
胡湘涛,美团云基础运维负责人,曾先后在爱奇艺、百度软件研究院负责系统和基础服务运维工作,主持开发爱奇艺CDN网络监控系统、爱奇艺CDN部署自动化系统建设。2014年加入美团云,带领基础设施运维团队,主要负责整体网络架构设计、基础设施、监控系统标准化、主导运维自动化平台建设等。
本文根据〖6月25日DBAplus电商行业运维实践沙龙〗胡湘涛老师的现场演讲内容整理而成。点击文末链接还能下载PPT哦~
演讲大纲:
基础平台服务
高可用基础服务
基础网络质量监控
多维资源数据运营
1
基础平台服务
非常感谢大家远道而来,我之前一直在CDN,一直从事基础设施的运维和运维自动化的开发工作。今天给大家分享一下承载新美大的云计算基础设施。
提到基础设施,可能更多的认为是服务器、IDC,还有网络这一块。其实在这里面为了承载整个新美大的电商平台,我们在基础设施方面,稳定性、可靠性方面做了非常多的工作。
基础设施这一块除了我们的设施以外,还有一个基础的服务平台,这样才能非常高效地将我们的业务传递给客户。现在新美大所有的业务都承载在美团云上面,像外卖、美团、点评等。

这是大概的一个基础平台结构,下面是物理层,包括服务器、网络、动力环境。动力环境大家可能相对比较陌生,其实在整个平台的稳定性方面还是发挥了非常重要的作用。之前我们看到经常有某个网站在年会时还在处理这个问题,其实更多的是跟动力环境相关。上面一层主要是我们IP的控制层,比如说网络、路由表、路由协议之类的。那么,如何把我们的服务稳定地交付给客户?更多的是在TCP/UDP这一层的负载均衡层和DNS上面来做,我们做了非常多有关稳定性的工作。讲基础设施,一个是基础,再一个是平台,我们首先从基础来介绍。
首先我们在IDC选用方面做了非常多的工作。在机房选型上,我们选用符合T3及以上标准IDC。什么是T3?T3是国际上针对IDC的标准,T3简而言之可以进行在线的维护工作,现在我们绝大多数的机房都是按照T3的标准来建,部分老的离线机房使用T3的标准,其它会使用T3+,甚至于T4。T4主要是给银行和金融业务服务,它所有的低压配电、空调、动力环境都是有2N或者2(N+1)冗余,当一路或者部分设备断掉的时候,都不会影响到IDC服务器工作。
我们在T3选型的时候,除了选用T3及以上的IDC外,还需要有独立的低压配电系统,比如说低压的配电机,UPS、UPS电池,还有柴油发电机,这个都需要针对我们自己的模块给到一个独立的系统,这样才能够对机房的稳定性做一个把握。同时空调制冷方面一般选用2N或者N+1系统,任何单台机组出现问题的情况下不会对机房产生影响。同时在物理空间方面,我们选用独立的物理空间,机房可以按照实际需求进行定制。
是不是有了高标准的基础设施以后就很稳定了呢?那也不一定。像之前出现过的友商整个机房中断,就是因为在运维的过程当中UPS出现了问题,在维护的过程将点切换到另一路,而另一路无法完全承载整个机房的负荷,最终导致机房瘫掉,所以在这个过程当中运维是影响稳定的最重要因素。
1、首先我们在运维方面有完善的SOP。必须是标准性的操作,所有非标准性的操作都可能会给机房带来灾难性后果。比如说我们做电力维护的时候、机房机架电源标签,标签和实际不一样,可能出现操作和预期不一致情况。同时我们对IDC风险评估做了大量的工作。
2、机房动力监控。除了能够看到的UPS负载、电力负载、机房的温度湿度以外,我们还做了人工24小时动环的巡检,机房的冷风道温度是否正常,是否有局部的过热,这些都是需要考虑的问题。
3、同时因为我们的空间是物理独立的空间,所以每个Q要定期和运营的IDC进行模拟的演练。比如说机房的一台空调宕机,会不会对我们造成影响。如果造成影响,怎样通过风险预案来保障整个IDC的稳定。
做电商的朋友可能都会面临这样的问题,开始可能只有一个IDC,但这个IDC不一定能给我们预留足够的机柜。我们业务在高速扩展的过程中,如何做到在既保证数据中心扩展,同时又能保证我的网络稳定性?
我们采用双超核的架构。我们机房主要在北京、上海,北京是一个IDC的集群,上海也是一样的,同时我们内网使用的是双超,每个IDC在建设的时候都会通过两条异路由光纤分别连到两个超核,这样让我们从容地应对市政施工、来自于蓝翔挖掘机的挑战,经常一铲子下去光纤中断,这是经常出现的情况。所以我们通过双线路OLP保护,主线路中断实行20毫秒的切换备用链路,在单条线路出现问题并不会对我们任何业务造成影响,甚至一个单超核故障都不会对我们业务造成影响,是因为我们实现了双超核互联。然后每条裸光纤上,使用波分系统进扩展带宽。每个机房的出口,按照业务需求在80G到320G之间,根据我们业务模块和业务需求灵活扩展。单条线路利用率一旦到了50%,会对这个进行扩容。所以这个架构充分体现了鸡蛋不放在一个篮子里面,通过冗余来提升基础网络稳定性。
一般的业务发展轨迹,会从单个IDC到同城容灾然后异地容灾,我们现在通过北京、上海两个region,为业务提供异地容灾的支持。我们北京—上海专线利用率即将达到50%的时候,我们会提发起专线扩容,保障整体的IDC群之间的互联带宽。以上是我们针对内网的网络建设情况。
其次,如何快速、稳定地把业务和服务交付我们的用户?我们在北京、上海自建了BGP平台,接入了教育网、三大运营商、以及大部分小运营商。这样也给基础设施带来了充足的资源。BGP平台和IDC也具备非常灵活的扩展方式,我们BGP平台基本都是采用双路容灾。我们之前刚刚提到的这个系统里面进行双线路,这样在任何一个网络设施出现了问题或者线路出现问题的情况下能够实现业务无感知切换。
我们在整体网络的架构和设计的时候,非常强调的是网络架构的自愈能力。任何单一线路出现了问题,第一不能对业务造成任何的干扰;第二业务恢复的时候,实现平滑恢复,这是我们在基础设施架构的设计和运维过程当中遵循最重要原则。
2
高可用基础服务
除了有这么多基础设施,刚刚我也提到怎么样把数据交付给客户、传递给客户?首先肯定是要有高效、高可用的基础服务。

