司唯一四星级内训师,国内一线知名数据库专家,在数据库优化和培训领域有着丰富的经验。多次应邀担任国内外数据库大会的演讲嘉宾,在业界有着广泛的影响力。著有多本畅销书籍,代表作有《收获,不止SQL优化》等。
本章会较为简要地给大家介绍一下体系结构知识,然后描述体系结构和SQL优化的关系。最后通过系列扩展的相关优化案例来拓宽我们的视野,从而使我们更深入地了解体系结构的原理。

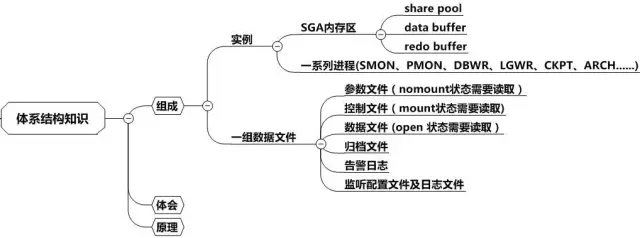
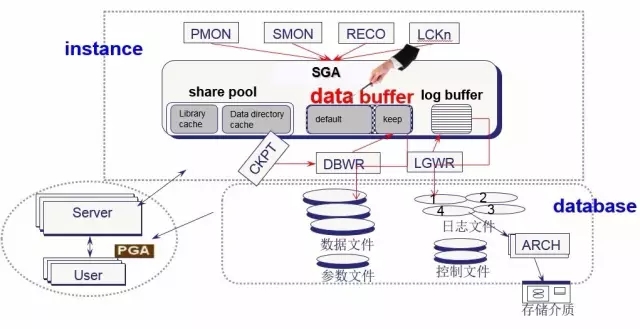
Oracle体系结构由实例和数据文件两部分组成。其中实例又由Oracle开辟的共享内存区SGA和一组进程组成。
其中SGA被划分成3部分,这里是知识重点。首先Shared Pool区是用来解析SQL并保存相关执行计划的区域,接下来SQL根据对应的执行计划来获取数据时首先看Data buffer中有没有所需的数据,没有则从磁盘读进Databuffer,下次再访问时可能就不需要从磁盘读取了。当更新SQL语句出现时,Databuffer中的数据变成脏数据,必须要将其写进磁盘。而为了保护这些数据,才有了Log buffer区。
更多的细节就不再累述了,详情阅读《收获,不止Oracle》。
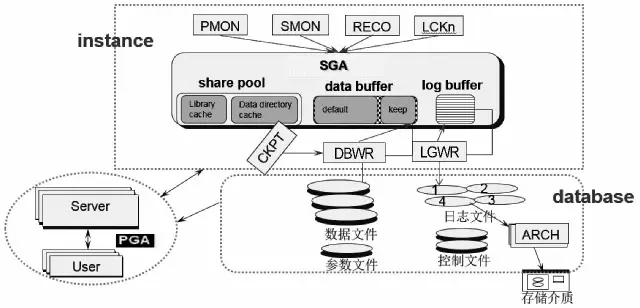
Oracle体系结构的SGA部分,如下图所示:


原来SGA开辟的就是这么大。
未启动数据库前的oracle进程情况:


