
作者介绍
梁敬彬,福富研究院副理事长、公司唯一四星级内训师,国内一线知名数据库专家,在数据库优化和培训领域有着丰富的经验。多次应邀担任国内外数据库大会的演讲嘉宾,在业界有着广泛的影响力。著有多本畅销书籍,代表作有《收获,不止SQL优化》等。
经过前面第一、二、三章的学习,我们不仅能快速获取整个数据库的整体信息,还能迅速得到SQL的所有详细信息。如果能将笔者研发的自动获取脚本应用在工作中,在解决问题上则无疑更是如虎添翼。
接下来笔者将教会大家如何真正读懂执行计划,这个其实并不容易。循序渐进学完这三个章节后,优化的大方向基本上都清晰了,剩下的就是具体的优化实施。可能会:修改数据库及主机相关性能参数,根据业务规则修改SQL代码,重新收集统计信息获取更准确的执行计划等等。
停!你想过在不改写SQL和不重新收集统计信息的情况下,改变SQL的执行计划吗?这,可能吗?当然可以!
不过,Oracle不是很智能。如果统计信息正确,应该可以得到正确的执行计划;如果统计信息不准确,用收集的方式更合理吧?
你说得太好了!不过假如生产中真的出现了某条SQL由于统计信息不准确执行非常慢的情况,你立即收集统计信息这个动作会影响生产吧?如果要等到系统较闲可以收集的时候,这个SQL不是要影响性能很久吗?
哦,说的是啊。另外,要是万一出现BUG,某SQL无论如何收集统计信息都得不到正确的执行计划,而你明知正确的执行计划该是怎么样子,那你该怎么办呢?
自己动手改变执行计划。正确!看来,左右SQL执行计划还真有用,OK,让我们开始吧,先看看总体学习思路,如下图所示:
一、控制执行计划的方法综述

1、控制执行计划的意义
前面已经讲过了,这里简单总结为两点:1.可以临时在高峰期解决问题,避免因收集统计信息带来的开销;2.有BUG导致执行计划一直不对,只好用人工控制来处理。
2、控制执行计划的思路

一般来说,环境的影响会改变SQL的执行计划,除此之外就是Hint 会强制让Oracle根据你的要求走对应的执行计划。
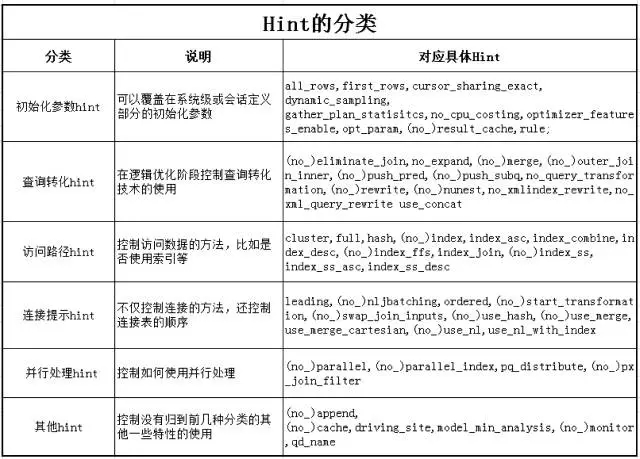
Hint的种类有多种,如下表所示:
此外,写法差异也会带来执行计划的改变,比如with子句改造、分析函数改造、rownum的位置,等等。还有一些设计的特性带来的执行计划的改变,比如普通表成为分区表就意味着执行计划从全表扫描要转换为分区扫描了。这些写法改变和设计改造改变执行计划的例子很多,在本章的案例部分将会详细解说。
二、从案例探索其方法及意义

