
本文根据李强老师在〖4月8日DBAplus社群上海数据库技术沙龙〗现场演讲内容整理而成。点击文末链接还能下载PPT哦~
李强
天天拍车运维总监
网名:撒加,先后在AdMaster、饿了么担任运维经理,现任天天拍车运维总监,主要负责天天拍车运维架构的管理、持续优化以及运维团队的建设、培养。
9年以上运维及管理经验。作为国内最早一批思科网络模拟器的推广者、虚拟化先锋论坛的创始人,一直致力于网络模拟器使用的推广,为国内培养网络工程师尽一份力。
分享大纲:
架构改造的动力
运维架构详解
未来的展望
一、架构改造的动力
大家好,我是天天拍车的运维总监李强,今天给大家分享一下天天拍车的运维架构的演进以及实践。我们公司前身是51汽车,也就是说,天天拍车的架构是从51汽车的架构一步一步演进到现在的。我们为什么要做架构的改造?是为了做什么?为了满足什么样的业务?今天的话题就分这三部分来讲,第一部分是为什么要改造,以及我们改造的动力。
1、网络层面
我入职51汽车面试时公司的技术VP和CPO告诉我机房的网络实在是太差了,希望找一个运维经理,对51汽车的机房网络进行改造,降低两机房之间的延迟。
所以,我到了51汽车以后第一次去机房就让我非常惊讶,为什么惊讶呢?
盘丝洞
首先第一点,就是一个“盘丝洞”,大家可以想象一下“盘丝洞”是什么样的,估计做运维的兄弟们,下机房肯定能在里面看到某些公司的服务器交换的网络,到处飞线。这个问题在51汽车的时候非常严重。
网络质量
第二点就是网络质量,我们是放在无锡国际,有两个机房。我去的时候两个机房用光纤互联的质量差到什么程度呢?如果你用mtr做测试可以从零点几毫秒变到三十、四十毫秒,外部访问51汽车网站就会很慢,延迟100多毫秒到200多毫秒,最小的时候是在50多毫秒。
为什么网络质量这么差呢?当时在我之前他们选择机房选了一家比较小的公司。可以这么说,如果你访问联通的线路,可以让你的路由经过美国再回来一趟。
交换机收敛比
第三点是交换机的收敛比,当时全部是做bond的且为mode 0模式。我们的接入层接到上联的带宽是1G,一台交换机是48口的,每个机柜里面放12台服务器,每个服务器两个可做bond,总共用24个口。在理想的情况下交换机会产生24G的流量,但是上联到核心的时候只有1G,这个时候交换机的收敛比是24:1。这种情况下想让你的基础架构承载住你的业务基本是不可能的。
网络部署架构
第四点就是网络部署架构。各位运维兄弟的公司里面也是这样的架构。电信或者是联通的线路拉进来以后先接的防火墙,防火墙后面再做负载均衡,不管是硬件还是软件。这种架构存在什么问题呢?所有的问题最终会发生在防火墙上。如果你的机房里面只用几万块钱甚至十几万块钱的防火墙,你就不要谈多少并发,要多少用户的访问。这就是扯淡,为什么呢?因为防火墙作为最前端的边界设备,如果你的请求进来会解包、封包再往后传递。
所以我们做网络架构时一般都是尽可能地在负载均衡前面少去接入一些硬件的防火墙,即使是用云防火墙也不要用硬件防火墙。
2、服务器硬件层面
我是2015年1月初入职51汽车的,在入职以后我收到了一个信息:2014年的11月份公司采购了28台服务器花了200多万。在去看服务器时,一直到我入职有三个多月的时间,这批服务器放在机房里面空转,为什么呢?就是服务器硬件搭配的严重不合理。