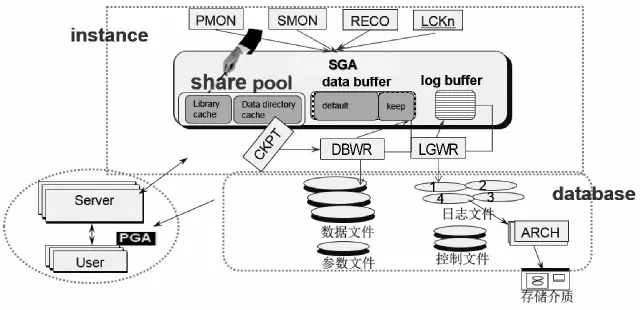
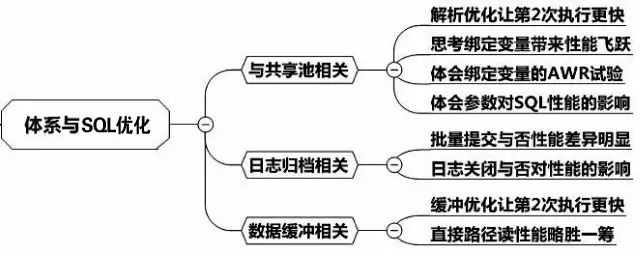
接下来我们从共享池、日志及数据缓冲三个方面来描述体系结构与SQL优化的关系,总体思路如下图所示:
首先我们看看体系结构SGA的三大组成之一的共享池Shared pool,这是SQL语句执行中最先访问到的内存部件。
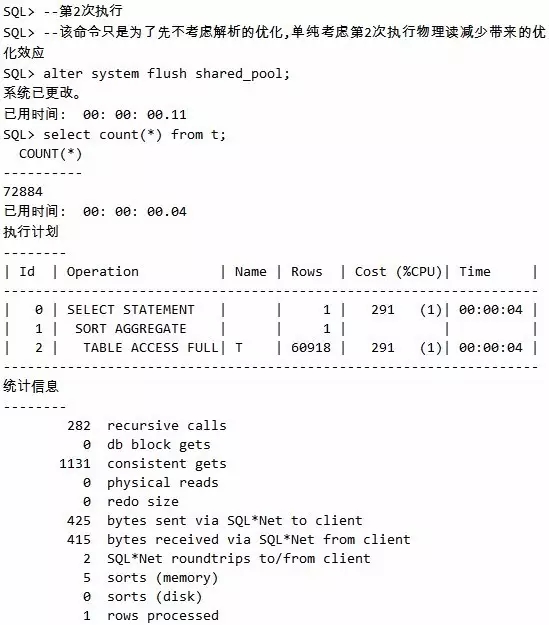
由于SQL第1次执行时已经完成了语法、语义的判断,完成了解析,保存了优选过的执行计划,第2次执行时Shared Pool中的这些事就可以不用去做了,所以必然执行效率能够提升不少。请看如下例子,首先是环境准备。

第1次执行:

SQL第二次执行:

脚本1 解析优化让第2次执行更快
结论:
第1次执行时间是00: 00: 00.10,Recursive Calls次数为28;
第2次执行时间是00: 00: 00.07,recursive calls次数为0。
很显然,解析的优化让第2次执行更快。
现实生活中绝大部分用户都有输入自己手机相关信息来访问某系统的经历,如SQL简单构造:select * from t where nbr=18900000001。可以预见到,系统很快就会出现新的nbr取值的SQL,如select * from t where nbr=18900000002。用户一多,系统中将会出现大量高度相似仅nbr不同的SQL,这些不同的SQL实际上执行计划应该都是一样的,但是在Shared Pool里都要挨个解析,因而做了很多的无用功,由于存储在共享池中,也耗费宝贵资源。
如果用绑定变量,这些SQL都变成select * from t where nbr=:x,这下形成一条SQL,减少了系统大量的解析时间,也节省了共享池资源,性能得到大幅提升。下面我们看一组例子,如下:
未使用绑定变量:
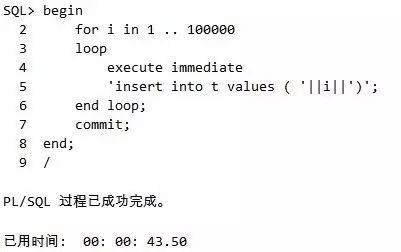
脚本2 未使用绑定变量脚本
使用绑定变量:

脚本3 使用绑定变量脚本
可以看出性能差异非常明显,未使用绑定变量是43s,使用后仅4s。
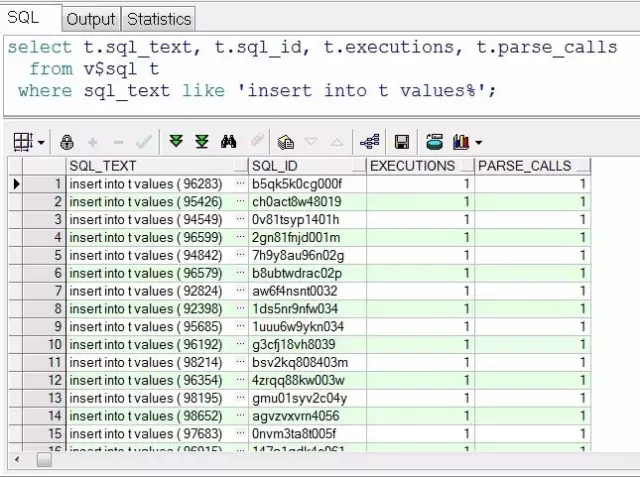
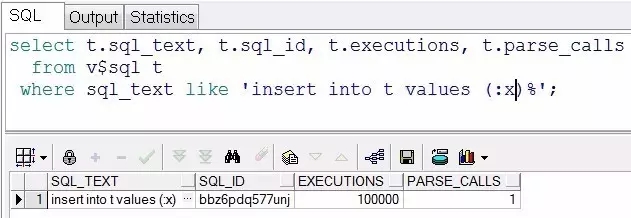
脚本4 体会硬解析次数和执行次数
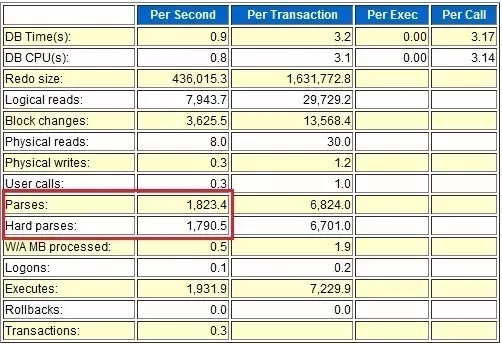
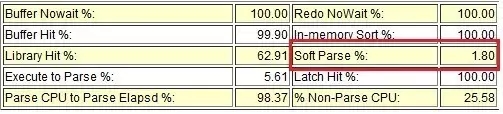
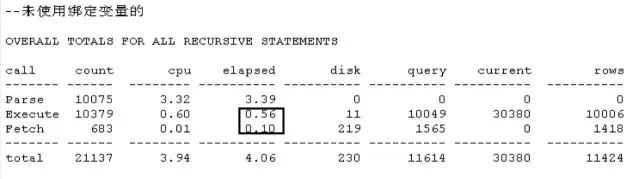
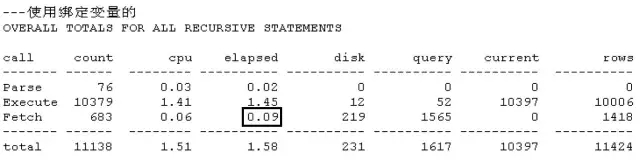


脚本5 缓冲优化让第二次执行更快
通过试验一看出,第1次执行的physical reads的值为1038,第2次执行则值为0,物理读瞬间大幅度减少,性能自然就提高了。不过这里细心的读者可能会发现,recursive calls都为282,并没有变化,因为这里我们通过alter system flush shared_pool,特意将解析优化的缓存给取消了。

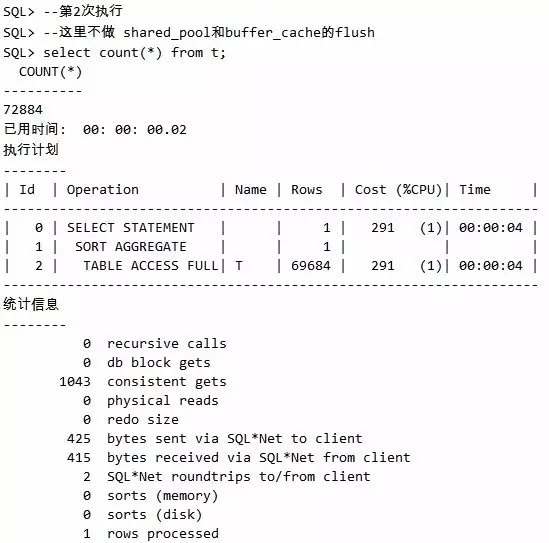
脚本6 解析和缓冲优化一起来
接下来的这个试验还请同时观察recursive calls与physical reads,第2次执行后这两个取值皆为0,这是解析和缓存同时优化后的情况。
环境准备:
|
--环境准备(构造一个有100万左右记录的表) drop table t purge; create table t as select * from dba_objects; insert into t select * from t; insert into t select * from t; insert into t select * from t; insert into t select * from t; commit; |
测试普通插入:

测试直接路径插入方式:

脚本7 解析和缓冲优化一起来
可以看出,普通的插入需要的时间是00: 00: 14.81,而直接路径插入的时间是00: 00: 04.22,差异还是非常大的。为啥会有这个差别呢?继续分析上面的试验我们可以看出,普通插入后,继续查询的物理读为0,而直接路径插入后,物理读为27469。这是为啥呢?因为直接路径读写可以绕开SGA,这对于插入而言少做事了,所以性能当然更好。
不过话说回来,优化都是相对的,插入由于不缓存数据,所以插入快了,查询同样也会因为没有缓存数据,而导致接下来的查询就不会快了。
Oracle的体系结构的log buffer部分,如下图所示:


脚本8 批量提交与否的性能差异
可以看出,未使用批量提交,耗时11.21s,使用后耗时4.26s,有天壤之别。

测试直接路径写方式:
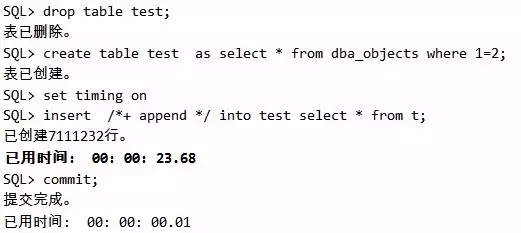
脚本9 直接路径写插入
测试nolgging关闭日志+直接路径写方式:
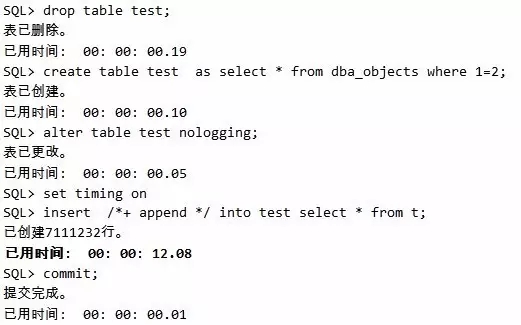
脚本10 直接路径写加关闭日志的插入
从这里可以清晰看出,不关闭日志的插入耗时23.68s,而关闭日志的插入耗时12.08s,差别巨大。当然我们不是说鼓励大家都把日志关闭了,只是告诉大家,在某些特定的场景下,数据不是非常重要的时候,允许关闭日志的时候,性能可以有较大幅度的提升。

某系统遭遇大量硬解析的性能瓶颈,相关人员无从下手来找到具体的未使用绑定变量的SQL,这时候该如何处理呢?我们模拟一个这样的场景,来看看如何定位出未使用绑定变量的SQL。首先构造一个未使用绑定变量并频繁执行的SQL如下:
脚本11 构造未使用绑定变量的SQL
捕获出需要使用绑定变量的SQL的思路如下,其原理是未使用绑定变量的SQL比较类似,通过@替换相似部分,然后提取相同的分组,从而找出未使用绑定变量的SQL。

接下来用如下方式就可以快速定位了:

脚本12 获取未使用绑定变量SQL的方法
接下来的情况如下所示,果然定位非常清晰,就是它了!

大家知道,SQL的逻辑读一般不可能为0,不过有一种情况,真的可以让SQL的逻辑读为0,那就是缓存结果集。设定方法是在SQL语句中加上如/*+ result_cache */的hint或者在session属性上固定这个特性。
当设定完毕后,第一次执行的时候,SQL执行的结果集会被扔到SGA的Shared pool中,下次执行的时候直接把它当作结果来用就OK了,因为根本不需要访问任何指定对象,所以逻辑读为0,试验如下:

脚本13 缓存结果集让逻辑读为0
使用缓存结果集一定要注意应用的场景,因为SQL对应的对象(比如表)等一变化,相关SQL的缓存结果集就自动失效了。所以这个技术一般用在表记录很少变化的情况。
与SQL的缓存结果集类似,缓存函数的结果集也可以使逻辑读为0。某些情况下,函数的结果集由于基表等数据没有发生变化,故而其也会保持不变,这个时候为了避免重复计算函数,就可以应用缓存函数结果集的技术。同样这个结果集也存在Shared pool中。具体构造的案例脚本如下:


脚本14 缓存函数结果集让函数逻辑读为0
(1)感谢,keep让SQL跑得更快
大家知道,Data buffer的数据是会被挤出去的,所以有的时候,为了避免某些重要的数据被挤出去,我们会采取一些特殊的手段来固定这部分数据,这也是一个常见的做法。如何来固定这部分数据呢?具体的思路和方法如下。
未固定时的情况:

脚本15 未固定缓存的情况
固定的方式和查询的方式如下:

脚本16 固定缓存的情况
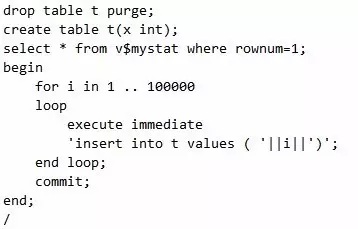
数据库运行得健康与否是有很多指标的,我们可以通过每段时间数据库运行时间、日志、逻辑读、解析、事务数等指标的变化,来分析数据库在某个时段是否有异常。这是一个非常有用的监控数据库运行状态、定位数据库问题故障点的方法。脚本如下:

脚本17 查询数据库分时段的健康状况
很显然,这个输出结果对我们确定数据库的峰值时间点能起到一定的指导作用。
很多生产系统由于没有注意批量提交的事情,出现了性能问题,产生了相关的日志等待。表现在告警日志上,就是日志切换过于频繁。此时我们也可以通过观察AWR报表中事务个数和每个事务的尺寸来看出问题所在。不过很多时候,我们也可以通过如下方法及时地跟踪到具体未批量提交的SQL是哪些,如下所示:
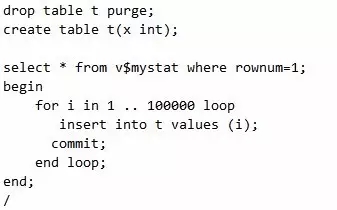
获取提交次数超过一个阈值的SID
获取到对应的Sql_id

通过Sql_id得到对应的SQL

脚本18 如何捕获提交过于频繁的语句
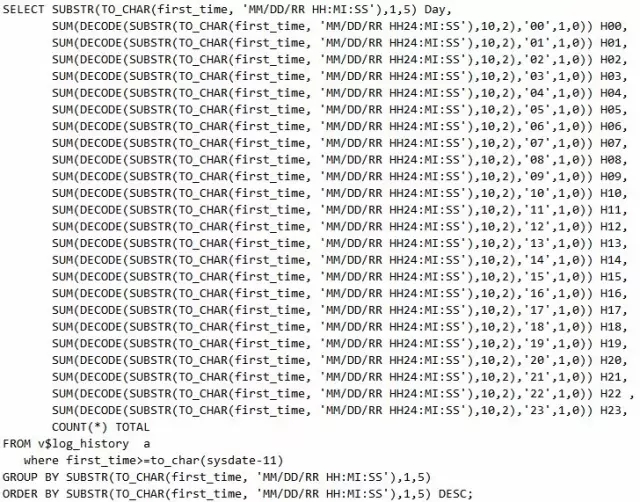
输出结果如下,因此可以很清楚地看出11月12日问题比较明显。

脚本19 查询日志切换规律的语句
XXX工程点最近经常出现数据库无法连接的问题,经查是归档空间满导致,清理归档后恢复正常。由awr报表中load profile可以算出,每天日志量大约为160GB,而XXX工程点的归档空间大约为1TB左右,这样不到一周就满了。
按照以下步骤可以查出这些redo日志是谁产生的,本例中的故障是由一个自身监控的存储过程导致。脚本如下:


解决过程:

脚本20 查出日志暴增的SQL语句
-AND-
更多数据库干货
尽在全球敏捷运维峰会北京站!
9月15日 大牛亲授绝技 就差你了

抢座链接:http://www.bagevent.com/event/643565#website_moduleId_60229








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721