简单的SQL语句只有一个单独的查询块。当使用视图或类似子查询、内联视图、集合操作符等结构时,就会出现多个查询块(比如这个例子的查询就有两个查询块,第一个是引用了dept表的主查询,第二个是引用了emp表的子查询)。
之前我们总结了hint的分类,除了第一类初始化参数hint外,所有其他的hint都是仅针对单个查询块起作用。下面来看如何让各个模块的HINT生效的各种方法。
环境准备:
|
drop table emp purge; create table emp as select * from scott.emp; create index idx_emp_deptno on emp(deptno); create index idx_emp_empno on emp(empno); drop table dept purge; create table dept as select * from scott.dept; create index idx_dept_deptno on dept(deptno); |
请看如下语句的执行计划:
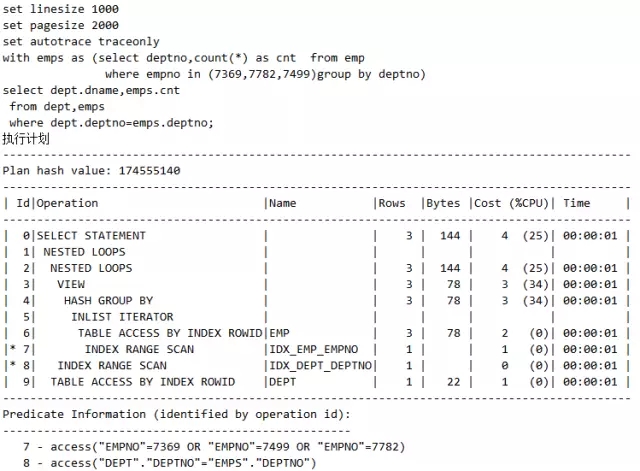
1)控制在所在的查询块内
两个hint的有效区域都被严格控制在它们所在的查询块内,如下:
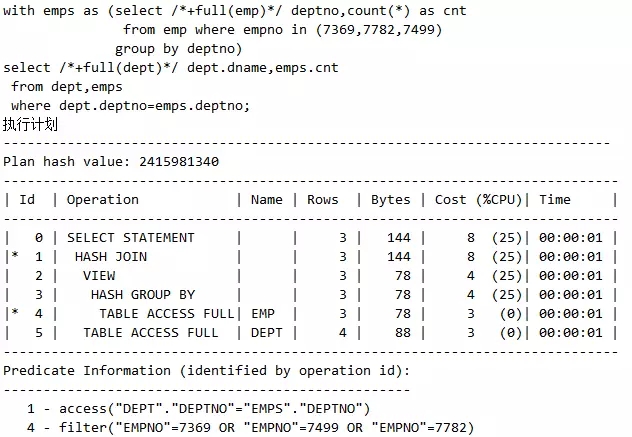
脚本1 Hint控制查询块
2)全局的Hint的别名引用
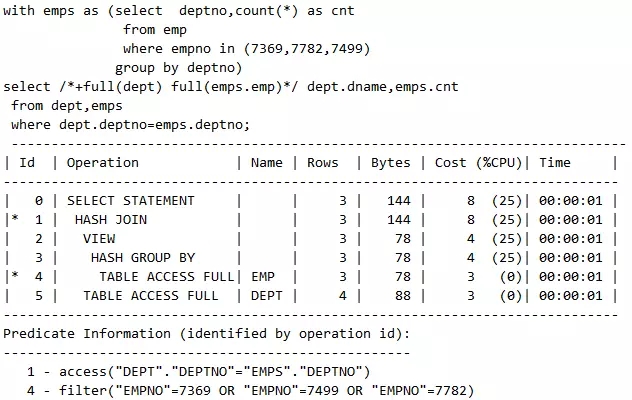
脚本2 全局的Hint的别名引用
3)用qb_name定义方式
有的时候SQL不写子查询的别名,比如WHERE条件中的子查询显然用不到别名,这时可以用qb_name定义方式,其中,qb_name(main)是固定必须写的,比如如下的full(@main dept)就是来引用主表的。
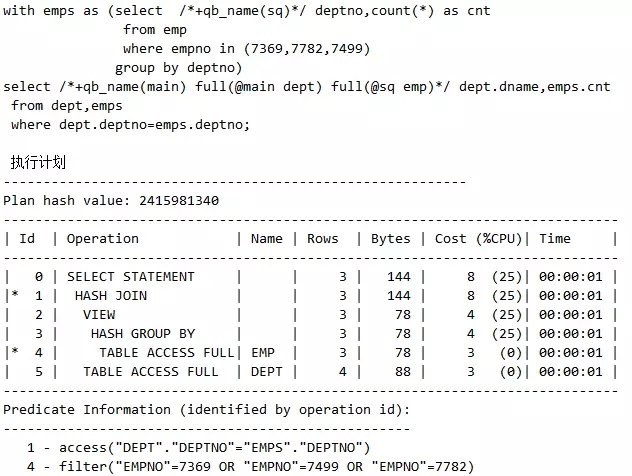
脚本3 用qb_name定义方式
HINT在使用过程中时常会遇到无法生效的情况,这时我们要冷静分析判断,一般来说,就是算法无法支持、Hint有矛盾、根据Hint的结果执行会错、书写语法错这几个原因。
1)算法没能够支持
环境准备:

语句1,使用use_hash的Hint希望能走Hash连接,结果实际是NL连接,因为Hash连接不支持连接条件是t1.id > t2.t1_id 这样不等的写法,如下:
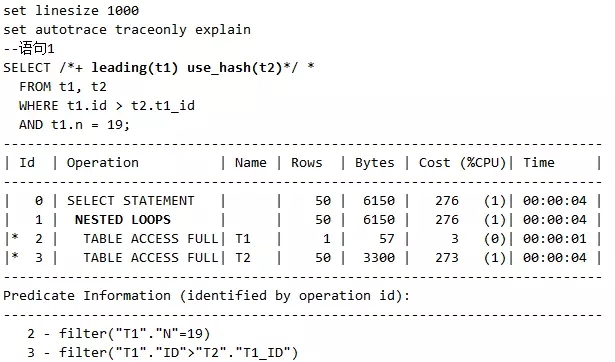
脚本4 use_hash的算法不支持不等值连接
语句2的连接条件是Like,同样只能适用于NL,而不能适用于其他,这里试验use_merge,一样以失败告终:
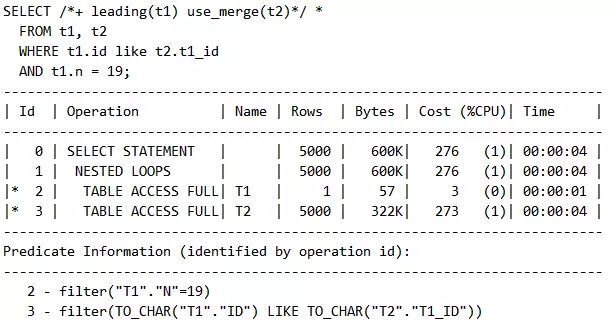
脚本5 use_hash的算法不支持LIKE连接
2)组合Hint有矛盾
我们接上面的例子,继续运行一个SQL语句,如下:
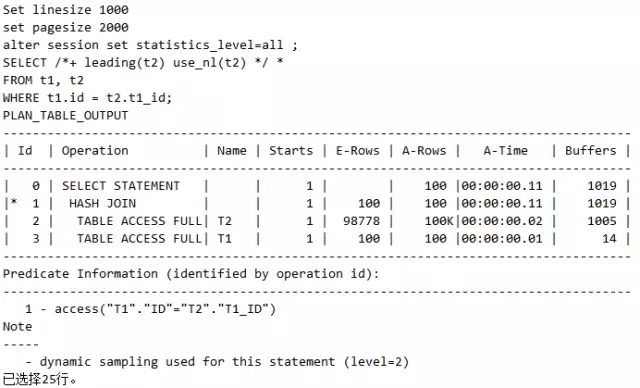
脚本6 组合Hint有矛盾
这里我们发现,我们明明使用use_nl的Hint,走的却是Hash join,这是为啥呢?因为这里use_nl(t2)表示t2被驱动,也就是t2表后访问,而leading(t2)却告诉我们这是表示t2表要前驱,先访问。这不是矛盾吗?所以这个Hint失效了。
3)依据Hint结果执行会错
请看如下语句,使用index(t,idx_object_id)希望语句强制走索引,结果如何呢?请看:

脚本7 依据Hint结果执行会错
发现依然走的是全表扫描,Hint失效了。真正原因是,如果走索引,那就要依赖索引来回答条数的问题。这里有巨大风险,因为索引不存储空值,而索引列并没有保证非空,这里的值会不正确。
4)书写出现了错误
如果SQL的表有别名,必须用别名而不能用原表名,否则无法生效,这点要牢记。比如如下:

脚本8 Hint书写出现了错误
很显然,这里如果是如下两种写法都不会出现问题:要么用别名t,要么就干脆这个SQL语句本身就没有别名。
|
select /*+index(t,idx_test_objid)*/ * from test t where object_id>0; select /*+index(test,idx_test_objid)*/ * from test where object_id>0; |
当然,还有的是把index(t,t_idx) 不小心写成了 indexx(t,t_idx),把/*+full(t)*/ 写成了/*full(t)*+/ 等诸如此类的低级错误,一定要细心哦,这里就无须举例说明了。
1)执行计划SQL写法差异改变之1_with子句
环境准备:
|
drop table t_with; CREATE TABLE T_WITH AS SELECT ROWNUM ID, A.* FROM DBA_SOURCE A WHERE ROWNUM < 100001; SET autotrace traceonly Set linesize 1000 |
语句1:

语句2:

脚本9 执行计划SQL写法差异改变之1_with子句
亲们,看到什么变化了?没错,有点看不懂。
SYS_TEMP_0FD9D6605_3B91BA4。这就是WITH子句的魅力,一次获取后缓存在内存中多次使用,你看不懂的执行计划是很牛的。
2)执行计划SQL写法差异改变之2_insert all
环境准备:
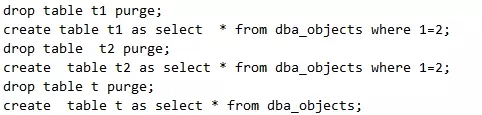
普通的插入语句:
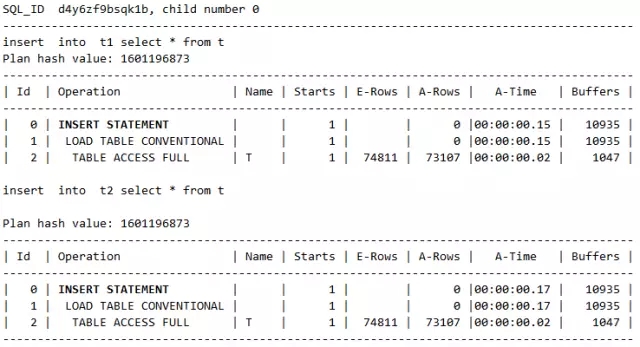
假如T表的数据不会变化,看如下语句:
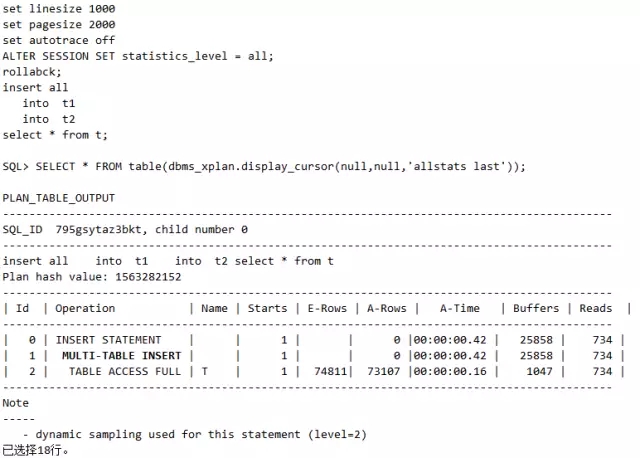
脚本10 执行计划SQL写法差异改变之2_insert all
大家看到一个新词MULTI-TABLE INSERT,这就是经典的Insert all多表插入对应的执行计划。从性能上来看,insert all不一定会有优势,但是当分开写和合并写不等价的时候,分开写要很麻烦,比如锁表,比如中间表,这样性能就要比insert all差多了!
3)执行计划SQL写法差异改变之3_rownum分页
环境准备:
|
drop table t; create table t as select * from dba_objects; set linesize 1000 set pagesize 2000 set autotrace off |
语句1:
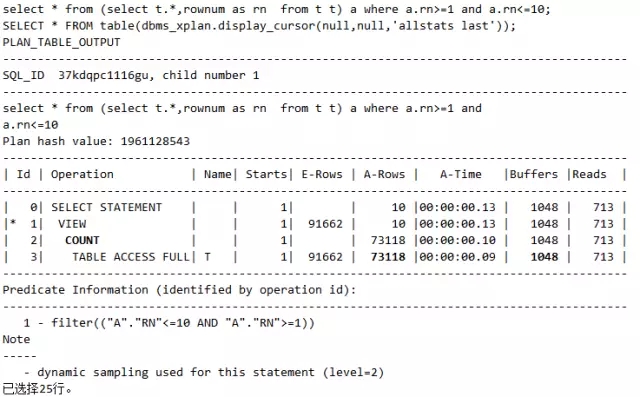
语句2:
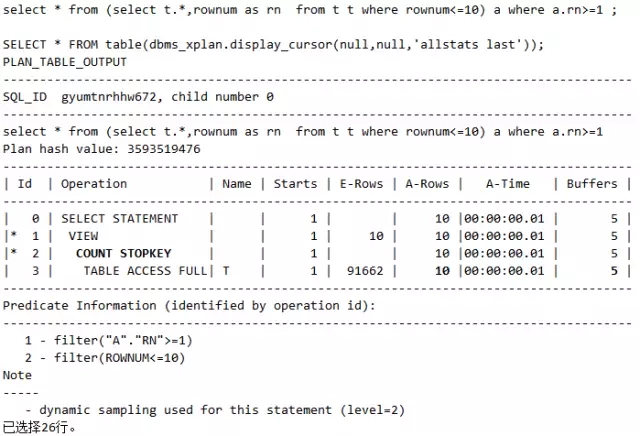
脚本11 执行计划SQL写法差异改变之3_rownum分页
说明:语句1和语句2在写法上是等价的。但是语句2走的是COUNT STOPKEY ,请分别观察语句1和语句2的执行计划中的A-ROWS部分。
4)执行计划SQL写法差异改变之4_rownum实体化
不少开发人员喜欢使用复杂子查询写各类SQL,其实很多时候,要是不注意某些细节,就会出现很多问题,如性能问题甚至结果值不对。我们举个某运营商系统的例子,具体如下:
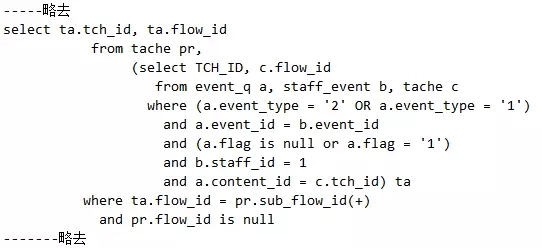
这条SQL本身很复杂,我们把其他部分略去,只显示典型的子查询这一小部分,另外主要也是这一小部分慢,如果把这一小部分注释掉,执行可在1s内完成,否则需要30s才可以完成。
我们单看这一小部分的执行计划,截取如下:

由此我们可以很清楚地判断,该子查询的连接顺序是什么。首先是外面的TACHE表先和ta结果集的TACHE表连接,然后再和STAFF_EVENT连接,最后和EVENT_Q完成连接!由于staff_event这个表和TACHE表没有连接条件,就是没有体现staff_event的某某字段和TACHE表的某某字段关联的地方,所以这里产生了笛卡儿乘积!因此本次查询非常慢。
该如何处理呢?其实很简单,我们发现,整个语句最终只返回42条记录。

说明ta这个结果集本身返回的记录数并不多,虽然tache是一张大表,但是这段语句如果没有笛卡儿乘积,应该非常快!
通过简单研究发现,只要ta结果集内部先完成表连接,再和外部连接,就不至于产生笛卡儿乘积了。因为在ta结果集里,我们可以让STAFF_EVENT b和EVENT_Q a先完成连接,它们是有连接条件的,条件是a.event_id = b.event_id。接下来这两个连接再和ta结果集中的tache c表连接,又有连接条件,条件是:a.content_id=c.tch_id。最后再和外面的tache pr表完成连接,连接条件是:ta.flow_id = pr.sub_flow_id(+)。如此看来,不可能有笛卡儿乘积!而如何让Oracle的子查询不要先自行出去和外面表连接,再回过来连接内部剩下的部分呢?
很简单,只要修改为如下语句即可,增加rownum部分:
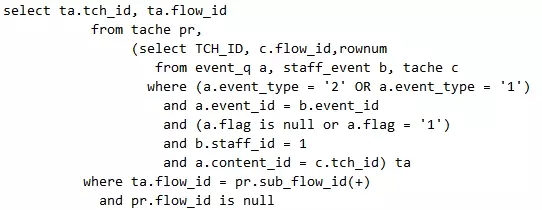
脚本12 执行计划SQL写法差异改变之4_rownum实体化
为了保证rownum的结果集是对的,oracle不可能先出去和结果集外的表关联一部分再回到结果集内,只可能内部先关联了,因此,我们成功了!最终执行计划如下,笛卡儿乘积消失,总的SQL语句执行时间从30s变为1s。

5)执行计划SQL写法差异改变之5_rowid 的影响
环境准备:
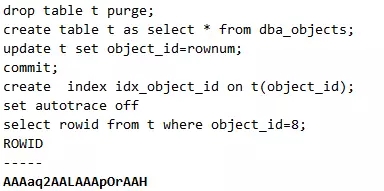
语句1:
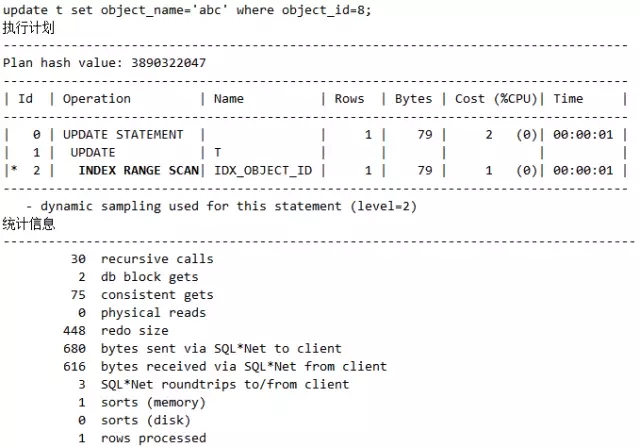
语句2:

脚本13 执行计划SQL写法差异改变之5_ rowid 的影响
说明:语句1和语句2在某些业务场景下,显然是等价的。但是语句2走的是TABLE ACCESS BY USER ROWID,而语句1走的是INDEX RANGE SCAN。请注意这个TABLE ACCESS BY USER ROWID扫描方式,其直接根据rowid来访问,是最快的访问方式!
6)执行计划SQL写法差异改变之6_缓存结果影响
环境准备:
|
drop table t purge; create table t as select * from dba_objects; insert into t select * from t; commit; |
语句1:
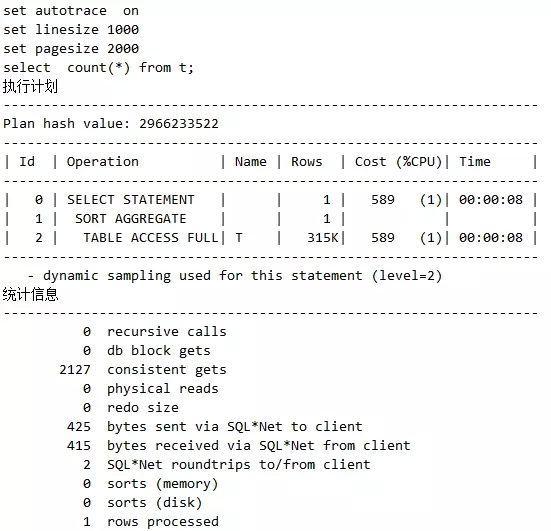
语句2(注,这是连续执行第2次的输出结果):
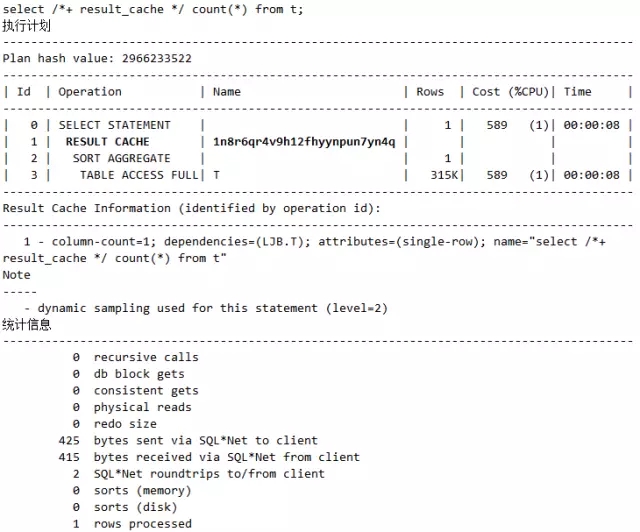
脚本14 执行计划SQL写法差异改变之6_缓存结果影响
可以看到,语句2出现RESULT CACHE关键字,这就表示该写法用了缓存结果集的特性。当然,这是特定场合应用的技术,不可滥用。
7)执行计划SQL写法差异改变之7_分区条件有无
环境准备:
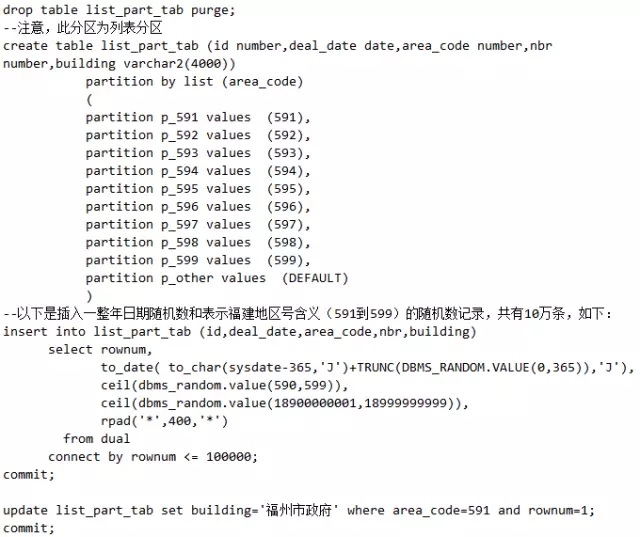
语句1:

语句2:
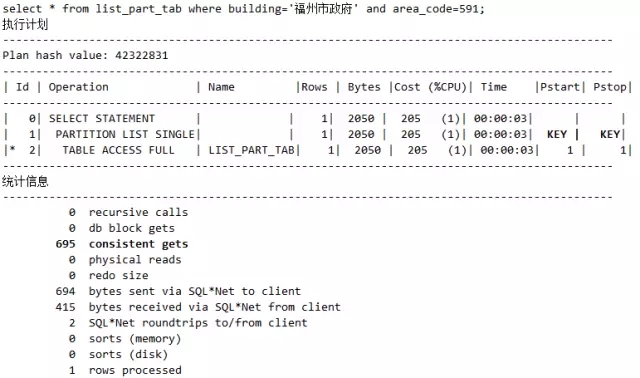
脚本15 执行计划SQL写法差异改变之7_分区条件有无
说明:两个语句的执行计划似乎没有差别,但是经过仔细查看我们发现,语句1的执行计划中Pstart 为1而Pstop为10,说明从第1个分区遍历到第10个分区。而第2个语句的执行计划中Pstart和 Pstop对应的是KEY,说明它们落在了指定的分区中。执行计划的不同性能也不言自明,逻辑读前者是6576,后者是695。请认真体会这句话:语句1和语句2表面上看不等价,实际从业务角度来看,是等价的,因为福州市政府肯定只位于福州市。
1)执行计划利用设计特性改变之1_分区设计影响
观察范围分区表的分区消除带来的性能优势。
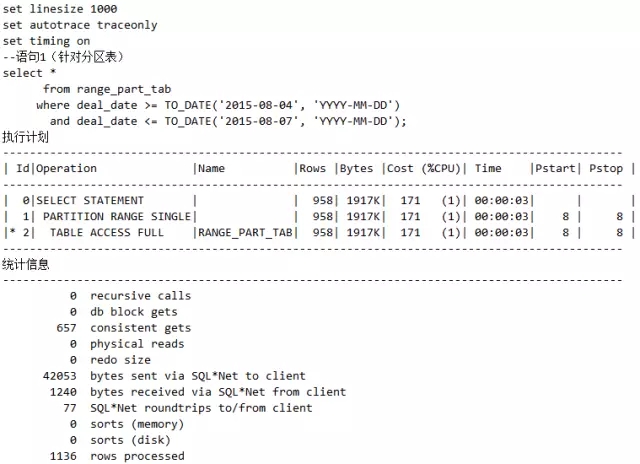
脚本16 分区表的分区消除特性
比较相同的语句,普通表无法用到利用DEAL_DATE条件进行分区消除的情况:

很显然,分区表的设计影响了执行计划。
2)执行计划利用设计特性改变之2_Cluster类型
普通表中,排序不可避免。
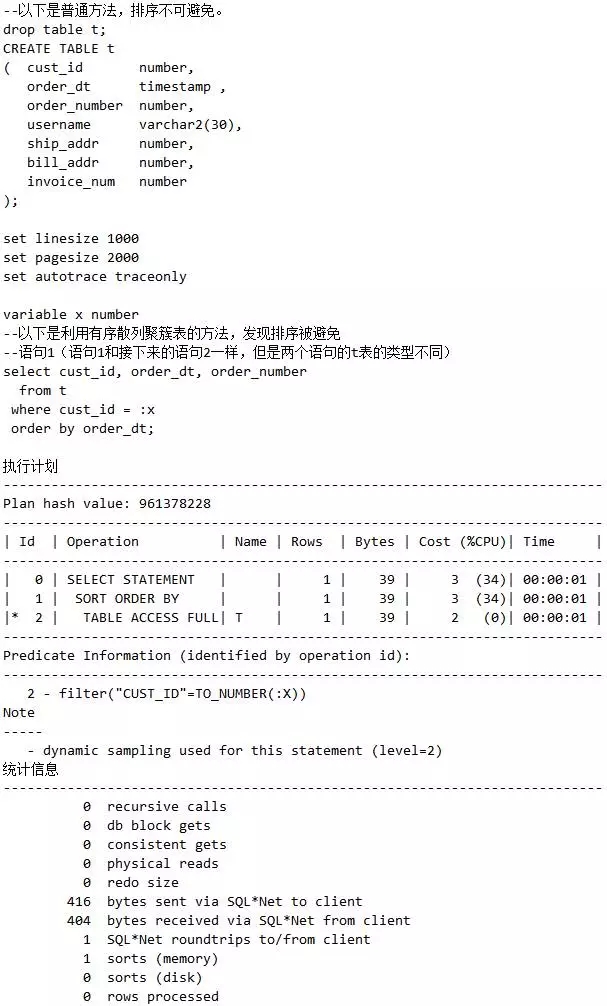
以下是利用有序散列聚簇表的方法,发现排序被避免:

脚本17 有序散列聚簇表消除排序
3)执行计划利用设计特性改变之3_Iot表类型
环境准备:

接下来分别比较索引组织表和普通表的查询性能,首先是普通表,语句1如下:
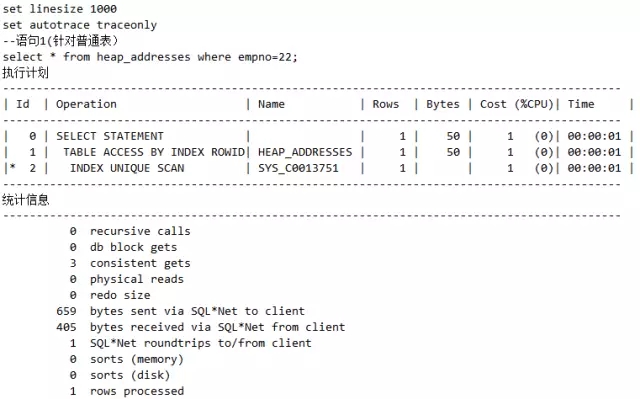
接下来针对索引组织表,语句2如下:
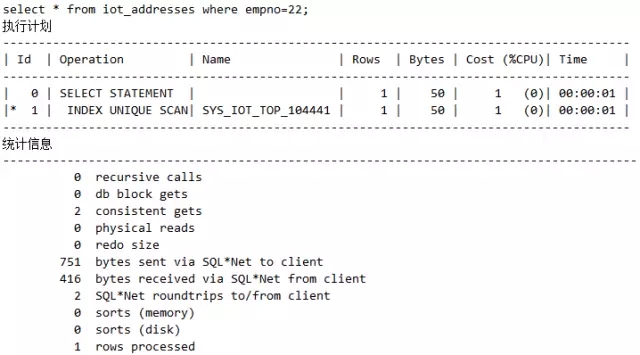
脚本18 IOT表消除回表
观察语句1和语句2的执行计划的差异,语句1的执行计划中有TABLE ACCESS BY INDEX ROWID部分,而语句2却没有。因为在索引组织表中,表就是索引,索引就是表,没有回表的概念。
4)执行计划利用设计特性改变之4_物化视图影响
语句1,普通写法未用到物化视图的特性,如下:

语句2,用到物化视图的特性,如下:
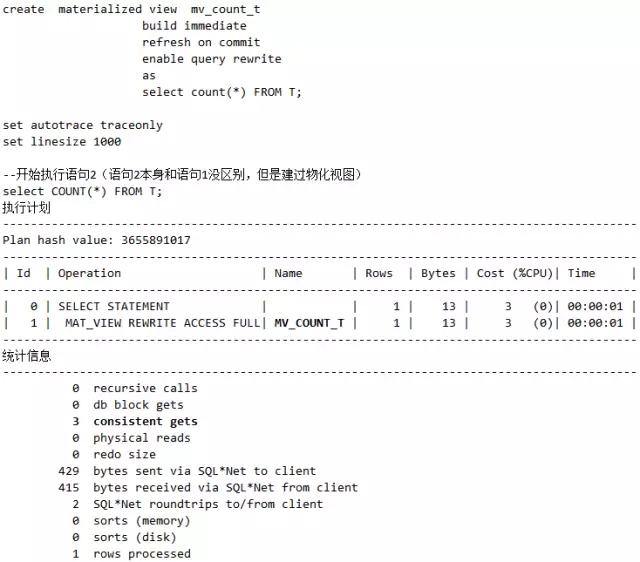
脚本19 物化视图改变了访问的表
说明:观察语句1和语句2的执行计划的差异,重点是执行计划的NAME部分的输出,一个是T,一个是MV_COUNT_T。还可以观察Operation部分,一个有SORT AGGREGATE,另一个没有。
最后,再观察比较输出的统计信息的逻辑读大小。
5)执行计划利用设计特性改变之5_并行度影响
语句1:
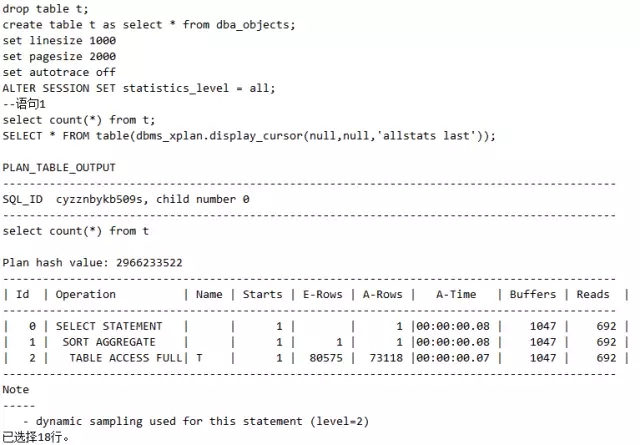
语句2:
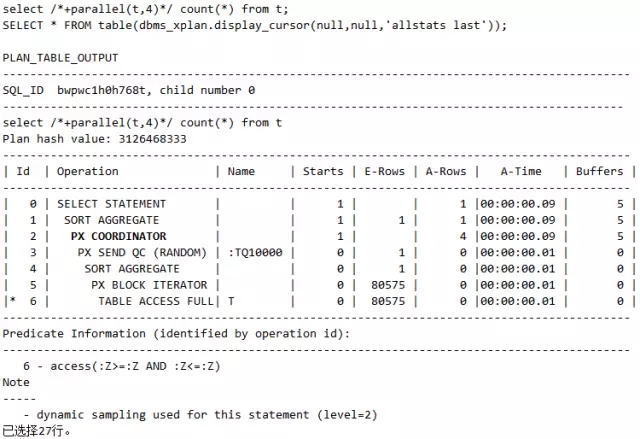
语句3(注意这时表的属性被设置成并行度为4):
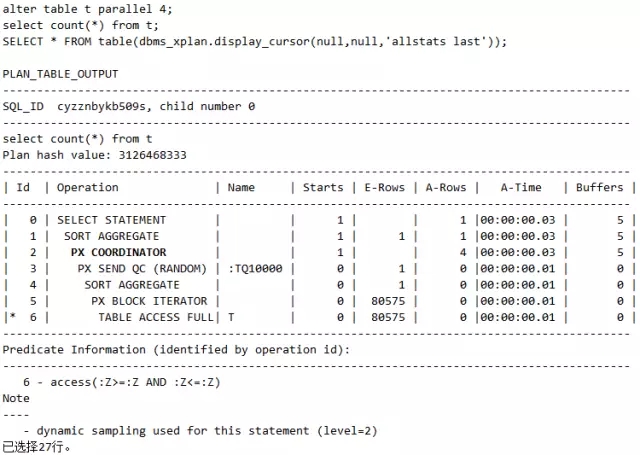
脚本20 表的属性设置为并行,执行计划变化了
语句4(注意这个no_parallel的hint,该hint可以消除并行特性):
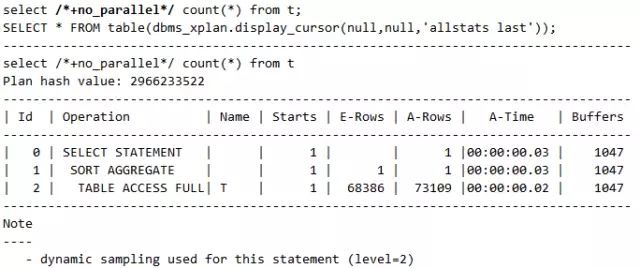
这里语句1和语句4没用到并行,语句2和语句3用到并行。其中语句3是表的属性本身被设置为并行,而语句4是虽然表的属性为并行,但是用Hint强制避免走并行,请好好体会这些语句,并认真观察并行对应的执行计划PX COORDINATOR。
6)执行计划利用设计特性改变之6_列空值影响
语句1(表的索引列的属性没有被限制为非空):

语句2(表的索引列的属性被限制为非空):
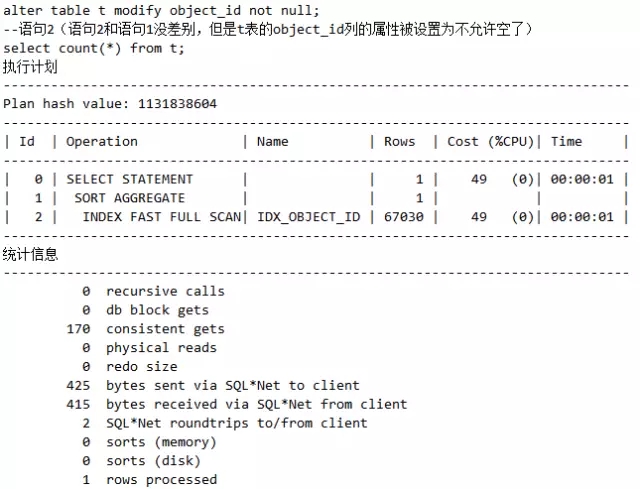
脚本21 索引列是否允许为空对执行计划的影响
观察语句1和语句2的执行计划的差异,语句1的object_id列允许为空,这导致走全表扫描。当设定了object_id列不允许为空后,一模一样的语句2开始走INDEX FAST FULL SCAN了。
7)执行计划利用设计特性改变之7_主外键影响
场景1,普通语句的写法:

场景2,接下来,为T1表增加一个主键,继续看该语句,看看语句执行计划有啥变化:
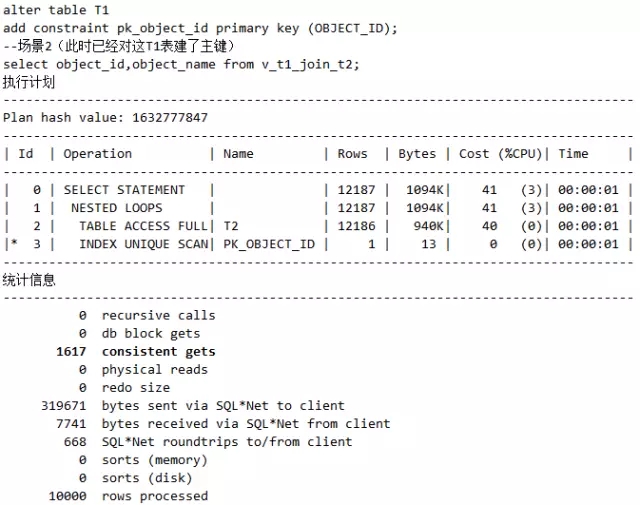
场景3,继续为T1表加主键后,再为T2表增加一个指向T1表的外键:

脚本22 主外键对执行计划的影响
认真观察执行计划大家会发现,同样的语句在场景1、2、3下的执行计划各不相同。其中场景3最为神奇的是,表的访问居然只有T2表,而没有T1表。这是为啥呢?因为主外键确保了只访问T2表和访问两表关联的视图的效果是一样的,所以Oracle聪明地选择了只访问T2表。
1)执行计划改变之其他相关手段1_set_table_stats
如下语句运行的效率比较低下,请仔细看其运行:

大家注意观察就会发现,T2表的记录是1000K,显然比T1的结果集要大得多,这里驱动顺序显然错了。应该是统计信息出现问题了,预测10条实际是1000K条。这时候我们可以通过如下的方式来重新收集统计信息:

不过遗憾的是,这个动作恐怕在业务高峰期影响生产,所以需要等到业务低峰的时候去完成。当然我们还可以用hint来强制改变驱动顺序,不过需要修改代码,也不合适。这时,有一种思路就出来了,就是用set_table_stats的方式来告诉Oracle表的大小情况,如下:
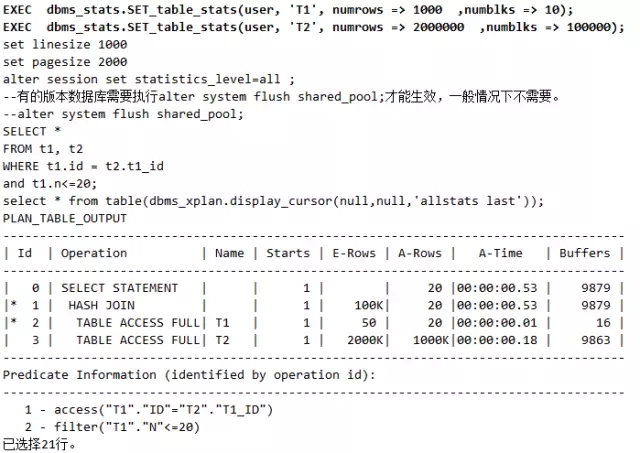
脚本23 set_table_stats改变执行计划
好神奇,我们在几乎没有付出什么代价的情况下,改变了Oracle的执行计划,让该SQL性能得以提升。
2)执行计划改变之其他相关手段2_预估索引效果
这是一个很有意思的特性,请看如下代码,由于没有索引,走的是全表扫描:
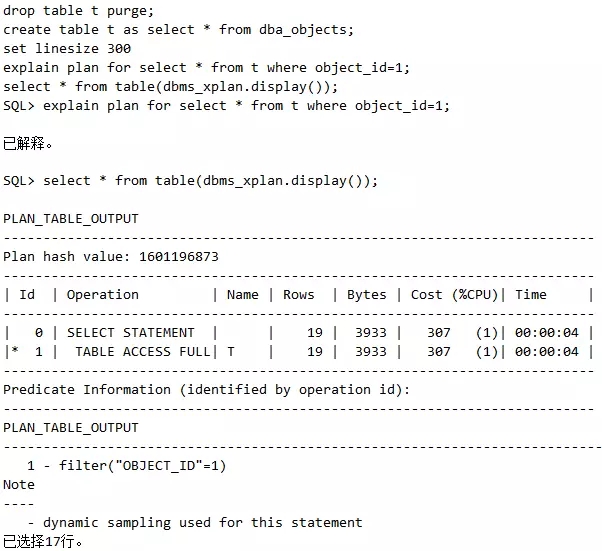
我们会想,要不建一个索引看看?问题来了,建索引后有几个问题,比如索引建完后,Oracle会选择使用这个索引吗?选择后代价会降低吗?建索引本身是一件很辛苦的事,要是建完后效果不好,怎么办?其实不用担心,有一个思路叫虚拟索引,我们来测试一下它的效果,如下:

脚本24 虚拟索引预估有无必要建索引
发现果然走索引,而且代价下降了不少,恩,很好用。可以建!
场景1,首先我们看一个简单的SQL,由于表的索引列没有被设置为非空,因此执行计划肯定是走不了INDEX FAST FULL SCAN的,而只能走TABLE ACCESS FULL,如下:
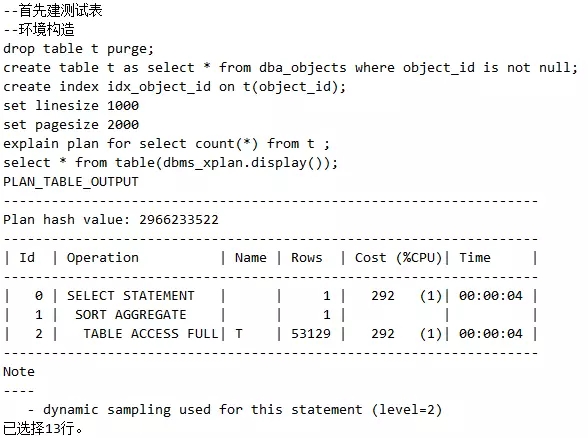
接下来切入正题,开始最关键的命令,建立大纲,也就是OUTLINE!

场景2,如果我们把object_id这个索引列的属性设置为非空,那select count(*) from t语句必然走INDEX FAST FULL SCAN,如下:

不过大纲的作用是固定执行计划,因此假如我们沿用原来的大纲,这个语句就不会走索引,如下:
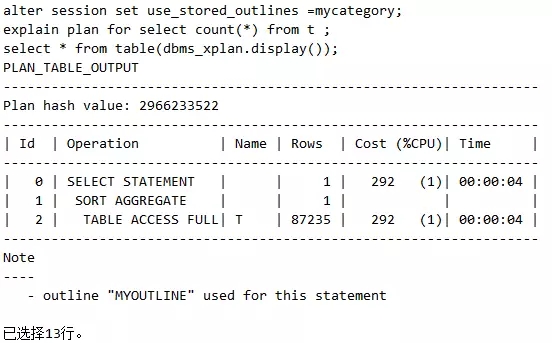
脚本25 执行计划的大纲固定
-END-
不过瘾?
想学习更多?更深?
来全球敏捷运维峰会北京站吧!
9月15日 精彩不容错过

链接:http://www.bagevent.com/event/643565#website_moduleId_60229








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721