当时都是用的戴尔的服务器,而且是在关键的数据库上面,用的是戴尔默认的网卡。我看了非常震惊,戴尔的R820服务器用来做数据库的服务器,上面内存只有32个G,是4CPU,3块600G的SAS盘,就差到这种情况。
做虚拟化的服务器CPU都是用的E5-2603、2609的处理器。反而做分布系统的机器CPU是用的E5-2650的处理器。内存分配问题非常不均匀。
3、操作系统层面
操作系统层面就更惨不忍睹了,任何一台服务器上面的TCP/IP协议栈配置,几乎清一色的默认。另外我们的系统限制,比如说最大文件句柄数、进程数,还有我们的栈的大小全默认了。
System Limits很多同学会设置为65535,如果你们有这样干的话,真的是浪费了服务器的性能。
第三点就是IRQ Balance,运维的同学应该不陌生。服务本身初衷是为了尽可能的让CPU平衡地使用。但是在个别的情况下,不建议启动,尤其是跟数据相关的开源组件是不建议启动的。
第四点就是多余服务,开放很多多余端口。哪些端口是跟你的服务器所提供服务相关,哪些是你开了以后从来没有关注的。你服务的端口一定是开放的,而且是监听全网。还有一些服务全是监听在0.0.0.0上的。
根本原因就是开放多余端口,而且是向公网开放的。如果在公网上你的服务器用云,随便的NTP的反射攻击你就挂了。
第五点是我们的软件包冗余,是根据不同的业务定制化,安装需要的包。
第六点就是Linux网络配置不合理,你们服务器上做bond的举手,在做bond以后使用mode 0的举手,mode 1的举手,mode 4的举手,没有。Mode 0在你服务器流量大的情况下会造成丢包以及TCP重传,而且你的网卡会非常繁忙。
4、开源组件层面
再下面是开源组件的层面,软件版本不统一。当时很多接手机器上去看了一下。Nginx版本从0.8的到1.26的版本全都有。而且安装方式各不相同,有通过编译安装的,各种各样都有。
还有糟糕的配置,因为51汽车的业务是使用JAVA的,当时用的Tomcat 6作为JAVA容器,配置均为默认配置,当时就震惊了。还有开源软件乱用,大部分可以作为对象缓存来使用,当时我进到51汽车时,memcached是在滥用的,很多东西都往里面“丢”,导致内存的占用并不到,但是应用访问经常是超时的。
基于以上这些问题,我当时入职51汽车的时候,我们老大说给我两个月的时间改造,把基础网络架构改造了,把软件不统一全部进行标准化。
最后我们花了不到两个月的时间就把里面大部分的问题都进行了解决。接下来详细讲一下天天拍车现在的架构。
二、架构详解
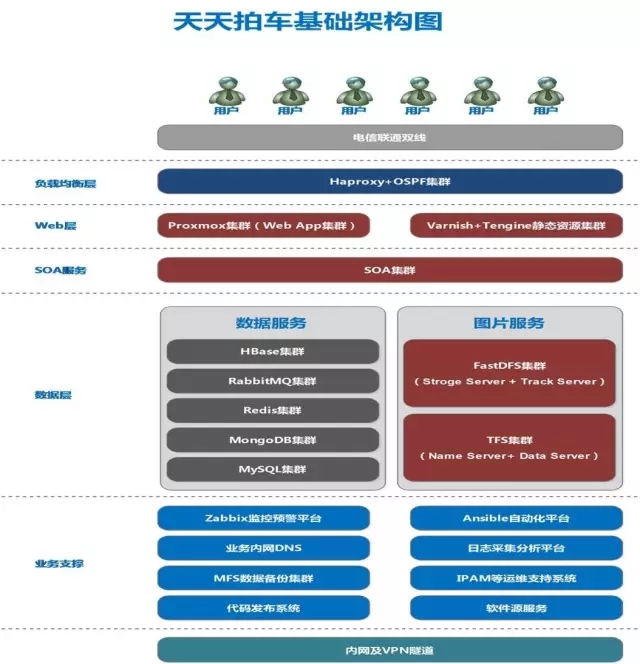
这是我们当时做的架构图,最上面的是我们的直接用户通过电信、联通的两条线路直接到我们的Haproxy,Haproxy集群目前还没有构建,这是我们今年要去实践的。再往下面是7层负载均衡,这块为OpenResty,其次Proxmox是提供我们应用虚拟化的一套套件。
另一面是静态资源,就是图片、JS、CSS脚本的服务提供。再下面是SOA集群,相当于软件通用的服务。到下面是数据层,数据层分了两类,一类是数据服务,由于应用的关系,MongoDB后来我们直接取消了剔出掉了。图片服务这一块儿在目前为止仍然是两种分布式系统同时提供服务。我们新的图片全部是存在TFS集群的,只有老的图片会存在FastDFS。
天天拍车运维还没有OPSDEV,全靠我们运维自己来做。