基础服务网络拓扑
这是我们整个基础服务的拓扑图,首先图中ISP是我刚刚提到的BGP平台,在这边是IDC,这是外网,下面是MGW,作为负载均衡的产品。左边是NAT集群负责将内网地址转换成公网地址,为内网的机器提供internet访问,所有的MGW、NAT都以集群方式的部署,集群可以灵活地横向扩张,避免单点问题。后面我介绍一下MGW的性能包括容灾切换时候的情况。
MGW是自研的产品,也是我们云平台的一个模块,为用户提供高效稳定的负载均衡服务。同时对外提供API方便地跟我们运维自动化系统集成,业务关系系统可以通过接口调用的方式,快速进行部署。
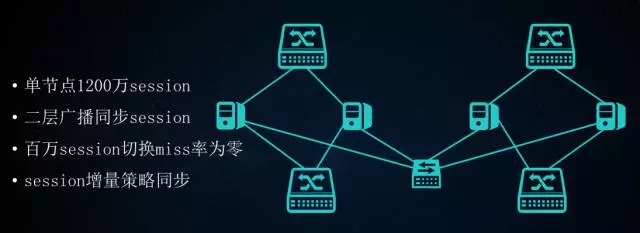
MGW Session同步
现在单台服务器只是1200万Session。在一台MGW出现故障的时候,Session可以无缝地迁移到同集群其他机器,为用户提供稳定的负载均衡服务。Session同步机制我们采用二层同步,在百万级Session切换miss率为零。在大量连接的时候,采用增量同步策略,保障新增的Session能够快速地同步到集群内部。
我们分别做了单台机器和多台机器的故障模拟测试。