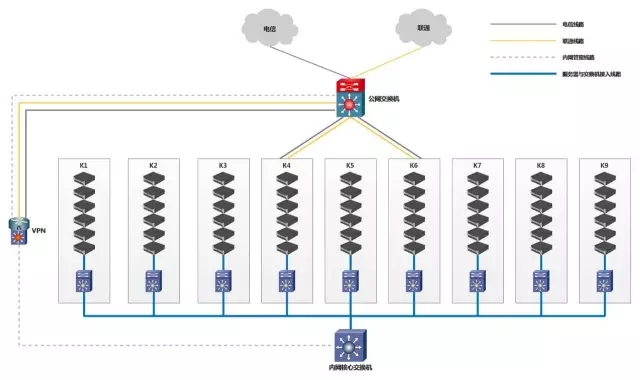
这是我们改造以后的网络架构,相当于是我们实际的部署。原来的架构里面是防火墙,防火墙是放在这上面的。后来我们把防火墙放在这边,就起一个VPN的作用,提供我们运维人员移动办公的需要,以及VPN跟总部的VPN隧道打通,进行直接的互访。
我们现在有9个机柜,每一个机柜里面有个别的服务器提供公网的访问,其它服务器的公网访问全部都是通过内网核心进行数据互访。
大家看到这边的防火墙,我们现在可以做到什么呢?只要通过防火墙连接到VPN,不光可以登录到内网核心交换机上管理内网所有的网络设备,还可以从这边连接公网交换机,对公网交换机进行管理。而且我们内部的监测系统是可以通过VPN设置,防火墙采集公网交换机的流量。
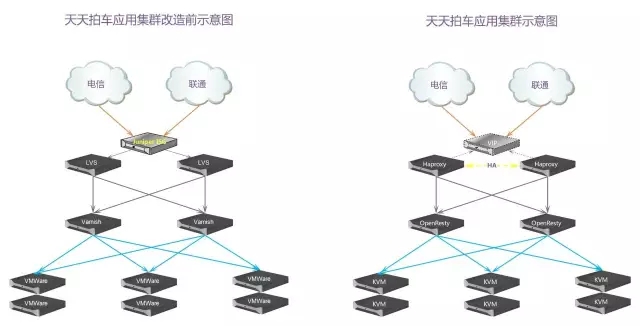
左边是51汽车原来早期的前端应用集群架构,后面是新的天天拍车应用集群。
最开始做的时候在ISG上面配置了地址池,通过NAT映射的方式,请求转发,当时还有一个高可用。LVS再把请求转发到下面的虚拟机上。逻辑架构是这样的,但物理部署是怎么部署呢?LVS这些东西全部是虚拟化的机器,除了数据库,其它全是虚拟机。再加上服务器做了bond以后,我们的模式是mode 0,造成大量的数据包重传。里面的各种应用配置又没有经过优化,大部分都是默认的。导致当时51汽车的网站经常挂。
后来重新做过以后把防火墙直接去掉了,用Haproxy来替换LVS,然后由OpenResty来实现负载均衡。Haproxy做4次的负载均衡,我们把VMware虚拟化,替换成KVM的虚拟化技术。
1、网络改造
移除防火墙
我们的网络改造做法是移除防火墙,把原来的防火墙全部下架。机柜交换机原来是两台,因为设备型号的更换现在是一台。原来用的是H3C的企业网交换机,现在全是华为的数据中心交换机。这里为什么要由两台精减为一台呢?当时我们发现早期人员在配置交换机时放两台是为了防止单点故障,必然要跟核心设备之间全部建立连线。这个时候就是避免交换机的环路。两个交换机之间要做互备,还要启用VRRP协议。在很多时候我们设计网络架构下是避免生成数据协议的。
机柜交换机由两台精简为一台
很多公司一般机柜都不会很多,几个、十来个已经挺不错了。如果你的规模非常大,超过100台交换机,这时如果你签了协议,你的链路只要断一条,整个网络就需要重新收敛,收敛的时间是以秒计。很多中大型的互联网公司,如果生成树协议引起了网络风暴,收敛时网络停止服务,几秒钟的时间肯定承受不了这样的损失。
如果你们之前有去听过京东的网络改造,他们当时也是遇上了这样的情况。交换机是几千台、上万台,早期时就是使用生成树协议,两台交换机做接入,一台交换机的一个口出现故障,会导致业务中断1、2个小时,其原因就是STP造成的。
调整交换机收敛比→6:5
我们调整了交换机的收敛比原来是24:1,后来调整为6:5。当时采购的交换机是24口的千兆交换机,每一个机柜里面放12台服务器,每台服务器有两个网口跟交换机做聚合,理论上来说交换机服务器产生的流量最大只有24G。这样我们的交换机收敛比就改了6:5,理论上是这样说,我们的流量转发是堵塞了,所以上线只有24G。只有我们设计时机柜里交换机收敛比小于等于1才可以进行流量的线速转发。
接入:核心的两层网络结构