MGW Session同步:故障验证
这边是刚刚提到的MGW。我们用了十个不同的机器通过MGW请求后端的服务来进行。我们把第一台MGW在23:37左右的时候,把一台MGW模拟故障机器进行了关闭,从监控上卡37分这个时间点,模拟故障的机器流量为零了,十个请求进程业务监控没有波动。同时我们会面临多台机器同时发生故障,或者多台机器陆续发生故障的情况,那么多台机器发生故障的时候是否影响业务交付的持续性呢?
我们在23:43先关掉了第一台的MGW,从监控上一台的MGW上的业务大多数迁移到第二台上面,我们在这个时间点把监控蓝色这台MGW模拟的故障把它关闭了,大家能够看到第四台的连接数和流量进行有徒增的情况,关闭机器的业务进行了切换,在23:55的时候第三台进行关闭,所有的流量都是迁移到最后一台。在切换的时间点上面,十个压测进程在整体监控曲线上面是非常平缓,说明Session切换过程非常平滑。
出现了故障修复了机器之后,重新上线或者业务增长需要扩容。上线和扩容时,是否也能一如既往保持平滑切换呢?
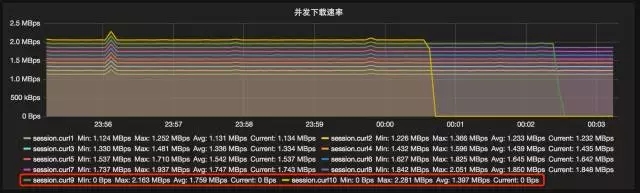

MGW Session同步:故障恢复/无感扩容
这是我们故障恢复和扩容的场景。像前面刚刚提到的这些时间段我们分别演练了三台机器一次发生故障,这个时间点先恢复了第一台MGW,从业务来看基本是没有任何波动的。在1:03左右的时间点剩余两台也进行了恢复和扩容,并发上面来看1:02到1:03是相对平缓的过程,特别需要说明的是,监控图上有红框框起来的,因为我们压测的时候是做文件的下载完成,所以进程求情带宽降为零了,并不是异常情况。
记得我刚刚入行的时候,领导跟我说过一句话,印象特别深刻——让一个网站在地球上消失最好的办法就是干掉它的DNS,可见DNS作为基础服务的重要性。如果一个机房挂掉了可以通过同城跨机房容灾解决,区域挂掉了可以做跨区域的容灾,DNS故障了就别无他法了。DNS是我们的基础服务,通常怎样部署呢?在一个IDC里面部署至少会部署两台DNS做互备,我们的服务器就会在文件里面配上这两个DNS IP。当迁移到另外一个IDC的时候,由于机房IP地址的唯一性,另外一个机房如果增加DNS,肯定服务器所在机房的IP。如果还使用原来的DNS,那么网络一旦有问题整个机房就没有办法进行域名解析。传统业务,通过自动化的发布流程,业务迁移换通过checklist和流程可以解决。

Traditional DNS Structure
在云计算平台的时候,这种场景就不一定适合了,因为机器在做跨IDC层面的漂移,漂移的过程当中还需要给客户改一个DNS,这种用户体验是不好的,会成为运维过程中的一个坑。
那怎么做呢?我们采用了基于AnyCast架构。大家对这个架构可能觉得陌生,但是实际大家经常使用类似方案的DNS服务,例如著名的8.8.8.8。在任何地方都使用一个DNS IP,为你提供DNS解析服务器的是网络路由选录最优的集群。
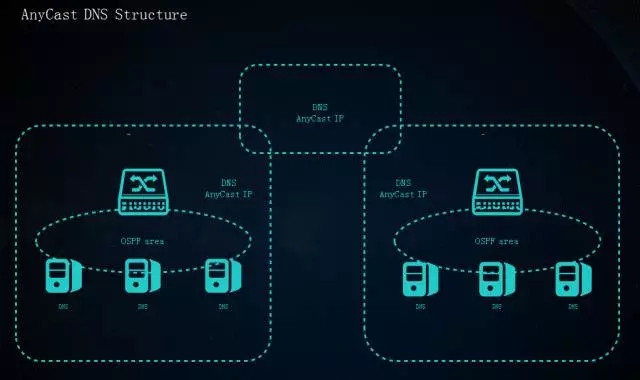
AnyCast DNS Structure
如何实现的呢?
Bind服务器还是使用经典的master-slave架构主从同步,每台bind server都有自己的内网IP,在bind server上和内网核心跑路由协议,所有的bind server都发给内网核心交换机同样的IP地址,如8.8.8.8或者10.10.10.10。 所有的DNS解析请求发到交换机的时候,通过网络就能实现最佳选路。机器扩容也非常的容易,这样方便整个基础设施架构的部署,包括简化了我们运维流程。
以上是我们的基础设施技术方案。
3
基础网络质量监控
有了良好的架构和方案,接下来制约系统稳定的就是运维。我一直坚定地认为运维决定整个平台的稳定性关键,如何快速发现异常,定位问题的root case,需要依赖完善的监控体系和直观的可视化交付。
因为我们的体量相对比较大,三万+的服务器,几千个机柜,上千台TOR,这种情况下如何做到对所有整体的网络一目了然,快速发现问题和响应解决?
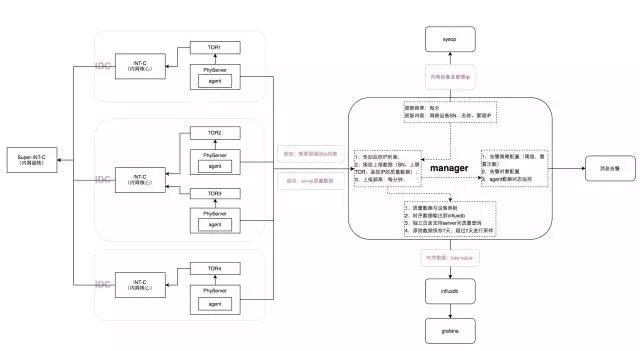
内网质量监控一期:全网ICMP质量
这是我刚刚提到的内网超核,所有跨IDC的网络流量都通过超核进行转发,这上面分别在三个不同的IDC每个IDC有两组内网核心。
我们会在每一组TOR下面的物理机上面布一个Agent,通过Agent监控到全网其它的TOR的网络情况。在这样一个体量的基础设施中,如果实现?依靠人工增加显然不现实。我们开发了一叫sysop的基础设施自动化平台,里面记录了基础设施所有资源信息,通过自动化校验我们信息的准确性。通过这个平台可以获取到IDC、交换机、服务器所有信息,例如监控所需的服务器SN、主机名、IP地址、上联TOR等信息。
最右边是消息告警的平台,根据我们的一些策略配置一些消息告警,比如说两台机器之间,有丢包、延时增大等情况,匹配我们的告警策略之后,通过短信、大象(内部IM)、电话通知到对应人员。下面是我们的监控数据存储和展示模块,通过InfluxDB存储监控数据,Grafana进行画图展示。中间是我们内网质量监控的核心管理和调度模块Manager。首先,我们每台服务器部署的时候会部署这个Agent堆,Agent启动会自动给管理和调度模块发请求,获取到需要监控的列表,然后监控的频率,上报信息字段。Agent监控生成的数据会上报到Manager模块,通过模块处理后存入InfluxDB。

内网质量监控一期:全网ICMP质量
我们知道现在整个网络架构当中监控南北向的流向是非常容易实现的,因为每个服务器到TOR,TOR到核心,再到外网,这是现在最基本的网络监控。但是内部业务调用都是东西向流量,尤其是电商行业。两个业务之间的请求,一旦出现异常大家可能第一反应是网络的问题,我想在场的网络工程师一定深有感触。如何避免这样的问题,如何快速为我们业务定位?可以在内网质量监控平台,把出现问题的源目主机名输入进去以后,通过sysop平台查询到这台机器在哪一个物理机上面的,通过物理机的agent监控。在内网质量监控平台查询这两台物理机之间的网络质量。
图示的两个VM分别是我们北京上海机房的机器,北京--上海长传的网络延时在27到30毫秒之间。大家知道光纤的长距离传输,基本一百公里ping的往返是约一毫秒,从监控来看过去一个小时延时没有波动,所以异常并不是网络原因。这里面可以看到过去任意时间段网络质量,相当于为网络质量做了快照。
网络是动态的,经常出现间歇性的丢包或者中断,网络工程师判断问题需要抓住现场,否则很难快速定位问题。所以我们通过这样的平台给到业务也好,我们自己也好,让我们快速地判断网络是否有问题,或者当服务端出现报错的时候,到底第一时间排查网络还是DNS,或者是业务服务本身的问题,这样缩小了问题点,让业务快速的定位。因为电商一旦出现问题,影响的时间越长,其实都是交易金额。所以在这一块我们投入了很多的精力来做这一块的工作。没有人能说自己的基础设施永远不出故障,我们所能做的是最大程度避免故障,出现故障时能快速发现、快速定位、快速解决。