我们希望架构的调整是使用接入核心的两层网络和架构,把核心层和汇聚层结合在一起。
所有机柜10G*2上联到核心,起动态LACP
数据经过链路启用巨型帧功能
每个机柜的接入层使用这样的网络结构:数据经过的全链路使用巨型帧,保证数据在传输时是正常的,如果你的交换机上没有开启巨型帧功能,你的服务器没有开启PMTU探测的话就会造成服务器访问异常的。
2、服务器硬件
按服务器部署业务类型合理搭配硬件
硬件改造当时是28台服务器我都重新做了规划,按照业务的不同做硬件的配置。比如说数据库服务器,用SAS加SSD的方案,使用Facebook Flashcache来做加速。现在公司里面所有的数据库集群都是这样放去做。
核心业务网卡由升级为intel i350
我们核心业务的网卡主要是为了负载均衡,还有所有跟数据有关的服务器。全都升级为intelI350的网卡。
内存与CPU严格匹配
内存与CPU严格匹配,当时我们有一些服务器,内存频率是比较高的,但是与之对应的CPU并不支持那么高,你虽然插上去可以用,但是系统一直提示报错。为了防止以后不应该出现的奇葩问题,所以我们是把内存跟CPU进行了试配。
3、操作系统
操作系统这一块儿我们做的是非常多,我们做了订制化,而且深度订制化。
Kernel统一使用精简过且重新生成的rpm包
第一就是我们kernel,我们把内核使用了2.6.32-431.29.2的内核,对内核重新做了调整。把一些服务器上用不到的驱动模块全都进行剔除,比如说WIFI、红外、蓝牙、用不着的网卡驱动全都剔除,做一个精减,精减完了以后重新做成内核的安装包。
KickStart高度定制(网络部分)
因为要实现自动化安装,所以必然要做KickStart,这块我们也做高度订制化。我们已实现了自动去配网卡,如果你看过红帽官方的文档,KickStart里面的章节是31章节,你就可以知道网卡直接可以配置成bond模式。
我们还在Kickstart里面对SSH配置,还有DNS的配置,还有对于网卡硬件的配置。我们可以修改网卡的参数,发送和接收都是可以更改的,我们也是在KickStart里面做脚本自动修改。
优化TCP/IP协议栈(TW、sysctl.conf)
优化TCP/IP的协议栈主要是窗口还有大小,调整TCP各种连接的超时时间。如果没有经过内核的订制,一般做架构或者你的应用访问时服务器上会产生TW连接,一般内核里面默认是60秒的时间才会进行释放。如果你的网站是高并发访问量非常大的话,那你的连接基本上是释放不干净的。所以我们做了一套直接修改内核的定义。从60秒修改成5秒。这样可以让自身的服务器对外始终只有少量的TW连接。
默认关闭不必要的服务,关闭无关端口
把不必要的服务全部关掉,因为关闭了不必要的服务大部分端口也就被你关闭掉了。
剔除不需要的rpm包,保留性能分析工具、编译工具
再接下来是删除不需要的rpm。如果你们有仔细订制过的话,就会发现有时候也挺坑的,会给你安装很多用不到的软件在系统里,而且还给你开放一些端口。
所有开源组件定制化,动态链接库不依赖操作系统(绿色版)
软件安装目录、配置文件目录、日志目录、PID目录标准化
再下面是所有的开源组件进行订制化,我们的安装目录、配置目录、PID文件目录、启动脚本都是做了定制的。需要你把软件安装到下面,方便管理。自己有源服务器,会在上面把源码进行定制化的翻译,再做成绿色软件。不依赖于操作系统,我的软件包如果是rpm包,只要是以rpm包管理的系统上随便安装,不依赖于动态软件库。
4、开源组件
这边是开源组件做的升级还有引用的其他东西,我们每一个开源组件的变更都是有原因的。
4层负载均衡:LVS--àHaproxy
其中第一个负载均衡把LVS换成了Haproxy,大家去网上查的话应该有很多人写过差别。当时换LVS是为什么呢?第一,LVS虽然是非常高性能的转发,网上人家说可以转发100万、200万,这都是扯淡的。因为这些人在写的时候并没有告诉你他的网卡的带宽,他测试时后端真实响应的数据多大。LVS在部署时它的机器的IP地址必须是同一网段的。如果你的公司业务非常大的话,你就要消耗非常非常多的公网IP,唯品会就是这样做的。
LVS除了刚才说的原因,还有一个原因是不能灵活地进行配置,配置我们的虚拟主机,不能把CPU按照不同的业务运营的负载高低进行分配。LVS不能做什么事情呢?不能动态地对配置进行修改,如果你要添加新的集群的话你得修改配置文件。再往大了说,如果用LVS跟OSPF配合使用的话,RealServer上就需要维护脚本,进入51汽车时运维经常在配置脚本时忘记执行,所以鉴于这些原因,当然还有一些其它的原因,使用起来并不符合我们的要求。
换成了Haproxy以后,可以根据业务的压力不同,将CPU分配给压力大的业务,有的人可能会用Haproxy,但是它就一个问题,不能将我们用户真实的IP传到后端。很多人会使用Haproxy的透明代理模式Tproxy模式,把用户的真实IP上传到后端,这跟LVS的机制几乎是类似的。但是我们更换到Haproxy的1.5版本以后这上面默认之了proxy协议,我不再使用透明代理上传客户端的真实IP,使用varnish写在日志里面做分析。
页面缓存:Varnish 3.0 ---à Varnish 4.1
页面缓存原来用的是varnish3.0的版本,后来升级到varnish4.1。因为它在做数据连接时很容易产生CLOSE-WAIT连接,它连接的释放是有问题,你的内存有多大就一直消耗。大家知道做TCP连接的内存是不可交换的内存,不能使用交换分区。
反向代理:Nginx--àTengine--àOpenResty
早期反向代理用的很多版本后来我们使用Tengine,为了统一技术体系就使用了它。但是在去年下半年时我们发现Tengine的很多公司已经跟不上Nginx了,很多技术Tengine虽然支持但是有很多问题。后来用下来,包括日志的过滤,相信大家有很多这种需求,比如说你的网站,你主要的运维下面可能会加一些JS、CSS,如果你不开始过滤的话会希望把访问日志全部写到日志里面,不方便你去进行日志的分析。如果我只去过滤我主要的请求,那我就需要使用日志过滤,而那个时候Tengine2.1.2里面根本没有,只能使用第三方的模块。第三方的模块功能我要去用时,我发现Nginx早就实现了,可以做一些变量的映射,应用到我们的指令里面就可以进行过滤,非常方便。我们更换了Opneresty,更换它的原因还有什么呢?因为微博开发了一个模块是Opneresty,可以进行增加和产出,而Tengine不支持模块,所以没有办法,我们只能更换Opneresty。而且Opneresty又支持别的模块所以我们就直接更换了。
虚拟化技术:VMWare --à Proxmox(kvm)