内网质量监控二期:全网路由质量
这是我们内网监控的第二期架构,第一期我们完成了东西向流量端到端网络监控,但是还不能实现快速发现问题。按照图上网络加,在WJ和DBA的两个超核,每个IDC的内网核心有很多线互联的,之前提到我们跨机房带宽按照业务不同在80-320G之间,也就在核心层面最多有32条路径可达。两台机器互Ping的时候,出现丢包率。
比如说服务器到TOR,TOR到内网核心可能四条线,到超核是16条、32条线,超核到内网核心又是32条线,可选路径是指数级上升的。能否将每一条链路的状况在我们内网的网络拓扑图上面进行展示,这样我们能够第一时间在业务之前发生这个问题。例如两台机器又32条路径的时候,其中一条有问题,按照理想的离散情况,业务访问受影响个概率是3%。但是我们ping的时候源目地址一定,只能测试到一条路径,从ping上检测发现故障的概率只有1/32。
第二期所做的,是能够监测到这32条路径的网络质量。按照路由选路原则,根据厂商不同, Hash策略不一样,常规监控无法检测到其中每段线路的网络质量。我们通过了解厂商的Hash策略,认为构造数据包监控每段链路质量,如从TOR到核心这一段一秒一次的频率检测丢包率和延时的波动了解到每一段的网络是否有问题。这样整个网络的质量,通过拓扑图和质量数据结合,让网络工程师直观地了解到整个网络的情况。

内网质量监控二期:查询&展示
第二期全路由的质量已近部分完成,我们先上线了同一个IDC内路由质量监控,这是我们的展示。当我们需要查看两台机器之间网络状况,在这里输入两个主机名,同一个IDC可以清晰的知道有四条不同的路由,从这边到达对方,比如说10.4.29.2.1是网关。
接下来有两条路径,第一条10.5.1.9,第二条10.4.1.181,从核心到TOR又有两种选择,组合起来就有四种选择,通常如果仅仅只是用ping或者MTR时只能看到一条路径是否正常。如果我们需要判断四条的时候我们需要做大量的工作,这样判断问题就会花费大量时间。通过这个我们能够知道四条链路过去其实都是正常的,如:过去五分钟的平均延时是0.12毫秒,丢包率是零。这样我们对网络稳定性的了解,和排查问题的速度都有巨大提升。
说完了在IDC内部的网络监控,那公网网络质量如果能够快递精确地掌握呢?通常正常情况下是一个黑盒,只有用户有报障的时候才知道我到这个区域的网络有问题,我们能不能主动地监控、发现这个网络是否有问题呢?通过博睿、基调还有17测、阿里测也可以监控,但是成本和时间限制无法让我们在用户报障之前就发现问题和解决问题。