虚拟化技术把vmware更换为KVM,直接使用了开源的Proxmox,目前小的互联网公司也在用。做虚拟化非常简单,运维开发时可以进行系统研发。
对象缓存:Memcached--àRedis
对象缓存,我们把Memcached替换成Redis。现在的缓存也不是什么数据都往Redis里面放,Redis里面只做数据对应关系的缓存。不像以前Memcached里面,不光存缓存,还有很多乱七八糟全都存。后来Memcached经常出现失败,原因就是因为缓存的非常大,超过1M。Memcached默认是1M这是1.4.21版本之前。
图片存储:NFS--àFastDFS--àTFS
图片存储对51汽车来说是最头疼的事情。最早是用NFS来搭建的,而且是两台。我去的时候NFS 6T空间用的不到500G,访问一些图片时非常非常慢,慢到什么程度呢?假如说你在一个图片库下要执行的话会卡住,大家知道某一个目录下面存在了上千万张图片时,怎么才能最快速度地把图片给列出来?这个是非常小的技巧,就是用LS命令在执行的时候把色彩参数给去掉,或者直接dir命令。
NFS用得非常头大,所以我们使用了FastDFS,因为它非常的轻量。可后来我们为什么又替换了FastDFS呢?因为扩容时必须以group单位进行扩容,如果单位超过16个单位怎么办?当你的FastDFS上的硬盘是独立的模式,如果一台戴尔的730XD可以插14块硬盘,当硬盘再多时你会发现挂载时你在Nginx做配置,这个零零你们猜是10进制还是16进制,这个信息FastDFS的作者从来没有说过,作者说这个地方只能是16进制的,M00到MFF,就踩了这么一个坑,后来发现它在扩容时真的不方便,因为我以前用过TFS,所以建议我们老大换TFS。
TFS可以做什么呢?动态进行了扩容,我们现在是5台TFS DS,当容量不够的时候只需要往里面增加机器就可以了,每增加一台机器,原来5台的机器数据就可以做负载,增加到新的机器上,这个扩容是非常容易的,比起FastDFS的扩容简单的多,FastDFS的扩容每次绝对是两个服务器。
数据库:MySQL--à Percona
服务器我们用的是MySQL,后来我们全部统一替换成Percona。原因是它里面的功能做了增强,对于一些空闲的事物做了控制,库里面的数据可以拿出来,在下次数据启动时可以进行热加载。
数据库读写分离:代码实现--à OneProxy
数据库原来是在DevOps应用里面使用代码实现的,我增加服务器的话,所有应用的配置文件必须做,否则没法用,后来我们使用了Oneproxy,在使用这个之前我们首选还是开源。我们在侧环境用的时候一点问题都没有,一上线早上9点钟线到10点钟全网全挂了,查问题最终查到什么呢?我们的应用连不上数据库,但是登上去看的时候数据库是连上后来跟用户交流的时候,发现它的数据特别容易造成假死。

唯品会也用过,但他们做了修改。13.0使用的一种方式,但是大部分的公司肯定不会投入这么大的精力。很多人只能说两台放在那里做高可用,结果到只要你的数据库连接库超过800就开“死”。发现它已经发布的版本跟下一个版本的文字表述是有差异的,会让我们踩到坑。代码里面并没有写名,这个配置1.4的版本是这样的,在1.5的版本是那样的,但是并没有写名,原代码的注释里面写的,一路坑。后来没有办法我们又上了Oneproxy,自从用上了这个,我再也没有关心过数据库的问题,基本上数据库没出现过问题,使用这个根本不用在数据库服务器上查询,通过Onepoxy我们可以直接看到业务过来的时候哪些执行时间非常高,哪些执行时间非常长,现在都不需要上服务器。包括我们的研发,现在都很主动、自觉地等到Oneproxy。
引入RabbitMQ并且实现集群化
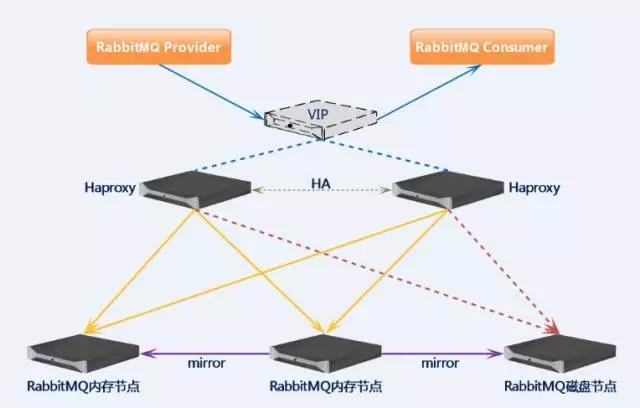
原来我们写入数据库时,当你访问量大时数据库写压会比较大,我们引用了RabbitMQ,RabbitMQ很多公司也要用。做集群必须要注意一点,就是连接。节点之间必须配置长连接,如果没有长连接的话你的应用里面经常会报错,这个我们原来是碰上了。做调试实现了超连接。当然是TCP的而不是HTTP。
引入业务内网DNS系统:PowerDNS
再下面是引入了业务内网DNS系统,我们之前用的东西是非常低效,我刚去时代码连接的数据库存全是用的IP,只要用一遍,应用就要修改、重启,很麻烦。我并没有用棒的东西,虽然现在有插件,但是还是需要修改的方式,我当时觉得这个东西肯定不是高效的。我使用了的话没有办法进国内网的DNS系统进行匹配。
现在如果有新的机器要开或者有运维的变化,会通过我们的运维访问工具直接上数据库里面去写数据就可以了,不是很忙的时候可以通过PowerDNS的数据包进行修改。我们会通过格式导出来,导出来的文件会下发到所有的机器上面,让面还部署了PowerDNS的解析器,每一台访问的是宾机的PowerDNS的解析器。不管我们PowerDNS的认证器挂不挂,我都可以保证在解析方面不会出现任何错误的。
构建数据备份集群:LizardFS(MFS)
数据库的备份集群使用了分布式文件系统,MFS大家应该比较熟悉了,比较常见了。就是MooseFS。我们并没有使用官方的,而是使用了这个,MooseFS的衍生版,它能做什么呢?它实现了MooseFS的影子版,备份数据库的数据。这个指令可以在被动服务商上使用,通过其它集群的Moos,方便我做数据的任意节点的恢复。
引入Rundeck作为代码发布任务的平台
再下面发代码,我们使用了Rundeck,很多公司是可以自己做代码发布平台,就是通常所说的自动化运营平台。我们因为没有,所以使用这种Rundeck方式,这个可以建议大家使用一下,非常方便。
引入Kong作为API Gateway
最后是API网关,我们引入了开源的Kong作为API访问网关,这个主要是做手机APP用的,为什么使用它呢?原因是在于Kong的底层使用的就是Opneresty。这是我们2015年到2016年整个的改造,实现了发布代码的分秒级。数据库再也没有操过心,虚拟化也没有操心,我现在基本上不做原来以前一线的运维,现在主要做架构。
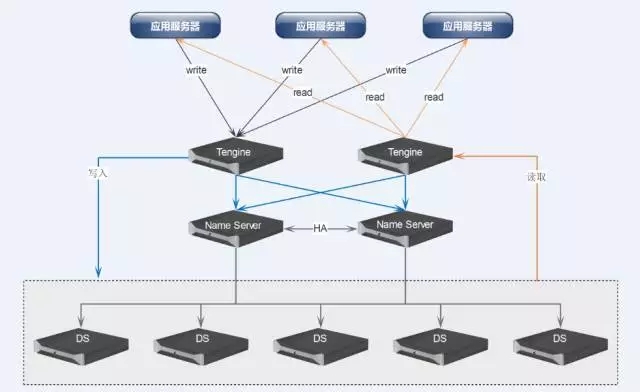
这个图是我们刚才说的DNS系统的。这是是MQ集群的结构,两个内存节点加一个磁盘节点。这个是TFS的集群,如何向我们的应用提供服务。
三、未来的展望
1、网络架构
今年我们准备即将要做的事情,第一个就是网络。网络这一快写准备把介入层设备华为的CE交换机并升级为2台,使用华为的网络设备虚拟化技术,Stack技术,把两台设备虚成一台设备。可以提供给冗余。
主要是为我们的技术网络做铺垫,我们现在已经准备部署了,但是网络端并没有使用Vxlan,因为这是非常重要的事情,使用Vxlan坑太多。
2、构建日志采集分析平台