全国公网质量监控:直观展示
我们做了外网网络质量监控,并通过一个地图来展示,随时能够了解我们出口到全国各地级市网络丢包和延时。电信、联通、移动三条线路出口分别进行监控。我们主动以1秒钟为频率监控到全国每一个地级市网络情况。
比如说我们发现西南地区经常出现大范围的网络波动,我们发现这一块区域如果出现红色,比如说延时大于120毫秒或者出现2%的丢包率,这是有问题的。如图上这个时间点到广东省的每个地级市的网络状况都很不好,这种情况结合我们业务的DAU比重就能知道这个网络出现这种情况,业务影响有多大。所以我们的监控系统探测能够很清晰地知道哪一个区域有问题。电信线路有问题,通过BGP平台,将这几个区域的地址或者将这个区域的IP切换到我们联通线路、切换到移动线路,快速的保障业务可用性和用户访问体验。
平台发展壮大是源自于用户的选择,我们需要给用户做到更高质量的服务、更好的用户体验。同时这些系统其实在公有云和私有云是一样的保障标准,我们自己用到什么基础设施、网络条件,其实给到美团云的客户也能使用同样的服务。
因为时间的关系不能一一给大家讲,我们还针对交换机,包括机房温度、DNS解析,以及整个机房之间的专线带宽,按照拓扑图,使用的百分比,有没有峰值,都有非常完善的监控体系。
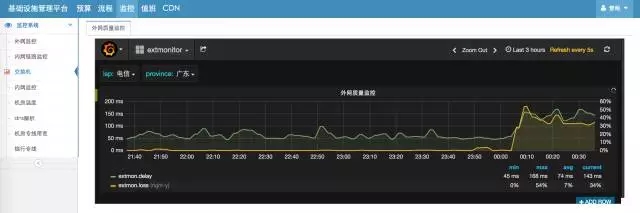
全国公网质量监控:详情&告警
这是我们在全国公网质量的监控和告警,我们发现全国某一些区域出口的时候出现了这种丢包,正常情况会有大量的报警信息,这样可能因为海量的报警淹没了核心的内容。
我们需要做的是将报警进行归并,例如一个省有好多个地级市,通过刚刚提到的报警中心,将信息合并发一条短信内容是这个省的网络又问题,这样收到报警的时候信息对我们判断问题更加有效。
比如说3月23日晚上零点九分的时候,电信出口到江西、广东、湖北这边,虽然到了零点,我们还是有客户的,我们会第一时间拿到这个信息,然后做一个网络切换。同时我们针对重要报警在非工作时间有电话告警的,核心的业务问题如果发生在夜晚,大家不一定关注短信,会通过电话来通知,这样让我们运维人员不会错过任何一个非常重要的告警。
报警信息除了常规信息还会包含监控URL,点击URL就能直接查看监控功能,广东电信正常是这么多毫秒,突然这个时间点突增了,丢包率从0到54%,这对用户访问影响是非常大的,我们收到报警需要进行第一时间的切换,通过之前的系统和优化能够最快的做出判断,按照操作预案进行操作。
4
多维资源数据运营
刚刚讲完了监控,那么是不是只做完监控就高枕无忧了,是否还需要不断、持续优化运维效率?我们会通过监控系统,结合各项数据汇总的指标,针对性的持续优化,让基础设施更加的稳定。
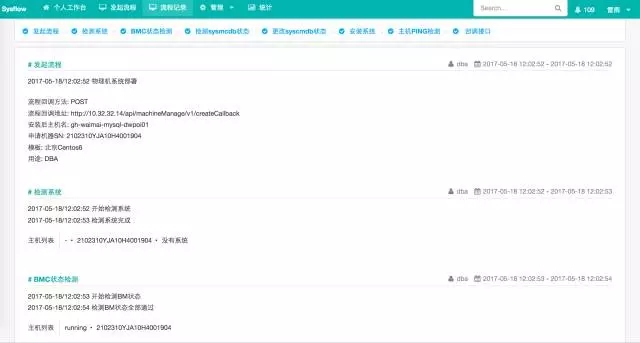

服务器操作流程自动化
比如说这是服务器自动化操作方面,我们申请机器的时候走自动化流程,发起,检测有没有系统,我们CMDB的状况是否正常,如果正常的话,更改为预申请,部署操作系统,部署之后对主机进行Ping检测,认为OK的,最终交付给业务。机器的序列号,部署系统成功率和耗时,这些后端我们都会把数据进行收集,拿到最近30天,比如说服务器上线、下线流程的总量,成功率、失败率、正在运行的数量以及平均每个流程的耗时来针对性的优化。
比如说成功率没有到100%,流程所需的时间是否可以优化?因为服务器的故障还是部署操作系统不完善导致的?每周、每个月,针对性的主题进行优化。比如说平均交付时间过长,申请一个机器等待半个小时,业务方觉得等不及的,我们是不是有办法缩短这个流程,这是针对我们整个基础设施层面的数据化运营。
同时我们在成本方面也做了一定的考量,比如说所有机柜的房间有多少服务器,有多少交换机,这里面有效机柜是多少,针对于每个机柜的电力是多少,我们针对这个机柜所承载的业务和服务器的功耗进行匹配,来提高机柜的有效率。机柜的有效率上升了,在IDC平均业务量的租用成本就会降低,这也是数据化运营的方向。一个是提高我们的稳定性,一个需要降低整体的成本。

服务器电力功耗统计分析
包括现在除了有数据以外,我们更多强调监控的可视化。
我们在机房都有类似于探头来监控我们环境,比如说一些变更。包括除了机房的动力环境以外,我们自己来监控机房的温度、湿度是否达标。比如说机房一个机器或者空调出现了问题,并不一定会告诉你。真当机房不可靠时,我们再发现,可能整个机房死掉了,所以这边有一个提前的预警,包括跟机房建立一个长效的机制。我们在IDC层面,每一个Q进行一次巡检。做一个动力环境的巡检,看一下基础设施的利用率是否有超标、是否有风险来完善风险的评估体系。

现场可视化

环境检测
以上就是我今天的分享,谢谢大家。
PPT下载链接:http://pan.baidu.com/s/1kVJY00R









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