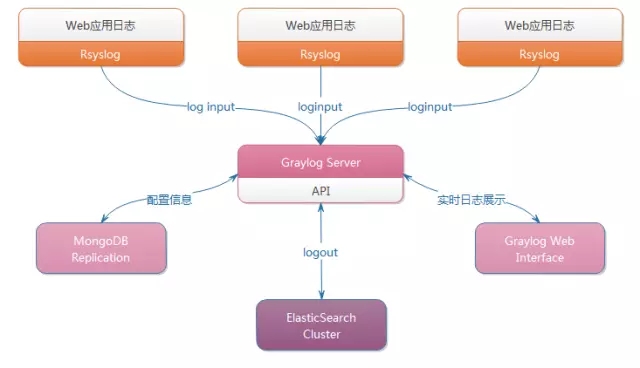
第二个是构建日志采集分析平台,我们的分析平台跟网上人家讲的ELK完全是不一样的,我们不使用ELK,而是使用了V8,V8版本是可以做模板定制,收集日志是GRaylog,非常方便。
3、非核心业务Docker化
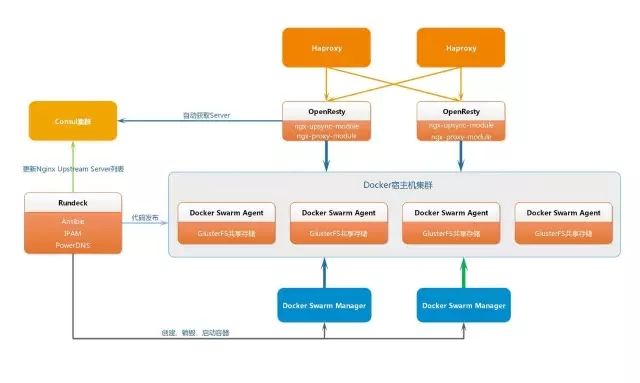
这是我们即将马上实施的Docker方案。
4、Web业务前段技术验证
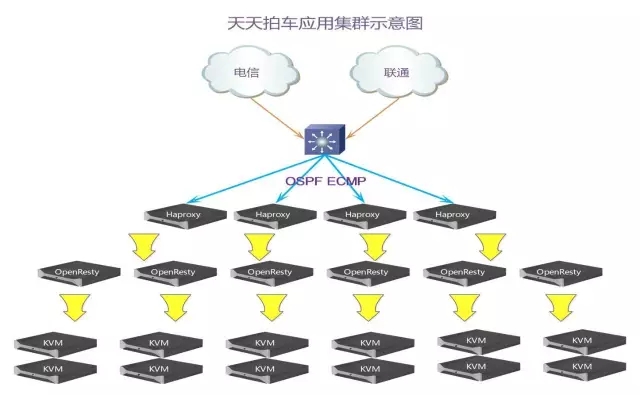
第四个是技术认证,通过ECMP+HAproxy可以实现百万并发,如果你们去买过京东技术解秘,京东目前就是用了这样的方式。
5、运维其他方面
再接下来是其它的辅助。首先是运营平台的建设、资产管理、VPN。然后,实时性能的分析大家都了解过,我们准备使用开源。
第三就是Zabbix+OneProxy的分库分表设计,数据库的性能单采用的性能是撑不住的,需要做分表,这一块儿我们是非常熟悉的。而且新浪微博也使用Zabbix做数据库。
第四是GlusterFS深入研究和集群化。我们现在使用的换并没有做集群,我们做集群化实践考虑是跟这个有关,GlusterFS。
第五是OVS-DPDK,如果你们公司采用Docker的话这块东西是必然跑不掉的。我们为什么要去研究?主要是因为DPDK环境下可以实现单机网卡性能的最大化。
Q1:我是一个做网站的,将来想做大型的网站,但我不是网管,你说的都是网管的事情,跟我们不相关。
A1:绝对不是网管做的,公司必须要有专门的运维团队。
(接上问)
Q2:绝对不是做网站的程序员管的事情吗?
A2:很多公司都是由写代码的人区别做的,当你的网站有一定规模时必须要有专门的运维团队。
Q3:我问一个比较low的问题,我对防火墙的理解不是特别深,我也是搞开发的。看到你们把防火墙拿掉了,会不会有安全性的问题?
A3:如果你的服务器能把大部分的关口给关闭了,你的服务器不得不开放公网时,你在启动时必须加上监听IP,要监听在内网IP上,不要监听在0.0.0.0上。你只要把不需要的服务给关闭掉,基本上可以解决80%的安全问题。
防火墙真的能防护你吗?防不住,传统的放火墙并不能帮你处理一些基层的处理,你要做策略是做不了的。传统的防火墙做不了这件事的,只有应用服务墙是专门做的。但凡设计到硬件有一个最大的问题,不易扩展。
如果你今天买一个30万的防火墙在那里,你怕它出问题得买两台,60万,你的网站如果流量非常大到像饿了么那种流量爆发式的增长,那你得加设备你买新的设备,你一买就得是2的倍数,而且最快也要一周,你的网站连续挂一周能接受吗?不能接受。
(接上问)
Q4:别人用拼的放或者搞肉鸡搞你的网站呢?
A4:这个时候云防火墙有非常大的用处,基本上使用云防火墙做处理。拼不了你还有一种方式是说在小流量的攻击下面,一般让想到是用IPT,建议不要用这种。使用推动路由,你可以把攻击者的IP路由指向了LO环回接口这就是简单的黑洞物流。如果你做防火墙规则的话还得消耗资源。所以我们公司的所有服务器上IPT都是关闭的,不开放。
PPT下载链接:https://pan.baidu.com/s/1c2IM66c#list/path=%2F









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721